广告推荐CTR点击率预测实践项目!
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了广告推荐CTR点击率预测实践项目!相关的知识,希望对你有一定的参考价值。
Datawhale干货
作者:鱼佬,武汉大学硕士,Datawhale成员
与报纸、杂志、电视、广播这些传统的传播媒体广告相比,新生的互联网广告拥有天然优势:它能够追踪、研究用户的偏好,并在此基础上进行精准广告推荐和营销。
CTR(Click-Through-Rate)即点击通过率,是衡量互联网广告效果的一项重要指标。这个问题是近几年各大平台研究的热点。本文借助华为全球校园AI算法精英赛题——广告-信息流跨域ctr预估,对该问题进行研究。
实践背景
赛题背景
广告推荐主要基于用户对广告的历史曝光、点击等行为进行建模,如果只是使用广告域数据,用户行为数据稀疏,行为类型相对单一。而引入同一媒体的跨域数据,可以获得同一广告用户在其他域的行为数据,深度挖掘用户兴趣,丰富用户行为特征。引入其他媒体的广告用户行为数据,也能丰富用户和广告特征。
赛题任务
本赛题基于广告日志数据,用户基本信息和跨域数据优化广告ctr预估准确率。目标域为广告域,源域为信息流推荐域,通过获取用户在信息流域中曝光、点击信息流等行为数据,进行用户兴趣建模,帮助广告域ctr的精准预估。
报名及数据下载
报名地址:
https://developer.huawei.com/consumer/cn/activity/digixActivity/digixdetail/101655281685926449?ha_source=dw&ha_sourceId=89000243
数据下载:(没有参赛过的同学参考)
https://xj15uxcopw.feishu.cn/docx/doxcnufyNTvUfpU57sRyydgyK6c
实践思路
本次比赛是一个经典点击率预估(CTR)的数据挖掘赛,任务是构建一种模型,根据用户的测试数据来预测这个用户是否点击广告。这是典型的二分类问题,模型的预测输出为 0 或 1 (点击:1,未点击:0)
机器学习中,关于分类任务我们一般会想到逻辑回归、决策树等算法,在本文实践代码中,我们尝试使用逻辑回归来构建我们的模型。我们在解决机器学习问题时,一般会遵循以下流程: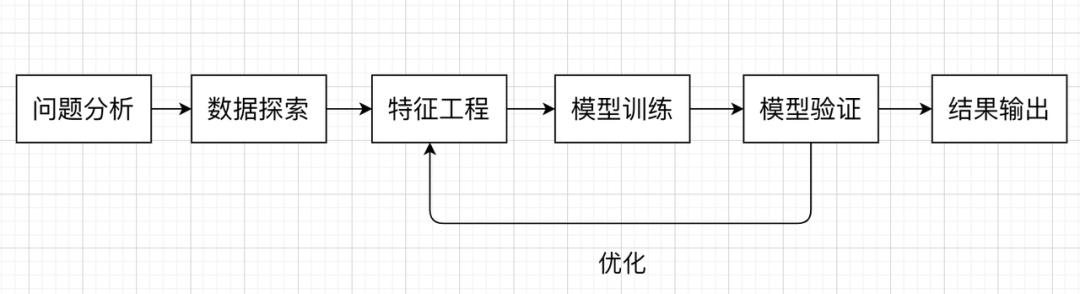
实践代码
需要内存:1GB
运行时间:5分钟
#安装相关依赖库 如果是windows系统,cmd命令框中输入pip安装,参考上述环境配置
#!pip install sklearn
#!pip install pandas
#---------------------------------------------------
#导入库
import pandas as pd
#----------------数据探索----------------
# 只使用目标域用户行为数据
train_ads = pd.read_csv('./train/train_data_ads.csv',
usecols=['log_id', 'label', 'user_id', 'age', 'gender', 'residence', 'device_name',
'device_size', 'net_type', 'task_id', 'adv_id', 'creat_type_cd'])
test_ads = pd.read_csv('./test/test_data_ads.csv',
usecols=['log_id', 'user_id', 'age', 'gender', 'residence', 'device_name',
'device_size', 'net_type', 'task_id', 'adv_id', 'creat_type_cd'])
#----------------数据集采样----------------
train_ads = pd.concat([
train_ads[train_ads['label'] == 0].sample(70000),
train_ads[train_ads['label'] == 1].sample(10000),
])
#----------------模型训练----------------
# 加载训练逻辑回归模型
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(
train_ads.drop(['log_id', 'label', 'user_id'], axis=1),
train_ads['label']
)
#----------------结果输出----------------
# 模型预测与生成结果文件
test_ads['pctr'] = clf.predict_proba(
test_ads.drop(['log_id', 'user_id'], axis=1),
)[:, 1]
test_ads[['log_id', 'pctr']].to_csv('submission.csv',index=None)实践提升
我们完成了广告信息流跨域ctr预估实践的baseline任务,接下来可以从以下几个方向思考:
继续尝试不同的预测模型或特征工程来提升模型预测的准确度
尝试模型融合等策略
查阅广告信息流跨域ctr预估预测相关资料,获取其他模型构建方法
参与内测
本文为Datawhale项目实践2.0教程,如果你也是在校生,还在入门阶段,可以进内测学习群,我们在学习反馈中一起优化教程。


整理不易,点赞三连↓
以上是关于广告推荐CTR点击率预测实践项目!的主要内容,如果未能解决你的问题,请参考以下文章