集合和泛型
Posted 猪八戒1.0
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了集合和泛型相关的知识,希望对你有一定的参考价值。
目录
1.3.1 LinkedList 与 Comparator 结合使用
1.1集合框架
1.1.1为什么要使用集合框架
之前我们学习过数组,知道了数组可以存储多个数据类型相同的元素,但面对频繁增加、删除、修改元素的要求以及动态扩容要求时显得捉襟见肘。为此,JDK 提供了一套 “集合” 框架,这套框架是对常见数据结构的实现,不仅可存储数据,还提供了丰富的访问和处理数据的操作。在面向对象思想里,数据结构也被认为是一个容器,所以集合、容器等词汇经常被交替使用。
Java 集合框架支持两种类型的容器:一种是为了存储一个元素集合,简称为集合(collection);另一种是为了存储键/值对,称为映射(map,或称图)。
使用数组存放多个 对象的信息会存在很多问题,首先,Java 语言中的数组长度是固定的,旦创建出指定长度的数组以后,就给内存分配了相应的存储空间如果数组长度设置大了,又会造成空间浪费,删除数组元素全部要前移一位,但这种元素的移动是比较消耗系统资源的。
1.1.2单值集合的顶层接口:Collection 家族
集合框架可以分为 Collection 和 Map 两类,现在开始学习 Collection。Collection 是一个顶层接口,一些 Collection 接口的实现类允许有重复的元素,而另一些则不允许;一些 Collection 是有序的,而另一些则是无序的。
JDK 不提供 Collection 接口的任何直接实现类,而是提供了更具体的子接口,如 Set 接口和 List 接口。这些子接口继承 Collection 接口的方法,然后再对 Collection 接口从不同角度进行重写或扩充。
Collection 接口主要有三个子接口,分别是 Set 接口、List 接口和 Queue 接口,下面简要介绍这三个接口。
-
Set 接口
Set 实例用于存储一组不重复的,无序的元素。
-
List 接口
List 实例是一个有序集合。程序员可对 List 中每个元素的位置进行精确控制,可以根据索引来访问元素,此外 List 中的元素是可以重复的。
-
Queue 接口
Queue 中的元素遵循先进先出的规则,是对数据结构 “队列” 的实现。
1.1.3键值映射集合的顶层接口:Map 家族
Map 接口定义了存储和操作一组 “键(key)值(value)” 映射对的方法。
Map 接口和 Collection 接口的本质区别在于,Collection 接口里存放的是一系列单值对象,而 Map 接口里存放的是一系列 key-value 对象。Map 中的 key 不能重复,每个 key 最多只能映射到一个值。HashMap ,Hashtable 和TreeMap 是 Map 接口的实现类。
1.2Set 接口
1.2.1HashSet 类的使用
Set 接口是 Collection 的子接口。Set 接口中的元素是不能重复的、无序的,这里的 “无序” 是指向 Set 中输入的元素,与从 Set 中输出元素的顺序是不一致的。
例如,向 Set 接口中依次增加 “北京”、“深圳” 和 “西安” 三个元素,但输出顺序却是 “西安”、“北京”和“深圳” 。对于开发者而言,只需要了解这一 “无序” 的特性即可,不必深究其原因。
下面列出了 Set 接口继承自 Collection 接口的主要方法。
-
boolean add(Object obj)向集合中添加一个 obj 元素,并且 obj 不能和集合中现有数据元素重复,添加成功后返回 true。如果添加的是重复元素,则添加操作无效,并返回 false。
-
void clear()移除此集合中的所有数据元素,即将集合清空。
-
boolean contains(Object obj)判断此集合中是否包含 obj,如果包含,则返回 true。
-
boolean isEmpty()判断集合是否为空,为空则返回 true。
-
Iterator iterator()返回一个 Iterator 对象,可用它来遍历集合中的数据元素。
-
boolean remove(Object obj)如果此集合中包含 obj,则将其删除,并返回 true。
-
int size()返回集合中真实存放数据元素的个数,注意与数组、字符串获取长度的方法的区别。
-
Object[] toArray()返回一个数组,该数组包含集合中的所有数据元素。
本实验主要学习了 Set 接口和 HashSet 类的使用:
- Set 接口的特性:无重复,无序。
- Set 接口下继承父接口的方法。
- Set 接口的实现类 HashSet 的使用:
- 通过 HashSet 无参构造器创建 Set 对象。
- 使用了 add()、contains()、remove()、size() 等常用的方法对集合元素进行操作。
import java.util.HashSet;
import java.util.Set;
/**
* HashSet 类的使用
*/
public class TestSet
public static void main(String[] args)
//创建一个HashSet对象,存放学生姓名信息
Set nameSet = new HashSet();
nameSet.add("王云");
nameSet.add("刘静涛");
nameSet.add("南天华");
nameSet.add("雷静");
nameSet.add("王云"); //增加已有的数据元素
System.out.println("再次添加王云是否成功:" + nameSet.add("王云"));
System.out.println("显示集合内容:" + nameSet);
System.out.println("集合里是否包含南天华:" + nameSet.contains("南天华"));
System.out.println("从集合中删除\\"南天华\\"...");
nameSet.remove("南天华");
System.out.println("集合里是否包含南天华:" + nameSet.contains("南天华"));
System.out.println("集合中的元素个数为:" + nameSet.size());
1.2.2HashSet 类无重复特性体现
HashSet 实现类的使用还是挺简单的,上一个实验中我们提到了 Set 接口的特性是无序无重复。对吧!
那么需要思考一个问题:HashSet 是如何判断元素重复的?如果逐个比较 HashSet 中的全部元素,显然是一种效率低下的做法。因此 HashSet 的底层引入了 hashcode。
hashcode 最初定义在 Object 类中,如果两个对象相等,那么这两个对象的 hashcode 值相同,因此根据逆否定理可知如果两个对象的 hashcode 值不同,那么这两个对象不相等。但反之,如果两个对象的 hashcode 值相同,则这两个对象可能相等,也可能不等,需要再通过 equals() 方法进一步比较这两个对象的内容是否相同。
当向 HashSet 中增加元素时,HashSet 会先计算此元素的 hashcode,如果 hashcode 值与 HashSet 集合中的其他元素的 hashcode 值都不相同,那么就能断定此元素是唯一的。否则,如果 hashcode 值与 HashSet 集合中的某个元素的 hashcode 值相同,HashSet 就会继续调用 equals() 方法进一步判断它们的内容是否相同,如果相同就忽略这个新增的元素,如果不同就把它增加到 HashSet 中。
因此,在实际开发中,当使用 HashSet 存放某个自定义对象时,就得先在这个对象的定义类中重写 hashCode() 和 equals() 方法。hashcode 值是对象的映射地址,而 equals() 用于比较两个对象,判断 2 个元素的地址是否相等。在重写时,hashCode() 方法需要自定义 “映射地址” 的映射规则,equals() 方法需要自定义对象的 “比较” 规则。一般而言,映射规则和比较规则都需要借助于对象的所有属性进行计算。
实际上,如何在 hashCode() 方法中设计计算公式是一个数学问题,我们不必深究。计算公式的目的是为了 “尽可能的避免不同对象计算出的 hash 值相同” ,普通开发者通常只需在 hashCode() 方法中使用全部的属性值进行计算即可。例如,也可以将上面程序中的 hashCode() 方法重写为以下的简易形式。
@Override
public int hashCode()
return name.hashCode() & oil;
总结:
在向 HashSet 集合中增加元素时,会先计算此元素的 hashcode 值,如果 HashSet 集合中没有此 hashcode 值,那么此元素就可以插入。如果 hashcode 值与 HashSet 集合中的某个元素的 hashcode 值相同,HashSet 就会继续调用 euqals() 方法进一步判断它们的内容是否相同,如果相同就忽略这个新增的元素,如果不同才能把它增加到 HashSet 集合中。
1.2.3TreeSet 类的使用
TreeSet 类在实现了 Set 接口的同时,也实现了 SortedSet 接口,是一个具有排序功能的 Set 接口实现类。
TreeSet 集合中的元素默认是按照自然升序排列,并且 TreeSet 集合中的对象需要实现 Comparable 接口。Comparable 接口用于比较集合中各个元素的大小,常用于排序操作。
import java.util.Set;
import java.util.TreeSet;
public class TestTreeSet
public static void main(String[] args)
Set ts = new TreeSet();
ts.add("王云");
ts.add("刘静涛");
ts.add("南天华");
System.out.println(ts);
从运行结果可以看出,TreeSet 集合 ts 里面的元素不是毫无规律的排序,而是按照自然升序(这里是指 “字典” 里的顺序)进行了排序。这是因为 TreeSet 集合中的元素是 String 类,而 String 类实现了 Comparable 接口。但如果 TreeSet 中的元素不是 String 类,如何进行排序呢?后面 “比较器” 实验中会为大家进行讲解。
1.2.3.1使用 TreeSet 生成数组
- toArray() 方法,把集合中的所有数据提取到一个新的数组中。
import java.util.Random;
import java.util.TreeSet;
/**
* 使用 TreeSet 生成数组
*/
public class RandomSortArray
public static void main(String[] args)
// 创建 TreeSet 对象
TreeSet set = new TreeSet();
// 创建 Random 对象
Random ran =new Random();
int count =0;
while(count<10)
// 提取 0 - 99 的随机数加入到集合中
boolean succeed = set.add(ran.nextInt(100));
if(succeed)
count ++;
int size = set.size();
// 创建整型数组
Integer[] array = new Integer[size];
// 将集合元素转换为数组元素
set.toArray(array);
System.out.print("生成不重复随机数组内容如下:");
for(int value : array)
System.out.print(value + " ");
1.2.4内部比较器 Comparable 接口
JDK 提供了 Comparable 和 Comparator 两个接口,都可以用于定义集合元素的排序规则。如果程序员想定义自己的排序方式,一种简单的方法就是让加入 TreeSet 集合中的对象所属的类实现 Comparable 接口,通过实现 compareTo(Object o) 方法,达到排序的目的。
假设有这样的需求,学生对象有两个属性,分别是学号和姓名。希望将这些学生对象加入 TreeSet 集合后,按照学号从小到大进行排序,如果学号相同再按照姓名自然排序。来看 Student 类需要实现 Comparable 接 口。
/**
* 学生类实现 Comparable 接口
*/
public class Student implements Comparable
// 学生学号
int stuNum = -1;
// 学生姓名
String stuName = "";
Student(String name, int num)
this.stuNum = num;
this.stuName = name;
// 返回该对象的字符串表示,利于输出
public String toString()
return "学号为:" + stuNum + " 的学生,姓名为:" + stuName;
// 实现 Comparable 的 compareTo() 方法
public int compareTo(Object o)
Student input = (Student) o;
// 此学生对象的学号和指定学生对象的学号比较
// 此学生对象学号若大则res为1,若小则res为-1,相同的话res = 0
int res = stuNum > input.stuNum ? 1 : (stuNum == input.stuNum ? 0 : -1);
// 若学号相同,则按照String类自然排序比较学生姓名 因为String 类实现了 Comparable 接口
if (res == 0)
res = stuName.compareTo(input.stuName);
return res;
import java.util.Set;
import java.util.TreeSet;
/**
* 测试类
*/
class TestComparable
public static void main(String[] args)
//用有序的 TreeSet 存储学生对象
Set stuTS = new TreeSet();
stuTS.add(new Student("王云", 1));
stuTS.add(new Student("南天华", 3));
stuTS.add(new Student("刘静涛", 2));
stuTS.add(new Student("张平", 3));
//循环输出
for(Object stu : stuTS)
System.out.println(stu);

1.3 List 接口
List 是 Collection 接口的子接口,List 中的元素是有序的,而且可以重复。List 集合中的数据元素都对应一个整数形式的序号索引,记录其在集合中的位置,可以根据此序号存取元素。JDK 中常用的 List 实现类是 ArrayList 和 LinkedList。
List 接口继承自 Collection 接口,除了拥有 Collection 接口所拥有的方法外,还拥有下列方法:
-
void add(int index,Object o)在集合的指定 index 位置处,插入指定的 o 元素。
-
Object get(int index)返回集合中 index 位置的数据元素。
-
int indexOf(Object o)返回此集合中第一次出现的指定 o 元素的索引,如果此集合不包含 o 元素,则返回-1。
-
int lastIndexOf(Object o)返回此集合中最后出现的指定
o元素的索引,如果此集合不包含o元素,则返回-1。 -
Object remove(int index)移除集合中 index 位置的数据元素。
-
Object set(int index,Object o)用指定的 o 元素替换集合中 index 位置的数据元素。
ArrayList 实现了 List 接口,其底层采用的数据结构是数组。另一个 List 接口的实现类是 LinkedList,它在存储方式上采用链表进行链式存储。
根据数据结构的知识可知,数组(顺序表)在插入或删除数据元素时,需要批量移动数据元素,故性能较差;但在根据索引获取数据元素时,因为数组是连续存储的,所以在遍历元素或随机访问元素时效率高。
那么本实验需要学习的 ArrayList 实现类的底层就是数组,因此 ArrayList 实现类更加适合根据索引访问元素的操作。
假设车辆管理有如下需求:
- 用户可以按照车辆入库的顺序查阅车辆信息。
- 所有车辆有连续的编号,当用户输入车辆的编号后系统显示车辆完整信息。
/**
* 自定义车辆信息类
*/
public class Vehicle
private String name;
private int oil;
public Vehicle()
public Vehicle(String name, int oil)
this.name = name;
this.oil = oil;
public String getName()
return name;
public void setName(String name)
this.name = name;
public int getOil()
return oil;
public void setOil(int oil)
this.oil = oil;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
/**
* ArrayList 类的基本使用
*/
public class TestArrayList
public static void main(String[] args)
Scanner input = new Scanner(System.in);
// 创建 ArrayList 集合,用于存放车辆
List vehAL = new ArrayList();
Vehicle c1 = new Car("战神","长城");
Vehicle c2 = new Car("跑得快","红旗");
Vehicle t1 = new Truck("大力士","5吨");
Vehicle t2 = new Truck("大力士二代","10吨");
// 将 c1 添加到 vehAL 集合的末尾
vehAL.add(c1);
vehAL.add(c2);
vehAL.add(t1);
vehAL.add(t2);
System.out.println("*** 显示全部车辆 ***");
// 用于显示序号
int num = 1;
// 增强for循环遍历
for(Object obj:vehAL)
if(obj instanceof Car)
Car car = (Car)obj;
System.out.println(num + " 该车是轿车,其车名为:" + car.getName());
else
Truck truck = (Truck)obj;
System.out.println(num + " 该车是卡车,其车名为:" + truck.getName());
num++;
System.out.print("请输入要显示车名的车辆编号:");
String name = ((Vehicle)vehAL.get(input.nextInt()-1)).getName();
System.out.println("车辆名称为:"+name);
//轿车类
class Car extends Vehicle
//品牌
private String brand = "红旗";
//构造方法,指定车名和品牌
public Car(String name, String brand)
super(name, 20);
this.brand = brand;
//获取品牌
public String getBrand()
return brand;
//卡车类
class Truck extends Vehicle
// 吨位
private String load = "10吨";
//构造方法,指定车名和品牌
public Truck(String name, String load)
super(name, 20);
this.load = load;
//获取吨位
public String getLoad()
return load;

1.3.1 LinkedList 与 Comparator 结合使用
本实验将学习 LinkedList 与 Comparator 结合使用。LinkedList,它在存储方式上采用链表进行链式存储;而 Comparator 是外部比较器。
LinkedList 的底层是链表。LinkedList 和 ArrayList 在应用层面类似,只是底层存储结构上的差异导致了二者对于不同操作,存在性能上的差异。这其实就是顺序表和链表之间的差异。一般而言,对于 “索引访问” 较多的集合操作建议使用 ArrayList 实现类,而对于 “增删” 较多的集合操作建议使用 LinkedList 实现类。
LinkedList 实现类除了拥有 ArrayList 实现类提供的方法外,还增加了如下一些方法:
-
void addFirst(Object o)将指定数据元素插入此集合的开头。
-
void addLast(Object o)将指定数据元素插入此集合的结尾。
-
Object getFirst()返回此集合的第一个数据元素。
-
Object getLast()返回此集合的最后一个数据元素。
-
Object removeFirst()移除并返回此集合的第一个数据元素。
-
Object removeLast()移除并返回此集合的最后一个数据元素。
Comparator 可以理解为一个专用的比较器,当集合中的对象不支持自比较或者自比较的功能不能满足程序员的需求时,就可以写一个实现 Comparator 接口的比较器来完成两个对象之间的比较,从而实现按比较器规则进行排序的功能。
例如,要比较的对象是 JDK 中内置的某个类,而这个类又没有实现 Comparable 接口,因此我们是无法直接修改 JDK 内置类的源码的,因此就不能通过重写 compareTo(Object o) 方法来定义排序规则了,而应该使用 Comparator 接口实现比较器功能。
接下来,在外部定义一个姓名比较器和一个学号比较器,然后在使用 Collections 工具类的 sort(List list, Comparator c) 方法时选择使用其中一种外部比较器,对集合里的学生信息按姓名、学号分别排序输出。
import java.util.Collections;
import java.util.Comparator;
import java.util.LinkedList;
/**
* LinkedList 与 Comparator 结合使用
*/
public class TestLinkedList
public static void main(String[] args)
//用LinkedList存储学生对象
LinkedList stuLL = new LinkedList();
stuLL.add(new Student("王云",1));
stuLL.add(new Student("南天华",3));
stuLL.add(new Student("刘静涛",2));
//使用sort方法,按姓名比较器进行排序
Collections.sort(stuLL,new NameComparator());
System.out.println("*** 按学生姓名顺序输出学生信息 ***");
for (Object object : stuLL)
System.out.println(object);
//使用sort方法,按学号比较器进行排序
Collections.sort(stuLL,new NumComparator());
System.out.println("*** 按学生学号顺序输出学生信息 ***");
for (Object object : stuLL)
System.out.println(object);
// 定义学生对象,未实现Comparable接口
class Student
int stuNum = -1;
String stuName = "";
Student(String name, int num)
this.stuNum = num;
this.stuName = name;
@Override
public String toString()
return "学号为:" + stuNum + " 的学生,姓名为:" + stuName;
//定义一个姓名比较器
class NameComparator implements Comparator
//实现Comparator接口的compare()方法
public int compare(Object op1, Object op2)
Student eOp1 = (Student)op1;
Student eOp2 = (Student)op2;
//通过调用String类的compareTo()方法进行比较
return eOp1.stuName.compareTo(eOp2.stuName);
//定义一个学号比较器
class NumComparator implements Comparator
//实现Comparator接口的compare()方法
public int compare(Object op1, Object op2)
Student eOp1 = (Student)op1;
Student eOp2 = (Student)op2;
return eOp1.stuNum - eOp2.stuNum;
1.4泛型
1.4.1泛型的基本使用
首先说明,在初级阶段,为了快速的掌握泛型的用法,本节只讲解 “使用泛型限制集合元素类型” 这一个核心内容,其余较为深入的泛型知识暂不做介绍。
在之前使用集合的时候,装入集合的各种类型的元素都被当作 Object 对待,而非元素自身的类型。因此从集合中取出某个元素时,就需要进行类型转换,这种做法效率低下且容易出错。
🤔 那么如何解决这个问题呢?可以使用泛型。
泛型是指在定义集合的同时也定义集合中元素的类型,需要 “< >” 进行指定,其语法形式如下:
集合<数据类型> 引用名 = new 集合实现类<数据类型> ();⭐ 注意:使用泛型约束的数据类型必须是对象类型,而不能是基本数据类型。
以下代码就限制了 List 集合中只能存放 String 类型的元素。
List<String> list = new ArrayList<String>();在 JDK1.7 之后,= 右边 < > 中的的 String 等类型也可以省略,也可以写成以下的等价形式:
List<String> list = new ArrayList<>();在定义集合的同时使用泛型,用 “< >” 进行指定集合中元素的类型后,再从集合中取出某个元素时,就不需要进行类型转换,不仅可以提高程序的效率,也让程序更加清晰明了,易于理解。
1.5 Iterator 迭代器
1.5.1Iterator 接口的使用
前面学习的 Collection 接口、Set 接口和 List 接口,它们的实现类都没有提供遍历集合元素的方法。
Iterator 接口为遍历集合而生,是 Java 语言解决集合遍历的一个工具。
iterator() 方法定义在 Collection 接口中,因此所有单值集合的实现类,都可以通过 iterator() 方法实现遍历。iterator() 方法返回值是 Iterator 对象,通过 Iterator 接口的 hasNext() 和 next() 方法即可实现对集合元素的遍历。
下面是 Iterator 接口的三个方法:
-
boolean hasNext()判断是否存在下一个可访问的数据元素。
-
Object next()返回要访问的下一个数据元素,通常和 hasNext() 在一起使用。
-
void remove()从迭代器指向的 Collection 集合中移除迭代器返回的上一个数据元素。
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
/**
* 使用迭代器遍历集合数据
*/
public class TestIterator
public static void main(String[] args)
// 创建 HashSet 集合,用于存放车辆
Set<Vehicle> vehSet = new HashSet<>();
// 创建两个轿车对象、两个卡车对象,并加入 HashSet 集合中
Vehicle c1 = new Car("战神", "长城");
Vehicle c2 = new Car("跑得快", "红旗");
Vehicle t1 = new Truck("大力士", "5吨");
Vehicle t2 = new Truck("大力士二代", "10吨");
vehSet.add(c1);
vehSet.add(c2);
vehSet.add(t1);
vehSet.add(t2);
// 使用迭代器循环输出
Iterator<Vehicle> it = vehSet.iterator();
System.out.println("*** 显示集合中元素信息 ***");
while (it.hasNext())
Vehicle vehicle = it.next();
if (vehicle instanceof Car)
Car car = (Car) vehicle;
//调用 Car 类的特有方法 getBrand()
System.out.println("该车是轿车,其品牌为:" + car.getBrand());
else
Truck truck = (Truck) vehicle;
//调用 Truck 类的特有方法 getLoad()
System.out.println("该车是卡车,其吨位为:" + truck.getLoad());
System.out.println("车辆名称:" + vehicle.getName());
// 集合元素分隔显式
System.out.println("--------------------------");
/**
* 自定义车辆信息类
*/
public class Vehicle
private String name;
private int oil;
public Vehicle()
public Vehicle(String name, int oil)
this.name = name;
this.oil = oil;
public String getName()
return name;
public void setName(String name)
this.name = name;
public int getOil()
return oil;
public void setOil(int oil)
this.oil = oil;
//轿车类
class Car extends Vehicle
//品牌
private String brand = "红旗";
//构造方法,指定车名和品牌
public Car(String name, String brand)
super(name, 20);
this.brand = brand;
//获取品牌
public String getBrand()
return brand;
//卡车类
class Truck extends Vehicle
// 吨位
private String load = "10吨";
//构造方法,指定车名和品牌
public Truck(String name, String load)
super(name, 20);
this.load = load;
//获取吨位
public String getLoad()
return load;
1.5.2使用 Iterator 显示数据信息
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
public class DataShowIterator
public static void main(String[] args)
Set<Integer> treeSet = new TreeSet<Integer>();
int[] a = 12, 45, 23, 86, 100, 78, 546, 1, 45, 99, 136, 23;
for (int i = 0; i < 12; i++)
treeSet.add(a[i]);
Iterator<Integer> it = treeSet.iterator();
while (it.hasNext())
System.out.println(it.next());
1.6 Map 接口
1.6.1HashMap 类的使用
Map 接口,用于保存具有映射关系的键值对数据。
Map<K,V> 接口中的 key 和 value 可以是任何引用类型的数据,key 不允许重复原因和 HashSet 一样,value 可以重复,key 和 value 都可以是 null 值,但需要注意的是,key 为 null 只能有一个,value 为 null 可以多个,它们之间存在单向一对一关系,也就是说通过指定存在的 key 一定找到对应的 value 值。
Map 接口的常用方法如下:
-
Object put(Object key,Object value)将指定键值对(key 和 value)添加到 Map 集合中,如果此 Map 集合以前包含一个该键 key 的键值对,则用参数 key 和 value 替换旧值。
-
Object get(Object key)返回指定键 key 所对应的值,如果此 Map 集合中不包含该键 key,则返回 null。
-
Object remove(Object key)如果存在指定键 key 的键值对,则将该键值对从此 Map 集合中移除。
-
Set keySet()返回此 Map 集合中包含的键的 Set 集合。在上面的程序最后添加下面的语句:
System.out. println(domains.keySet());,则会输出[com, edu, org, net]。 -
Collection values()返回此 Map 集合中包含的值的 Collection 集合。在上面的程序最后添加下面的语句:
System.out.println(domains.values());,则会输出[工商企业,教研机构,非营利组织,网络服务商]。 -
boolean containsKey(Object key)如果此 Map 集合包含指定键 key 的键值对,则返回 true。
-
boolean containsValue(Object value)如果此 Map 集合将一个或多个键映射到指定值,则返回 true。
-
int size()返回此 Map 集合的键值对的个数。
Map 接口常用的实现类有 HashMap 和 Hashtable,本实验主要讲 HashMap 类的使用。
import java.util.HashMap;
import java.util.Map;
/**
* HashMap 类的基本使用
*/
public class TestHashMap
public static void main(String[] args)
// 使用 HashMap 存储域名和含义键值对的集合
Map<String, String> domains = new HashMap<>();
domains.put("com", "工商企业");
domains.put("net", "网络服务商");
domains.put("org", "非营利组织");
domains.put("edu", "教研机构");
domains.put("gov", "政府部门");
// 通过键获取值
System.out.println("edu国际域名对应的含义为:" + domains.get("edu"));
// 判断是否包含某个键
System.out.println("domains键值对集合中是否包含gov:" + domains.containsKey("gov"));
// 删除键值对
domains.remove("gov");
System.out.println("删除后集合中是否包含gov:" + domains.containsKey("gov"));
// 输出全部键值对
System.out.println(domains);
1.6.2 Map 映射数据的遍历
我们已经掌握了遍历 Collection 的通用方法—使用增强 for 或者迭代器 Iterator,并且知道 Collection 是单值形式元素的集合,而 Map 是键值对形式的元素集合。
因此就能推测出,遍历 Map 的方法就是:先将 Map 集合或 Map 集合的部分元素转换成单值集合的形式,然后使用增强 for 或者迭代器 Iterator 遍历即可。
简单来说就是:Map --> 转换为单值集合 --> 使用增强 for 或者迭代器 Iterator 遍历。
我们可以将 Map 中的 key 全部提取出来,遍历 key,然后再根据 key 获取 value,如以下程序所示。
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
/**
* 采用 Iterator 方式遍历 Map 数据
*/
public class TestMap
public static void main(String[] args)
Map<String, String> map = new HashMap<>();
map.put("k1", "v1");
map.put("k2", "v2");
map.put("k3", "v3");
//将Map中的key全部提取出来
Set<String> keys = map.keySet();
System.out.println("使用迭代器遍历");
Iterator<String> keyIter = keys.iterator();
while (keyIter.hasNext())
//获取map的每个key
String key = keyIter.next();
//根据key获取对应的value
String value = map.get(key);
System.out.println(key + "," + value);
System.out.println("使用增强for遍历");
for (String key : keys)
//根据key获取对应的value
String value = map.get(key);
System.out.println(key + "," + value);
另一种方式遍历:Map 中的每一组 key-value 对称为一个 entry 对象,即 entry = key + value。Map 接口提供了获取 Map 中全部 entry 对象的方法,因此就可以先获取全部的 entry 对象,然后再提取 entry 对象中的 key 和 value。
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* 采用 Map.Entry 方式遍历 Map 数据
*/
public class TestMap2
public static void main(String[] args)
Map<String, String> map = new HashMap<>();
map.put("k1", "v1");
map.put("k2", "v2");
map.put("k3", "v3");
//获取 Map 的全部 entry 对象
Set<Map.Entry<String, String>> entries = map.entrySet();
//遍历 entry 集合
for (Map.Entry<String, String> entry : entries)
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "," + value);
控制台录入一个字符串,程序经过统计最后输出这个字符串中每个字母出现的次数。

import java.util.*;
public class Statistics
static HashMap<Character, Integer> hashMap = new HashMap<>();
public Map statis(String str)
// 判断 map里面是否存过key=c的键
//有则 查找其value并且加1; 再存进map里面
for (char c:str.toCharArray())
if(hashMap.containsKey(c))
int value=hashMap.get(c);
value++;
hashMap.put(c,value);
else
hashMap.put(c,1);
return hashMap;
public static void main(String[] args)
Scanner input = new Scanner(System.in);
System.out.println("请输入一个字符串:");
String str=input.next();
//将非字母的字符去掉
String str1 = str.replaceAll("[^a-zA-Z]", "");
Statistics statistics = new Statistics();
statistics.statis(str1);
Set<Character> set=hashMap.keySet();
for (char c:set)
int value=hashMap.get(c);
System.out.println(c+"="+value);
1.7工具类
1.7.1Collections 工具类的使用
Collections 工具类,是集合对象的工具类,类中方法都是静态的,可以直接以 类名.静态方法() 的形式调用。
该类提供了操作集合的工具方法,如排序、复制、反转和查找等方法,如下所示:
-
void sort(List list)根据数据元素的排序规则对 List 集合进行排序,其中的排序规则是通过内部比较器设置的。例如 List 中存放的是 obj 对象,那么排序规则就是根据 obj 所属类重写内部比较器 Comparable 中的 compareTo() 方法定义的。
-
void sort(List list, Comparator c)根据指定比较器中的规则对 List 集合进行排序。通过自定义 Comparator 比较器 c,可以实现按程序员定义的规则进行排序。
-
void shuffle(List list)对指定 List 集合进行随机排序。
-
void reverse(List list)反转 List 集合中数据元素的顺序。
-
Object max(Collection coll)根据数据元素的自然顺序,返回给定 coll 集合中的最大元素。该方法的输入类型为 Collection 接口,而非 List 接口,因为求集合中最大元素不需要集合是有序的。
-
Object min(Collection coll)根据数据元素的自然顺序,返回给定 coll 集合的最小元素。
-
int binarySearch(List list,Object o)使用二分查找法查找 list 集合,以获得 o 数据元素的索引。如果此集合中不包含 o 元素,则返回-1。在进行此调用之前,必须根据 list 集合数据元素的自然顺序对集合进行升序排序(通过 sort(List list) 方法)。如果没有对 list 集合进行排序,则结果是不确定的。如果 list 集合中包含多个元素 “等于” 指定的 o 元素,则无法保证找到的是哪一个,这里说的 “等于” 是指通过 equals() 方法判断相等的元素。
-
int indexOfSubList(List source,List target)返回指定源集合 source 中第一次出现指定目标集合 target 的起始位置,换句话说,如果 target 是 source 的一个子集合,那么该方法返回 target 在 source 中第一次出现的位置。如果没有出现这种集合间的包含关系,则返回 -1。
-
int lastIndexOfSubList(List source,List target)返回指定源集合 source 中最后一次出现指定目标集合 target 的起始位置,如果没有出现这样的集合,则返回 -1。
-
void copy(List dest,List src)将所有数据元素从 src 集合复制到 dest 集合。
-
void fill(List list,Object o)使用 o 数据元素替换 list 集合中的所有数据元素。
-
boolean replaceAll(List list,Object old,Object new)使用一个指定的 new 元素替换 list 集合中出现的所有指定的 old 元素。
-
void swap(List list,int i,int j)在 list 集合中,交换 i 位置和 j 位置的元素。
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class TestCollections
public static void main(String[] args)
List list = new ArrayList();
list.add("w");
list.add("o");
list.add("r");
list.add("l");
list.add("d");
System.out.println("排序前: " + list);
System.out.println("该集合中的最大值:" + Collections.max(list));
System.out.println("该集合中的最小值:" + Collections.min(list));
Collections.sort(list);
System.out.println("sort排序后: " + list);
//使用二分查找,查找前须保证被查找集合是自然有序排列的
System.out.println("r在集合中的索引为: " + Collections.binarySearch(list, "r"));
Collections.shuffle(list);
System.out.println("再shuffle排序后: " + list);
Collections.reverse(list);
System.out.println("再reverse排序后: " + list);
Collections.swap(list, 1, 4);
System.out.println("索引为1、4的元素交换后:" + list);
Collections.replaceAll(list, "w", "d");
System.out.println("把w都换成d后的结果: " + list);
Collections.fill(list, "s");
System.out.println("全部填充为s后的结果: " + list);
-
主要使用了 sort()、shuffle()、reverse()、max()、min()、binarySearch()、fill()、replaceAll()、swap() 方法。
-
该工具类可以方便的完成对集合数据的一系列操作
1.7.2 Arrays 工具类的使用
Arrays 类是操作数组的工具类,和 Collections 工具类相似,Arrays 类主要有以下功能:
- 对数组进行排序。
- 给数组赋值。
- 比较数组中元素的值是否相等。
- 进行二分查找。
import java.util.Arrays;
/**
* Arrays 工具类的使用
*/
public class TestArrays
public static void output(int[] a)
for (int num : a)
System.out.print(num + " ");
System.out.println();
public static void main(String[] args)
int[] array = new int[5];
//填充数组
Arrays.fill(array, 8);
System.out.println("填充数组Arrays.fill(array,8):");
TestArrays.output(array);
//将数组索引为1到4的元素赋值为6
Arrays.fill(array, 1, 4, 6);
System.out.println("将数组索引为1到4的元素赋值为6 Arrays.fill(array, 1, 4, 6):");
TestArrays.output(array);
int[] array1 = 12, 9, 21, 43, 15, 6, 19, 77, 18;
//对数组索引为3到7的元素进行排序
System.out.println("排序前,数组的序列为:");
TestArrays.output(array1);
Arrays.sort(array1, 3, 7);
System.out.println("对数组索引为3到7的元素进行排序:Arrays.sort(array1,3,7):");
TestArrays.output(array1);
//对数组进行自然排序
Arrays.sort(array1);
System.out.println("对数组进行自然排序 Arrays.sort(array1):");
TestArrays.output(array1);
//比较数组元素是否相等
int[] array2 = array1.clone();
System.out.println("数组克隆后是否相等:Arrays.equals(array1, array2):" +
Arrays.equals(array1, array2));
//使用二分查找法查找元素下标(数组必须是排好序的)
System.out.println("77在数组中的索引:Arrays.binarySearch(array1, 77):"
+ Arrays.binarySearch(array1, 77));

综合案例
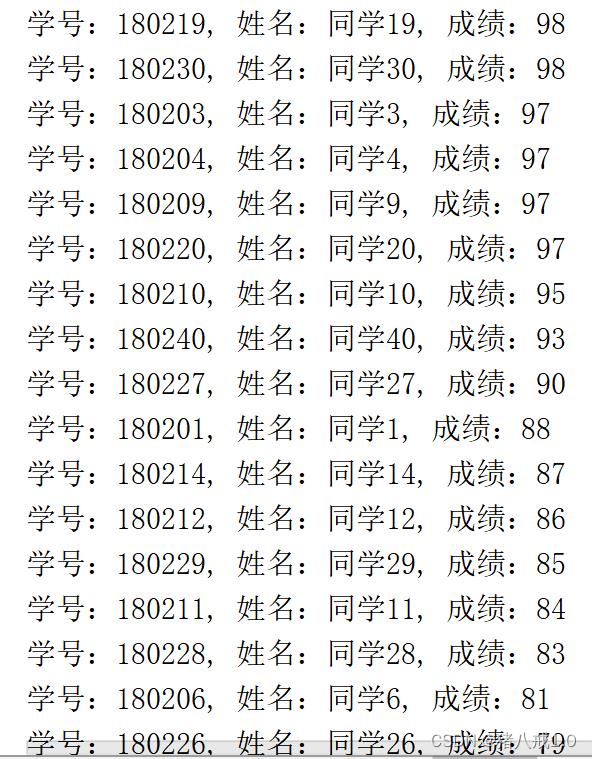
某班有 40 个学生,学号为 180201-180240, 全部参加 Java 集合阶段检测,给出所有同学的成绩 (可随机产生,范围为 50-100),请编写程序将本班 各位同学成绩从高往低排序打印输出。
注:成绩相同时学号较小的优先打印。
package entity;
public class Student
public int id;
String name;
public int score;
@Override
public String toString()
return "学号:" + id + ", 姓名:" + name + ", 成绩:" + score;
public Student()
public Student(int id, String name, int score)
this.id = id;
this.name = name;
this.score = score;
public int getId()
return id;
public void setId(int id)
this.id = id;
public String getName()
return name;
public void setName(String name)
this.name = name;
public int getScore()
return score;
public void setScore(int score)
this.score = score;
package main;
import entity.Student;
import java.util.*;
public class Results
public static List<Student> data = new ArrayList<Student>();
public void initData()
Random random = new Random();
int k;
for (int i = 0; i < 40; i++)
k = i + 1;
Student student = new Student(180201 + i, ("J" + k), (random.nextInt(50) + 50));
data.add(student);
public void adjust()
Collections.sort(data, new GradeComparator());
public void print()
for (int i = 0; i < data.size(); i++)
Student s = data.get(i);
System.out.println(s);
//定义一个成绩比较器
static class GradeComparator implements Comparator
@Override
public int compare(Object o1, Object o2)
Student O1 = (Student) o1;
Student O2 = (Student) o2;
if(O2.score == O1.score)
return O1.id-O2.id;
return O2.score - O1.score;
public static void main(String[] args)
Results results = new Results();
results.initData();
results.adjust();
results.print();
以上是关于集合和泛型的主要内容,如果未能解决你的问题,请参考以下文章