重学Java 8新特性 | 第2讲——Java 8新特性简介
Posted 李阿昀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重学Java 8新特性 | 第2讲——Java 8新特性简介相关的知识,希望对你有一定的参考价值。
请再看我一眼
写在前面
从本讲开始,咱们就要开始正式学习Java 8新特性了,不知大家做好准备没有?做好准备之后,我就要开始发车了。
在这一讲中,我会对大家接下来要学习的Java 8新特性做一个整体的介绍,以便让大家从全局上对Java 8新特性有一个高屋建瓴的认识。
实际上,Java 8早在2014年3月份的时候就发布了,而现在已经是2021年12月份了,童鞋们,七年都已经过去了,你还有什么资格说你没学过Java 8新特性啊!你要知道,你已经学的是七年前的技术了!当然,未曾学过的童鞋也不要灰心,现在开始学一点都不晚,须知种一棵树最好的时间是十年前,其次就是现在,所以接下来请开始你的学习吧!
而且,现在很多框架(例如Spring Boot)的底层都已经在使用Java 8的一些新特性了,例如Lambda表达式、函数式接口等,在上一讲中我就已经提到了。正是由于被开发者们发现了Java 8的一些优点,所以导致它现在应用的非常广泛。但是这并不意味着你工作之后就一定会用到它,因为作为一个盈利的公司来讲,它往往不是追求技术的新,而是追求技术的稳定,所以有可能你进公司之后会发现实际项目依旧用的还是JDK 1.7那老一套,并没有用到Java 8新特性。
有些人可能就说了,既然项目中没有用到Java 8新特性,那还学个毛啊!大家千万不要抱有这种心态,我知道看过我文章的读者们肯定没有这种摆烂的心态,因为你们是可爱的人!这里,我着重强调一遍,Java 8一定是未来的一个趋势,极有可能你公司所上的新项目就用到了,这太有可能了,到时候项目经理扔给你一个项目,让你去熟悉熟悉代码,要是碰到了一些Java 8新特性所带来的代码,那你可不要懵逼哦!
所以,我们现在就应该开始学习并掌握Java 8的那些新特性,至少要对它有一个基本的了解与应用,等到你真在实际项目中遇到了Java 8新特性所带来的代码,你内心就不会害怕了,而且还能很快地第一时间就上手,将它用起来。要是学了它之后,没用到,也不妨碍,毕竟技多不压身嘛!
你能从这套课程中学到什么呢?
这里,我得告诉大家的是,本套系列教程的大部分内容都是来自我本人在实际工作过程中踩过的坑,经过提炼和总结形成的。
那么,作为一个初学者,你能从这套课程中学到什么呢?如下图所示,你可以看到这套系列教程涵盖了Lambda表达式、函数式接口、方法引用与构造器引用、Stream API、接口的默认方法与静态方法、新时间日期API、其他新特性等内容,而这也正是Java 8所具有的新特性。所以,你能学到什么,不用我再废话了吧!
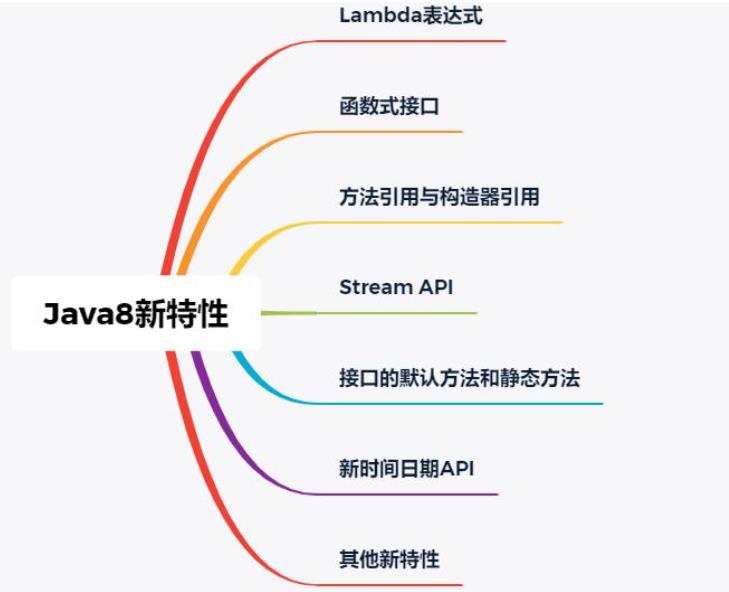
当然,Java 8新特性中最为核心的便是Lambda表达式与Stream API。
Lambda表达式是改动最大的,它是Java 8推出的一种新的语法;至于Stream API,我后面会详细讲到,不过这里我还是稍微提一下,就是有了Stream API之后,我们操作Java中的一些数据,就能如同操作SQL语句那样简单了。例如,我们想通过SQL语句来查询年龄大于35的员工的信息,那么SQL语句是不是就应该像下面这样写啊!
select * from employees where age > 35;
但是只要我们会了Stream API,碰到类似这样的需求,使用Stream API就能解决了,甚至于比SQL语句操作起来还要简单,等到你学到Stream API那块,自然而然就知道了。
Java 8有哪些优点?
现在,Java 8已经被越来越多的人发现它的优点了,那么Java 8对于咱们这些开发者来说,有一些什么样的优点呢?或者说给我们这些程序员带来了一些什么好处呢?见下图便知。
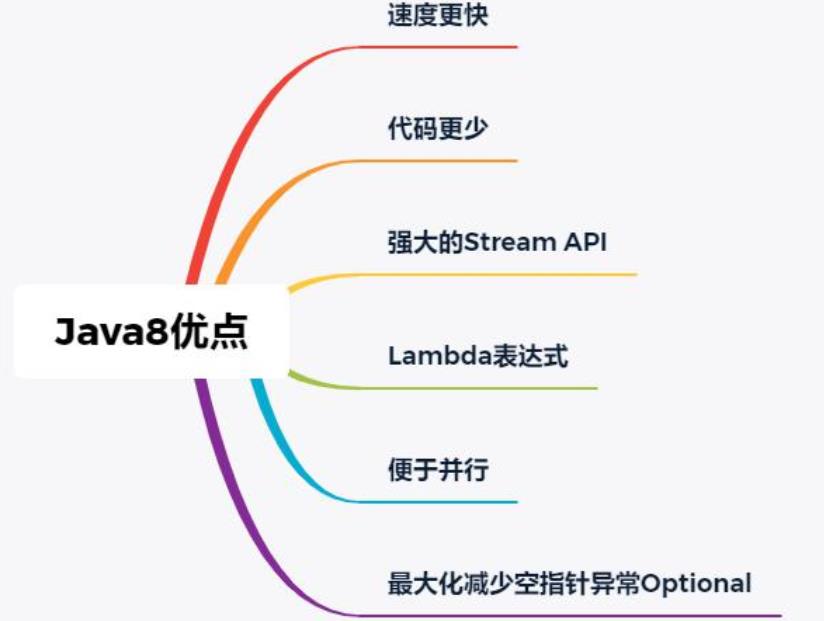
接下来,我就挨个挨个来为大家详细讲一下Java 8的以上每一个优点。
速度更快
Java 8的速度更快实际上体现在多个方面,例如Java 8对于底层的数据结构做了一定的更新和改动,对垃圾回收机制(也即内存结构)也做了一定的改变,以及对并行做了一个扩展和支持,这样我们就可以很容易地进行并行操作了。
接下来,我们就要一点一点来说了,好让大家对Java 8的速度更快更加的深有体会。
更新了底层的数据结构
对于底层的数据结构怎么做的改动就让Java 8的速度更快了呢?下面我们就得来好好分析分析了。
Java 8对于HashMap所做的改动
想必大家也听说过了,Java 8对底层数据结构做的最核心的一个改动便是HashMap,那么Java 8对HashMap做了一个怎么样的改动呢?
我们先回顾回顾HashMap原来是什么样的,它是不是采用的哈希表啊!为什么呢?因为如果HashMap不采用哈希表的话,那么我们往它里面存储元素,是不是就全都是无序的了啊!而且,我们要想往里添加一个元素,且不能重复,那就得通过equals方法去比较两个元素是不是一样的了,就像下图这样,画图不易,请多关注+点赞+收藏!
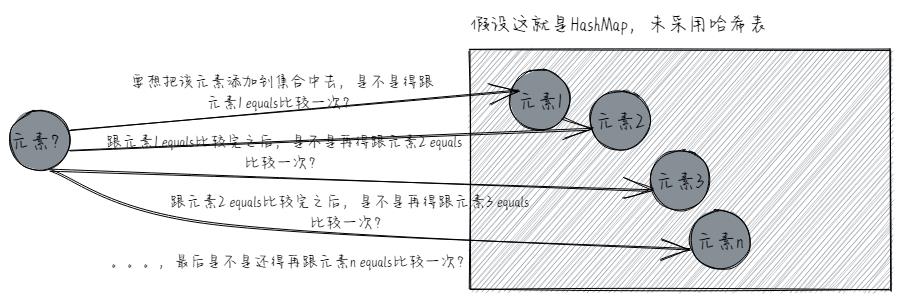
总之,如果HashMap底层不采用哈希表,那么往它里面添加元素,并且还不能重复,就得用equals方法去比较两个元素是不是一样的了。这里,大家需要注意的是,要添加的元素得跟HashMap集合中的每一个元素进行equals比较哟!如果HashMap集合中有一万个元素,你想添加一个新元素,那么就得equals一万次了,真的添加进去之后,你还想再添加一个新元素,那么除了跟之前那个添加进去的元素equals一次之外,还得再跟HashMap集合中的其他每一个元素equals一次。
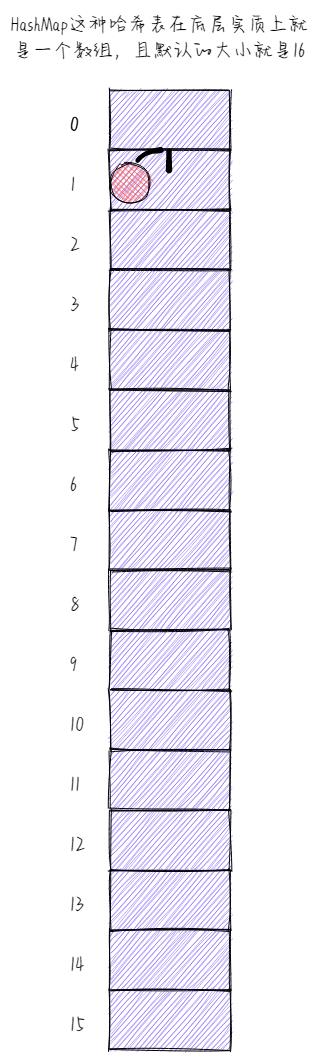
也就是说,如果HashMap底层不采用哈希表(或者哈希算法),那么它的效率是极低的。因此,大家自然就清楚人家开发Java的工程师是怎么做的了,怎么做的呢?实际上就是让HashMap底层去采用哈希表(或者哈希算法)这种数据结构,哈希表在底层实质上就是一个数组,既然是数组,那么它肯定就会有索引值,而且HashMap这种哈希表默认的大小就是16。
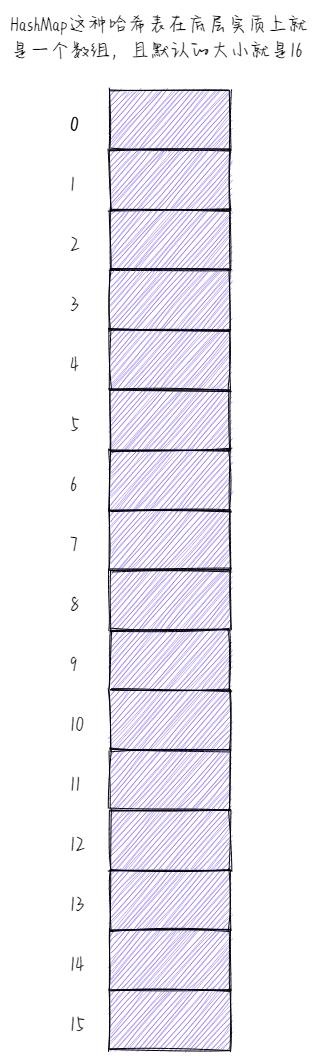
如果HashMap底层采用的是哈希表,那么当我们往里添加一个对象时,首先就会调用该对象的hashCode方法,经hashCode方法运算之后生成一个哈希码值,说白了,就是根据哈希算法算出一个数组的索引值。有了这个数组的索引值之后,HashMap就能根据该索引值很快地找到对象要存储的相应位置了。

找到对应位置之后,首先就会看一下该位置有没有对象在,如果没有对象在的话,那么就直接进行存储。
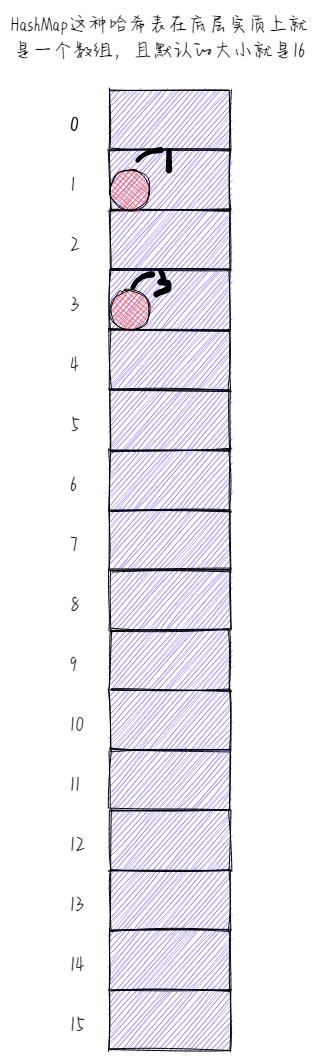
同理,再添加一个对象,也会调用其对应的hashCode方法,经hashCode方法运算之后同样也会生成一个哈希码值,例如3。然后,该对象就会到对应的固定位置(即3索引处)去找有没有对象在,如果没有对象在的话,那么该对象就会被直接存储进去。
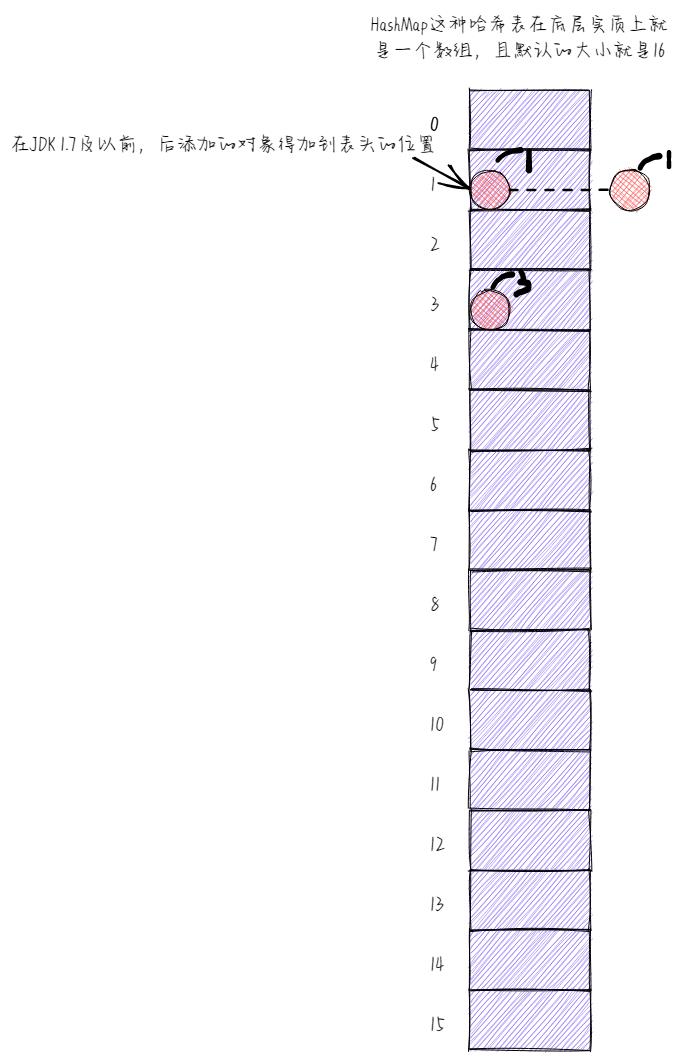
那么相应的就会有另一种情况,就是我们创建了一个对象,该对象经其hashCode方法运算之后生成的哈希码值还是1,此时,在这种情况下,该对象依旧是要到对应的固定位置(即1索引处)去找有没有对象在的,如果有对象在,那么又该怎么办呢?
很显然,现在索引1处是有对象在的!有对象在,没有关系,因为会再通过equals方法比较两个对象的内容。如果内容一样,那么咱们创建的对象的value就会将已有对象的value给覆盖掉,说到底最终只会保留一个对象。
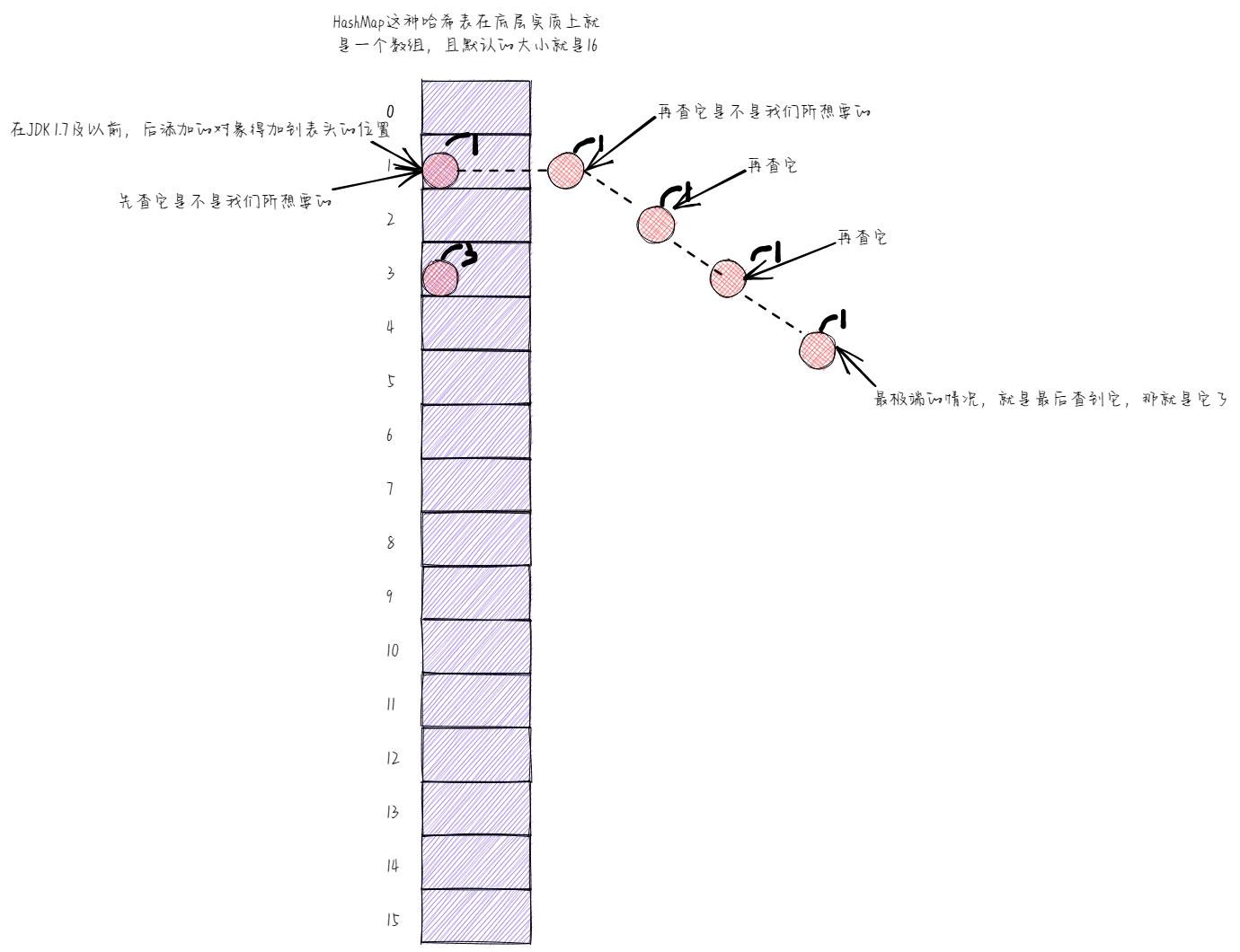
还有一种情况,就是经equals方法比较之后,发现两个对象的内容不一样,如果不一样,那么又该怎么办呢?此时,实际上会形成一个链表,而且在JDK 1.7及以前,形成的链表是这样子的,后添加的对象得在链表前面,即后添加的对象得加到表头。
发生的这种情况,我们就称之为碰撞。很显然,我们应该尽可能的去避免这种情况的发生,为什么呢?
大家不妨试想一下,如果集合中的元素过多的话,那么最终可能会造成一个什么后果呢?是不是效率还是会很低下啊!你想啊,如果此时我们再添加一个对象,而且该对象经其hashCode方法运算之后生成的哈希码值还是1,那么该对象是不是得到对应的固定位置(即1索引处)去找有没有对象在啊,唉😔,发现现在是有的,且还是一个链表,此时那就无话可说了,该对象必须得跟链表中的每一个对象equals比较一次了。
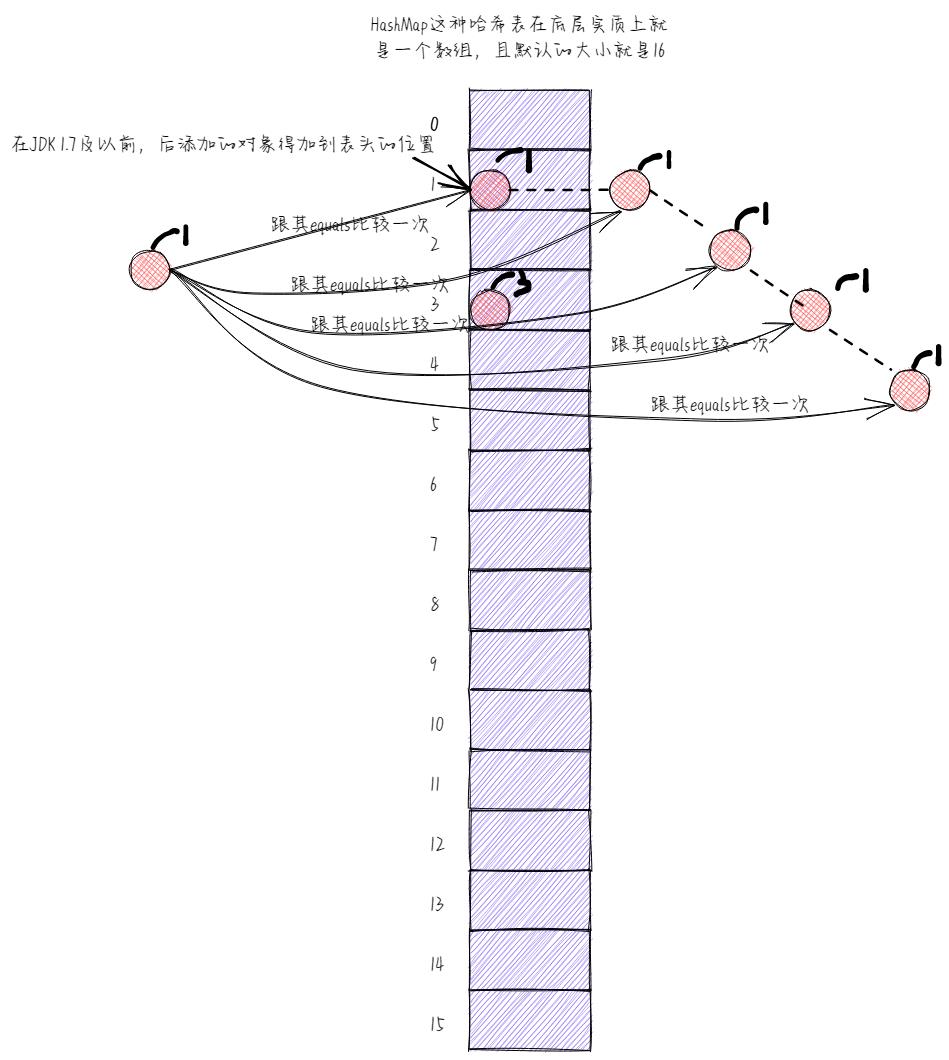
这他妈不就又回到刚开始我们最初的那种状态了嘛,你说,哈希表现在还有没有意义啊?肯定没有嘛!所以,碰撞这种情况我们是要尽可能的去避免的。
既然要避免碰撞这种情况发生,那么我们应该怎么做呢?是不是得重写对象的hashCode方法和equals方法啊,而且重写的时候还要重写的尽量严谨一点,此外,还得让hashCode方法和equals方法保持一致。啥叫保持一致呢?就是相比较的对象只有在哈希码值一样的情况下,才会去比较它们的内容,如果内容一样,那么equals方法就要返回true。
但是,即便hashCode方法和equals方法重写的再严谨,碰撞这种情况我们依旧还是避免不了的,只能是让其发生的概率变得更小而已。
为什么避免不了呢?这我可得好好唠叨了,上面我也说过了,当咱们创建一个对象,想要将其添加到HashMap中去的时候,是不是得调用该对象的hashCode方法生成一个哈希码值啊!注意,哈希码值就是一长串的东东。然后,由于人家HashMap底层采用的是哈希算法,所以生成的哈希码值经哈希算法运算以后就会运算成为一个数组的索引值。
这下就有意思了,因为数组的索引值实际上一共就16个,所以不管你产生什么哈希码值,只要经过运算,运算出的数值一定是在这16个索引的范围内。因此极有可能就有这样的情况发生,就是一下子创建10个对象之后,其中就会有一部分对象经hashCode方法生成的哈希码值通过运算算出来的对应的数组索引值是一样的,所以碰撞这种情况我们是避免不了的。
即使我们把hashCode方法和equals方法写得再好,写得再严谨,碰撞这种情况我们仍然还是避免不了。既然避免不了,那么我们就不能让链表过长了,也就是说不能让链表中的元素过多。
有童鞋可能就会问了,人家HashMap是怎么做到的呢?HashMap提供了一个叫做加载因子的东东,而且默认是0.75。唉😔,这个 加载因子(默认是0.75) 指的是什么啊?它指的是当元素到达现有哈希表容量的75%的时候,就得进行扩容。
想问下大家,能到达100%再扩容吗?用脑子一想,就知道绝不可能。为什么呢?因为有可能就有这样的情况发生啊,就是对象经过哈希算法运算之后,对象就存到数组的1、3索引处,其他索引处就是没有对象存进去,所以说不能到达100%再扩容。既然不能到达100%再扩容,那太小怎么样?也不行,因为会浪费空间。
所以,折中来算,0.75就挺好的,这也就是说当元素到达现有哈希表原来容量的75%的时候就要进行扩容了。一旦扩容,链表里边的每一个元素就得重新排序,也就是说重新经过哈希算法运算,然后找到扩容以后新的位置再存进去。不知道,我这样说,大家能明白否?
这样的话,在某种程度上,碰撞发生的概率是不是就变低了呀!这是原来解决问题的方式。但是,很不幸的是,即便是有了扩容这种机制,碰撞这种情况也是无法避免的,一旦避免不了,那是不是就意味着效率低下啊!
为什么这么说呢?这里我举个例子来说明一下,现在我要查询一个对象,假设也找到了对应位置,比如索引1处,最极端的情况下,我是不是得把链表里边的元素一个一个都找一遍啊,然后找到最后一个之后再将其取出来,这是不是效率就很低下啊!
于是,Java 8就对HashMap做了一个改动,那就不是原来这种数组+链表的结构了,而是在数组+链表的基础之上又多了一个红黑树,即数组+链表+红黑树。注意,红黑树也是二叉树的一种。
那么问题就来了,什么时候能变红黑树呢?大家注意可不是时时刻刻就变哟!只有当碰撞的元素的个数大于8,也就是说当链表长度到达9,并且与此同时整个HashMap总大小(总容量)大于64的时候,才会将链表转成红黑树。
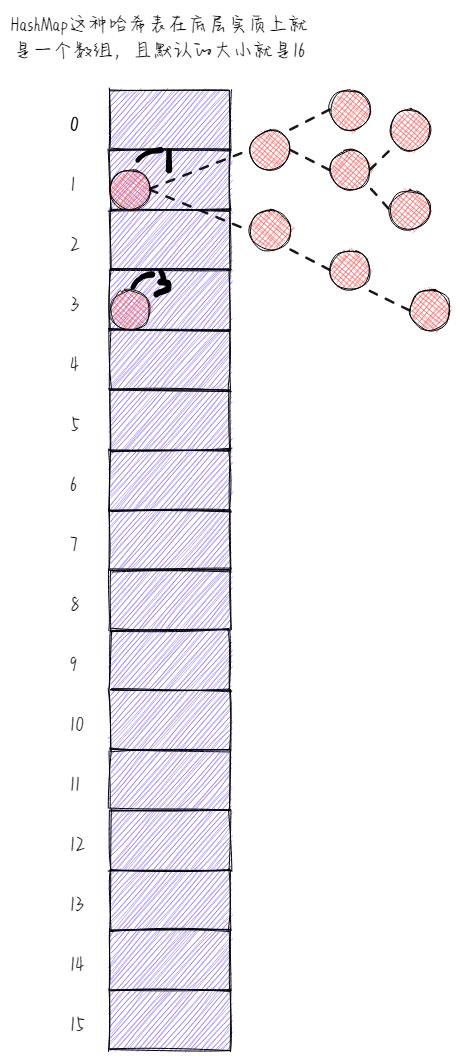
这里,我再说一遍啊!只有当某一个链表长度大于8并且整个HashMap总容量大于64的时候,才会将链表转成红黑树。
那转成红黑树有什么好处呢?好处就是除了添加操作之外,其他操作的效率都比链表要高。
为什么呢?就拿添加操作来说,如果要是链表的话,那么直接加到末尾就完事了。大家一定要注意,Java 8的时候是要加到链表的末尾,而在JDK 1.7及以前,则是要加到链表的表头。如果要是红黑树的话,那么就得根据要添加对象生成的哈希码值依次与红黑树里面的对象进行比较了。
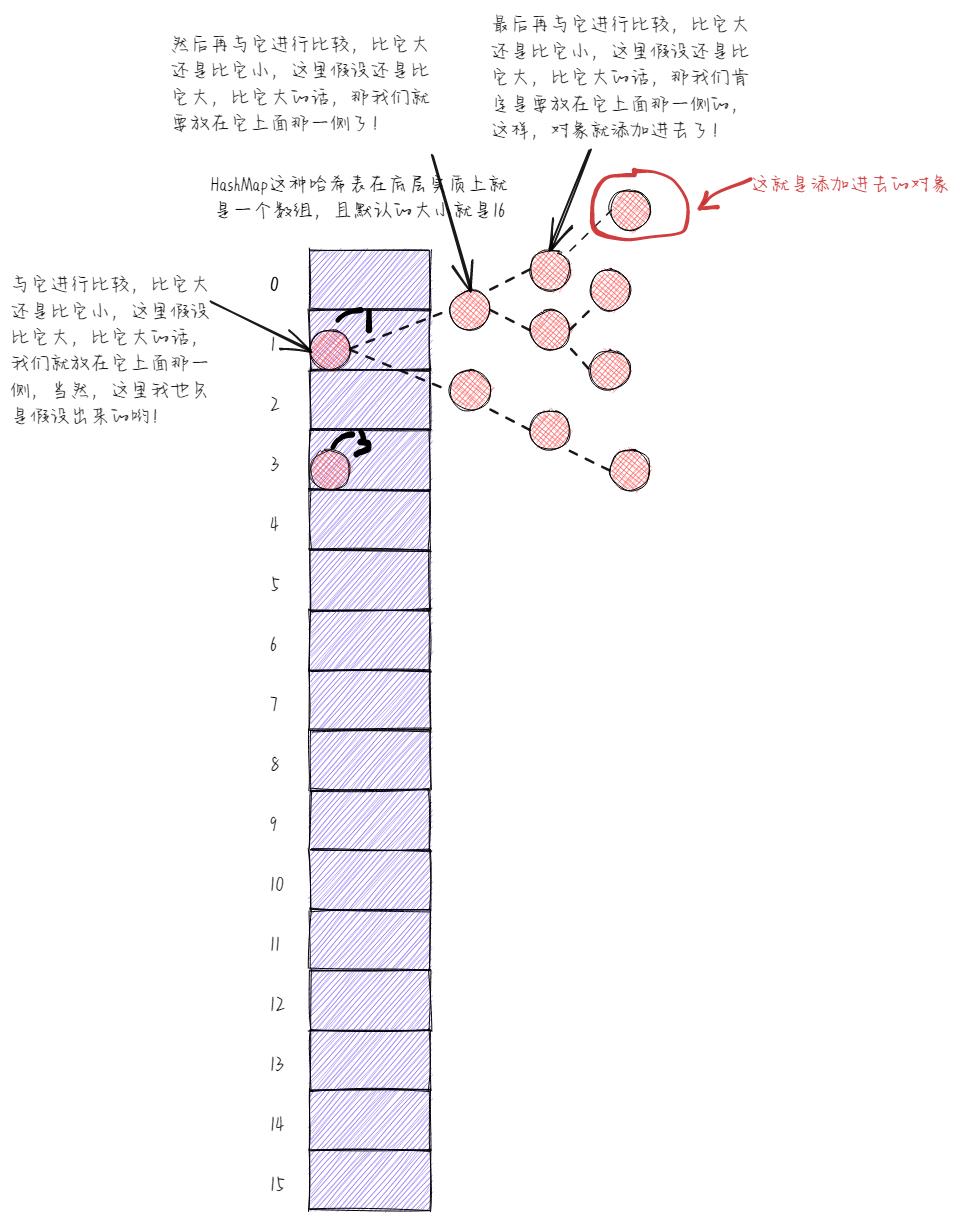
不知道我上面画的示意图大家看不看得懂,应该是蛮清楚的了,要是有不懂的,可以与我一起在评论区进行讨论哟~
现在大家该知道添加元素时,红黑树的效率不如链表高吧!但是,除了添加操作之外,其他操作的效率红黑树都要比链表高。
就拿查询操作来说,看下图,是不是少比了很多次啊,那效率自然就高了。
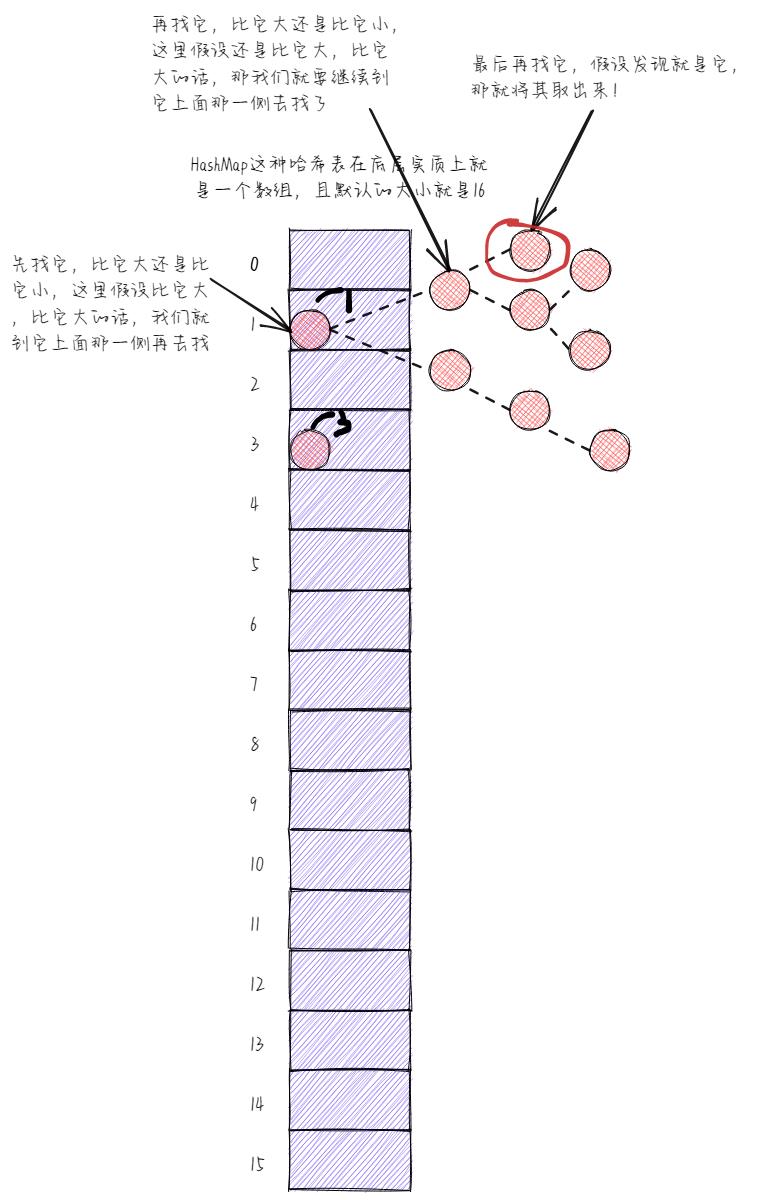
再来看删除操作,如下图所示,同理,是不是也少比了很多次啊,因此效率自然就高了。
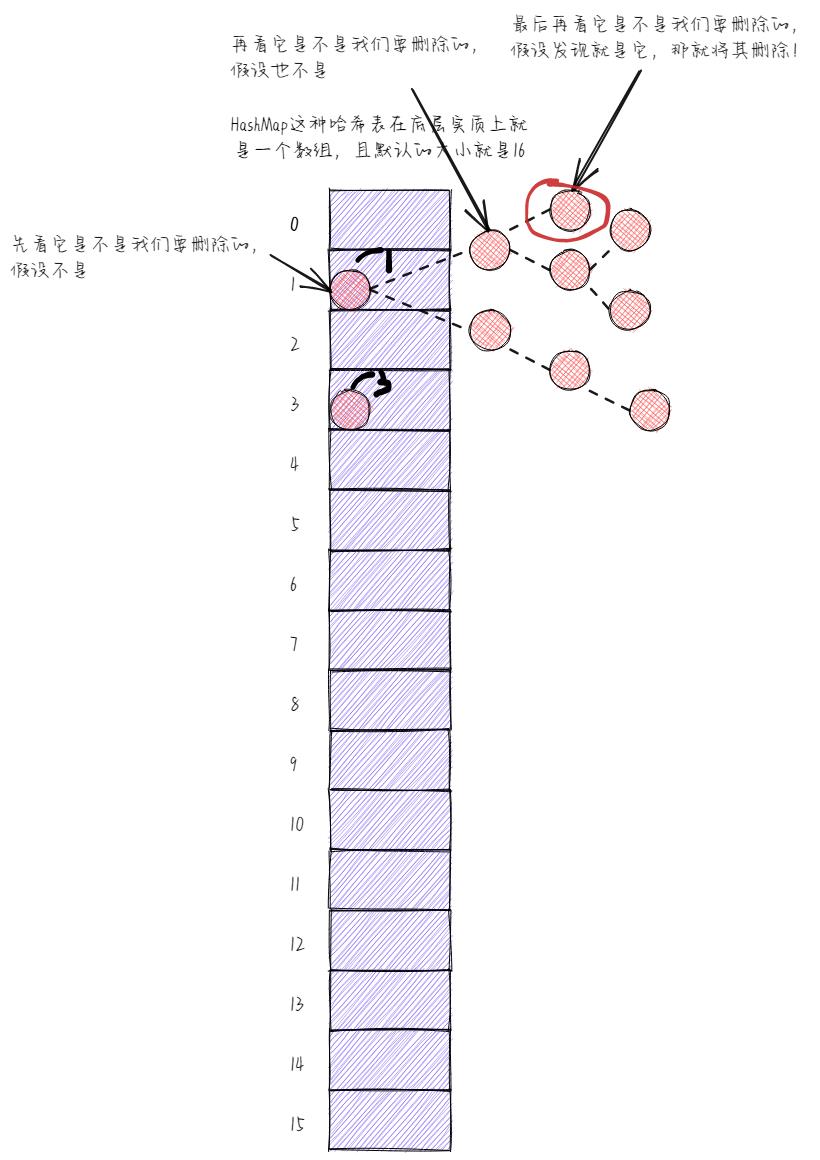
所以,从链表转换成红黑树以后,除了添加操作以外,其他操作的效率都变得高了许多。
此外,HashMap扩容以后,红黑树里面的元素依旧还得重新排序,进行换位置。只不过现在不用再通过哈希算法来运算其哈希码值以便找到它的位置了,那如何找到HashMap扩容以后它对应的位置呢?很简单,只需要通过原来哈希表的总长度加上其当前所在的位置计算出来就完事了。例如,下图被圈中的红黑树中的元素就得存放到17索引处。
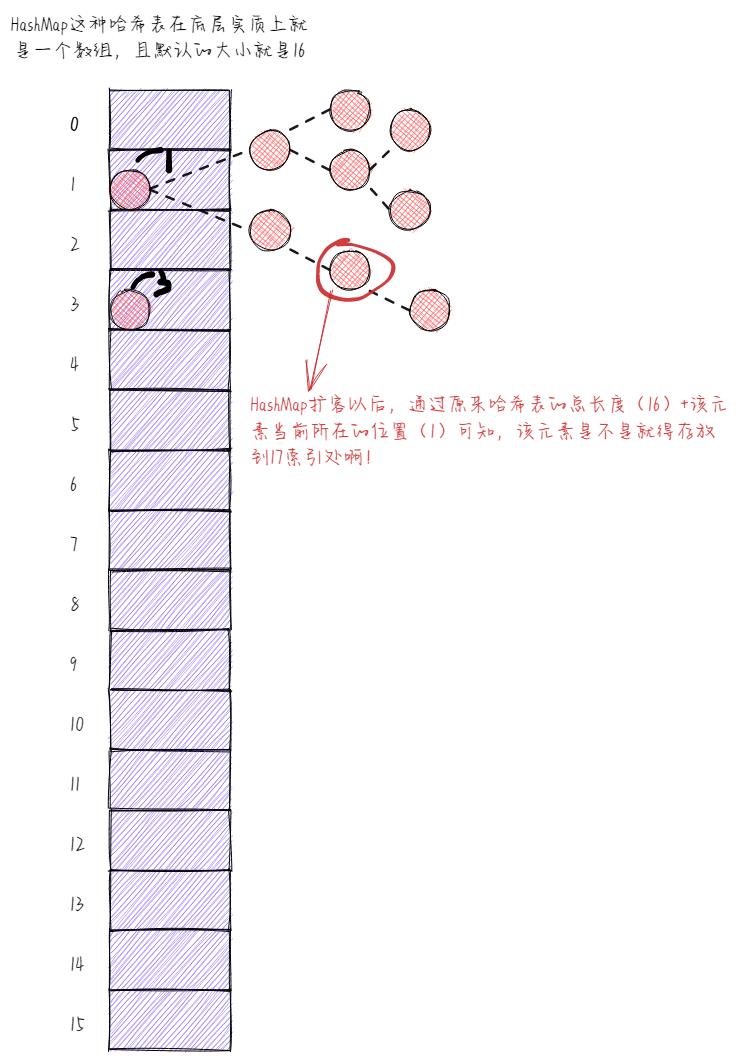
希望我没有讲错,要是真讲错了,大家最好提出修改意见,我一定及时改正!
以上就是Java 8对于HashMap所做的改动。既然HashMap变了,那HashSet是不是也会变啊!这是肯定的啦!
所以,现在只要你将JDK由1.7换成1.8,就算你啥都不用做,效率也会在不知不觉间提升。而且HashMap这种哈希表数据结构在实际开发中应用的也是非常广泛,当然是相对来说啦!当你以后做项目的时候不知道选择哪种数据结构的时候,那就选哈希表吧!
至此,我就为大家讲清楚了Java 8对于HashMap所做的改动,当然啦,肯定还有不足之处,如有错误,请及时指出,我一定勘正!
Java 8对于ConcurrentHashMap所做的改动
上面我已经算是讲清楚了Java 8对于HashMap所做的改动,而且大家也知道了,HashSet也会随之发生改动。除此之外,其实还有一个跟Map相关的东东也会发生改动,那就是ConcurrentHashMap,Java 8对其也进行了升级,相信大家之前应该有用过它,就算没用过那也听说过,对吧?
在JDK 1.7的时候,ConcurrentHashMap是不是有个并发级别啊,而且默认是16,即concurrentLevel = 16,大家应该知道这点吧!而且,此时ConcurrentHashMap采用的还是锁分段机制,如下图所示。
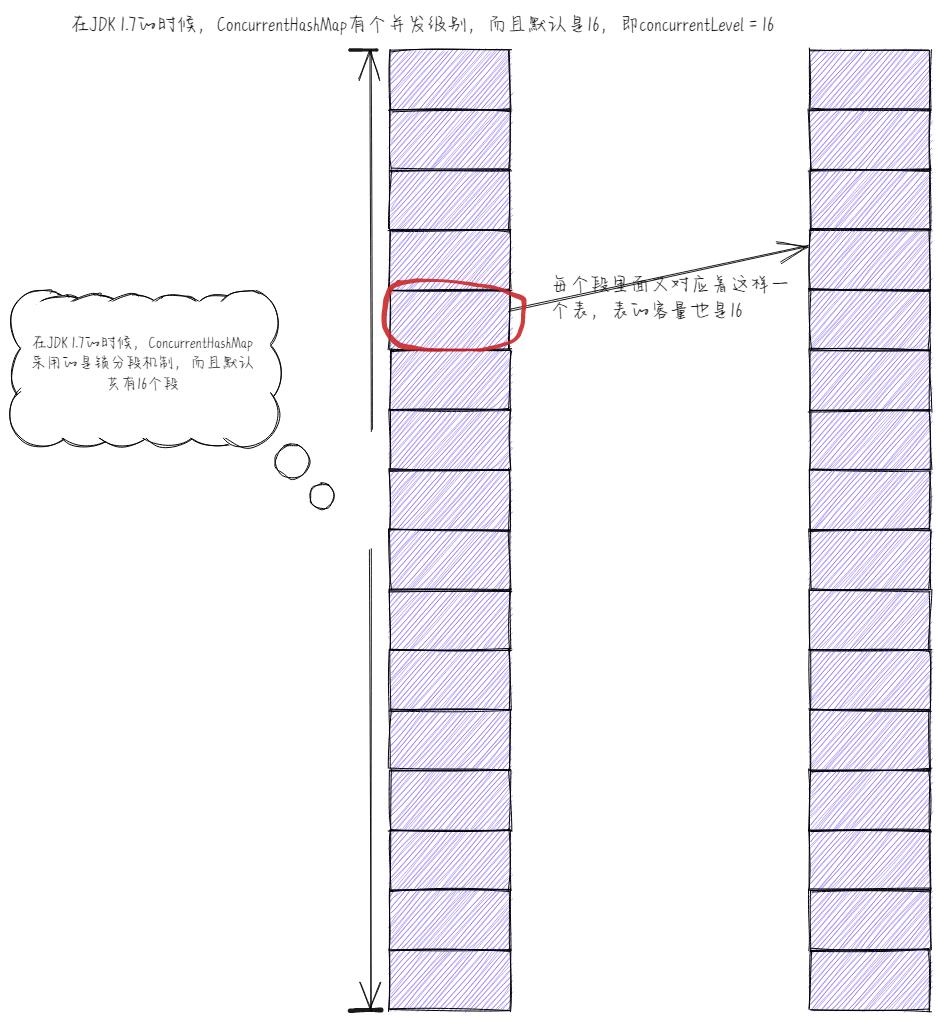
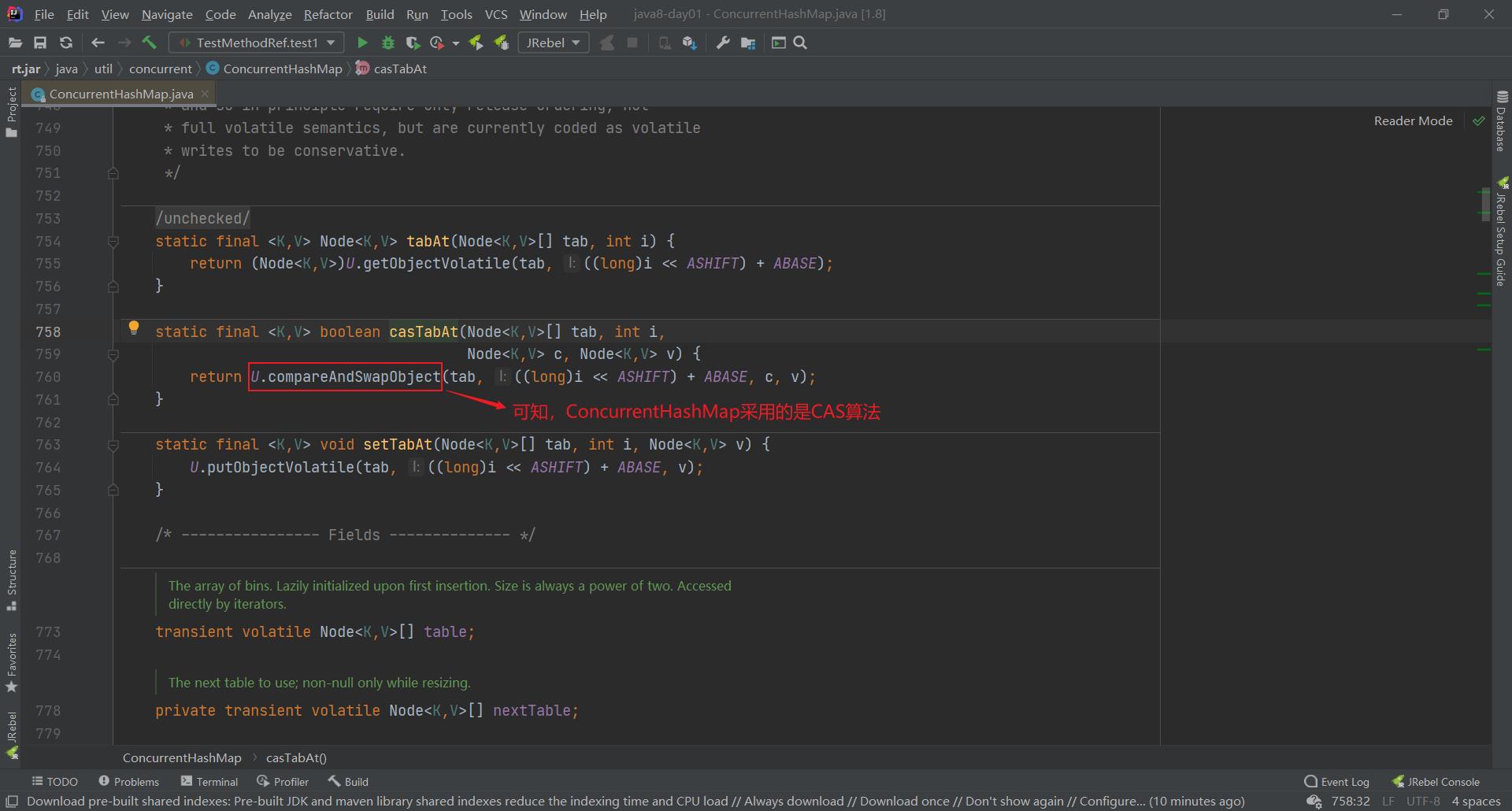
但是,在Java 8中,段就几乎没有用了,给改成了CAS算法,而且我们可以称CAS算法为无锁算法。下面,我们不妨去看一看ConcurrentHashMap的源码,如下图所示,当我们put添加元素时,人家putVal方法里面的注释是不是写得无锁添加啊!
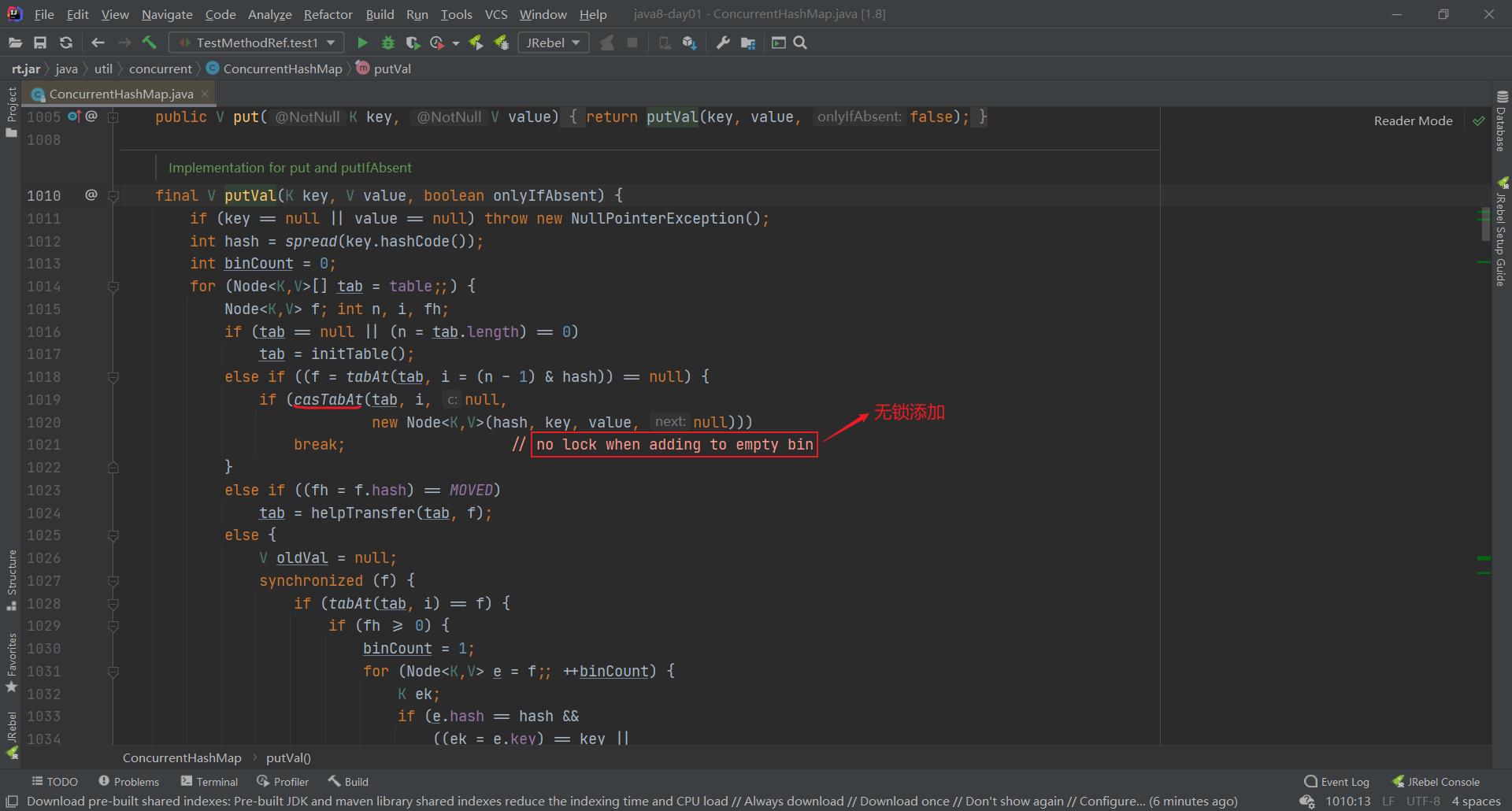
大家再点进去casTabAt方法里面去看一看,如下图所示,可以看到该方法又调用了底层的compareAndSwapObject方法。大家现在该知道ConcurrentHashMap底层采用的是CAS算法(也即无锁算法)了吧!
所以,在Java 8中,所谓的段就被取消了,为什么会被取消呢?因为ConcurrentHashMap的并发级别不太好评定,如果并发级别太大,那么有可能某些段里边就没有元素,这样就会导致浪费很多的空间;如果并发级别太小,那么有可能会导致某些段里边的元素过多,这样效率又会变得很低下。
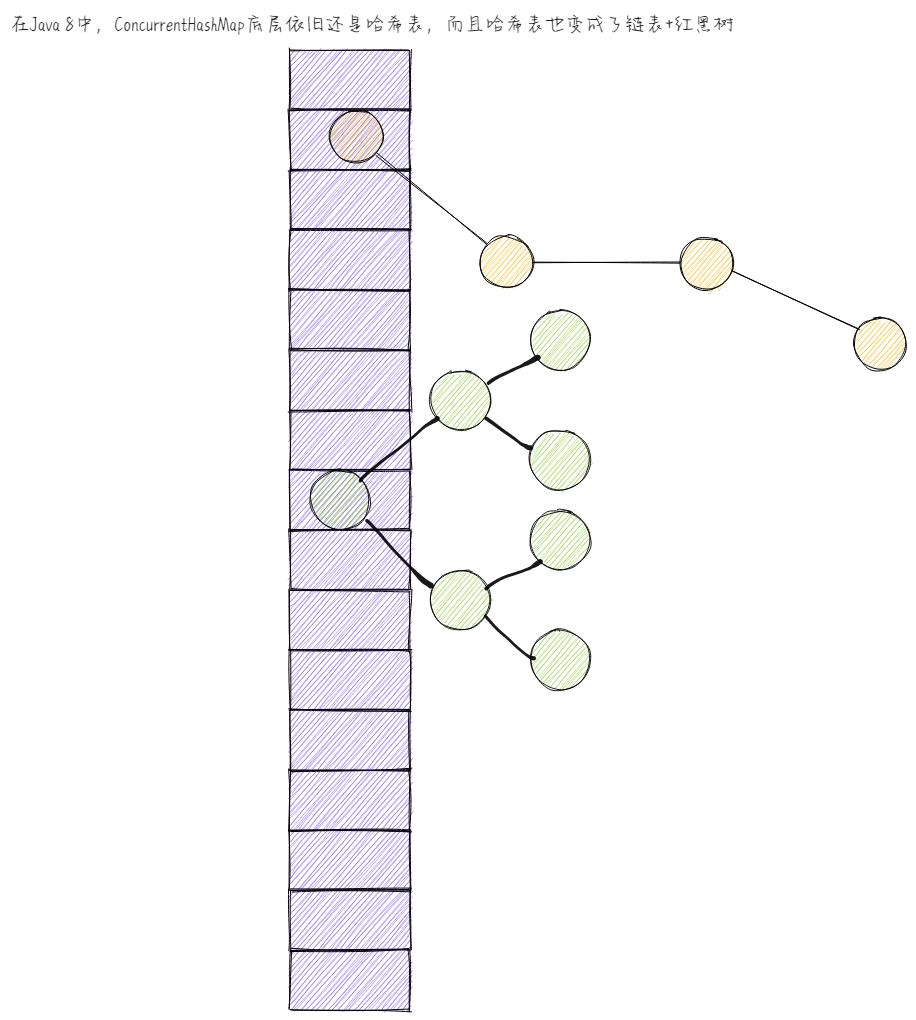
其实,ConcurrentHashMap也采用了哈希算法,这样,它底层是不是还是哈希表啊,而且哈希表也变成了链表+红黑树,这样,效率是不是也得到了提升啊!
并且,由于ConcurrentHashMap底层采用的是CAS算法,CAS算法又是底层操作系统支持的算法,很显然它会比锁的效率要高,所以从这方面来说,ConcurrentHashMap的效率也得到了提高。
至此,我就为大家讲清楚了Java 8对于ConcurrentHashMap所做的改动。希望大家能对我讲的东西稍微理解一下,这样你也有得跟面试官聊,不至于说一问三不知。
更新了底层的内存结构
我们说Java 8速度更快,其一是因为它对于底层数据结构进行了一个改动;其二是因为它对底层内存结构也做了一个改动。接下来,我们就来好好唠唠Java 8对底层内存结构所做的改动。
还记得原来我们画内存图的时候,是怎样画的吗?瞧一瞧,是不是像下面这样画的啊!
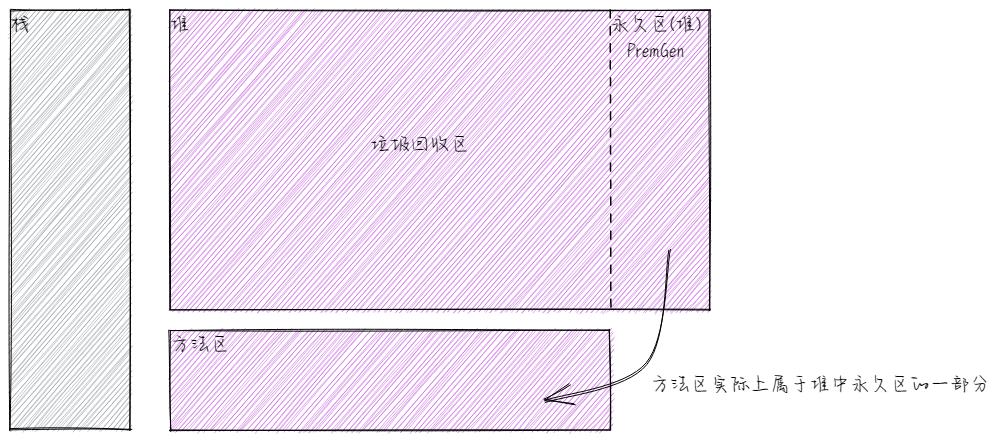
实际上方法区这块应该是非堆,但是又算是堆中永久区的一部分,我自己都感觉这句话很矛盾,姑且先这样写吧!
这里先问大家一个问题,有人知道永久区实际上存的都是些什么吗?不知道的童鞋还是由我来告诉吧,永久区主要存储的就是一些加载类的信息,例如JDK中的核心类库都会被加载到这。总之,大家要知道一点,就是当我们加载一个类时,类的信息会全存在方法区中。
再问大家一个问题,永久区里面的内容会不会被垃圾回收机制所回收?答案是几乎不会,换言之,永久区里面的内容是会被垃圾回收机制所回收的,只不过回收的条件比较苛刻。
有童鞋可能会有所疑问,既然方法区属于堆内存中永久区的一部分,为什么每次在画内存图的时候我们都要像上图一样把方法区画在堆外面来呢?
有一部分原因是因为JVM厂商实际上是有很多种,例如有:
- HotSpot:sun公司提供的,当然现在它属于Oracle了,它也是我们现在常用的JVM。
- JRocket:Oracle自己本身原来的JVM。
- J9 JVM:IBM自己的JVM。
- Taobao JVM:我们国产JVM。
实际上,早在JDK 1.7以前的时候,除了HotSpot以外,其他厂商的JVM早就没有所谓的永久区了,而且这些JVM厂商也已经把方法区从永久区里面剥离出来了。当然,HotSpot同样也在做着相同的努力,即逐渐地将方法区从永久区中剥离出来。所以,平时我们画内存图的时候,就不把方法区画到堆里面去了。
于是,在Java 8的时候,永久区就彻底的被干掉了,即没有永久区了,取而代之的是MetaSpace,我们称之为元空间。元空间相较于原来的方法区,最大的不同之处在于元空间直接使用的是物理内存,而不是我们自己去分配的内存。
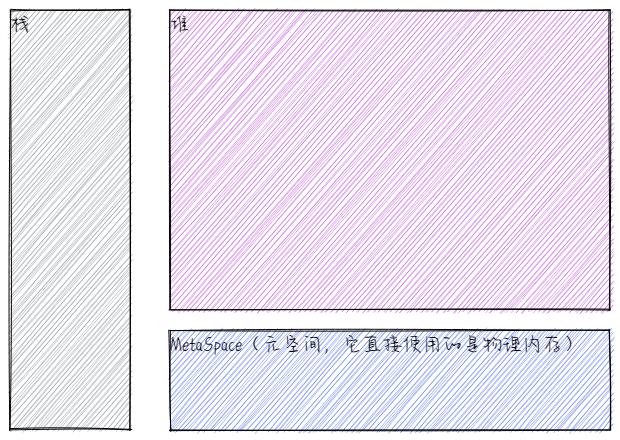
什么是物理内存呢?就是下面这个东东,明白了吧!
这也就是说,只要物理内存有多大,元空间就能应用多大,这便是元空间所带来的好处。
既然元空间首先使用的就是物理内存,那么这意味着垃圾回收机制也是一直在优化。之前我们就已说过,虽然永久区(或者方法区)中的内容回收的条件比较苛刻,但是它仍然还是能被回收,例如当永久区(或者方法区)快要满的时候,垃圾回收机制就会对其里面的内容进行回收。
而现在是不是只有当元空间快要满(或者容量过大、超标了)的时候,垃圾回收机制才会开始运行起来进行回收啊!只不过此时垃圾回收机制运行的概率变小了很多,因为元空间直接使用的是物理内存,而物理内存又是很大的,是很难被撑爆的!
相信大家现在也明白了一点,就是由于此时垃圾回收机制运行的概率变小了很多,所以效率必然就会有所提升。
我们都知道,类的加载信息现在是全都存元空间了,既然如此,那我就要问大家一个问题了,就是OOM(即Out Of Memory)这个错误还会发生吗?答案是会,只不过发生的概率极低。因为元空间现在直接使用的是物理内存,想要物理内存被撑爆,那还是挺难的,如果真的想要被撑爆的话,除非你开发的应用程序就是专门用于加载.class字节码文件的,一下子把一亿个类文件都加载到内存中来,那才会有可能。
最后,我还得多说一嘴,就是现在永久区这块内存空间都没了,那么相应地JVM调优的参数是不是也得随之变啊!之前JVM调优的时候,想必大家用过PremGenSize、MaxPremGenSize这两个参数吧!现在,这俩参数在Java 8中就无效了,取而代之的是MetaSpaceSize和MaxMetaSpaceSize。这也就是说,虽然默认物理内存多大,元空间就能应用多大,但是我们还是可以去配置元空间的大小。
以上就是Java 8对底层内存结构上的一个改动,希望我是为大家讲清楚了。
代码更少(增加了新的语法,即Lambda表达式)
由于Java 8增加了一个新的语法,即Lambda表达式,所以大家以后写的代码就会变得更少更简洁了,同时,代码的可读性也会得到提高。
强大的Stream API
Java 8提供了一个强大的Stream API。有多强大呢?其实,上面我就已经说过了,只要有了这个强大的Stream API,那么我们在Java中操作数据就能像操作SQL语句那么简单了,甚至于比SQL语句还要简单。
便于并行
不知道大家有没有接触过Fork/Join框架(即分支合并框架),要是有接触过的话,并行流应该不是太陌生。
一般来说,讲解Fork/Join框架时,都会以实现数的累加操作(比如说计算1到100亿之间的和)为例来进行讲解。就拿计算1到100亿之间的和这个简单需求来说,要想解决该需求,我们是不是还得自己写算法啊,算法是怎样的呢?算法应该是这样的,即将这些数劈成两半,然后再劈两半,直至劈到不能再劈为止,是不是很麻烦啊!这样一个简单的需求,我们就得写半天代码,实际开发当中哪有这么简单的需求啊!
所以,原来的Fork/Join框架应用的人并不是特别的多,就是因为代码写起来难,还容易出错。
于是,在Java 8中,它就对Fork/Join框架进行了一个大幅度的提升,这样,我们就能很方便地从串行切换到并行,因为只需要调用一个方法即可。到时候我会为大家演示如何在Java 8中使用并行流计算1到100亿(或者500亿)之间的和,你将会看到在Java 8中我们只需要写几行代码就能搞定了。
总之,Java 8对Fork/Join框架进行了一个提升,也就是说对并行流进行了优化,这样,我们就可以很容易地对数据进行并行操作了。这从一方面来说,是不是也提升了效率啊!
最大化减少空指针异常(使用Optional容器类可以最大化减少空指针异常)
我想在座的各位肯定都遇到过空指针异常吧!只要是一个程序员,他就一定会遇到空指针异常,要是没遇到,那他就不是一个真正的程序员,压根就没敲过代码。
原来我们解决一个空指针异常,有的时候还是挺麻烦的,因为我们得Debug一步一步来调试,看是哪儿发生的空指针异常,所以空指针异常对于我们程序员来讲还是非常头疼的。
于是,在Java 8中,它就最大化的减少了空指针异常的发生。那么Java 8是如何做到这一点的呢?很简单,它提供了一个Optional容器类,我们以后只须将有可能为空的对象封装到该Optional容器类里面就可以最大化的解决空指针异常。
至此,Java 8的所有优点我就为大家介绍完了。唉😔,这篇文章写的真是累死我了,一点一点写,写了大概有3天了,才算是写毕,文章创作不易啊,所以请大家猛烈关注我吧!
以上是关于重学Java 8新特性 | 第2讲——Java 8新特性简介的主要内容,如果未能解决你的问题,请参考以下文章
重学Java 8新特性 | 第2讲——Java 8新特性简介
重学Java 8新特性 | 第1讲——我们为什么要学习Java 8新特性?