Java集合类之 HashSet以及底层逻辑分析
Posted 小新爱学习.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java集合类之 HashSet以及底层逻辑分析相关的知识,希望对你有一定的参考价值。



前言:
“前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默
经过小新缜密的思考与亲身体验,忍不住分享一下给大家。有人工智能兴趣的朋友们,推荐大家一起学习 🎉点击直接访问🎉
URL: https://www.captainai.net/hmmwx
里面有丰富的人工智能学习资料,真正做到从入门到入土,还不快来一起学习🎏🎏🎏
个人名片:
🐼作者简介:一名大一在校生
🐻❄️个人主页:小新爱学习.
🐼个人WeChat:hmmwx53
🕊️系列专栏:零基础学java ----- 重识c语言
🐓每日一句:人生没有一劳永逸,想不被抛弃,只有自己努力
文章目录
HashSet集合🎋
1.1 HashSet集合的概述和特点🎐🎐🎐
首先先来研究一下帮助文档

HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。
HashSet 允许有 null 值。
HashSet 是无序的,即不会记录插入的顺序。
HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的。 您必须在多线程访问时显式同步对 HashSet 的并发访问。
HashSet 实现了 Set 接口。
public class HashSet< E >
extends AbstractSet< E>
implements Set< E>, Cloneable, Serializable
此类实现 Set 接口,由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null 元素。
此类为基本操作提供了稳定性能,这些基本操作包括 add、remove、contains 和 size,假定哈希函数将这些元素正确地分布在桶中。对此 set 进行迭代所需的时间与 HashSet 实例的大小(元素的数量)和底层 HashMap 实例(桶的数量)的“容量”的和成比例。因此,如果迭代性能很重要,则不要将初始容量设置得太高(或将加载因子设置得太低)。
注意,此实现不是同步的。如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步。这通常是通过对自然封装该 set 的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来“包装” set。最好在创建时完成这一操作,以防止对该 set 进行意外的不同步访问:
Set s = Collections.synchronizedSet(new HashSet(...));
此类的 iterator 方法返回的迭代器是快速失败 的:在创建迭代器之后,如果对 set 进行修改,除非通过迭代器自身的 remove 方法,否则在任何时间以任何方式对其进行修改,Iterator 都将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就会完全失败,而不冒将来在某个不确定时间发生任意不确定行为的风险。
注意,迭代器的快速失败行为无法得到保证,因为一般来说,不可能对是否出现不同步并发修改做出任何硬性保证。快速失败迭代器在尽最大努力抛出 ConcurrentModificationException。因此,为提高这类迭代器的正确性而编写一个依赖于此异常的程序是错误做法:迭代器的快速失败行为应该仅用于检测 bug。
总结:HashSet集合特点
- 底层数据结构是哈希表
- 对集合的迭代顺序不做任何的保证,也就是说不保证存储和取出的元素顺序一致
- 没有带索引的方法,所以不能使用普通for循环来遍历(可以使用迭代器和增强for遍历)
- 由于是Set 集合,所以不包含重复元素的集合
1.2 HashSet 集合 Demo✨✨✨
代码示例:存储字符串并遍历
package com.ithmm_06;
import java.util.HashSet;
import java.util.Iterator;
/**
* HashSet集合特点
*
* 底层数据结构是哈希表
* 对集合的迭代顺序不做任何的保证,也就是说不保证存储和取出的元素顺序一致
* 没有带索引的方法,所以不能使用普通for循环来遍历(可以使用迭代器和增强for遍历)
* 由于是Set 集合,所以不包含重复元素的集合
*/
public class HashSetDemo
public static void main(String[] args)
//创建集合对象
HashSet<String> hs = new HashSet<String>();
//添加元素
hs.add("hello");
hs.add("world");
hs.add("java");
// hs.add("hello");
//遍历
for(String s:hs)
System.out.println(s);//world java hello
//迭代器 Iterator<E> iterator()
// 返回对此 set 中元素进行迭代的迭代器
Iterator<String> it = hs.iterator();
while (it.hasNext())
String str = it.next();
System.out.println(str);
1.3 HashSet集合保证元素唯一性底层逻辑(源码分析)🎊🎊🎊
HashSet集合添加一个元素的过程:
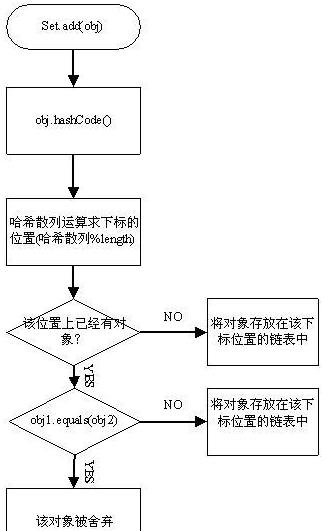
HashSet底层源码:
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package java.util;
import java.io.IOException;
import java.io.InvalidObjectException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import java.util.HashMap.KeySpliterator;
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, Serializable
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E, Object> map;
private static final Object PRESENT = new Object();
public HashSet()
this.map = new HashMap();
public HashSet(Collection<? extends E> var1)
this.map = new HashMap(Math.max((int)((float)var1.size() / 0.75F) + 1, 16));
this.addAll(var1);
public HashSet(int var1, float var2)
this.map = new HashMap(var1, var2);
public HashSet(int var1)
this.map = new HashMap(var1);
HashSet(int var1, float var2, boolean var3)
this.map = new LinkedHashMap(var1, var2);
public Iterator<E> iterator()
return this.map.keySet().iterator();
public int size()
return this.map.size();
public boolean isEmpty()
return this.map.isEmpty();
public boolean contains(Object var1)
return this.map.containsKey(var1);
public boolean add(E var1)
return this.map.put(var1, PRESENT) == null;
public boolean remove(Object var1)
return this.map.remove(var1) == PRESENT;
public void clear()
this.map.clear();
public Object clone()
try
HashSet var1 = (HashSet)super.clone();
var1.map = (HashMap)this.map.clone();
return var1;
catch (CloneNotSupportedException var2)
throw new InternalError(var2);
private void writeObject(ObjectOutputStream var1) throws IOException
var1.defaultWriteObject();
var1.writeInt(this.map.capacity());
var1.writeFloat(this.map.loadFactor());
var1.writeInt(this.map.size());
Iterator var2 = this.map.keySet().iterator();
while(var2.hasNext())
Object var3 = var2.next();
var1.writeObject(var3);
private void readObject(ObjectInputStream var1) throws IOException, ClassNotFoundException
var1.defaultReadObject();
int var2 = var1.readInt();
if (var2 < 0)
throw new InvalidObjectException("Illegal capacity: " + var2);
else
float var3 = var1.readFloat();
if (!(var3 <= 0.0F) && !Float.isNaN(var3))
int var4 = var1.readInt();
if (var4 < 0)
throw new InvalidObjectException("Illegal size: " + var4);
else
var2 = (int)Math.min((float)var4 * Math.min(1.0F / var3, 4.0F), 1.07374182E9F);
this.map = (HashMap)(this instanceof LinkedHashSet ? new LinkedHashMap(var2, var3) : new HashMap(var2, var3));
for(int var5 = 0; var5 < var4; ++var5)
Object var6 = var1.readObject();
this.map.put(var6, PRESENT);
else
throw new InvalidObjectException("Illegal load factor: " + var3);
public Spliterator<E> spliterator()
return new KeySpliterator(this.map, 0, -1, 0, 0);
1.4 常见数据结构之哈希表🎐🎐🎐
HashSet底层是哈希表结构的
哈希表
- JDK8之前,底层采用数组+链表实现。
- JDK8以后,底层进行了优化。由数组+链表+红黑树实现。
一、HashSet1.7版本原理解析🎐🎐🎐
当我们用空参构造 创建一个Hashset 时
HashSet<String> haset1 = new HashSet<>();
底层 创建一个默认长度16,默认加载因子0.75的数组,数组名table

第一次添加元素时🎐🎐🎐
根据元素的哈希值跟数组的长度计算出应存入的位置 例如:4
在判断当前 4 索引位置是否为null,如果是null直接存入

第二次添加元素时🎐🎐🎐
根据元素的哈希值跟数组的长度计算出的结果 是 10 索引位置
在判断当前位置是否为null,如果是null直接存入

第三次添加元素时🎐🎐🎐
根据元素的哈希值跟数组的长度计算出的结果 还是 4 索引位置
此时 4 索引上 已经有了一个元素 不为null ,则会调用equals方法比较 内部的属性值
如果一样,则不存,如果不一样,则存入数组,老元素挂在新元素下面 形成链表结构

第四次添加元素时🎐🎐🎐
根据元素的哈希值跟数组的长度计算出的结果 还是 4 索引位置
此时 4 索引上 已经有了两个元素
会通过equals方法比较 从上到下 一 一比较
如果一样,则不存,如果不一样,则存入数组,老元素挂在新元素下面
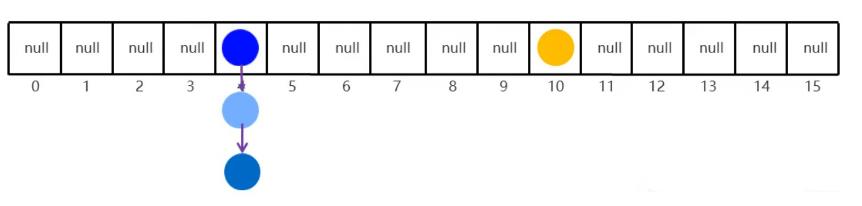
扩容
当数组里面存了16*0.75 =12个元素的时候,数组就会扩容为原先的两倍 32
总结
- 底层结构∶哈希表。(数组+链表)
- 数组的长度默认为16,加载因子为0.75
- 首先会先获取元素的哈希值,计算出在数组中应存入的索引
- 判断该索引处是否为null
- 如果是null,直接添加
- 如果不是null,则与链表中所有的元素,通过equals方法比较属性值只要有一个相同,就不存,如果都不一样,才会存入集合。
以上是关于Java集合类之 HashSet以及底层逻辑分析的主要内容,如果未能解决你的问题,请参考以下文章