通过redis生成编码生成不重复的序列号
Posted qq_43367379
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通过redis生成编码生成不重复的序列号相关的知识,希望对你有一定的参考价值。
/**
* 生成一个序列号,每天从0开始自增
* yyyyMMdd0001
* @Param leftCode编号特定前缀
* */
public String getSequence(String leftCode)
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyyMMdd");
String dateTime = simpleDateFormat.format(new Date());
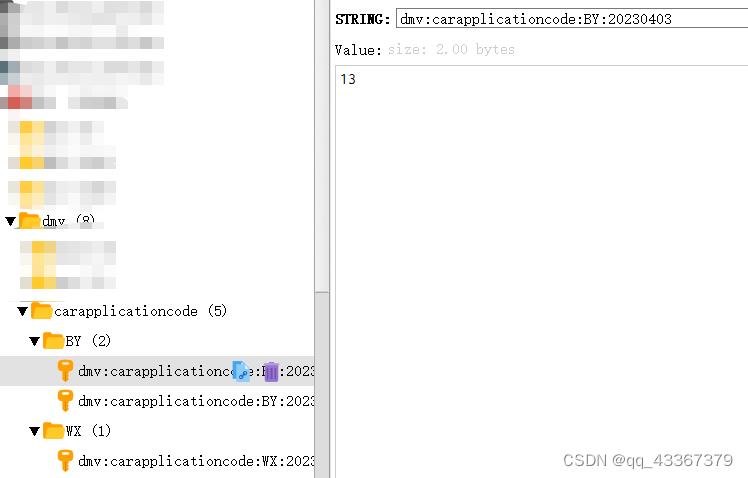
String key = MessageFormat.format("0:1","dmv:carapplicationcode"+":"+leftCode,dateTime);
Long autoID = redisTemplate.opsForValue().increment(key,1);
if(autoID == 1)
//设置 hash 值在凌晨23;59:59 清理
Date date = Date.from(LocalDateTime.of(LocalDate.now(), LocalTime.MAX).toInstant(ZoneOffset.of("+8")));
redisTemplate.expireAt(key,date);
String value = org.apache.commons.lang.StringUtils.leftPad(String.valueOf(autoID),3,"0");
String code = MessageFormat.format("01",dateTime,value);
return leftCode+code;
redis中的存储
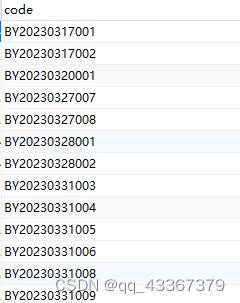
实际的生成效果
创建无重复的随机数序列
【中文标题】创建无重复的随机数序列【英文标题】:Create Random Number Sequence with No Repeats 【发布时间】:2010-10-16 04:26:36 【问题描述】:复制:
Unique random numbers in O(1)?
我想要一个伪随机数生成器,它可以以随机顺序生成不重复的数字。
例如:
随机(10)
可能会回来 5、9、1、4、2、8、3、7、6、10
除了确定数字范围并将它们随机排列或检查生成的列表是否有重复之外,还有更好的方法吗?
编辑:
我还希望它能够有效地生成没有整个范围的大数字。
编辑:
我看到每个人都在建议洗牌算法。但是,如果我想生成大的随机数(1024 字节+),那么与我只使用常规 RNG 并插入 Set 直到达到指定长度相比,该方法会占用更多内存,对吧?有没有更好的数学算法。
【问题讨论】:
有些 PRNG 在整个循环结束之前不会重复——其中任何一个使用最后生成的数字作为下一个数字的种子都具有该属性。 关于您的编辑:如果您使用常规 RNG 并将数字添加到集合中,您认为会占用多少内存?与您提前生成数字列表的数量相同... Derobert,他们中的一些人叫什么名字?这正是我正在寻找的解决方案类型。 这真的不是重复的,因为 OP 表示他想从一个非常大的范围内生成一小组唯一性。在这种情况下,洗牌是不合适的。 @Bill 该问题中正确的(与接受的相反)答案不需要改组。 【参考方案1】:为了确保列表不重复,它必须保留以前返回的数字列表。由于它必须在算法结束时生成整个列表,这在存储需求上相当于生成有序列表然后洗牌。
更多关于洗牌的信息:Creating a random ordered list from an ordered list
但是,如果随机数的范围很大,但所需的数字数量很少(您在评论中暗示这是实际要求),那么生成一个完整的列表并打乱它是浪费的。对巨大数组的洗牌涉及以某种方式访问虚拟内存页面(根据定义)会破坏操作系统的分页系统(在较小的规模上,CPU 的内存缓存也会出现同样的问题)。
在这种情况下,搜索到目前为止的列表会更有效率。因此,理想的做法是使用启发式(由实验确定)为给定参数选择正确的实现。 (很抱歉用 C# 而不是 C++ 提供示例,但 ASFAC++B 我正在训练自己用 C# 思考)。
IEnumerable<int> GenerateRandomNumbers(int range, int quantity)
int[] a = new int[quantity];
if (range < Threshold)
for (int n = 0; n < range; n++)
a[n] = n;
Shuffle(a);
else
HashSet<int> used = new HashSet<int>();
for (int n = 0; n < quantity; n++)
int r = Random(range);
while (!used.Add(r))
r = Random(range);
a[n] = r;
return a;
检查重复数字、在发生冲突时循环等的成本会很昂贵,但可能会有一些Threshold 值比分配整个范围更快。
对于足够小的数量要求,使用used 的数组并在其中进行线性搜索可能会更快,因为位置更大、开销更低、比较便宜...
同样对于大数量和大范围,最好返回一个根据请求生成序列中数字的对象,而不是预先为结果分配数组。由于 yield return 关键字,这在 C# 中很容易实现:
IEnumerable<int> ForLargeQuantityAndRange(int quantity, int range)
for (int n = 0; n < quantity; n++)
int r = Random(range);
while (!used.Add(r))
r = Random(range);
yield return r;
【讨论】:
查看 中的 random_shuffle 以获得 Knuth-Fisher-Yates shuffle 的干净 C++ 实现,前提是您已将值列表填充到 RandomAccessIterator 兼容容器中。 第一句话不对。线性反馈移位寄存器的正确设置实现将在其返回开始之前精确地遍历其范围内的所有值。 你说得对,我假设随机性的来源是一个获取所需范围的函数,这可能是不必要的。但我猜 LFSR 的问题在于将输出缩放到指定范围而不会引起冲突? 这个答案的第一句话(“为了确保列表不重复,它必须保留以前返回的数字列表”)显然是错误的。在不存储先前生成的数字的情况下,有很多方法可以生成不重复的序列。因此,这种方法是错误的。【参考方案2】:洗牌是一种非常好的方法(前提是您不使用朴素算法引入偏差)。见Fisher-Yates shuffle。
【讨论】:
反对者(对这个旧答案)是否请发表评论。谢谢。 OP 特别要求提供一种不需要存储整个范围并对其进行改组的方法。 请仔细看:这些附加要求是后来添加的。【参考方案3】:洗牌 N 个元素不会占用过多的内存...考虑一下。一次只能交换一个元素,因此使用的最大内存是 N+1 个元素。
【讨论】:
假设我想从 1-2^64 位生成 100 个数字,如果我洗牌 N 个元素,我需要 2^64 个 64 位长的数字。如果我使用其他解决方案,我只需要存储大约 100 个 64 位数字。 @unknown (yahoo):这不是你问的问题。【参考方案4】:对于特定范围内的随机数,无重复随机数是最好的方法。您描述的方法(随机生成数字并将它们放入 Set 直到达到指定长度)效率较低的原因是由于重复。从理论上讲,该算法可能永远不会完成。与 shuffle 相比,它充其量只能在无法确定的时间内完成,而 shuffle 总是在高度可预测的时间内运行。
对编辑和 cmets 的回应:
如果如您在 cmets 中指出的那样,数字范围非常大,并且您想随机选择相对较少的数字而不重复,那么重复的可能性会迅速降低。范围和选择数量之间的大小差异越大,重复选择的可能性越小,您在问题中描述的选择和检查算法的性能就越好。
【讨论】:
但是,如果我想生成 100 个 1 - 2^64 位的数字,那么创建一个 2^64 数字的列表然后从中进行随机洗牌是没有意义的. 不,它没有。在这种情况下,碰撞的可能性将大大降低。如果这是您需要的样本和范围,那么您问题中的示例将非常具有误导性。【参考方案5】:如果您不介意平庸的随机性属性并且元素数量允许,那么您可以使用linear congruential random number generator。
【讨论】:
你知道这与 LSFR 在随机性方面的比较吗?投票支持你的算法。我有点担心这些数字会位于“m1/n 超平面”中。 LCG 有一些严重的问题,但超平面问题存在于 所有 PRNG 中。这取决于算法、状态字的大小和发生这种情况的参数的良好选择以及有多少超平面。例如。 624 维超平面中的 Mersenne Twister 屈服点 啊,我明白了,感谢您解释所有 PRNGS 都有这个限制。【参考方案6】:如果保证一个随机数永远不会重复,那么它就不再是随机的,并且 随机性 的数量会随着数字的生成而减少(在九个数字之后random(10) 是相当可预测的,即使只在八你有 50-50 的机会)。
【讨论】:
他使用“随机”的含义没有你那么严格。想象一下,他的应用程序是一次一个地填充网格中的一个单元格,直到每个单元格都被填满,以产生良好的视觉效果。一些细胞序列会产生规则的视觉模式。一个“随机”序列,在他似乎是这个意思的意义上,不会。【参考方案7】:您可能对线性反馈移位寄存器感兴趣。 我们曾经用硬件构建这些,但我也用软件完成了它们。它使用一个移位寄存器,其中一些位异或并反馈到输入,如果您选择正确的“抽头”,您可以获得与寄存器大小一样长的序列。也就是说,一个 16 位的 lfsr 可以产生一个 65535 长且没有重复的序列。它在统计上是随机的,但当然是可重复的。此外,如果做错了,你可能会得到一些令人尴尬的短序列。如果您查找 lfsr,您会发现如何正确构造它们的示例(即“最大长度”)。
【讨论】:
你知道在随机性方面这与线性同余 RNG 相比如何吗?投票支持你的算法。 对不起,不是数学家。我看不出它们之间有任何相似之处(尽管我本能地怀疑)。 最好不要尝试从头开始构建 RNG frmo。太多可能会出错。如果你已经有了一个不错的 RNG,你可以使用(在 Boost 左右)你应该使用它。几乎所有周期 = 模数的方法都会产生很多非重复数字,但无论如何这对你来说似乎没用 LFSR 是一种非常有效且简单的解决方案 - 但您必须选择合适的常量才能使其正常工作。网络上有资源可以帮助解决这个问题。【参考方案8】:我知道您不希望大范围的随机播放,因为您必须存储整个列表才能这样做。
改为使用可逆的伪随机哈希。然后依次输入值 0 1 2 3 4 5 6 等。
有无数这样的哈希值。如果它们被限制为 2 的幂,生成它们并不太难,但可以使用任何基础。
例如,如果您想遍历所有 2^32 32 位值,则可以使用以下方法。它最容易编写,因为在这种情况下,整数数学的隐式 mod 2^32 对您有利。
unsigned int reversableHash(unsigned int x)
x*=0xDEADBEEF;
x=x^(x>>17);
x*=0x01234567;
x+=0x88776655;
x=x^(x>>4);
x=x^(x>>9);
x*=0x91827363;
x=x^(x>>7);
x=x^(x>>11);
x=x^(x>>20);
x*=0x77773333;
return x;
【讨论】:
在这种情况下可逆是什么意思? 不知道,我期待“n == f(f(n))”,但事实并非如此。 这里的可逆意味着没有信息丢失。如果您有 y=f(x),则有一个反向函数 x=g(y)。这保证了您拥有一对一的映射,因此您的伪随机序列不会重复。【参考方案9】:如何使用 GUID 生成器(如 .NET 中的生成器)。当然,不能保证不会有重复,但是得到一个的机会非常低。
【讨论】:
据我所知,当前时间是 A GUID 生成的一部分。因此,数字之间肯定存在相关性。【参考方案10】:假设您有一个随机或伪随机数生成器,即使它不能保证返回唯一值,您也可以使用此代码实现每次都返回唯一值的生成器,假设上限保持不变(即您总是用random(10) 调用它,不要用random(10); random(11) 调用它。
代码不检查错误。如果您愿意,您可以自己添加。 如果您想要大范围的数字,它也需要大量内存。
/* the function returns a random number between 0 and max -1
* not necessarily unique
* I assume it's written
*/
int random(int max);
/* the function returns a unique random number between 0 and max - 1 */
int unique_random(int max)
static int *list = NULL; /* contains a list of numbers we haven't returned */
static int in_progress = 0; /* 0 --> we haven't started randomizing numbers
* 1 --> we have started randomizing numbers
*/
static int count;
static prev_max = 0;
// initialize the list
if (!in_progress || (prev_max != max))
if (list != NULL)
free(list);
list = malloc(sizeof(int) * max);
prev_max = max;
in_progress = 1;
count = max - 1;
int i;
for (i = max - 1; i >= 0; --i)
list[i] = i;
/* now choose one from the list */
int index = random(count);
int retval = list[index];
/* now we throw away the returned value.
* we do this by shortening the list by 1
* and replacing the element we returned with
* the highest remaining number
*/
swap(&list[index], &list[count]);
/* when the count reaches 0 we start over */
if (count == 0)
in_progress = 0;
free(list);
list = 0;
else /* reduce the counter by 1 */
count--;
/* swap two numbers */
void swap(int *x, int *y)
int temp = *x;
*x = *y;
*y = temp;
【讨论】:
【参考方案11】:如果您可以生成“小”随机数,则可以通过整合它们来生成“大”随机数:为每个“前一个”添加一个小的随机增量。
const size_t amount = 100; // a limited amount of random numbers
vector<long int> numbers;
numbers.reserve( amount );
const short int spread = 250; // about 250 between each random number
numbers.push_back( myrandom( spread ) );
for( int n = 0; n != amount; ++n )
const short int increment = myrandom( spread );
numbers.push_back( numbers.back() + increment );
myshuffle( numbers );
myrandom 和 myshuffle 函数我在此慷慨地委托给其他人:)
【讨论】:
【参考方案12】:以前有人问过这个问题 - 请参阅 my answer to the previous question。简而言之:您可以使用分组密码在您想要的任何范围内生成安全(随机)排列,而无需在任何时候存储整个排列。
【讨论】:
【参考方案13】:实际上,这里有一个小问题;不允许重复的随机数生成器不是随机的。
【讨论】:
【参考方案14】:如果您想创建没有重复的大(例如,64 位或更大)随机数,那么只需创建它们。如果您使用的是一个好的随机数生成器,它实际上有足够的熵,那么生成重复的几率非常小,不值得担心。
例如,在生成加密密钥时,实际上没有人会费心检查他们之前是否生成过相同的密钥;既然您相信您的随机数生成器,专门的攻击者将无法获得相同的密钥,那么您为什么会期望您会意外地想出相同的密钥呢?
当然,如果你有一个糟糕的随机数生成器(比如Debian SSL random number generator vulnerability),或者生成的数字足够小,以至于birthday paradox 给你带来了很高的冲突机会,那么你需要实际做一些事情来确保您不会重复。但是对于具有良好生成器的大随机数,只需相信概率不会给您任何重复。
【讨论】:
【参考方案15】:假设您想生成一系列 256 个不重复的随机数。
-
创建一个用零初始化的256位(32字节)内存块,我们称之为
b
您的循环变量将是 n,即尚未生成的数字数量
从n = 256 循环到n = 1
在[0, n)范围内生成一个随机数r
在你的内存块b中找到r-th零位,我们称之为p
将p 放入您的结果列表中,一个名为q 的数组
将内存块b中的p-th位翻转为1
n = 1 传递后,您就完成了数字列表的生成
这是我正在谈论的一个简短示例,最初使用 n = 4:
**Setup**
b = 0000
q = []
**First loop pass, where n = 4**
r = 2
p = 2
b = 0010
q = [2]
**Second loop pass, where n = 3**
r = 2
p = 3
b = 0011
q = [2, 3]
**Third loop pass, where n = 2**
r = 0
p = 0
b = 1011
q = [2, 3, 0]
** Fourth and final loop pass, where n = 1**
r = 0
p = 1
b = 1111
q = [2, 3, 0, 1]
【讨论】:
【参考方案16】:生成号码时,请使用Bloom filter 来检测重复号码。这将使用最少的内存。根本不需要存储系列中较早的数字。
权衡是您的列表在您的范围内无法详尽无遗。如果您的数字确实在 256^1024 的数量级上,那几乎没有任何折衷。
(当然,如果它们实际上是那种规模的随机数,那么即使费心检测重复项也是浪费时间。如果地球上的每台计算机都生成数万亿年每秒大小的数万亿个随机数,那么发生碰撞的机会仍然绝对可以忽略不计。)
【讨论】:
【参考方案17】:请查看答案
Generate sequence of integers in random order without constructing the whole list upfront
我的答案也在那里
very simple random is 1+((power(r,x)-1) mod p) will be from 1 to p for values of x from 1 to p and will be random where r and p are prime numbers and r <> p.
【讨论】:
【参考方案18】:我第二个 gbarry 关于使用 LFSR 的回答。即使在软件中,它们也非常高效且易于实现,并且保证不会在 (2^N - 1) 次使用中重复使用具有 N 位移位寄存器的 LFSR。
但也有一些缺点:通过观察 RNG 的少量输出,可以重建 LFSR 并预测它将生成的所有值,这使得它们无法用于密码学和任何需要良好 RNG 的地方。第二个问题是全零字或全一字(以位为单位)无效,具体取决于 LFSR 实现。与您的问题相关的第三个问题是 LFSR 生成的最大数量始终是 2 - 1 的幂(或 2 - 2 的幂)。
根据您的应用程序,第一个缺点可能不是问题。从您给出的示例中,您似乎不希望答案中出现零;因此,第二个问题似乎与您的情况无关。 最大值(以及范围)问题可以通过重复使用 LFSR 来解决,直到你得到一个范围内的数字。这是一个例子:
假设您想要 1 到 10 之间的数字(如您的示例所示)。您将使用范围为 [1, 15] 的 4 位 LFSR。这是关于如何获取 [1,10] 范围内数字的伪代码:
x = LFSR.getRandomNumber();
while (x > 10)
x = LFSR.getRandomNumber();
您应该将之前的代码嵌入到您的 RNG 中;这样调用者就不会关心实现。 请注意,如果您使用大型移位寄存器并且您想要的最大数字不是 2 - 1 的幂,这会减慢您的 RNG。
【讨论】:
【参考方案19】:我之前问过一个类似的问题,但我的问题是关于 int 的整个范围,请参阅Looking for a Hash Function /Ordered Int/ to /Shuffled Int/
【讨论】:
【参考方案20】:static std::unordered_set<long> s;
long l = 0;
for(; !l && (s.end() != s.find(l)); l = generator());
v.insert(l);
generator() 是你的随机数生成器。只要条目不在您的集合中,您就滚动数字,然后添加您在其中找到的内容。你明白了。
我为示例使用了 long,但如果您的 PRNG 是模板化的,您应该将其设为模板。
替代方法是使用加密安全的 PRNG,它生成两倍相同数字的概率非常低。
【讨论】:
【参考方案21】:如果您的意思不是生成序列的统计特性差,那么有一种方法:
假设您要生成 N 个数字,每个数字 1024 位。您可以牺牲一些生成的数字作为“计数器”。
所以你生成每个随机数,但是在你选择的一些位中放入二进制编码的计数器(从变量中,每次生成下一个随机数时你都会增加)。
您可以将该数字拆分为单个位,并将其放入生成数字的一些不太重要的位中。
这样您就可以确保每次都获得唯一编号。
我的意思是,例如,每个生成的数字看起来像这样: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxyyxxxxxxyxyyyyxxyxx 其中 x 直接取自生成器,ys 取自计数器变量。
【讨论】:
【参考方案22】:梅森龙卷风
可在 Wikipedia 上找到其描述:Mersenne twister
查看页面底部以了解各种语言的实现。
【讨论】:
【参考方案23】:问题是从范围 1..M 中选择 N 个唯一数字的“随机”序列,其中对 N 和 M 之间的关系没有限制(M 可以大得多,大致相同,甚至更小比 N;它们可能不是互质的)。
扩展线性反馈移位寄存器答案:对于给定的 M,为大于 M 的 2 的最小幂构造一个最大 LFSR。然后从 LFSR 中获取您的数字,丢弃大于 M 的数字。平均,您将最多丢弃一半生成的数字(因为通过构造超过一半的 LFSR 范围小于 M),因此获取数字的预期运行时间为 O(1)。您没有存储以前生成的数字,因此空间消耗也是 O(1)。如果您在获得 N 个数字之前循环,则 M 小于 N(或 LFSR 构造不正确)。
您可以在此处(来自***)找到最大长度为 168 位的 LFSR 的参数:http://www.xilinx.com/support/documentation/application_notes/xapp052.pdf
这是一些java代码:
/** * 在 [0,M) 中生成一系列唯一的“随机”数字 * @author dkoes * */
公共类 UniqueRandom 长 lfsr; 长面具; 长最大值;
private static long seed = 1;
//indexed by number of bits
private static int [][] taps =
null, // 0
null, // 1
null, // 2
3,2, //3
4,3,
5,3,
6,5,
7,6,
8,6,5,4,
9,5,
10,7,
11,9,
12,6,4,1,
13,4,3,1,
14,5,3,1,
15,14,
16,15,13,4,
17,14,
18,11,
19,6,2,1,
20,17,
21,19,
22,21,
23,18,
24,23,22,17,
25,22,
26,6,2,1,
27,5,2,1,
28,25,
29,27,
30,6,4,1,
31,28,
32,22,2,1,
33,20,
34,27,2,1,
35,33,
36,25,
37,5,4,3,2,1,
38,6,5,1,
39,35,
40,38,21,19,
41,38,
42,41,20,19,
43,42,38,37,
44,43,18,17,
45,44,42,41,
46,45,26,25,
47,42,
48,47,21,20,
49,40,
50,49,24,23,
51,50,36,35,
52,49,
53,52,38,37,
54,53,18,17,
55,31,
56,55,35,34,
57,50,
58,39,
59,58,38,37,
60,59,
61,60,46,45,
62,61,6,5,
63,62,
;
//m is upperbound; things break if it isn't positive
UniqueRandom(long m)
max = m;
lfsr = seed; //could easily pass a starting point instead
//figure out number of bits
int bits = 0;
long b = m;
while((b >>>= 1) != 0)
bits++;
bits++;
if(bits < 3)
bits = 3;
mask = 0;
for(int i = 0; i < taps[bits].length; i++)
mask |= (1L << (taps[bits][i]-1));
//return -1 if we've cycled
long next()
long ret = -1;
if(lfsr == 0)
return -1;
do
ret = lfsr;
//update lfsr - from wikipedia
long lsb = lfsr & 1;
lfsr >>>= 1;
if(lsb == 1)
lfsr ^= mask;
if(lfsr == seed)
lfsr = 0; //cycled, stick
ret--; //zero is stuck state, never generated so sub 1 to get it
while(ret >= max);
return ret;
【讨论】:
【参考方案24】:为了获得不重复的随机数并避免浪费时间检查双打数字并一遍又一遍地获取新数字,请使用以下方法,这将确保 Rand 的最低使用量: 例如,如果您想获得 100 个不重复的随机数: 1. 用 1 到 100 的数字填充数组 2. 使用 Rand 函数得到一个随机数,范围为(1-100) 3.使用生成的随机数作为索引从数组中获取第一个值(Numbers[IndexGeneratedFromRandFunction] 4.将该索引后的数组中的数字向左移动 5. 从第 2 步开始重复,但现在响铃应该是 (1-99) 并继续
【讨论】:
转移阻止了这个实现是 O(1)。【参考方案25】:这个答案提出了一些策略来获得你想要的东西,并使用一些众所周知的算法确保它们是随机顺序的。
Fisher-Yates shuffle 算法有一个由内而外的版本,称为 Durstenfeld 版本,它在加载数组或集合时将顺序获取的项目随机分配到数组和集合中。
要记住的一点是,加载时使用的 Fisher-Yates (AKA Knuth) shuffle 或 Durstenfeld 版本对对象数组非常有效,因为只有指向对象的引用指针被移动而对象本身不会作为算法的一部分,必须检查或与任何其他对象进行比较。
我将在下面进一步介绍这两种算法。
如果你想要非常大的随机数,大约 1024 字节或更多,一个非常好的随机生成器可以一次生成无符号字节或单词就足够了。随机生成尽可能多的字节或单词来构造数字,使其成为一个带有指向它的引用指针的对象,嘿,你有一个非常大的随机整数。如果您需要一个特定的非常大的范围,您可以将零字节的基值添加到字节序列的低位端以将值向上移动。这可能是您最好的选择。
如果您需要消除非常大的随机数的重复项,那就更棘手了。即使有非常大的随机数,删除重复项也会使它们有很大的偏差,而且根本不是随机的。如果您有一组非常大的不重复的非常大的随机数,并且您从尚未选择的随机数中随机选择,那么偏差只是为可供选择的非常大的数字集创建巨大值的偏差。 Durstenfeld 的 Yates-Fisher 版本的反向版本可用于从非常大的一组值中随机选择值,将它们从剩余值中删除,然后将它们插入到一个新数组中,该数组是一个子集并且可以执行这仅使用原位的源和目标阵列。这将非常有效。
这可能是一个很好的策略,它可以从一组非常大且不重复的随机数中获取具有巨大值的少量随机数。只需在源集中选择一个随机位置,获取它的值,将它的值与源集中的顶部元素交换,将源集的大小减一,然后用减小的源集重复,直到你选择了足够的值。这本质上是倒转的费舍尔-耶茨的 Durstenfeld 版本。然后,您可以使用 Dursenfeld 版本的 Fisher-Yates 算法将获取的值插入到目标集中。然而,这是矫枉过正,因为它们应该被随机选择和随机排序,如这里给出的。
这两种算法都假设你有一些随机数实例方法,nextInt(int setSize),它生成一个从零到 setSize 的随机整数,这意味着存在 setSize 可能的值。在这种情况下,它将是数组的大小,因为数组的最后一个索引是 size-1。
第一个算法是 Fisher-Yates(又名 Knuth)洗牌算法的 Durstenfeld 版本,适用于任意长度的数组,该算法简单地将整数从 0 到数组长度随机定位到数组中。该数组不必是整数数组,而是可以是顺序获取的任何对象的数组,这实际上使其成为引用指针数组。它简单、简短且非常有效
int size = someNumber;
int[] int array = new int[size]; // here is the array to load
int location; // this will get assigned a value before used
// i will also conveniently be the value to load, but any sequentially acquired
// object will work
for (int i = 0; i <= size; i++) // conveniently, i is also the value to load
// you can instance or acquire any object at this place in the algorithm to load
// by reference, into the array and use a pointer to it in place of j
int j = i; // in this example, j is trivially i
if (i == 0) // first integer goes into first location
array[i] = j; // this may get swapped from here later
else // subsequent integers go into random locations
// the next random location will be somewhere in the locations
// already used or a new one at the end
// here we get the next random location
// to preserve true randomness without a significant bias
// it is REALLY IMPORTANT that the newest value could be
// stored in the newest location, that is,
// location has to be able to randomly have the value i
int location = nextInt(i + 1); // a random value between 0 and i
// move the random location's value to the new location
array[i] = array[location];
array[location] = j; // put the new value into the random location
// end if...else
// end for
瞧,你现在已经有了一个随机数组。
如果你想随机打乱你已有的数组,这里是标准的 Fisher-Yates 算法。
type[] array = new type[size];
// some code that loads array...
// randomly pick an item anywhere in the current array segment,
// swap it with the top element in the current array segment,
// then shorten the array segment by 1
// just as with the Durstenfeld version above,
// it is REALLY IMPORTANT that an element could get
// swapped with itself to avoid any bias in the randomization
type temp; // this will get assigned a value before used
int location; // this will get assigned a value before used
for (int i = arrayLength -1 ; i > 0; i--)
int location = nextInt(i + 1);
temp = array[i];
array[i] = array[location];
array[location] = temp;
// end for
对于有序集合和集合,即某种类型的列表对象,您可以只使用带有索引值的添加/或插入,允许您在任何地方插入项目,但它必须允许在当前最后一个项目之后添加或附加到避免在随机化中产生偏差。
【讨论】:
【参考方案26】:这是一种随机而不重复结果的方法。它也适用于字符串。它在 C# 中,但 logig 应该在许多地方工作。将随机结果放入一个列表并检查新的随机元素是否在该列表中。如果不是,那么您有一个新的随机元素。如果它在那个列表中,重复随机直到你得到一个不在那个列表中的元素。
List<string> Erledigte = new List<string>();
private void Form1_Load(object sender, EventArgs e)
label1.Text = "";
listBox1.Items.Add("a");
listBox1.Items.Add("b");
listBox1.Items.Add("c");
listBox1.Items.Add("d");
listBox1.Items.Add("e");
private void button1_Click(object sender, EventArgs e)
Random rand = new Random();
int index=rand.Next(0, listBox1.Items.Count);
string rndString = listBox1.Items[index].ToString();
if (listBox1.Items.Count <= Erledigte.Count)
return;
else
if (Erledigte.Contains(rndString))
//MessageBox.Show("vorhanden");
while (Erledigte.Contains(rndString))
index = rand.Next(0, listBox1.Items.Count);
rndString = listBox1.Items[index].ToString();
Erledigte.Add(rndString);
label1.Text += rndString;
【讨论】:
【参考方案27】:现在我们有了一个不同数字的数组!
int main()
int b[(the number
if them)];
for (int i = 0; i < (the number of them); i++)
int a = rand() % (the number of them + 1) + 1;
int j = 0;
while (j < i)
if (a == b[j])
a = rand() % (the number of them + 1) + 1;
j = -1;
j++;
b[i] = a;
【讨论】:
【参考方案28】:对于随机序列,不应该有任何自相关。数字不应该重复的限制意味着下一个数字应该取决于所有以前的数字,这意味着它不再是随机的......
【讨论】:
以上是关于通过redis生成编码生成不重复的序列号的主要内容,如果未能解决你的问题,请参考以下文章