AdaptiveAvgPool3dpytorch教程
Posted CV-杨帆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AdaptiveAvgPool3dpytorch教程相关的知识,希望对你有一定的参考价值。
目录
b站视频: https://www.bilibili.com/video/BV1va411D7Ua
1 torch.nn > AdaptiveAvgPool3d
1.1 相关资料
官方文档:https://pytorch.org/docs/stable/generated/torch.nn.AdaptiveAvgPool3d.html
参考资料:
https://runebook.dev/zh-CN/docs/pytorch/generated/torch.nn.adaptiveavgpool3d
Pytorch常用Layer深度理解:https://zhuanlan.zhihu.com/p/371167523
1.2 CLASS torch.nn.AdaptiveAvgPool3d(output_size)
Applies a 3D adaptive average pooling over an input signal composed of several input planes.
对由多个输入平面组成的输入信号进行三维自适应平均池化
The output is of size D x H x W, for any input size. The number of output features is equal to the number of input planes.
对于任何输入尺寸,输出的尺寸为D×H×W。输出特征的数量等于输入平面的数量。
1.3 Parameters 参数
output_size – the target output size of the form D x H x W. Can be a tuple (D, H, W) or a single number D for a cube D x D x D. D, H and W can be either a int, or None which means the size will be the same as that of the input.
output_size –目标输出大小,格式为D x H x W。可以是元组(D,H,W),也可以是多维数据集D xD x D的单个数字D。D,H和W可以是 int 或“ None ,这意味着大小将与输入的大小相同。
1.4 Shape

我从视频流的角度来对Shape进行解释
N表示batch_size、C代表channels、D是视频流的深度、H是每帧图像的高度,W是每帧图像的宽度
视频流,每帧都是一个或RGB或灰度图,且每帧的通道数都是一样的,假设为3,对于一 个固定的视频流,其应用Conv3d的输入大小应为(1,3, d, h, w), 其中1等于batch size, 3等于输入channels, d是视频流的深度,h是每帧图像的高度,w是每帧图像的宽度。
2 测试
2.1 可视化
【腾讯文档】AdaptiveAvgPool3d:https://docs.qq.com/slide/DWGlMU0ppa1RlcVJW
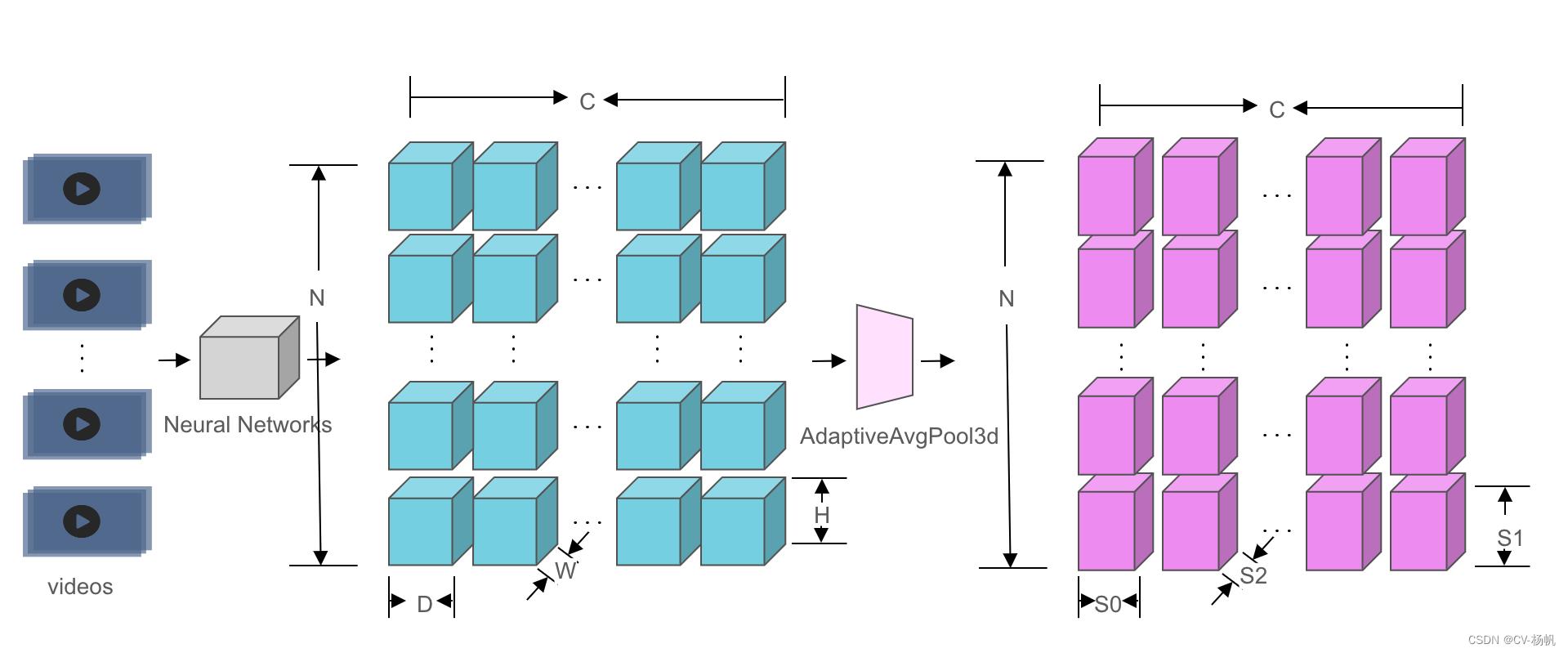
2.2 平台
这个例子我在极链AI平台测试:https://cloud.videojj.com/auth/register?inviter=18452&activityChannel=student_invite
2.3 代码

import torch
import torch.nn as nn
# target output size of 5x7x9
m = nn.AdaptiveAvgPool3d((5,7,9))
input = torch.randn(5, 64, 8, 9, 10)
output = m(input)
print("input.shape:",input.shape)
print("output.shape:",output.shape)
input.shape: torch.Size([5, 64, 8, 9, 10])
output.shape: torch.Size([5, 64, 5, 7, 9])
import torch
import torch.nn as nn
# target output size of 7x7x7 (cube)
m = nn.AdaptiveAvgPool3d(7)
input = torch.randn(5, 64, 10, 9, 8)
output = m(input)
print("input.shape:",input.shape)
print("output.shape:",output.shape)
input.shape: torch.Size([5, 64, 10, 9, 8])
output.shape: torch.Size([5, 64, 7, 7, 7])
import torch
import torch.nn as nn
# target output size of 7x9x8
m = nn.AdaptiveAvgPool3d((7, None, None))
input = torch.randn(1, 64, 10, 9, 8)
output = m(input)
print("input.shape:",input.shape)
print("output.shape:",output.shape)
input.shape: torch.Size([1, 64, 10, 9, 8])
output.shape: torch.Size([1, 64, 7, 9, 8])
3 paddle关于AdaptiveAvgPool3d
官网链接:https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/nn/AdaptiveAvgPool3D_cn.html

以上是关于AdaptiveAvgPool3dpytorch教程的主要内容,如果未能解决你的问题,请参考以下文章