python怎样创建具有一定长度和初始值的列表
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python怎样创建具有一定长度和初始值的列表相关的知识,希望对你有一定的参考价值。
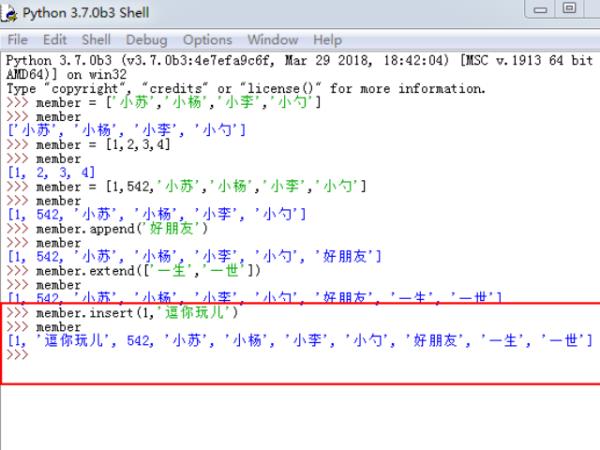
1、首先,我们需要打开Python的shell工具,在shell当中新建一个对象member,对member进行赋值。
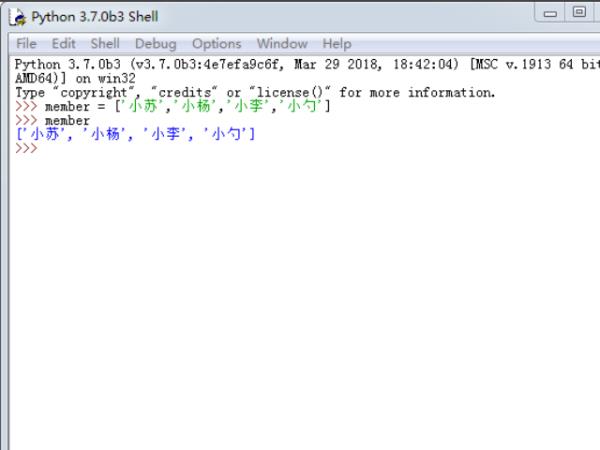
2、这里我们所创建的列表当中的元素均属于字符串类型,同时我们也可以在列表当中创建数字以及混合类型的元素。
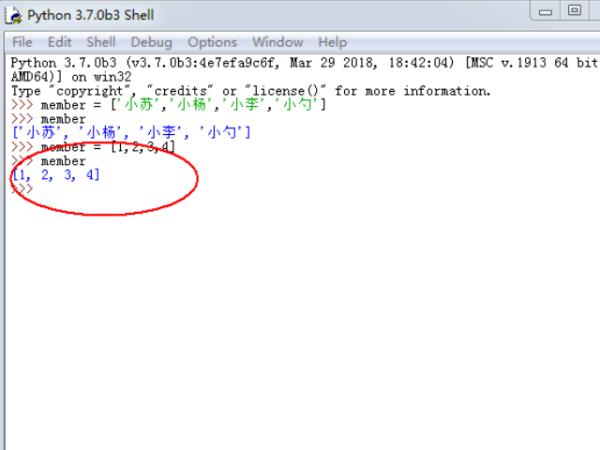
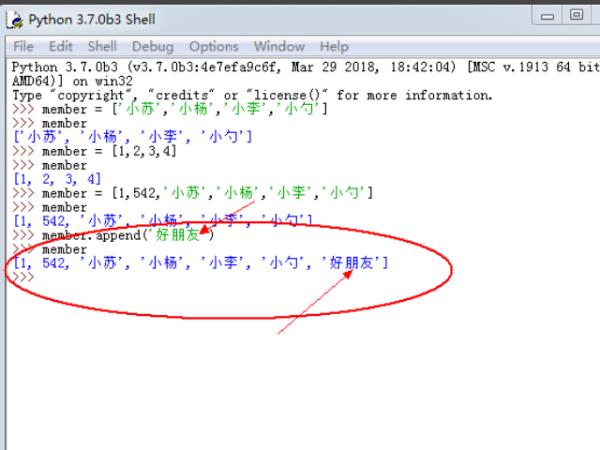
3、先来使用append函数对已经创建的列表添加元素,具体如下图所示,会自动在列表的最后的位置添加一个元素。
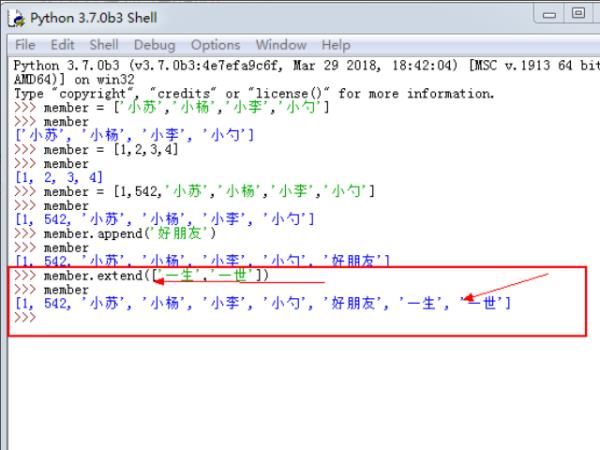
4、再来使用extend对来添加列表元素,如果是添加多个元素,需要使用列表的形式。
5、使用insert函数添加列表元素,insert中有两个参数,第一个参数即为插入的位置,第二个参数即为插入的元素。
创建所有元素初始值为None,长度为100的列表 参考技术B
python的数据是可以动态增长的,直接定义使用a=[]即可:
比如:a=[0,1,2],这时a[0]=0, a[1]=1, a[[2]=2;如果数组想a想定义为0到999,这时可能通过a = range(0, 1000)实现;或省略为a = range(1000);
如果想定义1000长度的a,初始值全为0,则 a = [0 for x in range(0, 1000)]
python的数组本来就是可以动态增长的。
a = []
这就是一个数组,你用append往里面塞数据就好
给定初值v,和长度l,定义list s

或者:

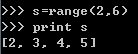
产生一个数值递增list
2.1 从0开始以1递增

在[a,b)区间上以1递增
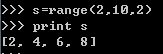
在[a,b)区间上以c递增
list的基本操作
[python] view plain copy
L.append(var) #追加元素
L.insert(index,var)
L.pop(var) #返回最后一个元素,并从list中删除之
L.remove(var) #删除第一次出现的该元素
L.count(var) #该元素在列表中出现的个数
L.index(var) #该元素的位置,无则抛异常
L.extend(list) #追加list,即合并list到L上
L.sort() #排序
L.reverse() #倒序
在 Python 中创建具有初始容量的列表
【中文标题】在 Python 中创建具有初始容量的列表【英文标题】:Create a list with initial capacity in Python 【发布时间】:2010-09-23 15:07:40 【问题描述】:这样的代码经常发生:
l = []
while foo:
# baz
l.append(bar)
# qux
如果您要向列表添加数千个元素,这真的很慢,因为必须不断调整列表的大小以适应新元素。
在 Java 中,您可以创建具有初始容量的 ArrayList。如果您知道您的列表有多大,这将更有效率。
我知道这样的代码通常可以重构为列表理解。但是,如果 for/while 循环非常复杂,这是不可行的。有没有适合我们 Python 程序员的等价物?
【问题讨论】:
据我所知,它们与 ArrayLists 类似,因为它们每次都将大小加倍。该操作的摊销时间是恒定的。它对性能的影响并没有您想象的那么大。 看来你是对的! 也许预初始化对于 OP 的场景来说并不是严格需要的,但有时它肯定是需要的:我有许多需要在特定索引处插入的预索引项,但它们出故障了。我需要提前增加列表以避免 IndexErrors。感谢您提出这个问题。 @Claudiu 接受的答案具有误导性。它下面最高支持的评论解释了原因。您会考虑接受其他答案之一吗? 如果 for/while 循环非常复杂,那么这是不可行的 -- 不一定。大多数复杂的循环体都是转换为函数的主要候选者,然后可以在列表推导中使用。这种做法倾向于通过抽象出复杂性来促进良好的设计。对于具有不明确或不确定终止条件的while 循环,itertools 和生成器可以在大部分时间将逻辑恢复到列表理解领域。
【参考方案1】:
Python 列表没有内置的预分配。如果您确实需要制作一个列表,并且需要避免追加的开销(并且您应该验证是否这样做),您可以这样做:
l = [None] * 1000 # Make a list of 1000 None's
for i in xrange(1000):
# baz
l[i] = bar
# qux
也许你可以通过使用生成器来避免列表:
def my_things():
while foo:
#baz
yield bar
#qux
for thing in my_things():
# do something with thing
这样,列表根本不会全部存储在内存中,只是根据需要生成。
【讨论】:
+1 生成器而不是列表。许多算法可以稍作修改以使用生成器而不是完全物化列表。 生成器是个好主意,真的。除了就地设置之外,我还想要一种通用的方法。我想差异很小,thoguh。【参考方案2】:据我了解,Python 列表已经与 ArrayLists 非常相似。但是如果你想调整那些参数我在网上发现了这个帖子可能很有趣(基本上,只需创建你自己的ScalableList 扩展):
http://mail.python.org/pipermail/python-list/2000-May/035082.html
【讨论】:
链接已损坏:“未找到。在此服务器上未找到请求的 URL /pipermail/python-list/2000-May/035082.html。” 【参考方案3】:警告:这个答案是有争议的。参见 cmets。
def doAppend( size=10000 ):
result = []
for i in range(size):
message= "some unique object %d" % ( i, )
result.append(message)
return result
def doAllocate( size=10000 ):
result=size*[None]
for i in range(size):
message= "some unique object %d" % ( i, )
result[i]= message
return result
结果。 (评估每个函数 144 次并平均持续时间)
simple append 0.0102
pre-allocate 0.0098
结论。没关系。
过早的优化是万恶之源。
【讨论】:
如果预分配方法(size*[None])本身效率低怎么办? python 虚拟机实际上是一次分配列表,还是像 append() 那样逐渐增加它? 嘿。它大概可以用 Python 表达,但还没有人在这里发布。 haridsv 的观点是我们只是假设'int * list' 不只是逐项附加到列表中。这个假设可能是正确的,但haridsv 的观点是我们应该检查一下。如果它无效,那就可以解释为什么您展示的两个功能花费几乎相同的时间 - 因为在幕后,它们正在做完全相同的事情,因此实际上并没有测试这个问题的主题。最好的问候! 这是无效的;您在每次迭代时都格式化一个字符串,这与您要测试的内容相比要花很长时间。此外,考虑到 4% 仍然可以根据具体情况显着,这是一个低估... @Philip 指出这里的结论具有误导性。预分配在这里无关紧要,因为字符串格式化操作很昂贵。我在循环中使用廉价操作进行了测试,发现预分配的速度几乎是原来的两倍。 许多赞成票的错误答案是万恶之源。【参考方案4】:我运行 S.Lott's code 并通过预分配产生了同样 10% 的性能提升。我尝试了Ned Batchelder's idea using a generator,并且能够看到生成器的性能优于 doAllocate。对于我的项目来说,10% 的改进很重要,所以感谢大家,因为这对我有很大帮助。
def doAppend(size=10000):
result = []
for i in range(size):
message = "some unique object %d" % ( i, )
result.append(message)
return result
def doAllocate(size=10000):
result = size*[None]
for i in range(size):
message = "some unique object %d" % ( i, )
result[i] = message
return result
def doGen(size=10000):
return list("some unique object %d" % ( i, ) for i in xrange(size))
size = 1000
@print_timing
def testAppend():
for i in xrange(size):
doAppend()
@print_timing
def testAlloc():
for i in xrange(size):
doAllocate()
@print_timing
def testGen():
for i in xrange(size):
doGen()
testAppend()
testAlloc()
testGen()
输出
testAppend took 14440.000ms
testAlloc took 13580.000ms
testGen took 13430.000ms
【讨论】:
“对于我的项目来说,10% 的改进很重要”?真的吗?您可以证明列表分配是瓶颈吗?我想了解更多。您是否有博客可以解释这实际上是如何提供帮助的? @S.Lott 尝试将大小增加一个数量级;性能下降了 3 个数量级(与 C++ 相比,性能下降了一个数量级以上)。 可能是这种情况,因为随着数组的增长,它可能必须在内存中移动。 (想想对象是如何一个接一个地存储在那里的。)【参考方案5】:短版:使用
pre_allocated_list = [None] * size
预先分配一个列表(也就是说,能够处理列表的“大小”元素,而不是通过附加来逐渐形成列表)。此操作非常快,即使在大列表上也是如此。分配稍后将分配给列表元素的新对象将花费更多更长的时间,并且在性能方面将成为您程序中的瓶颈。
长版:
我认为应该考虑初始化时间。
由于在 Python 中一切都是引用,所以无论您将每个元素设置为 None 还是某个字符串都无关紧要 - 无论哪种方式,它都只是一个引用。如果您想为每个要引用的元素创建一个新对象,则需要更长的时间。
对于 Python 3.2:
import time
import copy
def print_timing (func):
def wrapper (*arg):
t1 = time.time()
res = func (*arg)
t2 = time.time ()
print (" took ms".format (func.__name__, (t2 - t1) * 1000.0))
return res
return wrapper
@print_timing
def prealloc_array (size, init = None, cp = True, cpmethod = copy.deepcopy, cpargs = (), use_num = False):
result = [None] * size
if init is not None:
if cp:
for i in range (size):
result[i] = init
else:
if use_num:
for i in range (size):
result[i] = cpmethod (i)
else:
for i in range (size):
result[i] = cpmethod (cpargs)
return result
@print_timing
def prealloc_array_by_appending (size):
result = []
for i in range (size):
result.append (None)
return result
@print_timing
def prealloc_array_by_extending (size):
result = []
none_list = [None]
for i in range (size):
result.extend (none_list)
return result
def main ():
n = 1000000
x = prealloc_array_by_appending(n)
y = prealloc_array_by_extending(n)
a = prealloc_array(n, None)
b = prealloc_array(n, "content", True)
c = prealloc_array(n, "content", False, "some object ".format, ("blah"), False)
d = prealloc_array(n, "content", False, "some object ".format, None, True)
e = prealloc_array(n, "content", False, copy.deepcopy, "a", False)
f = prealloc_array(n, "content", False, copy.deepcopy, (), False)
g = prealloc_array(n, "content", False, copy.deepcopy, [], False)
print ("x[5] = ".format (x[5]))
print ("y[5] = ".format (y[5]))
print ("a[5] = ".format (a[5]))
print ("b[5] = ".format (b[5]))
print ("c[5] = ".format (c[5]))
print ("d[5] = ".format (d[5]))
print ("e[5] = ".format (e[5]))
print ("f[5] = ".format (f[5]))
print ("g[5] = ".format (g[5]))
if __name__ == '__main__':
main()
评价:
prealloc_array_by_appending took 118.00003051757812 ms
prealloc_array_by_extending took 102.99992561340332 ms
prealloc_array took 3.000020980834961 ms
prealloc_array took 49.00002479553223 ms
prealloc_array took 316.9999122619629 ms
prealloc_array took 473.00004959106445 ms
prealloc_array took 1677.9999732971191 ms
prealloc_array took 2729.999780654907 ms
prealloc_array took 3001.999855041504 ms
x[5] = None
y[5] = None
a[5] = None
b[5] = content
c[5] = some object blah
d[5] = some object 5
e[5] = a
f[5] = []
g[5] = ()
如您所见,只需对同一个 None 对象创建一个大的引用列表即可。
前置或扩展需要更长的时间(我没有平均任何东西,但运行几次后,我可以告诉你扩展和附加所花费的时间大致相同)。
为每个元素分配新对象——这是最耗时的。而S.Lott's answer 就是这样做的——每次都格式化一个新字符串。这不是严格要求的 - 如果您想预先分配一些空间,只需制作一个 None 列表,然后随意将数据分配给列表元素。无论哪种方式,生成数据都比追加/扩展列表花费更多的时间,无论是在创建列表时生成它,还是之后生成它。但是如果你想要一个人烟稀少的列表,那么从 None 列表开始肯定会更快。
【讨论】:
嗯,很有趣。所以答案很简单——你是否正在做任何操作将元素放入列表中并不重要,但如果你真的只是想要一个包含所有相同元素的大列表,你应该使用[]* 方法
除了不好玩之外,这在对列表完成时会产生有趣的行为(例如,预分配m * n 矩阵):x = 3 * [3 *[0]] 给出[[0, 0, 0], [0, 0, 0], [0, 0, 0]],但随后分配很不稳定:@987654330 @给[[1, 0, 0], [1, 0, 0], [1, 0, 0]]。
是的,因为x = 3 * [3 *[0]] 只分配了两个列表。有关该问题,请参阅this canonical post。【参考方案6】:
Pythonic 的方式是:
x = [None] * numElements
或您希望预填充的任何默认值,例如
bottles = [Beer()] * 99
sea = [Fish()] * many
vegetarianPizzas = [None] * peopleOrderingPizzaNotQuiche
(Caveat Emptor:[Beer()] * 99 语法创建 一个 Beer,然后用 99 个对同一单个实例的引用填充数组)
Python 的默认方法可能非常有效,尽管随着元素数量的增加,效率会下降。
比较
import time
class Timer(object):
def __enter__(self):
self.start = time.time()
return self
def __exit__(self, *args):
end = time.time()
secs = end - self.start
msecs = secs * 1000 # Millisecs
print('%fms' % msecs)
Elements = 100000
Iterations = 144
print('Elements: %d, Iterations: %d' % (Elements, Iterations))
def doAppend():
result = []
i = 0
while i < Elements:
result.append(i)
i += 1
def doAllocate():
result = [None] * Elements
i = 0
while i < Elements:
result[i] = i
i += 1
def doGenerator():
return list(i for i in range(Elements))
def test(name, fn):
print("%s: " % name, end="")
with Timer() as t:
x = 0
while x < Iterations:
fn()
x += 1
test('doAppend', doAppend)
test('doAllocate', doAllocate)
test('doGenerator', doGenerator)
与
#include <vector>
typedef std::vector<unsigned int> Vec;
static const unsigned int Elements = 100000;
static const unsigned int Iterations = 144;
void doAppend()
Vec v;
for (unsigned int i = 0; i < Elements; ++i)
v.push_back(i);
void doReserve()
Vec v;
v.reserve(Elements);
for (unsigned int i = 0; i < Elements; ++i)
v.push_back(i);
void doAllocate()
Vec v;
v.resize(Elements);
for (unsigned int i = 0; i < Elements; ++i)
v[i] = i;
#include <iostream>
#include <chrono>
using namespace std;
void test(const char* name, void(*fn)(void))
cout << name << ": ";
auto start = chrono::high_resolution_clock::now();
for (unsigned int i = 0; i < Iterations; ++i)
fn();
auto end = chrono::high_resolution_clock::now();
auto elapsed = end - start;
cout << chrono::duration<double, milli>(elapsed).count() << "ms\n";
int main()
cout << "Elements: " << Elements << ", Iterations: " << Iterations << '\n';
test("doAppend", doAppend);
test("doReserve", doReserve);
test("doAllocate", doAllocate);
在我的 Windows 7 Core i7 上,64 位 Python 提供
Elements: 100000, Iterations: 144
doAppend: 3587.204933ms
doAllocate: 2701.154947ms
doGenerator: 1721.098185ms
虽然 C++ 提供(使用 Microsoft Visual C++ 构建,64 位,已启用优化)
Elements: 100000, Iterations: 144
doAppend: 74.0042ms
doReserve: 27.0015ms
doAllocate: 5.0003ms
C++ 调试生成:
Elements: 100000, Iterations: 144
doAppend: 2166.12ms
doReserve: 2082.12ms
doAllocate: 273.016ms
这里的重点是,使用 Python,您可以实现 7-8% 的性能提升,并且如果您认为自己正在编写高性能应用程序(或者如果您正在编写用于 Web 服务或一些东西)那么这不是被嗤之以鼻的,但你可能需要重新考虑你选择的语言。
另外,这里的 Python 代码并不是真正的 Python 代码。在这里切换到真正的 Pythonesque 代码可以获得更好的性能:
import time
class Timer(object):
def __enter__(self):
self.start = time.time()
return self
def __exit__(self, *args):
end = time.time()
secs = end - self.start
msecs = secs * 1000 # millisecs
print('%fms' % msecs)
Elements = 100000
Iterations = 144
print('Elements: %d, Iterations: %d' % (Elements, Iterations))
def doAppend():
for x in range(Iterations):
result = []
for i in range(Elements):
result.append(i)
def doAllocate():
for x in range(Iterations):
result = [None] * Elements
for i in range(Elements):
result[i] = i
def doGenerator():
for x in range(Iterations):
result = list(i for i in range(Elements))
def test(name, fn):
print("%s: " % name, end="")
with Timer() as t:
fn()
test('doAppend', doAppend)
test('doAllocate', doAllocate)
test('doGenerator', doGenerator)
这给了
Elements: 100000, Iterations: 144
doAppend: 2153.122902ms
doAllocate: 1346.076965ms
doGenerator: 1614.092112ms
(在 32 位中,doGenerator 比 doAllocate 做得更好)。
这里 doAppend 和 doAllocate 之间的差距要大得多。
显然,这里的差异仅适用于您执行此操作的次数超过几次,或者您在负载重的系统上执行此操作时,这些数字将按数量级扩展,或者如果您正在处理更大的列表。
这里的重点:以 Python 式的方式实现最佳性能。
但是,如果您担心一般的高级性能,那么 Python 是错误的语言。最根本的问题是,由于装饰器等 Python 特性,Python 函数调用通常比其他语言慢 300 倍。(PythonSpeed/PerformanceTips, Data Aggregation)。
【讨论】:
@NilsvonBarth C++ 没有timeit
Python 有timeit,您应该在对 Python 代码进行计时时使用它;显然,我不是在谈论 C++。
这不是正确的答案。 bottles = [Beer()] * 99 不会创建 99 个 Beer 对象。相反,创建一个包含 99 个引用的 Beer 对象。如果您对其进行变异,则列表中的所有元素都将发生变异,因为每个i != j. 0<= i, j <= 99 都会导致(bottles[i] is bootles[j]) == True。
@erhesto 你判断答案不正确,因为作者以参考文献为例来填写列表?首先,没有人需要创建 99 个 Beer 对象(相对于一个对象和 99 个引用)。在预填充的情况下(他所说的),越快越好,因为稍后将替换该值。其次,答案根本与引用或突变无关。你错过了大局。
@YongweiWu 你说得对。这个例子并没有使整个答案不正确,它可能只是具有误导性,值得一提。【参考方案7】:
如果您使用的是NumPy,那么您会担心 Python 中的预分配问题,因为它有更多类似 C 的数组。在这种情况下,预分配问题与数据的形状和默认值有关。
如果您要对海量列表进行数值计算并希望获得性能,请考虑使用 NumPy。
【讨论】:
【参考方案8】:对于某些应用程序,字典可能就是您要查找的内容。例如,在 find_totient 方法中,我发现使用字典更方便,因为我没有零索引。
def totient(n):
totient = 0
if n == 1:
totient = 1
else:
for i in range(1, n):
if math.gcd(i, n) == 1:
totient += 1
return totient
def find_totients(max):
totients = dict()
for i in range(1,max+1):
totients[i] = totient(i)
print('Totients:')
for i in range(1,max+1):
print(i,totients[i])
这个问题也可以通过预先分配的列表来解决:
def find_totients(max):
totients = None*(max+1)
for i in range(1,max+1):
totients[i] = totient(i)
print('Totients:')
for i in range(1,max+1):
print(i,totients[i])
我觉得这不是那么优雅并且容易出现错误,因为我存储了 None 如果我不小心错误地使用它们可能会引发异常,并且因为我需要考虑地图让我避免的边缘情况。
确实字典不会那么高效,但正如其他人评论的那样,小的速度差异并不总是值得重大维护风险。
【讨论】:
【参考方案9】:正如其他人所提到的,预置列表的最简单方法是使用 NoneType 对象。
话虽如此,在决定是否有必要之前,您应该了解 Python 列表的实际工作方式。
在列表的CPython 实现中,底层数组总是在创建时留有额外空间,大小逐渐变大( 4, 8, 16, 25, 35, 46, 58, 72, 88, 106, 126, 148, 173, 201, 233, 269, 309, 354, 405, 462, 526, 598, 679, 771, 874, 990, 1120, etc),因此调整列表大小几乎不会经常发生。
由于这种行为,大多数 list.append() 函数的附加复杂度为 O(1),只有在跨越这些边界之一时复杂度才会增加,此时复杂度将为 O(n)。这种行为导致S.Lott's answer 中的执行时间增加最少。
来源:Python list implementation
【讨论】:
以上是关于python怎样创建具有一定长度和初始值的列表的主要内容,如果未能解决你的问题,请参考以下文章