机器学习算法集成学习-1 强学习器的融合学习
Posted 晴天qt01
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习算法集成学习-1 强学习器的融合学习相关的知识,希望对你有一定的参考价值。
目录
我的主页:晴天qt01的博客_CSDN博客-数据分析师领域博主
目前进度:第四部分【机器学习算法】
集成学习*
前言引入:
我们购买新车的时候会走进一家汽车店,然后按照经销商的建议购买吗?这应该不大可能。
更多的时候是浏览一些网站,比较不同的车型,功能,和价格,也可能问问朋友和同事,。我们下结论都是考虑他人的意见,然后下决定
机器学习中的集成学习模型就是类似的想法。
他们将多个模型的决策结合起来,提高预测结果。
案例:
假如你是一个电影的导演,你已经创作了一部非常重要且有趣的话题电影,你现在希望得到他人对电影的评价,反馈。你有什么方法呢
让一位好朋友给你评分。
你的好朋友可能会考虑到你们的关系,不会给你糟糕的电影提供1星评分刺伤你的心。
你可以让5位同事评价电影。
这应该是比上一个选择好许多的方法,可以更好了解电影的评级,比较诚实的评级。但是这5个人里面不一定是最佳的裁判
你可以让50个人评价你的电影。
有一些人是你的朋友,有一些人可能是你的同事,一些可能是完全陌生的。这种情况的回答普遍会更加的多元化,因为你拥有不同技能的人,事实证明,这是获得最佳评价的方法。
多个决策者比一个决策者可能会做出更好的决策,各种模型的整合也是如此,机器学习这种多样化就是通过集成学习的技术实现的
集成学习模型通过将多个学习器进行组合,常可获取比单一学习器更好的泛化能力
集成学习的方法在全球各大机器学习、数据挖掘竞赛中使用的非常广泛,其概念和思想也是风靡学术界和工业界。
如果要对其进行分类,可以大致划分为:
模型融合
机器学习元算法
模型融合是一个再学习的过程,将训练出的强学习器(比如把朴素贝叶斯,神经网络,SVM,逻辑回归,这些算法都竭尽所能的把数据进行分类。)组合起来进一步提高性能,也就是把不同的专家意见组合起来继续预测。
机器学习元算法,是属于弱学习器的算法。可能算法只有一种,通过不同的训练数据,用相同的算法(一种算法),进行预测结果的组合,当做我们的预测模型。从原始数据抽样模型的。
集成学习概述
集成学习的种类。
模型融合(强学习器)
多数法,平均法,加权平均法(前3个比较简单),堆叠法(stacking),混合法(Blending)
机器学习元算法(弱学习器):
袋装法:(bagging)
袋装通用法
随机森林
提升法
ADAboost
XGBoost
Gradient Boost
模型融合(强学习器融合)概述
模型融合的思想也很符合大多数人的直觉
训练出多个功能强大的学习器
为了提高学习器的能力,把几个学习器组合起来。
模型融合的
好处:增强了模型的预测以及泛化能力
坏处:多模型的学习加上再学习会显著的增加计算的代价(也就是耗费时间)
我们在训练数据得到的模型进行融合,如果它们好坏参差不齐,那么集成模型的性能可能会比好的坏一些,坏的好一些
不过在测试数据中,泛化能力比较好。也就是稳定性比较高。
所以我们什么时候才能让它得到泛化能力最好,我们需要每个“学习器”好而不同。
好而不同是什么:就是比如现在要把10笔数据进行分堆,可能naïve bayes分对了5个,神经网络分对了后5个,就是分错的数据不要是同一堆,一致的话融合就没有用,分错的数据不一致,还准确率都还不错,那么合并起来之后。如果每个学习器都好,而且准确率都不错的前提下,我们会取概率大的来猜,那么模型融合就可以做到更好,决策的更精准。
好是代表性能好,不同是代表模型分类类别不同。
模型融合方法:
多数法
多数法使用在分类问题,
使用多个模型对数据进行预测,每个模型的预测视为投票。
大多数模型得到的票,作为预测结果
例如我们现在让5位同事评价你的电影,2个5分,3个4分,所以最终认为取结果众数。

平均法:
和多少法类似,不过采用的是所以模型的平均值来作为预测结果。
平均法既可以用于分类问题也可以用于回归问题,分类问题可以吧结果的概率输出,用概率来平均。(平均要用数字平均)
所以这部影片的评分为4.4.

加权平均法。
这是上面平均法的扩展,根据模型的重要性分配不同的权重。
比如你的两个同事是评价专业者,其他同事则没有这个经验。那么这两个同事的评价就相对重要些。
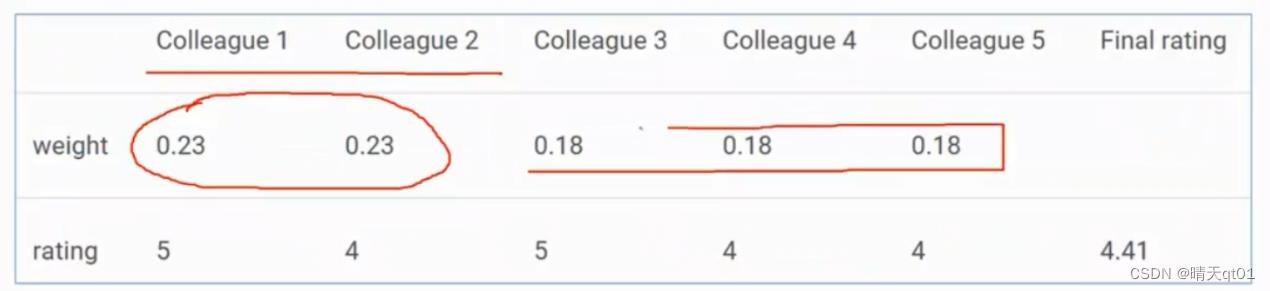
如图,我们给前两个同事0.23的权重。其他只有0.18的权重值。
另外我们加权平均法的权重一般要为1.0。
最后的结果就是4.41,累乘后求和。
堆叠法:
利用多个模型比如(SVM,KNN,决策树)来预测构建新模型。因为方法比较复杂我们拿案例来说明。
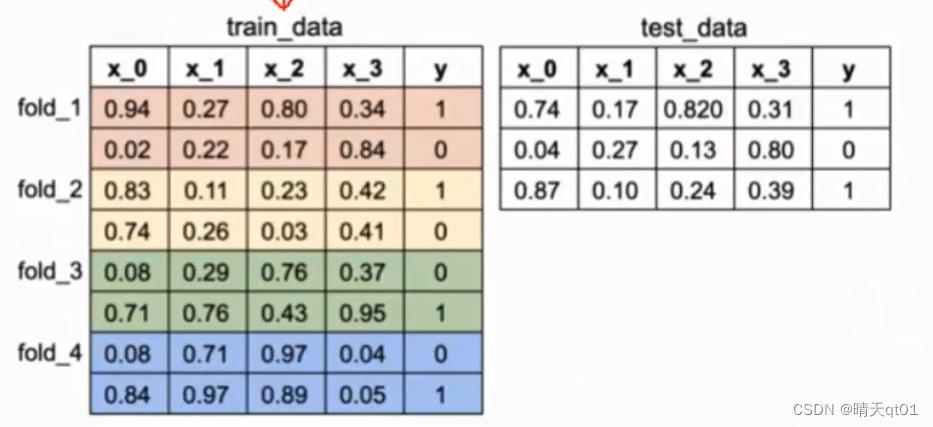
这里有训练数据和测试数据,训练数据用的是4个交叉验证。把训练数据切成4份。测试数据就不用
第一部分我们采用决策树
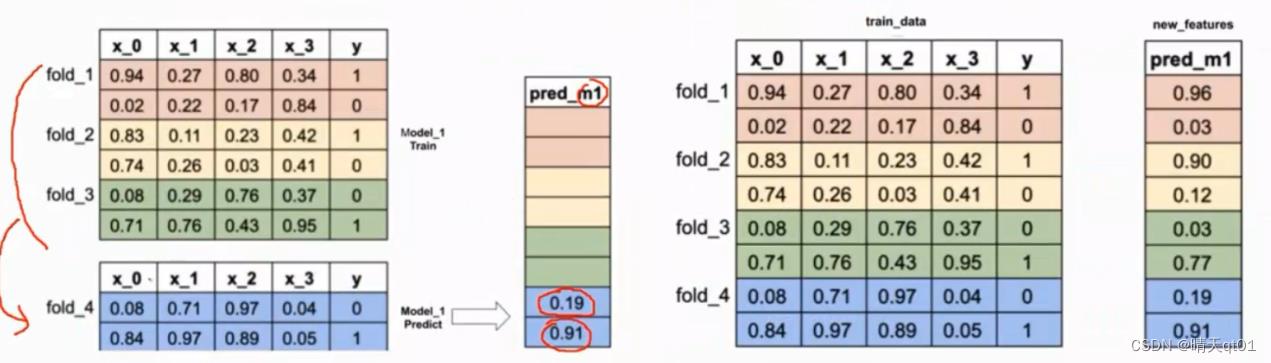
用前3个部分的数据来训练决策树模型,然后用决策树模型来预测第4个模型。
第二部分我们用决策树
使用flod134来训练决策树模型,用模型来预测fold2
第二部分我们用决策树
使用flod234来训练决策树模型,用模型来预测fold1
…
最后得到右边的预测结果图。
如果我们需要3个模型,右边的预测结果图就会有3条
然后我们用第一个模型对测试数据进行预测
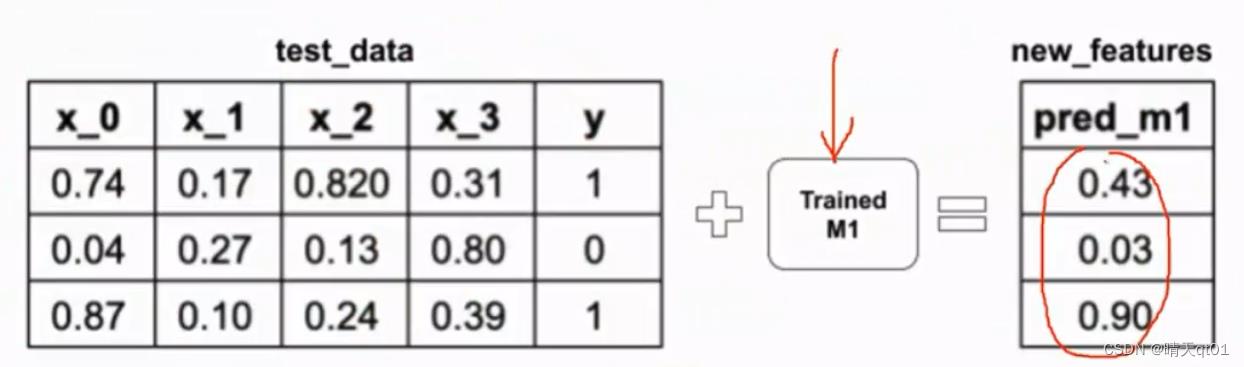
其他的2个模型都是这么做
于是我们得到结果图
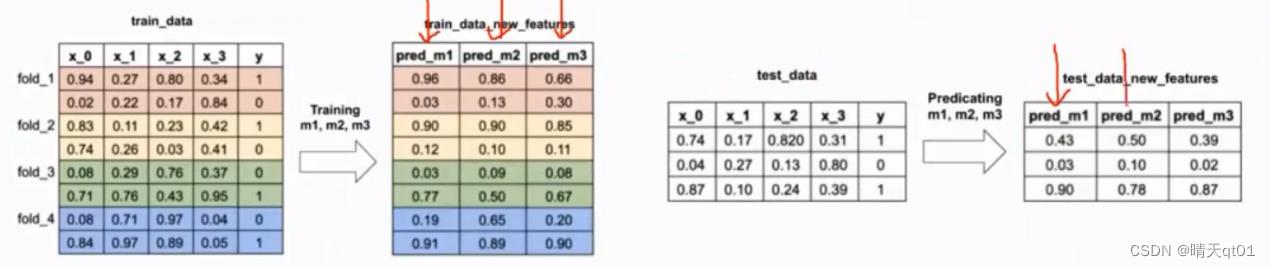
第二个图是模型对训练数据的预测结果,第4个图是3个模型对测试数据的预测结果
我们把第二个图用逻辑回归模型进行训练。再用逻辑回归去预测测试数据集的结果。
这个逻辑回归模型就是我们的预测模型了
它比较特别的地方是,它不是那全部的训练数据来训练模型,而是取其中的大部分用于训练,小部分的数据用于测试
那么我们就可以得到这个模式对每一笔数据的预测概率值,这一整个训练数据的含金量就相当于测试数据。但是它参与的模型的建构,所以还是需要测试数据用于训练。
我们把各个模型训练出的结果当成新特征来训练新模型,预测测试数据
这个堆叠法的名称大家应该立即了,就是在模型的头上堆叠模型。
这个是比较复杂的模型(stacking),因为效果还不错,所以大家也喜欢用。但是过程相对复杂。
最后测试数据在喂到新特征建立的模型来测试
混合法:
Blending与堆叠法类似,但是混合法只使用验证集来重新建模并进行预测。
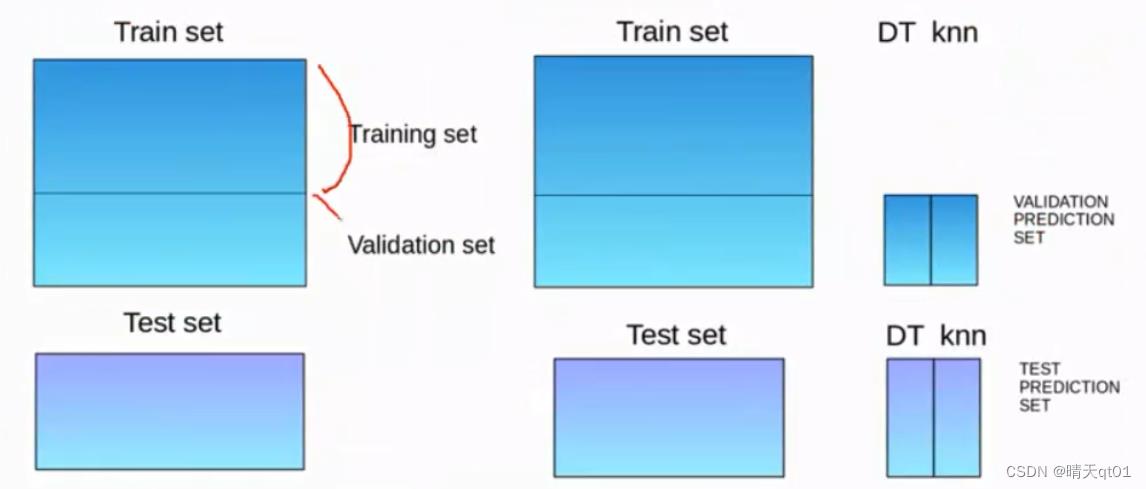
Blending相当于少了交叉验证的部分,
案例:
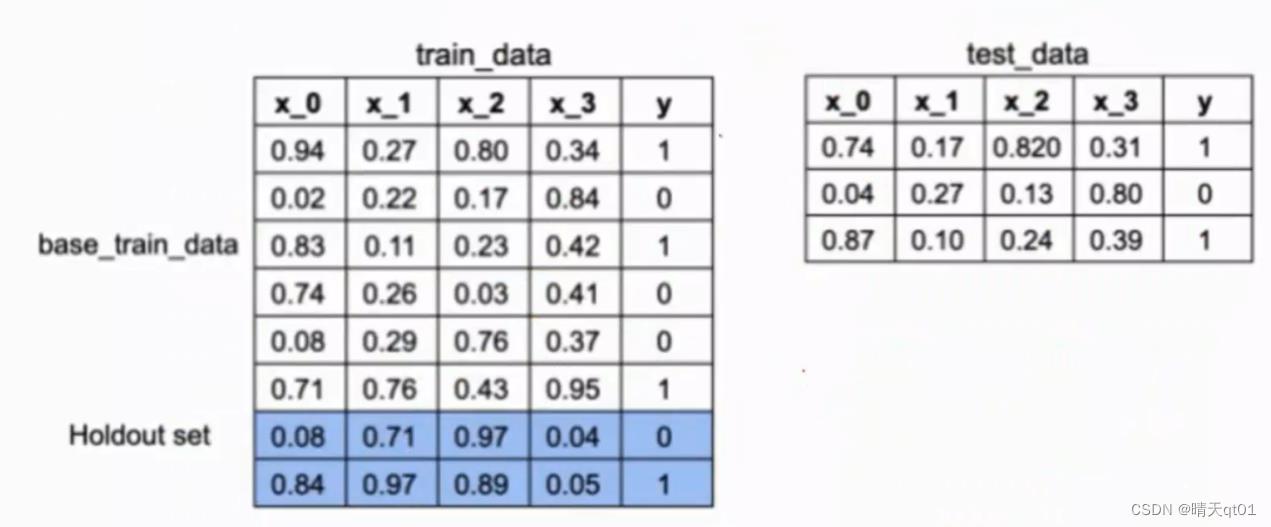
首先我们把数据分为2部分,训练数据集合测试数据集,训练数据集再分为两个部分,base_train_data 和holdout set
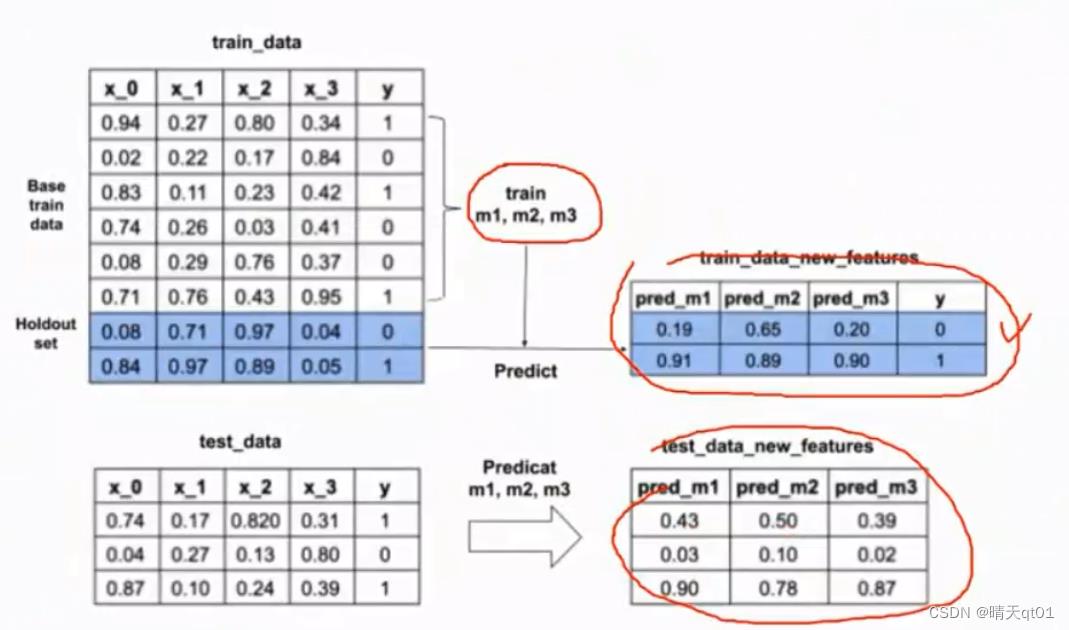
我们拿base_train_data来进行建立需要的多个模型holdout set用多个模型预测结果
然后再用多个模型预测测试集结果。然后再拿训练数据中的holdout set预测数据作为新特征来建立模型,用这个模型再预测测试集结果
总结:
什么强学习器的融合方法说明了5种,前3种是比较简单。后两种方法比较复杂,是模型上再套模型的方法来做融合。Stacking还更复杂些
明天我们说弱学习器的机器学习元算法,它的效果经常要比强学习器效果好很多。
以上是关于机器学习算法集成学习-1 强学习器的融合学习的主要内容,如果未能解决你的问题,请参考以下文章