HashMap源码阅读
Posted 秋风Haut
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap源码阅读相关的知识,希望对你有一定的参考价值。
本文内容来自于HashMap的源码内容,作为学习的记录。
HashMap是一种存储key-value对的对象。每个map不能包含重复的key,每个key至多映射一个value。我们可以看到HashMap实现自Map接口,继承自AbstractMap类。
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
//HashMap的默认容量为16、这个值通过移位来操作,而不是通过乘法运算符
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//HashMap的最大容量。(为什么是2的30次方?参考String的最大长度,可以猜想其受限于Integer类型的最大值是2^32-1和真实物理内存大小)
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//HashMap存储内容的初始值。一个空的Entry数组
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
//HashMap进行必要的调整时,table会进行变化。而且table的长度,必须,是2的整数次幂
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
//HashMap中包含的key-value对的个数
transient int size;
···如下图,HashMap的方法很多,选出最有特点的几个方法重点研究:
1. containsKey()
......
//采用getEntry(key)的方式,直接拿指定key向HashMap中取value,取到了就是true,取不到就是false
public boolean containsKey(Object key)
return getEntry(key) != null;
/**
* 如果在HashMap中不存在指定key的映射就会返回null
*/
final Entry<K,V> getEntry(Object key)
//防御式编程,如果hashMap中没有key-value映射对,则返回null
if (size == 0)
return null;
//求出key对应的hashCode,直接使用hashCode向entry数组中拿值
//编程风格:如果key==null,则hashCode为0
int hash = (key == null) ? 0 : hash(key);
//可以看到HashMap从table[hash]这个节点开始,以链表的方式一个个向后遍历,若一直没有找到符合条件的key,将一直遍历直到e=null才停止
//若在该条链中找到指定key对应的映射(e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))),就返回e
//for循环外部还有一个return null;就意味着如果整条链遍历结束,仍没有找到指定key,就说明hashMap中没有该key,就返回null,因此containsKey方法将返回false
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next)
Object k;
//判断条件很长.e是当前节点(指针),判断条件认为有两种情况说明找到指定节点,1. e.hash=key.hash;
//2. 将e的当前值与指定key使用==比较,或在保证key不是null的前提下,使用key.equals()方法来判断是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
return null;
2.put()
//使用指定key和指定value在HashMap中建立映射关系
//如果HashMap中已经有指定的key,则新value会替换旧value
//put方法其实会有返回值的,每次插入新值,会返回该key对应的旧value,如果key是新的key,返回null
public V put(K key, V value)
//如果当前的Entry数组为空,则将数组容量扩充为2的整数次幂
if (table == EMPTY_TABLE)
inflateTable(threshold);
//如果key为空则使用另一种方式添加
if (key == null)
return putForNullKey(value);
//key是不是null,其实区别并不大,只是如果key为null,就直接放在table的第一个位置
//计算key的hash值并由hash计算该key对应的index,是跟null型key的区别
int hash = hash(key);
int i = indexFor(hash, table.length);
//遍历链表,找到key的位置,e.recordAccess(this)方法是无法理解的.本来这个方法是就是空的
for (Entry<K,V> e = table[i]; e != null; e = e.next)
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
modCount++;
addEntry(hash, key, value, i);
return null;
//如果key为null时,从Entry数组的第一个元素开始遍历,找到第一个key为null的
//entry,将旧值替换为新值,并将旧值返回
//e.recordAccess(this)是空方法,不知道是什么设计原则
private V putForNullKey(V value)
for (Entry<K,V> e = table[0]; e != null; e = e.next)
if (e.key == null)
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
//HashMap结构化 修改次数 +1.如果有另一个进程进行了非同步的修改,就会抛出ConcurrentModificationException异常
//问题:HashMap是怎样确定现在的modCount跟原本的modCount不一致?
modCount++;
//
addEntry(0, null, value, 0);
return null;
......
//实际插入Entry元素的操作
//threshold是一个阈值,如果当前key-value个数大于等于threshold,说明HashMap需要扩容了
//bucketIndex是桶索引,因为HashMap的数据结构是链表数组,每个数组元素都可能挂了一个链表
//一种类似于门帘式的结构,因为这个bucketIndex是要插入的key对应的那个桶的索引,只有size个数达到了阈值,并且bucketIndex处的Entry已经有元素了,这样才需要扩容了....
//扩容后,需要对hash和bucketIndex进行重新计算
void addEntry(int hash, K key, V value, int bucketIndex)
if ((size >= threshold) && (null != table[bucketIndex]))
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
//具体addEntry的操作,只是不用担心resie的问题
createEntry(hash, key, value, bucketIndex);
//对这个map的内容进行rehash成一个新的容量更大的数组,当map中key的数量达到这个数组的threshold阈值时会自动调用
//PS:得亏我看了源码,现在知道了,不是说桶的多少达到了数组长度的threshold,而是key的个数,而且不管这些key有多少映射到了同一个桶中,
//也是,这种情况可以有效避免出现哈希表退化为链表的问题.
//如果当前容量是MAXIMUM_CAPACITY,就会将Integer.MAXVALUE设为threshold,这样可以防止将来再调用
void resize(int newCapacity)
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY)
threshold = Integer.MAX_VALUE;
return;
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
//将当前entries中的所有元素transfer到新的table中,新table的规格已经在resize中设置好了,具体操作由transfer来完成
void transfer(Entry[] newTable, boolean rehash)
int newCapacity = newTable.length;
for (Entry<K,V> e : table)
while(null != e)
Entry<K,V> next = e.next;
//看不懂,把null赋给e.hash然后再与e.key相比,相等的话返回0,否则返回e.key的hash值
if (rehash)
e.hash = null == e.key ? 0 : hash(e.key);
//根据e.hash和newCapacity新的容量来计算e元素的桶索引
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
- remove(Object key)
//删除节点操作,并且会返回删除节点的value.
public V remove(Object key)
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
//移除HashMap中指定的key,若该hashMap不包含该key的映射,则返回为空
final Entry<K,V> removeEntryForKey(Object key)
if (size == 0)
return null;
//编程风格学习
//三元表达式的输出类型需要注意
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null)
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
prev = e;
e = next;
return e;
- keySet()
/**
* Returns a @link Set view of the keys contained in this map.
* The set is backed by the map, so changes to the map are
* reflected in the set, and vice-versa. If the map is modified
* while an iteration over the set is in progress (except through
* the iterator's own <tt>remove</tt> operation), the results of
* the iteration are undefined. The set supports element removal,
* which removes the corresponding mapping from the map, via the
* <tt>Iterator.remove</tt>, <tt>Set.remove</tt>,
* <tt>removeAll</tt>, <tt>retainAll</tt>, and <tt>clear</tt>
* operations. It does not support the <tt>add</tt> or <tt>addAll</tt>
* operations.
* 返回map中的所有key 的set视图,此set是由map支持的,因此对map的修改,都将对set产生影响,反之亦然。
如果当set上的iterator正在执行中时,map被修改了,那么iterator的结果就是未 定义的(除非是对iterator进行remove操作。该set支持对元素的remove操作,可以使用remove/removeAll/Iterator.remove/retainAll/clear等操作,都将会同时移除元素在map中的映射。但不支持add/addAll操作
*
*/
public Set<K> keySet()
Set<K> ks = keySet;
return (ks != null ? ks : (keySet = new KeySet()));
private final class KeySet extends AbstractSet<K>
public Iterator<K> iterator()
return newKeyIterator();
public int size()
return size;
public boolean contains(Object o)
return containsKey(o);
public boolean remove(Object o)
return HashMap.this.removeEntryForKey(o) != null;
public void clear()
HashMap.this.clear();
从上可以了解到:
1、HashMap的数据结构一个Entry数组,而数组中的元素又是一个链表
2、HashMap的get操作都会先按key的hash得出该key对应的Entry数组的元素索引,然后以该元素为起点,以链表的方式往后遍历查找
3、HashMap中的Entry数组的size,原始长度是16,当元素个数达到了size * loadFactor=threshold时,将进行一次resize操作,就会声明一个新的长度为原来2倍的Entry数组,并将旧的Entry数组内容拷贝进去。而loadFactor加载因子是一个空间和时间效率上的平衡,如果loadFactor太高,空间利用率较高,但查找效率会降低,loadFactor过低,查找很快,但空间利用率不高
4、进行resize操作的目的有两个,一、扩展Entry数组。二、可以在一定程度上避免哈希表退货成链表的问题
5、关于put操作有个问题,在源码中可以看到,如果key是null,hashMap依旧可以插入到Entry数组的第一个元素后,然后返回旧key(null)的旧值,如果key已经存在,则put操作会找到key对应的桶,然后将key的旧值替换为新值,并返回该key对应的旧值,但对于key是新值,或key的hash为新值的情况,先调用addEntry(),进行必要的resize,重新计算hash和bucketIndex,然后调用createEntry(),为table[bucketIndex]申请空间,为new Entry()。
问题是:为什么可以确定不同的key,如果具有相同的hash,就一定具有相同的内容?因为以上并没有对按照key.hash找到了桶,但没有相同的key,需要在Entry后新增加节点的情况进行处理。对于新的要put的key,有两种情况,一、key为null,这种将直接插入到Entry[0]中,二、key!=null,若key!=null,也有两种情况,一、key.hash不存在,则将在进行的resize之后,新建一个Entry元素并申请空间,二、key.hash存在,我认为key.hash存在,也会有两种情况,一、key.hash存在,并且key已存在,将替换旧值为新值,二、这是key.hash存在,但key不存在的情况。HashMap没有处理。即,为什么在HashMap中没有向链表添加节点的操作,但是遍历链表的操作??
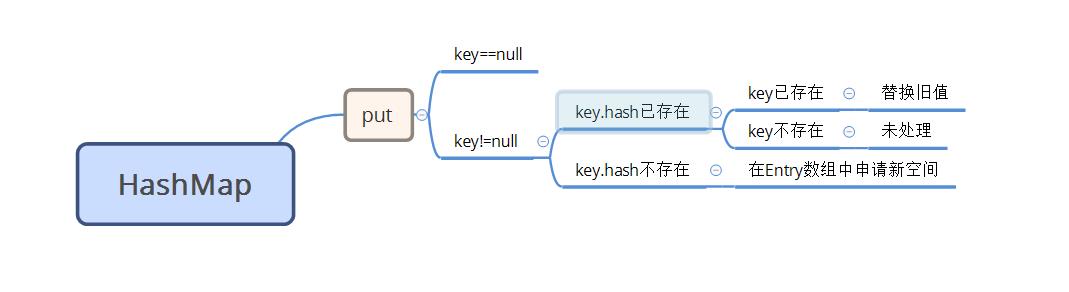
看完源码,还是有很多收获,其它收获有java的位运算、严谨的编程风格等,当然也限于本人现在的水平,有些操作是无法理解的,比较每次添加节点,都会执行一次e.recordAccess(this);而此方法的方法体是空的,暂时无法理解。还有其他比如keySet方法来获取HashMap的所有key的set视图,但是这个方法也看不懂,还有HashIterator、ValueIterator、KeyIterator内部数的设计,都不好理解。总之,这些都留待以后水平提高以后再去理解。
以上是关于HashMap源码阅读的主要内容,如果未能解决你的问题,请参考以下文章