语义分割项目实战制作语义分割数据集,并使用U-Net进行实战检测
Posted Bill~QAQ~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了语义分割项目实战制作语义分割数据集,并使用U-Net进行实战检测相关的知识,希望对你有一定的参考价值。
首先上项目的链接:
这个好像是官方给的项目代码,用起来非常的方便,下载完直接解压压缩包,然后使用pycharm打开即可
Labelme工具安装
首先在anaconda环境下创建一个新的环境
conda create -n labelme python=3.6安装完成后激活该环境
conda activate labelme
安装
pip install labelme安装完后直接打开即可
labelme
我们最终的目的是要有两个文件夹
第一个文件夹imgs:存放原图
第二个文件夹masks:存放生成的掩膜图像
语义分割就是使用这两个图像进行训练
open dir选择存放原图的imgs,我这里是一些五角星的图片
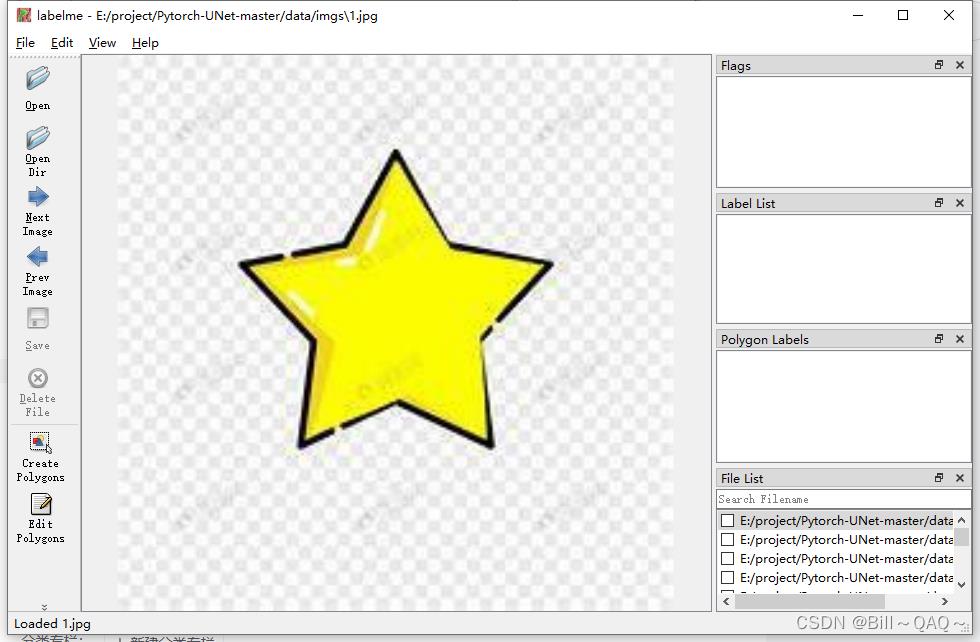
然后使用左下角Create Pologons进行标框即可,每标完一张图片,都要保存在另一个新建文件夹jsons下,最终结果如下
但是这不是我们最终需要的mask图像,还要使用别的脚本进行生成
我这里借鉴了博主 奶盖芒果的脚本,看了好多贴子只有这个姐姐讲的最好QAQ
原帖链接
(22条消息) U-net复现pytorch版本 以及制作自己的数据集并训练_奶盖芒果的博客-CSDN博客_unet训练
labelme批量实现json_to_dataset方法(2021)_奶盖芒果的博客-CSDN博客_json_to_dataset.py
首先按照文中的方法,找到json_to_dataset的文件,将其改写为
import argparse
import json
import os
import os.path as osp
import warnings
import PIL.Image
import yaml
from labelme import utils
import base64
import numpy as np
from skimage import img_as_ubyte
def main():
warnings.warn("This script is aimed to demonstrate how to convert the\\n"
"JSON file to a single image dataset, and not to handle\\n"
"multiple JSON files to generate a real-use dataset.")
parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args()
json_file = args.json_file
count = os.listdir(json_file)
for i in range(0, len(count)):
path = os.path.join(json_file, count[i])
if os.path.isfile(path):
data = json.load(open(path))
##############################
#save_diretory
out_dir1 = osp.basename(path).replace('.', '_')
save_file_name = out_dir1
out_dir1 = osp.join(osp.dirname(path), out_dir1)
if not osp.exists(json_file + '\\\\' + 'labelme_json'):
os.mkdir(json_file + '\\\\' + 'labelme_json')
labelme_json = json_file + '\\\\' + 'labelme_json'
out_dir2 = labelme_json + '\\\\' + save_file_name
if not osp.exists(out_dir2):
os.mkdir(out_dir2)
#########################
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = '_background_': 0
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
captions = [': '.format(lv, ln)
for ln, lv in label_name_to_value.items()]
lbl_viz = utils.draw_label(lbl, img, captions)
PIL.Image.fromarray(img).save(out_dir2+'\\\\'+save_file_name+'_img.png')
#PIL.Image.fromarray(lbl).save(osp.join(out_dir2, 'label.png'))
utils.lblsave(osp.join(out_dir2, save_file_name+'_label.png'), lbl)
PIL.Image.fromarray(lbl_viz).save(out_dir2+'\\\\'+save_file_name+
'_label_viz.png')
with open(osp.join(out_dir2, 'label_names.txt'), 'w') as f:
for lbl_name in label_names:
f.write(lbl_name + '\\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(out_dir2, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
#save png to another directory
if not osp.exists(json_file + '\\\\' + 'mask_png'):
os.mkdir(json_file + '\\\\' + 'mask_png')
mask_save2png_path = json_file + '\\\\' + 'mask_png'
utils.lblsave(osp.join(mask_save2png_path, save_file_name+'_label.png'), lbl)
print('Saved to: %s' % out_dir2)
if __name__ == '__main__':
main()然后将这个python文件复制到和imgs,jsons同一个文件夹下,在终端中输入以下指令
python json_to_dataset.py H:\\pictures\\jsons最后那个路径是jsons文件夹所在的绝对路径,要改成自己的
运行完成后结果如下:
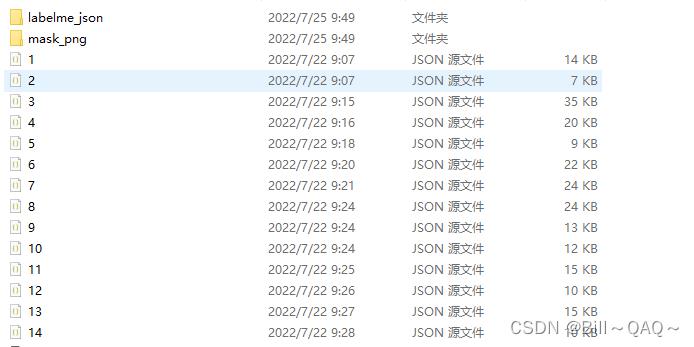
mask_png中存放的就是生成的掩膜图像

然后将这些掩膜图像复制粘贴到GitHub上下载项目的data/masks下,原图复制粘贴到data/imgs文件夹下
这样我们的数据集就准备好了
训练模型
打开我们下载的项目文件,有一些参数需要进行修改
在utils/data_loading.py的最后一行中,将mask_suffix后面的'_mask'修改为'_json_label',因为我们mask文件夹下的文件后缀是_json_label,所以要在读入的时候将后缀改成对应的

然后就可以在终端中运行
python train.py对于epoch,batch-size等变量,可以在train的源代码中修改,也可以在终端中直接修改
具体修改可以参考GitHub原作者的注释
> python train.py -h
usage: train.py [-h] [--epochs E] [--batch-size B] [--learning-rate LR]
[--load LOAD] [--scale SCALE] [--validation VAL] [--amp]
Train the UNet on images and target masks
optional arguments:
-h, --help show this help message and exit
--epochs E, -e E Number of epochs
--batch-size B, -b B Batch size
--learning-rate LR, -l LR
Learning rate
--load LOAD, -f LOAD Load model from a .pth file
--scale SCALE, -s SCALE
Downscaling factor of the images
--validation VAL, -v VAL
Percent of the data that is used as validation (0-100)
--amp Use mixed precision这样代码就开始运行了

代码运行结束后,我们每有一个epoch,就会生成一个.pth文件
到此,训练部分就结束了
使用训练好的权重进行预测
先找好需要进行测试的图片
然后在predict.py中:

将model的路径改成我们想使用的权重文件的绝对路径
然后在终端中输入以下指令:
python predict.py -i text.jpg -o output.jpg
#text.jpg是进行测试的原图,output是生成的掩膜结果运行结束,output.jpg就会生成,可以查看
我的text.jpg原图:

生成的output.jpg图像

至此复现结束
以上是关于语义分割项目实战制作语义分割数据集,并使用U-Net进行实战检测的主要内容,如果未能解决你的问题,请参考以下文章