mybaits-plus笔记
Posted 敲代码的xiaolang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mybaits-plus笔记相关的知识,希望对你有一定的参考价值。
目录
- 前言
- 1. 入门项目
-
- 1.1 数据库
- 1.2 项目构建
- 2. 配置日志
- 3. CURD基本用法
-
- 3.1 插入操作
- 3.2 更新操作
- 3.3 删除操作
- 3.4 查询操作
- 4. ActiveRecord
-
- 4.1 插入操作
- 4.2 更新操作
- 4.3 删除操作
- 4.4 查询操作
- 5. 表和列
-
- 5.1 主键类型
- 5.2 指定表名
- 5.3 指定列名
- 6. 自定义sql
- 7. 查询和分页
-
- 7.1 查询
- 7.2 分页
- 8. 代码生成器
前言
在学习mybatis-plus这篇文章时
需要掌握一些知识点
以及
- Spring框架从入门到学精(全)
- SpringMVC从入门到精通(全)
- springboot从入门到精通(全)
- Mybatis从入门到精通(全)
- Maven详细配置(全)
- Maven实战从入门到精通(全)
- java中lambda表达式
这篇文章的学习知识点汇总主要通过该链接
MyBatis plus实战视频教程-带你快速掌握MyBatis-plus
主要的代码学习
可通过如下进行获取
mybatis_plus学习代码从入门到精通.rar
- mybatis是直接执行sql语句,sql语句写在xml文件中,使用mybatis需
要多个xml配置文件,在一定程度上比较繁琐。一般数据库的操作都要涉及到
CURD - mybatis-plus是在mybatis上的增强,减少了xml的配置,几乎不用编写xml
就可以做到单表的CURD,极大提供了开发的效率。而且提供了各种查询功能和分页行为
1. 入门项目
具体的步骤为
- 创建工程,添加依赖
- 创建实体类,定义属性,定义主键类型
- 创建dao接口,继承BaseMapper实体类
- 在启动类中加入扫描dao接口的包
在测试类中或者service注入dao接口,实现动态代理创建dao的实现类对象
调用BaseMapper中的方法,完成数据库的添加操作
1.1 数据库
先创建数据库文件
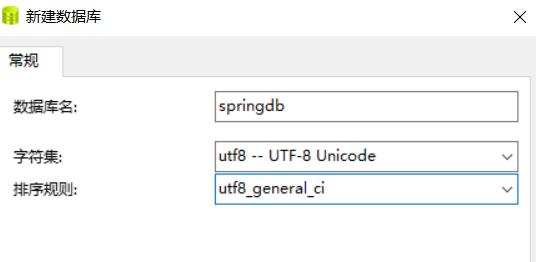
创建一个表
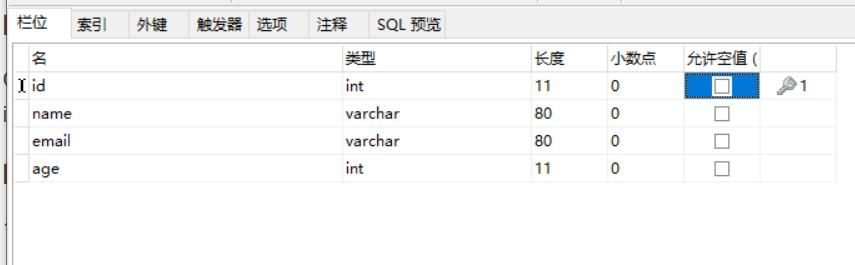
记得数据库的主键要设置一个自增的功能
不然会出现这种bug
出现Field ‘id‘ doesn‘t have a default value; nested exception is java.sql.SQLException的解决方法
在代码连接数据库中
代码要设置连接的端口账号密码以及数据库依赖文件等
先创建一个项目
在代码中创建连接数据库的配置文件
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/springdb?useUnicode=true&characterEncoding=utf-8
username: root
password: 123456
需要额外引入mybatis-plus的依赖文件
<!-- mybatis-plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
以及数据库的依赖文件
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
<version>5.1.6</version>
</dependency>
此处数据库的相关部分就到这里
1.2 项目构建
接下来是构建一个实体类
实体类的名字要和数据库名字一样
@TableId(
value="id",
type = IdType.AUTO
)
private Integer id;
private String name; // null
private String email;
//实体类属性,推荐使用包装类型, 可以判断是否为 null
private Integer age; // 0
可以通过使用@data注解自动生成实体类get、set等方法
spring中@Data注解详细解析
也可以手动设置
可以看到实体类上面还有注解
大致意思是
- value:主键字段的名称, 如果是id,可以不用写
- type:指定主键的类型, 主键的值如何生成。 idType.AUTO 表示自动增长
mapper类,也就是DAO接口
要实现BaseMapper,指定实体类
public interface UserMapper extends BaseMapper<User>
具体BaseMapper类的定义源码如下
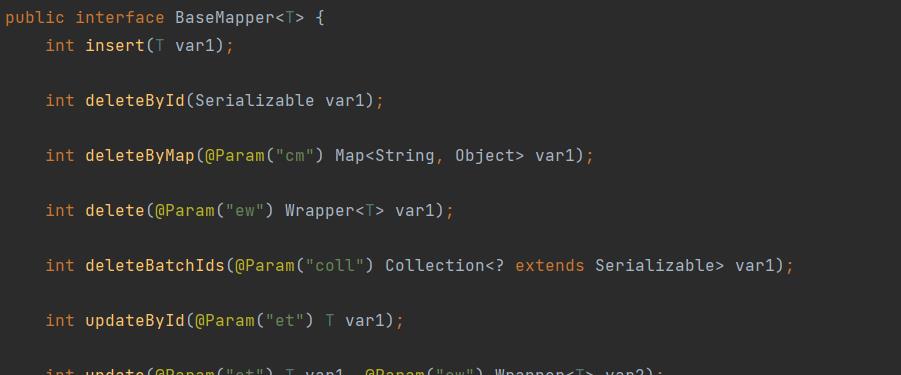
主要是这个框架中的对象,定义17个操作方法(CRUD)
在启动类中还要加一个注解扫描为了扫描这个类
@MapperScan:扫描器,指定Mapper类所在的包
@SpringBootApplication
@MapperScan(value = "com.wkcto.plus.mapper")
public class PlusApplication
public static void main(String[] args)
SpringApplication.run(PlusApplication.class, args);
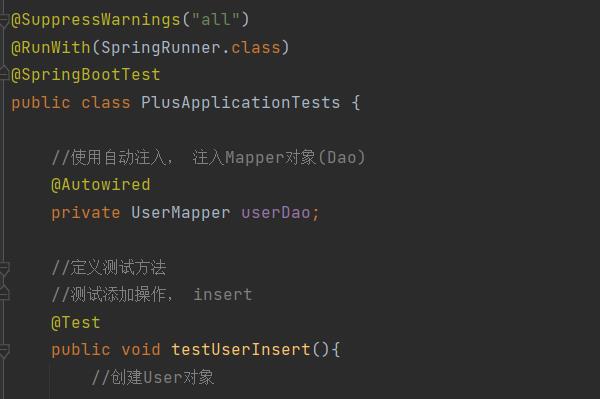
测试文件
关于@SuppressWarnings这个注解,主要是为了抑制警告值
具体信息可看我之前的文章
Spring中@SuppressWarnings注解详细解析
而对于@RunWith(SpringRunner.class),Test测试类要使用注入的类,比如@Autowired注入的类,才可实例化到spring容器
@SuppressWarnings("all")
@RunWith(SpringRunner.class)
@SpringBootTest
public class UserTest
//定义StudentMapper
@Autowired
private UserMapper userDao;
@Test
public void testInsertStudent()
User user = new User();
user.setName("zs");
user.setEmail("zd.com");
user.setAge(20);
int rows = userDao.insert(user);
System.out.println("inserStudent rows:" + rows);
2. 配置日志
在控制台打印日志
输出数据库的信息
主要在yml配置
具体信息为
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
3. CURD基本用法
完整代码就不书写了,只写核心代码
具体方法都是BaseMapper<T>这个类由来
3.1 插入操作
//添加数据后,获取主键值
@Test
public void testInsertGetId()
User user = new User();
user.setName("李四");
user.setAge(20);
user.setEmail("lisi@163.com");
int rows = userDao.insert(user);
System.out.println("insert user rows:"+rows);
//获取主键id ,刚添加数据库中的数据的id
int id = user.getId();//主键字段对应的get方法
System.out.println("主键id:"+id);
3.2 更新操作
- 如果属性用了多少,就会显示更新的多少
- 最好用包装类型的类
在定义实体类的时候,最好使用包装类型,情况如下:
- 定义实体类的基本类型,在如果没有更新,默认是会给0,也就是也更新了
- 定义实体类包装类型,如果没有更新,默认是给null,但是更新的话,是更新的非null类型。
@Test
public void testUpdateUser()
User user = new User();
user.setName("修改的数据");
user.setAge(22);
user.setEmail("edit@163.com");
user.setId(2);
//执行更新,根据主键值更新
/*UPDATE user SET name=?, email=?, age=? WHERE id=?
*更新了所有非null属性值, 条件where id = 主键值
*/
int rows = userDao.updateById(user);
System.out.println("update rows:"+rows);
3.3 删除操作
- 按主键删除一条数据
方法是deleteById()
@Test
public void testDeleteById()
//DELETE FROM user WHERE id=?
int rows = userDao.deleteById(3);
System.out.println("deleteById:"+rows);
- 按条件删除数据, 条件是封装到Map对象中
方法是deleteByMap(map对象);
@Test
public void testDeleteByMap()
//创建Map对象,保存条件值
Map<String,Object> map = new HashMap<>();
//put("表的字段名",条件值) , 可以封装多个条件
map.put("name","zs");
map.put("age",20);
//调用删除方法
//DELETE FROM user WHERE name = ? AND age = ?
int rows = userDao.deleteByMap(map);
System.out.println("deleteByMap rows:"+rows);
- 使用多个主键值,删除数据
使用列表,方法是deleteBatchIds()
@Test
public void deleteByBatchId()
List<Integer> ids = new ArrayList<>();
ids.add(1);
ids.add(2);
ids.add(3);
ids.add(4);
ids.add(5);
//删除操作
//DELETE FROM user WHERE id IN ( ? , ? , ? , ? , ? )
int i = userDao.deleteBatchIds(ids);
System.out.println("deleteBatchIds:"+i);
删除的话还可以使用lambda表达式
将其上面列表的代码替换为
//使用lambda创建List集合
List<Integer> ids = Stream.of(1, 2, 3, 4, 5).collect(Collectors.toList());
3.4 查询操作
- 根据主键值查询,方法是
selectById
@Test
public void testSelectById()
/**
* 生成的sql: SELECT id,name,email,age FROM user WHERE id=?
* 如果根据主键没有查找到数据, 得到的返回值是 null
*/
User user = userDao.selectById(6);
System.out.println("selectById:"+user);
//在使用对象之前,需要判断对象是否为null
if(user != null)
//业务方法的调用
- 实现批处理查询,根据多个主键值查询, 获取到List
方法是selectBatchIds
@Test
public void testSelectBatchId()
List<Integer> ids = new ArrayList<>();
ids.add(6);
ids.add(9);
ids.add(10);
//查询数据
//SELECT id,name,email,age FROM user WHERE id IN ( ? , ? , ? )
List<User> users = userDao.selectBatchIds(ids);
System.out.println("size:"+users.size());
for (User u:users)
System.out.println("查询的用户:"+u);
也可以使用lambda表达式进行查询
List<Integer> ids = Stream.of(6, 9, 10, 15).collect(Collectors.toList());
- 使用Map做多条件查询
方法是selectByMap()
@Test
public void testSelectMap()
//创建Map,封装查询条件
Map<String,Object> map = new HashMap<>();
//key是字段名, value:字段值 ,多个key,是and 联接
map.put("name","zhangsan");
map.put("age",20);
//根据Map查询
//SELECT id,name,email,age FROM user WHERE name = ? AND age = ?
List<User> users = userDao.selectByMap(map);
users.forEach(user ->
System.out.println("selectByMap:"+user);
);
4. ActiveRecord
- ActiveRecord负责把自己持久化,在ActiveRecord 中封装了对数据库的访
问,通过对象自己实现CRUD,实现优雅的数据库操作 - ActiveRecord 也封装了部分业务逻辑。可以作为业务对象使用
以下章节同样也是讲增上改查的用法(就不列举出小标题了)
主要的区别在于
- 前者需要注入mapper以及使用mapper中继承的类(实现curd)
- 现在是不需要注入mapper,而是通过实体类继承
extends Model<Dept>,之后调用model中类来实现curd
//不需要
//使用自动注入, 注入Mapper对象(Dao)
@Autowired
private UserMapper userDao;
查看model类中的源码
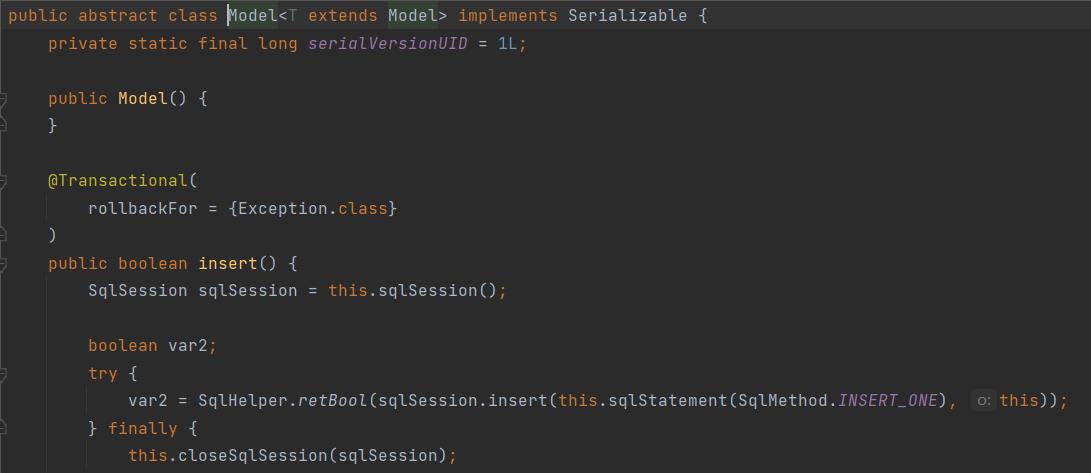
和原先步骤一样
- 在数据库中创建表
- 在代码中创建同样属性的实体类
使用AR,要求实体类需要继承MP中的Model,Model中提供了对数据库的CRUD的操作
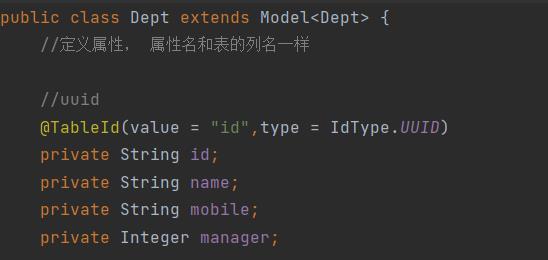
mapper文件也要书写一下
因为DeptMapper是不需要使用的,MP需要使用DeptMapper获取到数据库的表的信息。
如果不定义DeptMapper, MP会报错, 找不到表的定义信息
public interface DeptMapper extends BaseMapper<Dept>
测试类记得要加上这个注解
对于@RunWith(SpringRunner.class),Test测试类要使用注入的类,比如@Autowired注入的类,才可实例化到spring容器
具体测试类如下
4.1 插入操作
调用的是model中的insert方法
@Test
public void testARInsert()
//定义dept的实体
Dept dept = new Dept();
dept.setName("行政部");
dept.setMobile("010-66666666");
dept.setManager(5);
//调用实体对象自己的方法,完成对象自身到数据库的添加操作
boolean flag = dept.insert();
System.out.println("ar insert result:"+flag);
4.2 更新操作
@Test
public void testARUpdate()
//定义实体Dept
Dept dept = new Dept();
// dept.setId(2);
dept.setMobile("010-22222222");
dept.setName("改为市场部");
dept.setManager(2);
//根据主键id更新记录
// UPDATE dept SET name=?, mobile=?, manager=? WHERE id=? // id = 1
boolean result = dept.updateById();//使用dept实体主键的值,作为where id = 1
System.out.println("ar updateById result:"+result);
书写多少个属性就更新多少个属性(前提属性的定义都是包装类型)
@Test
public void testARUpdate2()
//定义实体Dept
Dept dept = new Dept();
// dept.setId(1);
dept.setMobile("010-3333333");
//name , manager是没有修改的
//根据主键id更新记录
// UPDATE dept SET name=?, mobile=?, manager=? WHERE id=? // id = 1
// null的属性值不做更新处理,在update中没有null的字段
//UPDATE dept SET mobile=? WHERE id=?
boolean result = dept.updateById();//使用dept实体主键的值,作为where id = 1
System.out.println("ar updateById result:"+result);
4.3 删除操作
- deleteById()删除操作即使没有从数据库中删除数据,也返回是true
@Test
public void testARDeleteById()
Dept dept = new Dept();
//DELETE FROM dept WHERE id=?
boolean result = dept.deleteById(1);
System.out.println("ar deleteById result:"+result);
4.4 查询操作
方法selectByID
- 按实体的主键能查找出数据,返回对象
- 按实体的主键不能查出数据,是null ,不报错
- 没有记录或者没有数据也是返回null
@Test
public void testARSelectById()
Dept dept = new Dept();
//设置主键的值
// dept.setId(1);
//调用查询方法
//SELECT id,name,mobile,manager FROM dept WHERE id=?
Dept dept1 = dept.selectById();
System.out.println("ar selectById result:"+dept1);
@Test
public void testARSelectById2()
Dept dept = new Dept();
Dept dept1 = dept.selectById(3);
System.out.println("dept1:"+dept1);
5. 表和列
主要讲解一些实体类上的属性定义和数据库不一致的话
分别为这三个属性
主键,TableName, Tableld
5.1 主键类型
IdType的枚举类型如下
public enum IdType
AUTO(0),
NONE(1),
INPUT(2),
ID_WORKER(3),
UUID(4),
ID_WORKER_STR(5);
private int key;
private IdType(int key)
this.key = key;
public int getKey()
return this.key;
- 0.none没有主键
- 1.auto自动增长(mysql,sql server)
- 2.input手工输入
- 3.id_worker:实体类用Long id ,表的列用bigint , int类型大小不够
- 4.id_worker_str 实体类使用String id,表的列使用varchar 50
- 5.uuid 实体类使用String id,列使用varchar 50
5.2 指定表名
定义实体类,默认的表名和实体类同名
- 如果不一致,在实体类定义上面使用
@TableName(value=“数据库表名”)
主要区别在于
定义实体类的时候使用的类名
如果不符合数据库表名要加上这个注解
数据库表名为user_address

5.3 指定列名
主要通过这个注解
@TableField(value = "数据库属性名")
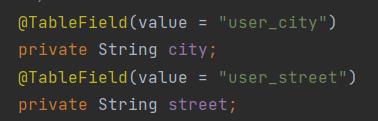
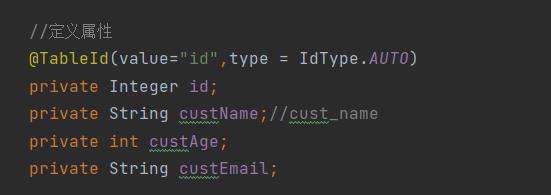
MyBatis 默认支持这种规则
列名使用下划线,属性名是驼峰命名方式
大致意思就是(举个例子)
- 列名使用custName
- 数据库名使用cust_name
6. 自定义sql
和前面的思路一样
主要区别在于方法的定义以及mapper文件的映射等
mapper文件的继承
public interface StudentMapper extends BaseMapper<Student>
//自定义方法
public int insertStudent(Student student);
public Student selectStudentById(Integer id);
public List<Student> selectByName(String name);
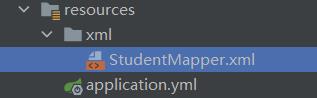
方法的定义在resources文件下
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.wkcto.plus.mapper.StudentMapper">
<insert id="insertStudent">
insert into student(name,age,email,status) values(#name,#age,#email,#status)
</insert>
<select id="selectStudentById" resultType="com.wkcto.plus.entity.Student">
select id,name,age,email,status from student where id=#studentId
</select>
<select id="selectByName" resultType="com.wkcto.plus.entity.Student">
select id,name,age,email,status from student where name=#name
</select>
</mapper>
文件的具体位置是这个
但是这样定义要让代码识别到
所以要在application.yml配置文件中加入路径
mapper-locations: classpath*:xml/*Mapper.xml
此处重点讲解一下CURD数据库的编写细节
- 名称空间要用mapper文件定义方法的全限定名称
<mapper namespace="com.wkcto.plus.mapper.StudentMapper"> - curd的方法id要用其类中定义的方法名,比如
insertStudent方法等 - resultType返回类型是实体类中的全限定名称名
7. 查询和分页
具体使用Wrapper
条件有:
| 条件 | 描述 |
|---|---|
| allEq | 基于map相等 |
| eq | 等于 |
| ne | 不等于 |
| gt | 大于 |
| ge | 大于等于 |
| lt | 小于 |
| le | 小于等于 |
| between | 介值中间 |
| notBetween | 不在这介值中间 |
| like | like ‘%值%’ |
| not like | not like ‘%值%’ |
| likeLeft | like ‘%值’ |
| likeRight | like ‘值%’ |
| isNull | 字段 is null |
| isNotNull | 字段 is not null |
| in | 字段 in(value1,value2,。。) |
| notIn | 字段 not in(value1,value2,。。) |
| inSql | 字段 in(sql 语句) 例如 insql(“age”,“1,2,3”)–>age in(1,2,3,4,5,6) 或者 insql(“id”,“select id from table where id < 3”)–>id in(select id from table where id < 3) |
| notInSql | 字段 not in (sql 语句) |
| groupBy | group by 字段 |
| orderByAsc | 升序 order by字段,…ASC |
| orderByDesc | 降序 order by 字段,…DESC |
| orderBy | 自定义字段排序 orderBy (true,true,“id”,“name”)—>order by id ASC,name ASC |
| having | 条件分组 |
| or | or 语句,拼接+or 字段=值 |
| and | and 语句,拼接+and 字段=值 |
| apply | 拼接sql |
| last | 在sql语句后拼接自定义条件 |
| exists | 拼接exists(sql 语句) 例:exists(“select id from table where age=1”)—>exists(select id from table where age=1) |
| notExists | 拼接not exists (sql 语句) |
| nested | 正常嵌套 不带and 或者or |
- select 设置查询字段select后面内容
- set 设置要更新的字段,mp拼接sql语句
- setSql 参数是sql语句,mp不在处理语句
7.1 查询
主要展示上面条件配合代码该如何实现
allEq
查询全部
@Test
public void testAllEq()
QueryWrapper<Student> qw = new QueryWrapper<>();
//组装条件
Map<String, Object> param = new HashMap<>();
//map<key,value> key列名 , value:查询的值
param.put("name", "张三");
param.put("age", 22);
param.put("status", 1);
qw.allEq(param);
//调用MP自己的查询方法
//SELECT id,name,age,email,status FROM student WHERE name = ? AND age = ?
//WHERE name = ? AND age = ? AND status = ?
List<Student> students = studentDao.selectList(qw);
students.forEach(stu -> System.out.println(stu));
如果有null的情况
- Map对象中有 key的value是null,使用的是
qw.allEq(param,true);,结果:WHERE name = ? AND age IS NULL - Map对象中有 key的value是null,
qw.allEq(param,false);结果:WHERE name = ?
结论: allEq(map,boolean)
- true:处理null值,where 条件加入 字段 is null
- false:忽略null ,不作为where 条件
@Test
public void testAllEq2()
QueryWrapper<Student> qw = new QueryWrapper<>();
//组装条件
Map<String, Object> param = new HashMap<>();
//map<key,value> key列名 , value:查询的值
param.put("name", "张三");
//age 是 null
param.put("age", null);
//allEq第二个参数为true
qw.allEq(param, false);
//调用MP自己的查询方法
List<Student> students = studentDao.selectList(qw);
students.forEach(stu -> System.out.println(stu));
符号判断
//eq("列名",值) 等于
@Test
public void testEq()
QueryWrapper<Student> qw = new QueryWrapper<>();
//组成条件
qw.eq("name", "李四");
//WHERE name = ?
List<Student> students = studentDao.selectList(qw);
students.forEach(stu -> System.out.println("查询eq:" + stu));
//ne不等于
@Test
public void testNe()
QueryWrapper<Student> qw = new QueryWrapper<>();
//组成条件
qw.ne("name", "张三");
// WHERE name <> ?
List<Student> students = studentDao.selectList(qw);
students.forEach(stu -> System.out.println("查询ne:" + stu));
//gt 大于
@Test
public void testGt()
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.gt("age", 30); //age > 30
// WHERE age > ?
List<Student> students = studentDao.selectList(qw);
students.forEach(stu -> System.out.println("stu:" + stu));
//ge 大于等于
@Test
public void testGe()
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.ge("age", 31);// >=31
//WHERE age >= ?
List<Student> students = studentDao.selectList(qw);
students.forEach(stu -> System.out.println("student:" + stu));
//lt 小于
@Test
public void testLt()
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.lt("age", 32);
// WHERE age < ?
List<Student> students = studentDao.selectList(qw);
students.forEach(stu -> System.out.println("student:" + stu));
//le 小于等于
@Test
public void testLe()
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.le("age", 32);
// WHERE age <= ?
List<Student> students = studentDao.selectList(qw);
students.forEach(stu -> System.out.println("student:" + stu));
区间范围内
//介值
@Test
public void testBetween()
QueryWrapper<Student> qw = new QueryWrapper<>();
//between("列名",开始值,结束值)
qw.between("age", 22, 28);
// where age >= 12 and age < 28
List<Student> students = studentDao.selectList(qw);
students.forEach(stu -> System.out.println(stu));
//不在介值
@Test
public void testNotBetween()
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.notBetween("age", 18, 28);
//WHERE age NOT BETWEEN ? AND ?
// where age < 18 or age > 28
List<Student> students = studentDao.selectList(qw);
students.forEach(stu -> System.out.println(stu));
匹配字段
/**
* like 匹配某个值
*/
@Test
public void testLike()
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.like("name", "张");
// WHERE name LIKE %张%
List<Student> students = studentDao.selectList(qw);
students.forEach(stu -> System.out.println(stu));
/**
* notLike 不匹配某个值
*/
@Test
public void testNotLike()
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.notLike("name", "张");
// WHERE name NOT LIKE ? %张%
List<Student> students = studentDao.selectList(qw);
students.forEach(stu -> System.out.println(stu));
/**
* likeLeft "%值"
*/
@Test
public void testLikeLeft()
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.likeLeft("name", "张");
//WHERE name LIKE %张
List<Student> students = studentDao.selectList(qw);
students.forEach(student -> System.out.println(student));
/**
* likeRight "%值"
*/
@Test
public void testLikeRight()
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.likeRight("name", "李");
//WHERE name LIKE 李%
List<Student> students = studentDao.selectList(qw);
students.forEach(student -> System.out.println(student));
/**
* isNull , 判断字段是 null
*/
@Test
public void testIsNull()
QueryWrapper<Student> qw = new QueryWrapper<>();
//判断email is null
//WHERE email IS NULL
qw.isNull("email");
print(qw);
/**
* isNotNull , 判断字段是 is not null
*/
@Test
public void testIsNotNull()
QueryWrapper<Student> qw = new QueryWrapper<>();
// WHERE email IS NOT NULL
qw.isNotNull("email");
print(qw);
private void print(QueryWrapper qw)
List<Student> students = studentDao.selectList(qw);
students.forEach(student -> System.out.println(student));
in 或者子查询
/**
* isNull , 判断字段是 null
*/
@Test
public void testIsNull()
QueryWrapper<Student> qw = new QueryWrapper<>();
//判断email is null
//WHERE email IS NULL
qw.isNull("email");
print(qw);
/**
* isNotNull , 判断字段是 is not null
*/
@Test
public void testIsNotNull()
QueryWrapper<Student> qw = new QueryWrapper<>();
// WHERE email IS NOT NULL
qw.isNotNull("email");
print(qw);
/**
* in 值列表
*/
@Test
public void testIn()
QueryWrapper<Student> qw = new QueryWrapper<>();
//in(列名,多个值的列表)
//WHERE name IN (?,?,?)
qw.in("name","张三","李四","周丽");
print(qw);
/**
* notIn 不在值列表
*/
@Test
public void testNoIn()
QueryWrapper<Student> qw = new QueryWrapper<>();
//in(列名,多个值的列表)
//WHERE name NOT IN (?,?,?)
qw.notIn("name","张三","李四","周丽");
print(qw);
/**
* in 值列表
*/
@Test
public void testIn2()
QueryWrapper<Student> qw = new QueryWrapper<>();
List<Object> list = new ArrayList<>();
list.add(1);
list.add(2);
//WHERE status IN (?,?)
qw.in("status",list);
print(qw);
/**
* inSql() : 使用子查询
*/
@Test
public void testInSQL()
QueryWrapper<Student> qw = new QueryWrapper<>();
//WHERE age IN (select age from student where id=1)
qw.inSql("age","select age from student where id=1");
print(qw);
/**
* notInSql() : 使用子查询
*/
@Test
public void testNotInSQL()
QueryWrapper<Student> qw = new QueryWrapper<>();
//WHERE age NOT IN (select age from student where id=1)
qw.notInSql("age","select age from student where id=1");
print(qw);
private void print(QueryWrapper qw)
List<Student> students = studentDao.selectList(qw);
students.forEach(student -> System.out.println(student));
分组
/**
* groupBy:分组
*/
@Test
public void testGroupby()
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.select("name,count(*) personNumbers");//select name,count(*) personNumbers
qw.groupBy("name");
// SELECT name,count(*) personNumbers FROM student GROUP BY name
print(qw);
字段升序降序
/**
* orderbyAsc : 按字段升序
*/
@Test
public void testOrderByAsc()
QueryWrapper<Student> qw= new QueryWrapper<>();
//FROM student ORDER BY name ASC , age ASC
qw.orderByAsc("name","age");
print(qw);
/**
* orderbyDesc : 按字段降序
*/
@Test
public void testOrderByDesc()
QueryWrapper<Student> qw= new QueryWrapper<>();
// ORDER BY name DESC , id DESC
qw.orderByDesc("name","id");
print(qw);
/**
* order :指定字段和排序方向
*
* boolean condition : 条件内容是否加入到 sql语句的后面。
* true:条件加入到sql语句
* FROM student ORDER BY name ASC
*
* false:条件不加入到sql语句
* FROM student
*/
@Test
public void testOrder()
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.orderBy(true,true,"name")
.orderBy(true,false,"age")
.orderBy(true,false,"email");
// name asc, age desc , email desc
//FROM student ORDER BY name ASC , age DESC , email DESC
print(qw);
拼接以及存在与否
/**
* and ,or方法
*/
@Test
public void testOr()
QueryWrapper<Student> qw= new QueryWrapper<>();
//WHERE name = ? OR age = ?
qw.eq("name","张三")
.or()
.eq("age",22);
print(qw);
/**
* last : 拼接sql语句到MP的sql语句的最后
*/
@Test
public void testLast()
QueryWrapper<Student> qw = new QueryWrapper<>();
//SELECT id,name,age,email,status FROM student WHERE name = ? OR age = ? limit 1
qw.eq("name","张三")
.or()
.eq("age",22)
.last("limit 1");
print(qw);
/**
* exists : 判断条件
*
* notExists
*/
@Test
public void testExists()
QueryWrapper<Student> qw= new QueryWrapper<>();
//SELECT id,name,age,email,status FROM student
// WHERE EXISTS (select id from student where age > 20)
//qw.exists("select id from student where age > 90");
//SELECT id,name,age,email,status FROM student WHERE
// NOT EXISTS (select id from student where age > 90)
qw.notExists("select id from student where age > 90");
print(qw);
7.2 分页
/**
* 分页:
* 1.统计记录数,使用count(1)
* SELECT COUNT(1) FROM student WHERE age > ?
* 2.实现分页,在sql语句的末尾加入 limit 0,3
* SELECT id,name,age,email,status FROM student WHERE age > ? LIMIT 0,3
*/
@Test
public void testPage()
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.gt("age",22);
IPage<Student> page = new Page<>();
//设置分页的数据
page.setCurrent(1);//第一页
page.setSize(3);// 每页的记录数
IPage<Student> result = studentDao.selectPage(page,qw);
//获取分页后的记录
List<Student> students = result.getRecords();
System.out.println("students.size()="+students.size());
//分页的信息
long pages = result.getPages();
System.out.println("页数:"+pages);
System.out.println("总记录数:"+result.getTotal());
System.out.println("当前页码:"+result.getCurrent());
System.out.println("每页的记录数:"+result.getSize());
8. 代码生成器
这个有点像mybatis的逆向工程
详情可看我之前的文章
mybatis逆向工程详细配置讲解(全)
结合创建数据库的表,自动生成代码
添加依赖包
<!-- 模板引擎 -->
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.0</version>
</dependency>
创建一个生成类
public class AutoMapper
public static void main(String[] args)
//创建AutoGenerator ,MP中对象
AutoGenerator ag = new AutoGenerator();
//设置全局配置
GlobalConfig gc = new GlobalConfig();
//设置代码的生成位置, 磁盘的目录
String path = System.getProperty("user.dir");
gc.setOutputDir(path+"/src/main/java");
//设置生成的类的名称(命名规则)
gc.setMapperName("%sMapper");//所有的Dao类都是Mapper结尾的,例如DeptMapper
//设置Service接口的命名
gc.setServiceName("%sService");//DeptService
//设置Service实现类的名称
gc.setServiceImplName("%sServiceImpl");//DeptServiceImpl
//设置Controller类的命名
gc.setControllerName("%sController");//DeptController
//设置作者
gc.setAuthor("码农研究僧");
//设置主键id的配置
gc.setIdType(IdType.ID_WORKER);
ag.setGlobalConfig(gc);
//设置数据源DataSource
DataSourceConfig ds = new DataSourceConfig();
//驱动
ds.setDriverName("com.mysql.jdbc.Driver");
//设置url
ds.setUrl("jdbc:mysql://localhost:3306/springdb");
//设置数据库的用户名
ds.setUsername("root");
//设置密码
ds.setPassword("123456");
//把DataSourceConfig赋值给AutoGenerator
ag.setDataSource(ds);
//设置Package信息
PackageConfig pc = new PackageConfig();
//设置模块名称, 相当于包名, 在这个包的下面有 mapper, service, controller。
pc.setModuleName("order");
//设置父包名,order就在父包的下面生成
pc.setParent("com.wkcto"); //com.wkcto.order
ag.setPackageInfo(pc);
//设置策略
StrategyConfig sc = new StrategyConfig();
sc.setNaming(NamingStrategy.underline_to_camel);
//设置支持驼峰的命名规则
sc.setColumnNaming(NamingStrategy.underline_to_camel);
ag.setStrategy(sc);
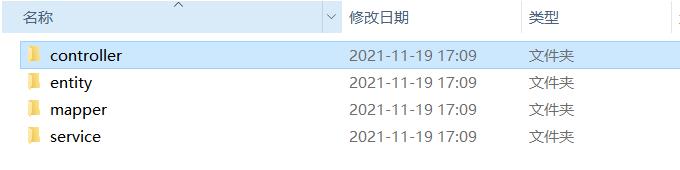
//执行代码的生成
ag.execute();
还要配置一个配置类
@Configuration
public class Config
/***
* 定义方法,返回的返回值是java 对象,这个对象是放入到spring容器中
* 使用@Bean修饰方法
* @Bean等同于<bean></bean>
*/
@Bean
public PaginationInterceptor paginationInterceptor()
return new PaginationInterceptor();
点击运行就会生成代码文件
执行测试类
@SuppressWarnings("all")
@RunWith(SpringRunner.class)
@SpringBootTest
public class StudentMapperTest
//注入生成的StudentMapper
@Autowired
StudentMapper studentMapper;
@Test
public void testInsertStudent()
Student student = new Student();
student.setName("john");
student.setAge(28);
student.setEmail("john@yahu.com");
student.setStatus(2);
int rows = studentMapper.insert(student);
System.out.println("insert Student rows:"+rows);
@Test
public void testSelect()
Student student = studentMapper.selectById(1);
System.out.println("testSelect:"+student);
@Test
public void testSelect1()
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.gt("age",35);
//selectOne:查询结果只能是一条记录或没有没有记录,多条记录是报错的
Student student = studentMapper.selectOne(qw);
System.out.println("testSelect:"+student);
————————————————
版权声明:本文为CSDN博主「码农研究僧」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_47872288/article/details/121397544
以上是关于mybaits-plus笔记的主要内容,如果未能解决你的问题,请参考以下文章