ChatGPT可以做WebRTC音视频质量性能优化,惊艳到我了
Posted ZEGO即构开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ChatGPT可以做WebRTC音视频质量性能优化,惊艳到我了相关的知识,希望对你有一定的参考价值。
摘要
随着GPT-4的发布,AI的风越吹越旺。GPT-4可以回答问题,可以写作,甚至可以基于一张草图生成html代码搭建一个网站。即构社区的一位开发者@倪同学就基于目前在研究的WebRTC QoS技术点对GPT-3.5跟GPT-4进行一场实验,ChatGPT会取代程序员还是成为最强辅助?
以下为@倪同学的博文。
ChatGPT取代程序员还是给程序员加Buff?
这两周,AI新闻一个接着一个,3月23日,Google开放了内测已久的AI对话服务Bard,Google强调,这是一款定位为用户提供创意之源的产品,可生成写作草稿或生活中的聊天机器人。早在一周前3月15日凌晨,OpenAI距发布GPT-3.5后四个月发布了升级版模型GPT-4,据发布会说,GPT-4可支持图片输入,角色扮演,写作能力更强了。紧接着3月16日百度发布了文心一言,一共有五大功能:文学创作、商业文案创作、数理逻辑推算、中文理解、多模态生成。
随着近日各大厂商AI产品的接连发布,AI取代人工这个话题持续在发酵。AI大幅解放人的生产力或是将冲击一大批职业?
博主近期在输出WebRTC相关的技术博客,不如向AI提问看他有什么见解。
和大部分人一样,博主都还没拿到Bard跟文心一言的内测资格。得知New Bing用的是GPT-4的模型,下面就着WebRTC通过哪些QoS技术提升音视频通话质量,向GPT-3.5和Newbing(GPT-4)分别提问,看看他们的答案有何差异。
如下图,技术科普类问题都难不倒GPT-3.5和GPT-4,我就该问题继续深挖让它们举实例说明:
New Bing(GPT-4)

GPT-3.5给出的结果

New Bing(GPT-4)直接给出了具体操作实例

GPT-3.5给出的结果(有些空泛)

GPT-4和GPT-3.5对比结论
通过实验,我们比较了同一问题两个版本的回答。在普通的文本处理当中,GPT-4和GPT-3.5的区别可能比较小,但是当问题足够具体和复杂时,GPT-4就会比GPT-3.5更精准、更有创意,而且能够处理用户更细微的指令。
当然,本篇内容不是要讨论GPT-3.5跟GPT-4的具体差别,而是程序员如何利用ChatGPT提升工作效率,加上最强Buff。以下我将以个人开发经验为音视频开发者分享《WebRTC的QoS如何提升音视频质量》。
WebRTC技术概述
WebRTC 通过一系列的QOS 技术来提升音视频通话质量: 抗丢包策略(NACK、 FEC), 拥塞控制策略(TWCC/REMB), SVC或多视轨, 视频质量自适应策略, Pacer、JitterBuffer等.
总体QOS架构如下图所示:
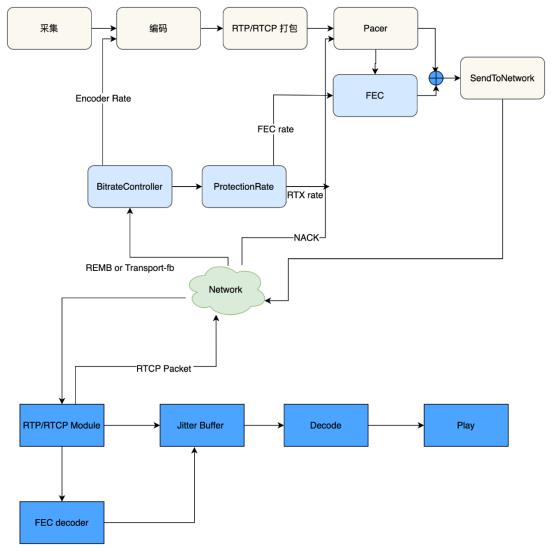
图 1
1 丢包恢复策略
1.1 NACK
NACK(Negative Acknowledgment)相较于ACK是通过"非到达确认"进行选择性重传的机制。基本原理是发送端对数据进行缓存,接收端通过到达包连续性检测丢包,结合rtt 和乱序情况在合适的时机向发送端发起重传请求。
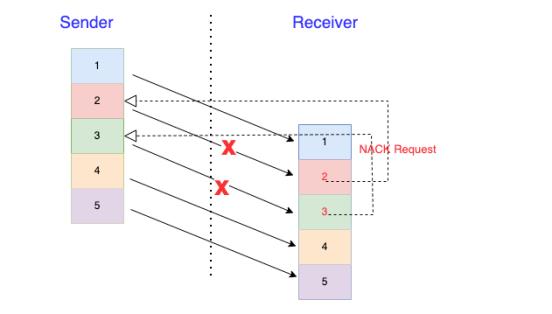
图 2
如图所示,Receiver在收到报文4之后发现报文2、3未到达,暂时将报文2、3放入丢失nack列表。在超过一定乱序阈值(通过乱序直方图计算得到,假设这里是2,那么收到包4可认为包2丢失),或者超过一定抖动时间(根据rtt计算),向Sender请求重传丢失的报文2、3。 Receiver的请求通过RTP FB 发送给Sender, 具体NACK 请求格式参考RFC4585。Sender 在收到NACK请求后重新发送报文2、3。
值得注意的是,NACK 策略丢包恢复效果取决于重传请求时机。一是rtt的计算(webrtc 默认rtt是100ms),一是乱序阈值计算。重传请求节奏控制不好容易造成重传风暴,加重拥塞导致拉流出现卡顿。
参考:https://www.rfc-editor.org/rfc/rfc4585.html#page-34
1.2 FEC
FEC(Forward Error Correction),前向纠错, 在数据传输和存储中普遍用于数据纠错。WebRTC中也使用了该技术进行丢包恢复。
webrtc实现该冗余功能,有三种方式:
1.2.1、RED
将前面的报文直接打入到新包里面,在接收端解析主包和冗余包。

图 3
如图,后面的报文直接包含前面报文,所以当其中某个报文丢失了,可以通过其相邻报文直接恢复。这种方式缺点是抗连续丢包效果差,但是实现简单。
Opus In-band FEC 正是使用这种方式进行纠错: 将重要信息以较低的比特率再次编码之后添加到后续数据包中,opsu 解码器根据收包情况决定是否利用当前包携带的冗余包进行丢包恢复。
Opus In-band FEC 详细参考:https://datatracker.ietf.org/doc/html/rfc6716#section-2.1.7
RED 详细介绍参考:https://www.rfc-editor.org/rfc/rfc2198.html
1.2.2、ULPFEC
在多个数据包之间使用 XOR 来生成此冗余信息,并能够在需要时在接收方恢复丢失的数据包。 ULPFEC 能够通过选择受保护的字节数并应用 XOR 的先前数据包的数量,为不同的数据包提供不同级别的保护。

图 4
如图,FEC packet 1 保护L0级报文A、B。 FEC packet 2 及保护L0级的A、B, 也保护L1级报文C、D。
参考:https://www.rfc-editor.org/rfc/rfc5109.html
1.2.3、FLEXFEC
较ULPFEC,FLEXFEC可以灵活选择1D行异或、列异或以及2D行列异或,增加网络抗丢包能力。
1-D 行异或纠错
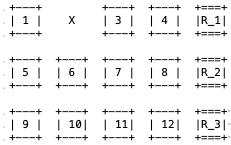
图 5
1-D 列异或纠错

图 6
2-D 行列异或纠错
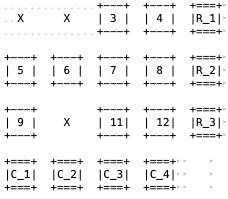
图 7
FLEXFEC 虽然相比前面两个有更强的恢复能力,行列交错丢包比如图7中(1、2、5、6)丢失就会出现无法纠错的情况。
WebRTC 用到FEC策略整体丢包恢复能力都偏弱,业界普遍应用Reed-Solomon FEC 进行丢包恢复,Reed-Solomon FEC(K + N : K个数据包 N个FEC包)可以真正恢复分组内任意 <=N 个丢包。
FLEXFEC 详细实现可以参考:https://www.rfc-editor.org/rfc/rfc8627.html
2 带宽评估及码率控制
2.1 REMB-GCC
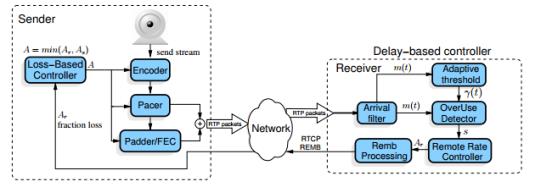
图 8
图8是REMB-GCC 架构图,基本思想是通过接收端评估带宽, 然后通过RTCP REMB 将带宽反馈给发送端。 发送端结合丢包率计算一个带宽结果As,和RMEB的结果Ar, 取min(As, Ar)作为最终带宽结果。
2.2 SendSide BWE
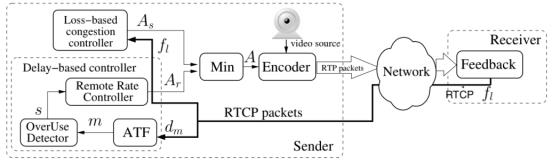
图 9
跟REMB-GCC 相比,TFB-GCC 主要区别在于大部分带宽计算都转移到发端计算,滤波器的实现不再用Kalman 滤波 而是变成TrendLine 滤波器。
发送端发送的包需在扩展头带: Transport-wide sequence number.
接收端定期发送Transport-wide feedback报文,通知发送端和接收端接收报文的相关信息,包括报文到达时间、报文到达时间、报文格式等信息。发送端收到Transport-wide feedback 报文之后,根据报文携带的信息进行延迟滤波计算(Trandline).
Transport-wide feedback 报文格式参考:https://datatracker.ietf.org/doc/html/draft-holmer-rmcat-transport-wide-cc-extensions-01
2.3 速率控制
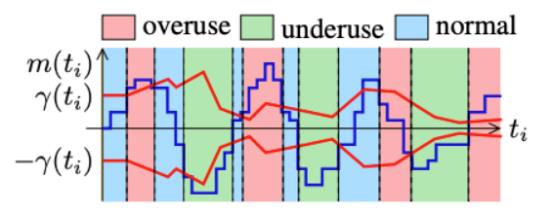
图 10
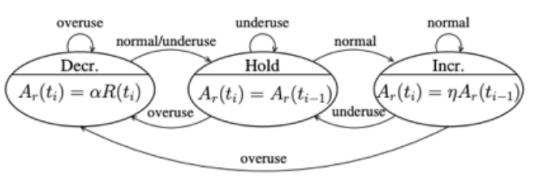
图 11
根据过载检测器产生的信号 s,驱动如图10所示的有限状态机来调整码率。
GCC 算法原理详细参考:https://c3lab.poliba.it/images/6/65/Gcc-analysis.pdf
3 SVC 、多视轨
3.1 SVC
SVC (Scalable Video Coding,可适性视频编码或可分级视频编码) 是传统 H.264/MPEG-4 AVC 编码的延伸,可提升更大的编码弹性,并具有时间可适性 (Temporal Scalability)、空间可适性 (Spatial Scalability) 及质量可适性 (SNR/Quality/Fidelity Scalability) 三大特性。
WebRTC 中h264 不支持svc 编码,Vp8 仅支持Temporal Scalability, VP9 和AV1 支持时间可适性 (Temporal Scalability)、空间可适性 (Spatial Scalability)。

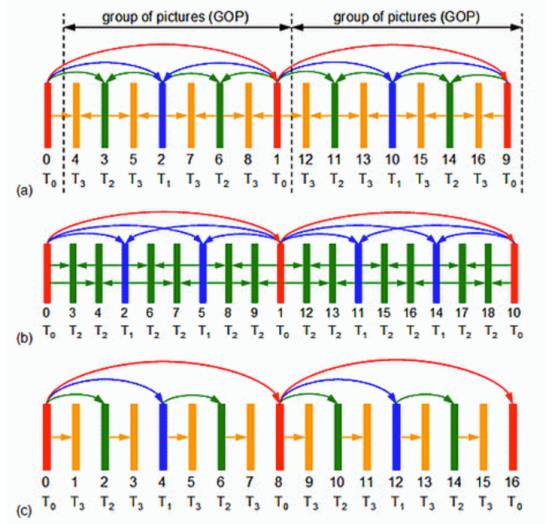
图12
上面是时间可适应示意图。假设图例中显示的图层以30 fps的帧速率显示。如果我们移除所有L2层的图片,剩下层(L0和L1)仍然可以成功解码,并且产生一个15fps的视频。如果我们进一步删除所有的L1图像,那么剩下的L0层依然可以被解码并产生一个7.5fps的视频, 所以即便是出现丢包,相比不可分级编码可明显提升弱网视频流畅度。

图 13
如图12,L0基层为分辨率最小编码数据,级别越高,分辨率越高。当实际应用中需要较低分辨率时,只需丢弃高Level层级数据进行解码。
针对不同的带宽条件用户和以及不同设备性能的用户可以灵活调整分辨。
SVC 扩展参考: http://ip.hhi.de/imagecom_G1/assets/pdfs/Overview_SVC_IEEE07.pdf
SVC 与 H264 结合参考: https://www.itu.int/rec/T-REC-H.264-201704-I
3.2 多视轨
目前主流浏览器都支持unified-plan sdp, 我们可以在sdp协商的时候添加多个视轨,业务上比较常见的就是添加两条视轨(类似于SVC的Spatial Scalability),复用相同DTLS 传输通道。

图 14
图12 典型利用WebRTC 支持多视轨特性编码一大一小两条流的出帧示意图。
支持多视轨(大小流) 可以让接收端在下行带宽受限的情况下动态切换到可以支持的分辨率,提升弱网体验。
多视轨(大小流)在对网络丢包及带宽受限情况的适应不如SVC 灵活,但是多视轨实现简单,编码、解码性能消耗较低,在实际的业务场景中得到广泛应用。
多视轨需要支持Unified Plan SDP 协商, 参考WebRTC 相关说明:https://webrtc.github.io/webrtc-org/web-apis/chrome/unified-plan/
4 视频质量调整策略
在网络传输质量变差(上行带宽不足)、CPU占有率过高,编码器编码质量QP值过大等情况下,WebRTC会通过降质量来保障视频通话。降质量策略主要分降帧率(即清晰优先模式)和降分辨率(即流畅优先模式),通过MediaStreamTrack Content Hints 来设置。
清晰优先模式 WebRTC 在编码的时候更注重视频细节,在出现上述情况需要降质量时,会通过降低帧率、保持分辨率不变来保障拉流用户的主观感受。对于推流端做屏幕分享内容是PPT或者拉流用户大屏显示的业务场景尤为重要。
流畅优先模式 推流端在需要降质量的时候优先降低分辨率、保持一定的帧率来保障拉流用户的流畅体验。
在带宽或CPU资源等不再受限时,WebRTC会根据降质量偏好设置逆向提升视频质量。
使用者应该根据自己的业务场景进行适当设置,才能在极端情况下保证主观体验不至于太差。
5 Pacer
WebRTC 的Pacer 模块主要是让需要发送的包根据评估的网络带宽尽量均匀的分布在每个发送时间窗口发出,起到平滑发包、避免网络拥塞的作用。
假设有一条 5Mbps 和 30fps 的视频流。 在理想情况下,每个帧大小约为 21kB,打包成 18 个 RTP 数据包。 按照一秒时间窗口统计的平均比特率是 5Mbps,但在更短的时间范围内,它可以被视为每 33 毫秒突发 167Mbps。 此外,视频编码器在突然移动的情况下会超过目标帧率,尤其是在处理屏幕共享时,帧比目标尺寸大 10 倍甚至 100 倍很常见。 这些数据包如果编码完成马上发出去会导致几个问题: 网络拥塞、缓冲区膨胀、甚至数据包丢失。 大多数会话都有不止一条媒体流,可能同时包含音频流、视频流、数据流。 如果你一次性将一个帧放在一条传输通道发送,这些数据包需要 100 毫秒才能发出,这可能阻止了任何音频数据包及时发送出去。 Pacer通过有一个缓冲区来解决这个问题。 媒体包在其中排队,然后使用漏桶算法将它们调整到网络上。 缓冲区包含所有媒体轨道的独立 fifo 流,例如 音频可以优先于视频 - 可以以循环方式发送相同优先级的流,以避免任何一个流阻塞其他流。
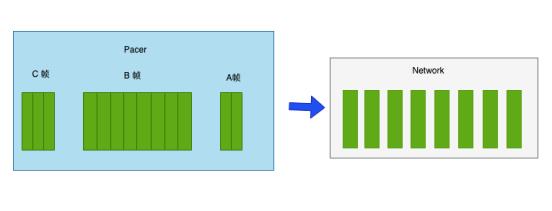
图 15
6 JitterBuffer
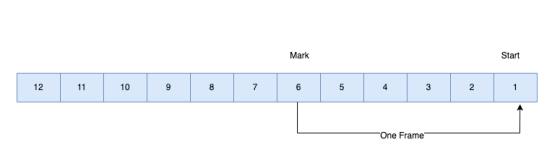
图 16
WebRTC 接收端收到RTP包后,放到PacketBuffer 进行缓存和排序。如上图,在收到Mark(帧结束)标志之后,从后往前开始组帧。组完一帧会放到该帧所在GOP的缓存里面,根据帧间参考顺序进行调整,当帧间参考关系建立好之后就会放到解码器进行解码。可以认为Jitter 主要先后做包排序、帧排序、GOP排序。之所以要进行着一系工作是因为网络本身存在一定的抖动、甚至有丢包,如果有丢包还得等丢包恢复才能完整组帧,所以导致帧到达时间跟发送时间存在一定抖动。Jitter buffer 的存在就很好的解决这个问题,能够在拉流端对待解码数据进行平滑处理,保证我们渲染出来视频是平滑、流畅的。
7 关键帧请求
视频流通常是以1个关键帧+ N个增量帧的方式发送,这些增量帧依赖于先前的帧进行解码和显示。如果因为一些原因导致sps/pps 丢失、 组包错误等,如果不采取任何补救措施,就很难继续解码视频流,视频就会卡主, 直到下个关键帧。很多时候为了编码稳定GOP设置很大,这个时候意味着长时间卡顿或者黑屏。
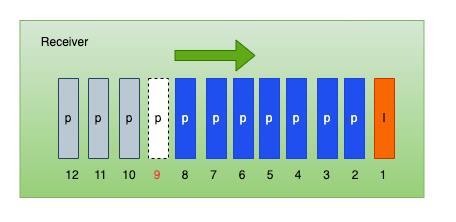
图 17
如图接收端因为丢包不能恢复导致Frame 9 组帧失败,后面即使能组帧成功也无法解码,此时需要从发送端请求一个I帧解码刷新当前视频流。
WebRTC通过RTCP报文向发送端请求发送关键帧,关键帧请求RTCP报文格式比较简单,在RFC4585(RTP/AVPF)以及RFC5104(AVPF)规定了两种不同的关键帧请求报文格式:Picture Loss Indication (PLI)、Full Intra Request (FIR)。从目前的实现看WebRTC 在收到PLI或者FIR之后,都是让编码器编码输出关键帧,然后发送给接收端。
PLI 报文格式参考: https://www.rfc-editor.org/rfc/rfc4585.html#page-36
FIR参考: https://www.rfc-editor.org/rfc/rfc5104.html
QOS技术总结:
本文简单介绍了WebRTC中所使用到的Qos技术,这些技术从不同的角度去提升Qos质量。包括通过NACK、FEC技术对丢包进行恢复,解决丢包导致的音、视频卡顿。通过带宽评估和拥塞控制技术调整编码和发送码率来自动适应网络带宽的变化情况。通过SVC、多视轨技术保障不同网络质量的拉流的用户差异的视频质量。 而Pacer、JitterBuffer分别在发送端和接收端提升音视频的平滑、流畅度。关键帧请求对极端网络抖动之后的快速视频恢复起了重要作用。WebRTC 利用这些技术协同作用,提升整体的Qos 质量,需要了解技术细节最好的方式还是去阅读WebRTC源码。
WebRTC 的Qos技术对提升整体音视频质量效果显著、但WebRTC的这些技术还是存在有很多可以优化的地方。音视频厂商ZEGO即构自研的WebRTC网关对这些策略都做了一定的优化:包括自研带宽评估算法、NACK算法、大小流等。
所以,如果你的业务需要一款稳定可靠的音视频服务,可以试试即构实时音视频RTC服务。
点击跳转ZEGO即构实时音视频服务了解更多WebRTC最佳实践内容。
线上分享WebRTC传输与服务质量
近几年,随着人们对音视频需求的增加,音视频实时通讯技术得到了迅猛发展。在音视频实时通信技术中,WebRTC无疑是最闪亮的一颗星。尤其是在WebRTC1.0规范加入到W3C和IETF标准之后,使得用户通过浏览器就可以非常方便的进行音视频实时通话了。然而上层的易用性,是WebRTC底层复杂实现换来的。为了保证音视频质量,WebRTC底层做了大量的工作,尤其是网络传输与服务质量更是其核心技术。
8月5日 19:30,我们邀请到了北京音视跳动科技有限公司 首席架构师 李超 和大家一同探讨WebRTC是如何平衡传输与服务质量之间的矛盾的。
【内容大纲】
1. WebRTC如何保障数据传输的实时性
2. WebRTC网络传输质量
3. 如何平衡传输与音视频服务质量之间的矛盾
除以上干货内容外,本次分享嘉宾还将会带来深入解析WebRTC开源音视频互动技术原理、架构,实战及源码分析的技术书籍《WebRTC音视频实时互动技术 — 原理、实战与源码分析》点击【阅读原文】试读书籍精彩内容,还可享受7.5折购书优惠!
# 参与收看直播还有机会免费抽取书籍 #
【参与方式】
LiveVideoStack 公众号内 回复 “分享”
即可获得加入直播群的方式

【嘉宾简介】
李超 北京音视跳动科技有限公司 首席架构师
《WebRTC音视频实时互动技术 — 原理、实战与源码分析》书籍作者,拥有 10 多年的音视频实时互动直播研发经验,多年的团队管理经验。曾经在全时云会议担任 “Tang” 平台研发经理,而后历任“跟谁学”团队直播研发高级经理,沪江网高级架构师,以及新东方音视频技术专家。

书籍深入浅出的对WebRTC进行了系统讲解,既有原理,又有实战,从WebRTC是如何实现实时音视频通信的,到如何应用WebRTC库实现音视频通信,再到WebRTC源码的剖析,逐步展开讲解。此外,本书对WebRTC的传输系统进行了重点分析,相信读者通过本书可以一窥WebRTC传输的奥秘。
本书第1~3章介绍了音视频实时通信的由来,WebRTC做了什么,以及它要解决什么问题;第4~10章是实战部分,介绍如何使用WebRTC库实现音视频通信,并对其实现原理进行讲解;第11~13章对WebRTC源码进行分析,让读者对WebRTC有更深层次的认知。
想了解WebRTC实现的专业开发人员可以通过本书了解WebRTC的运转机理,学生、老师和音视频爱好者可以通过本书了解WebRTC可以做什么,如何通过WebRTC实现音视频的实时通信。
以上是关于ChatGPT可以做WebRTC音视频质量性能优化,惊艳到我了的主要内容,如果未能解决你的问题,请参考以下文章