Android开发笔记(一百四十一)读取PPT和PDF文件
Posted aqi00
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Android开发笔记(一百四十一)读取PPT和PDF文件相关的知识,希望对你有一定的参考价值。
读取ppt文件
读取纯文本
上一篇博文讲到在android上如何读取word文件内容,那么office三剑客中还剩ppt文件的读取。前面解析word文件和excel文件时,都用到了poi库读取文件内容,对于ppt一样也可以通过poi读取幻灯片中的文本。HSLFSlideShow类就是poi中专门用于解析幻灯片的工具类,每张幻灯片又分别由单独的HSLFSlide类处理,幻灯片中的具体图文内容则由HSLFTextParagraph和HSLFTextRun进行分辨。下面是使用poi解析ppt文件(2003格式)的效果图:

不同版本的poi库在解析ppt的代码略有区别,下面是使用poi15读取ppt的代码:
public static ArrayList<String> readPPT(String path) {
ArrayList<String> contentArray = new ArrayList<String>();
try {
FileInputStream fis = new FileInputStream(new File(path));
HSLFSlideShow hslf = new HSLFSlideShow(fis);
List<HSLFSlide> slides = hslf.getSlides();
for (int i = 0; i < slides.size(); i++) {
String content = "";
HSLFSlide item = slides.get(i);
// 读取一张幻灯片的内容(包括标题)
List<List<HSLFTextParagraph>> tps = item.getTextParagraphs();
for (int j = 0; j < tps.size(); j++) {
List<HSLFTextParagraph> tps_row = tps.get(j);
for (int k = 0; k < tps_row.size(); k++) {
HSLFTextParagraph tps_item = tps_row.get(k);
List<HSLFTextRun> trs = tps_item.getTextRuns();
for (int l = 0; l < trs.size(); l++) {
HSLFTextRun trs_item = trs.get(l);
content = String.format("%s%s\\n", content, trs_item.getRawText());
}
}
}
contentArray.add(content);
}
} catch (Exception e) {
e.printStackTrace();
}
return contentArray;
}读取图文样式
poi方式只能有效读取ppt内部的文字信息,对于ppt内带的图片以及文字样式,便力有不逮了。在博文《Android开发笔记(一百四十)Word文件的读取与显示》中,提到可以解析docx内部的document.xml文件,从xml标记中获取图片信息与样式信息,然后把图文格式构造成html文件,最后由WebView网页视图加载显示html。对于pptx文件,也可以解析pptx内部的slide*.xml幻灯片文件,采用跟解析docx类似的做法,把解析得到的图片与样式数据写入到html文件,从而曲线实现了pptx文件的读取功能。下面是以HTML格式显示pptx文件的效果图:

下面是解析pptx并生成htmml文件的主要代码:
private void readPPTX(String pptPath) {
try {
ZipFile pptxFile = new ZipFile(new File(pptPath));
int pic_index = 1; // pptx中的图片名从image1开始,所以索引从1开始
for (int i = 1; i < 100; i++) { // 最多支持100张幻灯片
String filePath = String.format("%s%d.html", FileUtil.getFileName(pptPath), i);
String htmlPath = FileUtil.createFile("html", filePath);
Log.d(TAG, "i="+i+", htmlPath=" + htmlPath);
output = new FileOutputStream(new File(htmlPath));
presentPicture = 0;
output.write(htmlBegin.getBytes());
ZipEntry sharedStringXML = pptxFile.getEntry("ppt/slides/slide" + i + ".xml"); // 获取每张幻灯片
InputStream inputStream = pptxFile.getInputStream(sharedStringXML);
XmlPullParser xmlParser = Xml.newPullParser();
xmlParser.setInput(inputStream, "utf-8");
boolean isTitle = false; // 标题
boolean isTable = false; // 表格
boolean isSize = false; // 文字大小
boolean isColor = false; // 文字颜色
boolean isCenter = false; // 居中对齐
boolean isRight = false; // 靠右对齐
boolean isItalic = false; // 斜体
boolean isUnderline = false; // 下划线
boolean isBold = false; // 加粗
int event_type = xmlParser.getEventType();// 得到标签类型的状态
while (event_type != XmlPullParser.END_DOCUMENT) {// 循环读取流
switch (event_type) {
case XmlPullParser.START_TAG: // 开始标签
String tagBegin = xmlParser.getName();
if (tagBegin.equalsIgnoreCase("ph")) { // 判断是否标题
String titleType = getAttrValue(xmlParser, "type", "text");
if (titleType.equals("text")) {
isTitle = false;
} else {
isTitle = true;
isSize = true;
if (titleType.equals("ctrTitle")) {
output.write(centerBegin.getBytes());
isCenter = true;
output.write(String.format(fontSizeTag, getSize(60)).getBytes());
} else if (titleType.equals("subTitle")) {
output.write(centerBegin.getBytes());
isCenter = true;
output.write(String.format(fontSizeTag, getSize(24)).getBytes());
} else if (titleType.equals("title")) {
output.write(String.format(fontSizeTag, getSize(44)).getBytes());
}
}
}
if (tagBegin.equalsIgnoreCase("pPr") && !isTitle) { // 判断对齐方式
String align = getAttrValue(xmlParser, "algn", "l");
xmlParser.getAttributeValue(0);
if (align.equals("ctr")) {
output.write(centerBegin.getBytes());
isCenter = true;
}
if (align.equals("r")) {
output.write(divRight.getBytes());
isRight = true;
}
}
if (tagBegin.equalsIgnoreCase("srgbClr")) { // 判断文字颜色
String color = xmlParser.getAttributeValue(0);
output.write(String.format(spanColor, color).getBytes());
isColor = true;
}
if (tagBegin.equalsIgnoreCase("rPr")) {
if (!isTitle) {
// 判断文字大小
String sizeStr = getAttrValue(xmlParser, "sz", "2800");
int size = getSize(Integer.valueOf(sizeStr)/100);
output.write(String.format(fontSizeTag, size).getBytes());
isSize = true;
}
// 检测到加粗
String bStr = getAttrValue(xmlParser, "b", "");
if (bStr.equals("1")) {
isBold = true;
}
// 检测到斜体
String iStr = getAttrValue(xmlParser, "i", "");
if (iStr.equals("1")) {
isItalic = true;
}
// 检测到下划线
String uStr = getAttrValue(xmlParser, "u", "");
if (uStr.equals("sng")) {
isUnderline = true;
}
}
if (tagBegin.equalsIgnoreCase("tbl")) { // 检测到表格
output.write(tableBegin.getBytes());
isTable = true;
} else if (tagBegin.equalsIgnoreCase("tr")) { // 表格行
output.write(rowBegin.getBytes());
} else if (tagBegin.equalsIgnoreCase("tc")) { // 表格列
output.write(columnBegin.getBytes());
}
if (tagBegin.equalsIgnoreCase("pic")) { // 检测到图片
ZipEntry pic_entry = FileUtil.getPicEntry(pptxFile, "ppt", pic_index);
if (pic_entry != null) {
byte[] pictureBytes = FileUtil.getPictureBytes(pptxFile, pic_entry);
writeDocumentPicture(i, pictureBytes);
}
pic_index++; // 转换一张后,索引+1
}
if (tagBegin.equalsIgnoreCase("p") && !isTable) {// 检测到段落,如果在表格中就无视
output.write(lineBegin.getBytes());
}
// 检测到文本
if (tagBegin.equalsIgnoreCase("t")) {
if (isBold == true) { // 加粗
output.write(boldBegin.getBytes());
}
if (isUnderline == true) { // 检测到下划线,输入<u>
output.write(underlineBegin.getBytes());
}
if (isItalic == true) { // 检测到斜体,输入<i>
output.write(italicBegin.getBytes());
}
String text = xmlParser.nextText();
output.write(text.getBytes()); // 写入文本
if (isItalic == true) { // 输入斜体结束标签</i>
output.write(italicEnd.getBytes());
isItalic = false;
}
if (isUnderline == true) { // 输入下划线结束标签</u>
output.write(underlineEnd.getBytes());
isUnderline = false;
}
if (isBold == true) { // 输入加粗结束标签</b>
output.write(boldEnd.getBytes());
isBold = false;
}
if (isSize == true) { // 输入字体结束标签</font>
output.write(fontEnd.getBytes());
isSize = false;
}
if (isColor == true) { // 输入跨度结束标签</span>
output.write(spanEnd.getBytes());
isColor = false;
}
// if (isCenter == true) { // 输入居中结束标签</center>。要在段落结束之前再输入该标签,因为该标签会强制换行
// output.write(centerEnd.getBytes());
// isCenter = false;
// }
if (isRight == true) { // 输入区块结束标签</div>
output.write(divEnd.getBytes());
isRight = false;
}
}
break;
// 结束标签
case XmlPullParser.END_TAG:
String tagEnd = xmlParser.getName();
if (tagEnd.equalsIgnoreCase("tbl")) { // 输入表格结束标签</table>
output.write(tableEnd.getBytes());
isTable = false;
}
if (tagEnd.equalsIgnoreCase("tr")) { // 输入表格行结束标签</tr>
output.write(rowEnd.getBytes());
}
if (tagEnd.equalsIgnoreCase("tc")) { // 输入表格列结束标签</td>
output.write(columnEnd.getBytes());
}
if (tagEnd.equalsIgnoreCase("p")) { // 输入段落结束标签</p>,如果在表格中就无视
if (isTable == false) {
if (isCenter == true) { // 输入居中结束标签</center>
output.write(centerEnd.getBytes());
isCenter = false;
}
output.write(lineEnd.getBytes());
}
}
break;
default:
break;
}
event_type = xmlParser.next();// 读取下一个标签
}
output.write(htmlEnd.getBytes());
output.close();
htmlArray.add(htmlPath);
}
} catch (Exception e) {
e.printStackTrace();
}
}读取pdf文件
Vudroid方式读取
上面以html方式显示pptx文件,虽然能够读取图片与文字样式,但是与原始的幻灯片内容相差还是比较大的,主要问题包括:1、ppt中的图文不像word那样一般是上下排列,而是既有上下排列又有左右排列,还有根据相对位置的排列。可是简单的html格式只能上下排列,难以适应其它方向的图文排版。
2、ppt通常自带幻灯片背景,也就是每个幻灯片都有的背景图片,可是slide*.xml文件中解析不到背景图片;况且由于背景图的存在,使得图片序号与幻灯片插图对应不上,造成幻灯片页面上的插图产生混乱。
3、每张ppt的尺寸规格是固定的,及长度和高度的比例是不变的;但是一旦转为html格式,页面的长宽比例就乱套了,完全不是ppt原来的排版布局。
如果在java服务端,可以调用HSLFSlide类的draw方法,直接把每张幻灯片原样画到临时的图像文件。然而在手机端,无法调用draw方法,因为该方法用到了java的awt图像库,而Android并不提供该图像库,所以poi不能直接绘制ppt的原始页面。
既然直接显示原样的幻灯片难以实现,那么就得考虑其它的办法,一种思路是先在服务端把ppt文件转换为pdf文件,然后手机端再来读取pdf文件。正好Android平台上拥有多种pdf的解析方案,其中之一是开源框架Vudroid,该框架允许读取pdf文件,并把pdf文件内容以列表形式打印在屏幕上。下面是使用Vudroid框架解析pdf文件的效果图:

若要在Android项目中集成Vudroid框架,可按照以下步骤处理:
1、在AndroidManifest.xml中添加SD卡的操作权限;
2、在libs目录下导入Vudroid的so库libvudroid.so;(使用ADT开发时)
3、在工程源码中导入org.vudroid.pdfdroid包下的所有源码;
下面是使用Vudroid框架解析pdf文件的代码:
public class VudroidActivity extends Activity implements
OnClickListener, FileSelectCallbacks {
private final static String TAG = "VudroidActivity";
private FrameLayout fr_content;
private DecodeService decodeService;
@Override
protected void onCreate(Bundle savedInstanceState){
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_pdf_vudroid);
decodeService = new DecodeServiceBase(new PdfContext());
findViewById(R.id.btn_open).setOnClickListener(this);
fr_content = (FrameLayout) findViewById(R.id.fr_content);
}
@Override
protected void onDestroy() {
decodeService.recycle();
decodeService = null;
super.onDestroy();
}
@Override
public void onClick(View v) {
if (v.getId() == R.id.btn_open) {
FileSelectFragment.show(this, new String[] {"pdf"}, null);
}
}
@Override
public void onConfirmSelect(String absolutePath, String fileName, Map<String, Object> map_param) {
String path = String.format("%s/%s", absolutePath, fileName);
Log.d(TAG, "path="+path);
DocumentView documentView = new DocumentView(this);
documentView.setLayoutParams(new ViewGroup.LayoutParams(
ViewGroup.LayoutParams.MATCH_PARENT, ViewGroup.LayoutParams.MATCH_PARENT));
decodeService.setContentResolver(getContentResolver());
decodeService.setContainerView(documentView);
documentView.setDecodeService(decodeService);
decodeService.open(Uri.fromFile(new File(path)));
fr_content.addView(documentView);
documentView.showDocument();
}
@Override
public boolean isFileValid(String absolutePath, String fileName, Map<String, Object> map_param) {
return true;
}
}MuPDF方式读取
虽然Vudroid框架能够正常解析并显示pdf文件内容,但美中不足的是:1、Vudroid框架解析速度偏慢;
2、显示pdf页面时采用马赛克逐格展示,不够友好;
3、整个pdf文件内容都调用draw方法绘制,难以改造为翻页浏览的形式;
基于以上情况,博主又尝试了其它的pdf解析框架,发现MuPDF这个解决方案较为理想。MuPDF的实现代码相对较少,调用起来也比较方便,而且支持只浏览指定页面,这意味着我们可以使用翻页形式来逐页浏览pdf文件,更加符合普通用户的使用习惯。下面是采用MuPDF框架解析pdf文件的效果图(列表形式):

下面是采用MuPDF框架解析pdf文件的效果图(翻页形式):
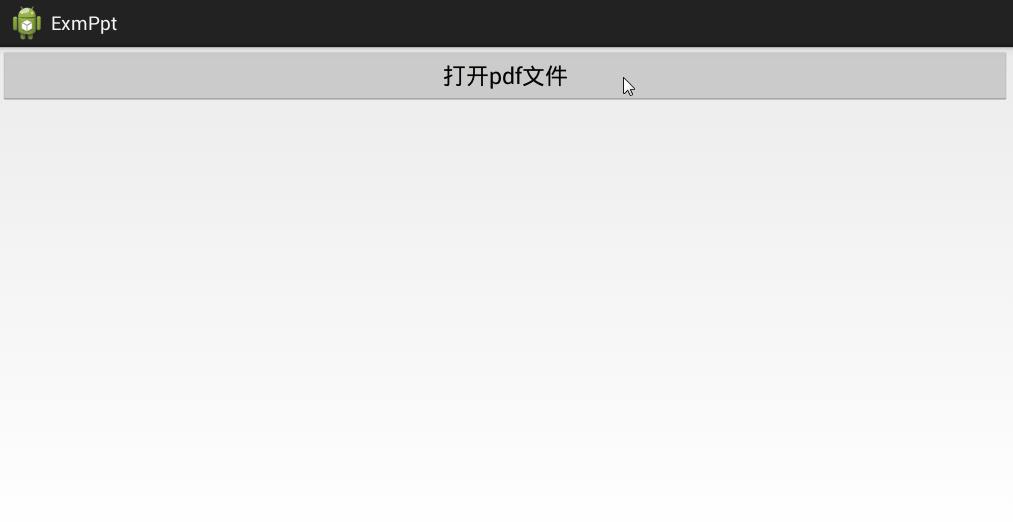
若要在Android项目中集成MuPDF框架,可按照以下步骤处理:
1、在AndroidManifest.xml中添加SD卡的操作权限;
2、在libs目录下导入MuPDF的so库libmupdf.so;(使用ADT开发时)
3、在工程源码中导入com.artifex.mupdf包下的所有源码;
下面是使用MuPDF框架解析pdf文件的代码:
public class PdfFragment extends Fragment implements OnPDFListener {
private static final String TAG = "PdfFragment";
protected View mView;
protected Context mContext;
private int position;
public static PdfFragment newInstance(int position) {
PdfFragment fragment = new PdfFragment();
Bundle bundle = new Bundle();
bundle.putInt("position", position);
fragment.setArguments(bundle);
return fragment;
}
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container,
Bundle savedInstanceState) {
Log.d(TAG, "width="+container.getMeasuredWidth()+", height="+container.getMeasuredHeight());
mContext = getActivity();
if (getArguments() != null) {
position = getArguments().getInt("position");
}
MuPDFPageView pageView = new MuPDFPageView(mContext,
MainApplication.getInstance().pdf_core,
new Point(container.getMeasuredWidth(), container.getMeasuredHeight()));
PointF pageSize = MainApplication.getInstance().page_sizes.get(position);
if (pageSize != null) {
pageView.setPage(position, pageSize);
} else {
pageView.blank(position);
MuPDFPageTask task = new MuPDFPageTask(
MainApplication.getInstance().pdf_core, pageView, position);
task.setPDFListener(this);
task.execute();
}
return pageView;
}
@Override
public void onRead(MuPDFPageView pageView, int position, PointF result) {
MainApplication.getInstance().page_sizes.put(position, result);
if (pageView.getPage() == position) {
pageView.setPage(position, result);
}
}
}点击下载本文用到的读取PPT和PDF文件的工程代码
点此查看Android开发笔记的完整目录
以上是关于Android开发笔记(一百四十一)读取PPT和PDF文件的主要内容,如果未能解决你的问题,请参考以下文章