Linux | 手把手教你写一个进度条小程序
Posted 烽起黎明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux | 手把手教你写一个进度条小程序相关的知识,希望对你有一定的参考价值。

文章目录
一、前言
- 学习了【vim】知道了如何编辑一个代码文本
- 学习了【gcc】知道了如何编译一个代码文本
- 学习了【make/Makefile】知道了如何自动化构建一个代码文本
今天,就让我们利用前面所学习的知识,在Linux上写一个小程序,来检验一下自己掌握的程度
【成品展示】

二、理解 ‘\\r’ 与 ‘\\n’
在写进度条之间呢,我们要理清两个概念,首先来看看什么是
\\r\\n
1、可显字符与控制字符
在C语言中呢,有很多的字符,大致分为【可显字符】和【控制字符】两大类
- 可显字符:也就是可以显示在屏幕上,我们能看得到的,例:a b c d 1 2 3 4…
- 控制字符:用来控制我们输出在屏幕上的一些格式,例:\\n \\r \\t \\b…
在我们日常写代码,写文章的过程中,写完一行后若是没有自动换行就需要敲下键盘中的Enter键来达到换行的效果。可是对于这个按键,实际上它在计算机内部做了两件事 —— 【换行】+【回车】
\\n—— 新起一行,光标位于行末【换行】\\r—— 回到当前文本行的首部【回车】
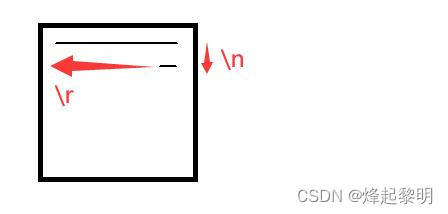
2、老式键盘
在我们使用的键盘中,看到的Enter回车键,莫过于下面这两种,第一种出现在台式机多一些,第二种出现在笔记本多一些。不过就这么看来,还是这种老式键盘符合【换行】+【回车】的这么一个概念,也就是新起一行,然后在回到当前行的行首

- 不过平常呢我们在C语言中写代码的时候为何直接使用
\\n就可以起到【换行】+【回车】的功能呢,其实这是语言本身的范畴所决定的,在C语言中便自动解释成了这个意思,不过在其他地方可能只能起到【换行】的功能,\\r需要我们手动加上 - 例如我们在Linux下写出一个文本的时候,就需要带上
\\r\\n
三、缓冲区的概念理解
了解了
\\r\\n的概念之后,我们继续来谈谈【缓冲区】的概念
1、五个代码段 + 现象分析
在这之前先普及两个Linux下的库函数
- sleep() —— 睡眠
- Windows中的sleep()单位是毫秒;Linxu中的sleep()单位是秒
- 其包含在头文件
<unistd.h>中
- fflush() —— 刷新流
- 格式:
int fflush(FILE *stream); - 一般用来刷新输出流即stdout
- 格式:
接下去我们通过五段代码来逐步理解行缓冲的概念
代码1
#include <stdio.h>
#include <unistd.h>
int main()
printf("hello linux!\\n");
sleep(3);
return 0;
现象观察

- 首先看到的是我们平常写的普通的代码,我在最后加上了
sleep()函数,相当于在打印输出完之后让程序睡上3秒,然后才会显示【命令提示符】
代码2
#include <stdio.h>
#include <unistd.h>
int main()
printf("hello linux!");
sleep(3);
return 0;
现象观察

- 本段代码我将最后的
\\n给去除了,可以看出,我们要输出的【hello linux】并没有在第一时间打印,而是在睡眠3秒后和【命令提示符】一同进行打印,这是为何呢?
代码3
#include <stdio.h>
#include <unistd.h>
int main()
printf("hello Makefile!");
fflush(stdout);
sleep(3);
return 0;
现象观察

- 接着我又使用到了
fflush()这个函数,将其放在sleep()函数之前,也就相当于是优先刷新了一下缓冲流,此时就可以看到【hello linux】立马先被打印了出来,等上3秒后才显示的【命令提示符】
代码4
#include <stdio.h>
#include <unistd.h>
int main()
printf("hello linux!\\r");
sleep(3);
return 0;
现象观察

- 可以看到,我在输出语句中加上了一个
\\r,当执行程序后便开始睡眠, 然后在3秒睡眠后便直接打印出了【命令提示符】,这是为何呢?我们原本要打印的数据去哪里了呢?
代码5
#include <stdio.h>
#include <unistd.h>
int main()
printf("hello linux!\\r");
fflush(stdout);
sleep(3);
return 0;
现象观察

- 通过
fflush()刷新流,我们提前显示了一下需要打印的数据,此时就可以看得很清楚,其实我们原本要打印的数据是在的,只是被【命令提示符】覆盖了而已
2、观察现象,提出问题❓
通过观察上面5个代码段以及它们所产生的现象,我们可以提出这样的问题
- 当不加换行符
\\n时为何会先睡眠再打印? - 为何带上
\\n后数据会立马先显示出来,睡眠后才显示提示符? - 在加上回车
\\r后为什么看不到我们要的数据?刷新一下就有了呢?
3、行缓冲的概念 + 疑难解答
接下去我们就正式地来谈谈【缓冲区】的概念。文字居多、都是概念,还望理解😄
当我们编写完代码的时候,要将数据进行输出,此时在内存中会为其预留了一块空间,用来缓冲输入或输出的数据,这个保留的空间被称为缓冲区
- 缓冲区分为【无缓冲】、【行缓冲】、【全缓冲】三类,本文主要讲行缓冲
- 对于缓冲区而言,需要进行刷新才可以将里面的内容显示出来。可以在进程退出的时候让系统自动去刷新缓冲区;也可以自己去调用刷新缓冲区,例如
fflush()函数
-
当不加换行符
\\n时为何会先睡眠再打印?- 对于我们写的这段代码而言,属于顺序执行,所以一定是从上到下执行下来的,因此一定会先打印printf()语句中的内容。
- 我们看不到这个内容不代表它不存在,只是它被预存在了缓冲区中,因为
sleep()函数的缘故,导致这个缓冲区没有被刷新而已,所以它并没有丢失
-
为何带上
\\n后数据会立马先显示出来,睡眠后才显示提示符?- 无论带不带
\\n,数据都会被保存在缓冲区里。缓冲区有很多自己的刷新策略【往显示器上打印就是行缓冲】,只要碰到了换行符,就会把换行符之前的所有内容全部显示出来 - 所以字符串是以行缓冲的方式保存在了行缓冲区里,最后会显示出来的原因是我们的程序要退出了,所以曾经缓冲在缓冲区里的数据就会被刷新出来

- 无论带不带
-
在加上回车
\\r后为什么看不到我们要的数据?刷新一下就有了呢?-
上面我们有谈到
\\r与\\n的特点,知道了对于前者来说会回到当前行的行首,那是什么回到行首呢?通过观察动图可以发现是光标。当我们在输入一个字符时,光标就会后移,也就会移动到下一个要输入字符的位置。因此在我们什么都不加的时候便会顺着打印【命令提示符】

-
那其实就可以说得通了,因为
\\r的原因,光标回到了行首,因此在3秒的等待后shell输出了【命令提示符】,便覆盖了我们原本所想要输出的内容

-
4、小结
好,看完行缓冲之后,也解答了遗留下来的疑难问题,我们来对其进行一个总结✒
- 程序内部存在缓冲区,无论带不带任何的【控制字符】,它都会在输出屏幕前将其保存在缓冲区中,缓冲区是需要刷新的,若是没有因为一些缘故,例如
slepp()函数导致缓冲区延迟刷新,我们一时就看不到想要输出的内容。可以等待系统睡眠后自动刷新,也可以手动使用fflush()自动刷新 - 输入字符光标后移,要显示的内容都是从光标所在处开始的。光标和显示器相互匹配,光标在哪里,显示器打印的时候就从哪里开始打印
四、实现一个倒计时的功能
通过前面学习的有关
\\r\\n以及缓冲区的知识,相信解开了你一直以来的很多困惑,现在我们先利用前面所学的一些知识,去实现一个数字倒计时的功能
1、实现从9 ~ 0的倒计时
- 首先我们来如何使一个数字从【9】变到【0】,那就是使用循环。然后我们在打印完每个数字之后使用
sleep()函数睡眠一秒
1 #include <stdio.h>
2 #include <unistd.h>
3
4 int main(void)
5
6 int i = 9;
7 while(i >= 0)
8
9 printf("%d\\n", i);
10 sleep(1);
11 i--;
12
13 return 0;
14
- 来看一下效果

- 但我们要实现的并不是这样,而是在一行内进行一个倒计时,而且每后一个数字会对前一个数字进行覆盖,那就可以这么去做
- 每打印完一个数字后进行一个回退,使光标重新回到行首,这样就使得后一个数字每次都可以覆盖掉前一个数字
- 那也就是我们前面学到过的
\\r回车 ——>printf("%d\\r", i);

- 是的,你眼睛👀没有问题,如果看到最后就可以发现原本我们要显示的内容完全打印出来,这是为什么呢?还记得前面的知识吗?
- 这里先公布答案:因为缓冲区没刷新呢 ❗
- 我们每次在
slepp()睡眠前将缓冲区刷新一下即可,保证在倒计时完不被命令行覆盖可以在最后加个换行

2、进阶:10 ~ 0的倒计时
再加个码,若是我从10开始倒计时,该怎么修改程序呢?你可试着先自己写写看✍
- 可以看到,若是我就将
i修改一下从10开始的话,就会出现下面这样的情况,只有前面的数字会被覆盖,10后面的这个0会始终被保留下来,最后倒计时结束后便成了00

显示器打印原理解释
那要如何去修改呢?关于这点我要先普及一下有关显示器打印的原理
- 看到这句代码
printf("%d\\n", 123);就是打印了一下123这个整数,但是在计算机内部进行处理后显示在屏幕上可不是这样,因为所有显示在屏幕上的内容都是字符 - 所以对于123其实并不是以一个整数的形式打印在屏幕上的,而是
1、2、3这三个字符,进行显示,只是看上去像是数字一样。在计算机内部,会将你输入的一些整型数字首先转换为字符串的形式,然后去遍历这个字符串,用putc()这个函数将字符一一地打印在显示器上
所以我们一般把【键盘】【显示器】这些称做为字符设备
3、错误修改
知道了显示器字符打印的原理,接下去我们就可以对上面的代码做一个修改
- 因为打印的均为字符,那么
10就算是有2个字符,所以我们每次在打印只需要预留出2个字符的位置就可以了,这样第一次打印10刚好占满两个字符的空间,后面在打印9 8 7...的时候虽然只有一个字符,但是还有一个预留的空间,所以就会把上一次打印的内容进行一个覆盖
printf("%2d\\r", i); //C语言中的格式化占位符

五、进度条小程序【详解】
好,终于来到了我们心心念念的【进度条】了,有关我为什么要将前面的这些知识做铺垫,你看完本模块就知道了😄
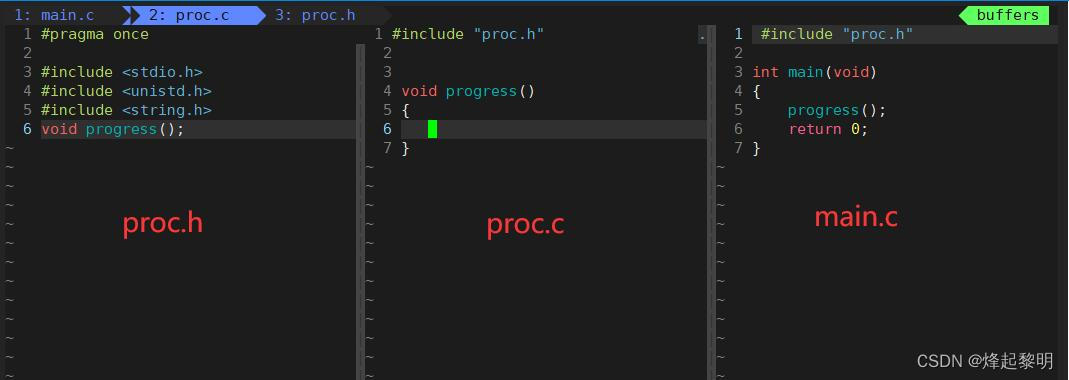
1、准备工作
- 既然是个小程序,那我们就用工程的形式来编写,那就是使用【多文件】的形式。首先要创建一个【proc】的目录其中包含
- 一个头文件
proc.h - 一个源文件
proc.c - 一个主调文件
main.c
- 一个头文件
- 这里充分的利用到了之前所学习的【
vim】来进行多文件编写如下图所示👇
- 因为我们要对代码去进行编译,每次去重新编译会很冗杂,因此可以使用之前学过【
make/Makefile】进行自动化构建 - 先前有说到过,目标文件它所依赖的是一个文件列表,不仅仅可以是一个,也可以是多个,例如这里的【main.c】与【proc.c】,因此在使用gcc进行编译的时候就需要对这两个
.c的文件一起进行编译

- 那此时就有同学会问,不是还有一个
proc.h吗?为何不进行一起编译呢? - 这一点我之前在讲解【
gcc】的时候也有提到过,我们在进行多文件编译时候是不需要考虑【头文件】的,因为在预处理阶段头文件就会在它被包含的.c源文件中进行展开,因此我们加了和没加一样,你想加的话也可以加上,不会有问题,不过一般我们是不加的
2、进度条样式说明
准备工作做好之后,我们来看看需要实现的进度条需要是一个什么样子
- 首先主体部分很明确,需要一个很大的空行,使用
[ ]进行囊括,中间用==>这样的符号进行一个慢慢地推进 - 那既然是进度条,就一定有进度,一般使用百分比来进行显示,即
50% - 除了上面两个,我们还需要这个进度条有缓冲显示,也就是我们日常在Windows下看到的那种转圈圈的缓冲,不过呢,我们是在Linux环境下,无法做到这种图形化界面,但是我们可以使用旋转字符来进行一个模拟
[|][/][-][\\]

这就是进度条的大致形状,要先有个数 [=======================>][100%][/]
3、主体进度推进实现【重点】
首先要实现的是主体进度条的推进时间,先简单地实现一下这个进度条不断变长的过程(๑•̀ㅂ•́)و✧
下面是详细介绍,想直接看整体代码的可以拉到最后面
- 我们可以将整体进度条看作是一个字符串,现在要实现从
0% ~ 100%的进度条扩展,因此就需要一个长度为101的字符数组,这里首先使用#define进行一个宏定义
#define SIZE 101
- 这里最令你困惑的应该是这个
memset,为什么要使用它呢?因为我相当于是使用一个循环的方式,每次都去修改这个字符数组当前位置上的字符,将其变为=,然后每次去打印的时候下一个位置就会多出来一个=,此时在视觉上看其实就相当于是一个进度条在慢慢推进的样子😮,不过在最后不要忘记带上sleep()这个睡眠函数,让进度条每过一秒钟向后前进一个单位
memset(bar, '\\0', sizeof(bar));
//初始化整个bar字符串均为\\0,sizeof(数组名)表示取到这个数组的字节大小
- 对于字符串我们知道自身就带有
\\0,因此我们每次在添加完当前位置的=后,还要在其后面添加上一个\\0才行,这会显得很麻烦,于是我就想到了在一开始就将整个字符串的内容初始化为\\0,对于sizeof(bar)来说也就是sizeof(数组名),可以取到这个数组的整个字节大小,若是不懂的可以看看C语言数组章节
下面是代码
1 #include "proc.h"
2
3 #define SIZE 101
4
5 void progress()
6
7 char bar[SIZE];
8 memset(bar, '\\0', sizeof(bar));
9 //初始化整个bar字符串均为\\0,sizeof(数组名)表示取到这个数组的字节大小
10
11 int i = 0;
12 while(i <= 100)
13
14 printf("[%s]\\n", bar);
15 bar[i] = '=';
16 i++;
17 sleep(1);
18
19
然后来看一下上面这段代码的演示过程

- 很明显可以看出,我们想要的进度条并不是这样的,虽然它有在进行一个慢慢的推进,但是我们想要它只在一行进行一个推进,此时应该要想到将最后打印的换行符
\\n去掉,让光标每次回到行首,再打印这个字符串
printf("[%s]\\r", bar);

不过可以看到,并没有显示出任何东西,此时相信你一定可以回答出来了,那就是:缓冲区没刷新!
fflush(stdout);
- 可以看到,因为每次都提前刷新了缓冲区,所以要打印的内容被显示出来了,因为
sleep(1)每次睡眠一秒,使得进度条一个不断推进的效果

不过可以观察到这个进度条推进得很慢,那有没有办法使它快一点呢❓
- 此时我们可以到Linux中的另一个睡眠延时函数
usleep(),我们可以通过【man】命令来查看一下它对应的手册 - 通过和
sleep()函数进行对比可以发现它的单位不是【秒】,而是【微秒】,对应单位转换也就是106秒

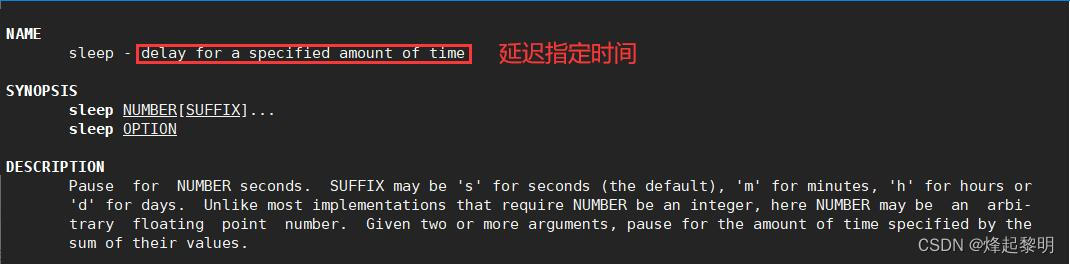
- 此时我们就可以对睡眠函数去进行一个修改,106是1秒,那么105就是0.1秒
//sleep(1); 1秒
// usleep(1000000); 1秒
usleep(100000); //0.1秒

- 上面有说到过,对于主体的进度条是需要预留出一个100的空间,好呈现进度条从0 ~ 100的推进,就可以上面说到过的格式化占位符
printf("[%100s]\\r", bar);

- 不过可以看到,加上之后是从右向左进行了一个推进,这不符合我们的认识,应该是从右向左才对,此时可以这样写,在100前面加个
-
printf("[%-100s]\\r", bar);

- 这么长的进度条,应该看了很烦把,把它改小,一样保持
0% ~ 100%

- 改动的部分多一些,给出代码,主要是循环的条件、字符数组预留空间以及占位符
1 #include "proc.h"
2
3 #define SIZE 51
4
5 void progress()
6
7 char bar[SIZE];
8 memset(bar, '\\0', sizeof(bar));
9 //初始化整个bar字符串均为\\0,sizeof(数组名)表示取到这个数组的字节大小
10
11 int i = 0;
12 while(i <= 50)
13
14 printf("[%-50s]\\r", bar);
15 bar[i++] = '=';
16 fflush(stdout);
17 // usleep(1000000); 1秒
18 usleep(100000); //0.1秒
19
20 printf("\\n");
21
- 为了看出让被人看出这是一个进度条的样子,在后面追加一个
>。重新定义一下
#define STYLE '='
#define ARR '>'
- 为了使进度条在
99%之前最后一个字符呈现【>】,而最后到100%为【=】,我们此处就需要再循环内部做一个判断若是其i != 50,就一直追加【>】,最后到达100%时便为【=】 - 那便需要预留出52个位置的空间
#define SIZE 52
if(i != 50) bar[i] = ARR;
此时来看的话我们进度条的主体部分就做完了

4、百分比递增实现
接下去我们来实现一下百分比递增这块
- 若是一开始很长的进度条,循环次数为101次的话直接输出下标
i即可,但是我们修改了进度条的长度,所以需要使用i * 2,也可以实现一个0% ~ 100%的过程
printf("[%-50s][%d]\\r", bar, i * 2);

- 来给数字的后面加上一个【%】,不过可以看到,编译器不允许我们这样做,这点要涉及到
.bat中的批处理程序,此时我们需要写上【%%】才算是一个【%】,你也可以理解为我们在写文件路径时的【\\】当做【\\】,防止出现转义字符的歧义- 如果想了解可以看看这个文章——> 链接

printf("[%-50s][%d%%]\\r", bar, i * 2);

5、旋转字符轮回实现
接下去来实现最后的一个旋转字符的轮回,已到达图形化界面中的缓冲功能
- 这一块我们只需要定义一个字符数组,前面加上
const是防止里面的内容被修改。而最后一个\\\\也就是我上面说到的【转义字符歧义】,其实它就是【\\】
const char* label = "|/-\\\\";
- 然后我们在打印的时候,要去实现一个轮回就需要用到一个取余
%的操作,每次打印的都是【0 ~ 3】的倍数
printf("[%-50s][%d%%][%c]\\r", bar, i * 2, label[i % 4]);
最后,就实现了一个完整的进度条

6、整体代码展示
1 #include "proc.h"
2
3 #define SIZE 52
4 #define STYLE '='
5 #define ARR '>'
6
7 void progress()
8
9 const char* label = "|/-\\\\";
10 // printf("%c\\n", label[0]);
11 char bar[SIZE];
12 memset(bar, '\\0', sizeof(bar));
13 //初始化整个bar字符串均为\\0,sizeof(数组名)表示取到这个数组的字节大小
14
15 int i = 0;
16 while(i <= 50)
17
18 printf("[%-50s][%d%%][%c]\\r", bar, i * 2, label[i % 4]);
19 bar[i++] = STYLE;
20 if(i != 50) bar[i] = ARR;
21 fflush(stdout);
22 // usleep(1000000); 1秒
23 usleep(100000); //0.1秒
24
25 printf("\\n");
26
六、总结与提炼
好,我们来总结一下本文所学习的内容
- 为了学习进度条小程序的编写,我们首先学习学习了C语言中的两个控制字符【
\\n】与【\\r】,知道了它们分别有什么作用 - 这它们的基础上,又了解到了计算机内部存在缓冲区这么一个概念,知道了缓冲区需要被刷新才可以显示。通过观察5个代码段对这些概念也有了更加深刻的理解
- 学习了上面两个小知识后,里面通过所学实现了一个【倒计时】的功能,做到了活学活用
- 最后的舞台给到【进度条】,我们分别通过三个主要模块实现了进度条,包括:进度条的主体部分、进度条的百分比递增以及旋转字符模拟缓冲图形。有关进度条,你学会了吗😜
以上就是本文所要阐述的所有内容,感谢您的阅读🌹

手把手教你写嵌入式Linux中的Makefile
一、Makefile的引入及规则
使用keil, mdk,avr等工具开发程序时点击鼠标就可以编译了,它的内部机制是什么?它怎么组织管理程序?怎么决定编译哪一个文件?
答:实际上windows工具管理程序的内部机制,也是Makefile,我们在linux下来开发裸板程序的时候,使用Makefile组织管理这些程序。
组织管理程序,组织管理文件,我们写一个程序来实验一下:
文件a.c
#include <stdio.h>
int main()
func_b();
return 0;
文件b.c
#include <stdio.h>
void func_b()
printf("This is B\\n");
编译:
gcc -o test a.c b.c
运行:
./test
结果:
This is B
gcc -o test a.c b.c 这条命令虽然简单,但是它完成的功能不简单。
我们来看看它做了哪些事情,
我们知道.c程序得到可执行程序它们之间要经过四个步骤:
- 1.预处理
- 2.编译
- 3.汇编
- 4.链接
我们经常把前三个步骤统称为编译了。我们具体分析:gcc -o test a.c b.c这条命令它们要经过下面几个步骤:
- 1)对于a.c:执行:预处理 编译 汇编 的过程,a.c ==>xxx.s ==>xxx.o 文件。
- 2)对于b.c:执行:预处理 编译 汇编 的过程,b.c ==>yyy.s ==>yyy.o 文件。
- 3)最后:xxx.o和yyy.o链接在一起得到一个test应用程序。
提示:gcc -o test a.c b.c -v :加上一个**‘-v’**选项可以看到它们的处理过程,

第一次编译 a.c 得到 xxx.o 文件,这是很合乎情理的, 执行完第一次之后,如果修改 a.c 又再次执行:gcc -o test a.c b.c,对于 a.c 应该重新生成 xxx.o,但是对于 b.c 又会重新编译一次,这完全没有必要,b.c 根本没有修改,直接使用第一次生成的 yyy.o 文件就可以了。
缺点:对所有的文件都会再处理一次,即使 b.c 没有经过修改,b.c 也会重新编译一次,当文件比较少时,这没有没有什么问题,当文件非常多的时候,就会带来非常多的效率问题如果文件非常多的时候,我们,只是修改了一个文件,所用的文件就会重新处理一次,编译的时候就会等待很长时间。
对于这些源文件,我们应该分别处理,执行:预处理 编译 汇编,先分别编译它们,最后再把它们链接在一次,比如:
编译:
gcc -o a.o a.c
gcc -o b.o b.c
链接:
gcc -o test a.o b.o
比如:上面的例子,当我们修改a.c之后,a.c会重现编译然后再把它们链接在一起就可以了。b.c就不需要重新编译。
那么问题又来了,怎么知道哪些文件被更新了/被修改了?
比较时间:比较 a.o 和 a.c 的时间,如果a.c的时间比 a.o 的时间更加新的话,就表明 a.c 被修改了,同理b.o和b.c也会进行同样的比较。比较test和 a.o,b.o 的时间,如果a.o或者b.o的时间比test更加新的话,就表明应该重新生成test。Makefile
就是这样做的。我们现在来写出一个简单的Makefile:
Makefie最基本的语法是规则,规则:
目标 : 依赖1 依赖2 ...
[TAB]命令
当“依赖”比“目标”新,执行它们下面的命令。我们要把上面三个命令写成Makefie规则,如下:
test :a.o b.o //test是目标,它依赖于a.o b.o文件,一旦a.o或者b.o比test新的时候,就需要执行下面的命令,重新生成test可执行程序。
gcc -o test a.o b.o
a.o : a.c //a.o依赖于a.c,当a.c更加新的话,执行下面的命令来生成a.o
gcc -c -o a.o a.c
b.o : b.c //b.o依赖于b.c,当b.c更加新的话,执行下面的命令,来生成b.o
gcc -c -o b.o b.c
我们来作一下实验:
在改目录下我们写一个Makefile文件:
文件:Makefile
test:a.o b.o
gcc -o test a.o b.o
a.o : a.c
gcc -c -o a.o a.c
b.o : b.c
gcc -c -o b.o b.c
上面是Makefie中的三条规则。Makefile,就是名字为Makefile的文件。当我们想编译程序时,直接执行make命令就可以了,一执行make命令它想生成第一个目标test可执行程序,如果发现a.o 或者b.o没有,就要先生成a.o或者b.o,发现a.o依赖a.c,有a.c但是没有a.o,他就会认为a.c比a.o新,就会执行它们下面的命令来生成a.o,同理b.o和b.c的处理关系也是这样的。
如果修改a.c ,我们再次执行make,它的本意是想生成第一个目标test应用程序,它需要先生成a.o,发现a.o依赖a.c(执行我们修改了a.c)发现a.c比a.o更加新,就会执行gcc -c -o a.o a.c命令来生成a.o文件。b.o依赖b.c,发现b.c并没有修改,就不会执行gcc -c -o b.o b.c来重新生成b.o文件。现在a.o b.o都有了,其中的a.o比test更加新,就会执行 gcc -o test a.ob.o来重新链接得到test可执行程序。所以当执行make命令时候就会执行下面两条执行:
gcc -c -o a.o a.c
gcc -o test a.o b.o
我们第一次执行make的时候,会执行下面三条命令(三条命令都执行):
gcc -c -o a.o a.c
gcc -c -o b.o b.c
gcc -o test a.o b.o
再次执行make 就会显示下面的提示:
make: `test' is up to date.
我们再次执行make就会判断Makefile文件中的依赖,发现依赖没有更新,所以目标文件就不会重现生成,就会有上面的提示。当我们修改a.c后,重新执行make,
就会执行下面两条指令:
gcc -c -o a.o a.c
gcc -o test a.o b.o
我们同时修改a.c b.c,执行make就会执行下面三条指令。
gcc -c -o a.o a.c
gcc -c -o b.o b.c
gcc -o test a.o b.o
a.c文件修改了,重新编译生成a.o, b.c修改了重新编译生成b.o,a.o,b.o都更新了重新链接生成test可执行程序,Makefie的规则其实还是比较简单的。规则是Makefie的核心,
执行make命令的时候,就会在当前目录下面找到名字为:Makefile的文件,根据里面的内容来执行里面的判断/命令。
二、Makefile的语法
本节我们只是简单的讲解Makefile的语法,如果想比较深入
学习Makefile的话可以:
- a. 百度搜 “gnu make 于凤昌”。
- b. 查看官方文档: http://www.gnu.org/software/make/manual/
2.1 通配符
假如一个目标文件所依赖的依赖文件很多,那样岂不是我们要写很多规则,这显然是不合乎常理的
我们可以使用通配符,来解决这些问题。
我们对上节程序进行修改代码如下:
test: a.o b.o
gcc -o test $^
%.o : %.c
gcc -c -o $@ $<
%.o:表示所用的.o文件
%.c:表示所有的.c文件
$@:表示目标
$<:表示第1个依赖文件
$^:表示所有依赖文件
我们来在该目录下增加一个 c.c 文件,代码如下:
#include <stdio.h>
void func_c()
printf("This is C\\n");
然后在main函数中调用修改Makefile,修改后的代码如下:
test: a.o b.o c.o
gcc -o test $^
%.o : %.c
gcc -c -o $@ $<
执行:
make
结果:
gcc -c -o a.o a.c
gcc -c -o b.o b.c
gcc -c -o c.o c.c
gcc -o test a.o b.o c.o
运行:
./test
结果:
This is B
This is C
2.2 假想目标: .PHONY
1.我们想清除文件,我们在Makefile的结尾添加如下代码就可以了:
clean:
rm *.o test
- 1)执行 make :生成第一个可执行文件。
- 2)执行 make clean : 清除所有文件,即执行: rm *.o test。
make后面可以带上目标名,也可以不带,如果不带目标名的话它就想生成第一个规则里面的第一个目标。
2.使用Makefile
执行:make [目标] 也可以不跟目标名,若无目标默认第一个目标。我们直接执行make的时候,会在makefile里面找到第一个目标然后执行下面的指令生成第一个目标。当我们执行 make clean 的时候,就会在 Makefile 里面找到 clean 这个目标,然后执行里面的命令,这个写法有些问题,原因是我们的目录里面没有 clean 这个文件,这个规则执行的条件成立,他就会执行下面的命令来删除文件。
如果:该目录下面有名为clean文件怎么办呢?
我们在该目录下创建一个名为 “clean” 的文件,然后重新执行:make然后makeclean,结果(会有下面的提示:):
make: \\`clean' is up to date.
它根本没有执行我们的删除操作,这是为什么呢?
我们之前说,一个规则能过执行的条件:
- 1)目标文件不存在
- 2)依赖文件比目标新
现在我们的目录里面有名为“clean”的文件,目标文件是有的,并且没有
依赖文件,没有办法判断依赖文件的时间。这种写法会导致:有同名的"clean"文件时,就没有办法执行make clean操作。解决办法:我们需要把目标定义为假象目标,用关键子PHONY
.PHONY: clean //把clean定义为假象目标。他就不会判断名为“clean”的文件是否存在,
然后在Makfile结尾添加.PHONY: clean语句,重新执行:make clean,就会执行删除操作。
2.3 变量
在makefile中有两种变量:
2.3.1 简单变量(即使变量):
A := xxx # A的值即刻确定,在定义时即确定
对于即使变量使用 “:=” 表示,它的值在定义的时候已经被确定了
2.3.2 延时变量
B = xxx # B的值使用到时才确定
对于延时变量使用“=”表示。它只有在使用到的时候才确定,在定义/等于时并没有确定下来。
想使用变量的时候使用“$”来引用,如果不想看到命令是,可以在命令的前面加上"@"符号,就不会显示命令本身。当我们执行make命令的时候,make这个指令本身,会把整个Makefile读进去,进行全部分析,然后解析里面的变量。常用的变量的定义如下:
:= # 即时变量
= # 延时变量
?= # 延时变量, 如果是第1次定义才起效, 如果在前面该变量已定义则忽略这句
\\+= # 附加, 它是即时变量还是延时变量取决于前面的定义
?=: 如果这个变量在前面已经被定义了,这句话就会不会起效果,
实例:
A := $(C)
B = $(C)
C = abc
#D = 100ask
D ?= weidongshan
all:
@echo A = $(A)
@echo B = $(B)
@echo D = $(D)
C += 123
执行:
make

结果:
A =
B = abc 123
D = weidongshan
分析:
-
A := $©
A为即使变量,在定义时即确定,由于刚开始C的值为空,所以A的值也为空。 -
B = $©
B为延时变量,只有使用到时它的值才确定,当执行make时,会解析Makefile里面的所用变量,所以先解析C= abc,然后解析C += 123,此时,C = abc 123,当执行:@echo B = $(B) B的值为 abc 123。 -
D ?= weidongshan
D变量在前面没有定义,所以D的值为weidongshan,如果在前面添加D = 100ask,最后D的值为100ask。
我们还可以通过命令行存入变量的值 例如:
执行:make D=123456里面的D?= weidongshan这句话就不起作用了。
make D=123456

结果:
A =
B = abc 123
D = 123456
2.3.3 变量的导出(export)
在编译程序时,我们会不断地使用make -C dir切换到其他目录,执行其他目录里的Makefile。如果想让某个变量的值在所有目录中都可见,要把它export出来。
比如CC = $(CROSS_COMPILE)gcc,这个CC变量表示编译器,在整个过程中都是一样的。定义它之后,要使用export CC把它导出来。
2.3.4 shell命令
比如:
TOPDIR := $(shell pwd)
这是个立即变量,TOPDIR等于shell命令pwd的结果。
2.3.5 放置第1个目标
执行make命令时如果不指定目标,那么它默认是去生成第1个目标。所以第 1 个目标,位置很重要。有时候不太方便把第1个目标完整地放在文件前面,这时可以在文件的前面直接放置目标,在后面再完善它的依赖与命令。比如:
First_target: //这句话放在前面
......// 其他代码,比如 include 其他文件得到后面的 xxx 变量
First_target : $(xxx) $(yyy) // 在文件的后面再来完善
command
三、Makefile函数
makefile里面可以包含很多函数,这些函数都是make本身实现的,下面我们来几个常用的函数。引用一个函数用“$”。
3.1 函数foreach[遍历]
函数foreach语法如下:
$(foreach var,list,text)
前两个参数,var和list,将首先扩展,注意最后一个参数text此时不扩展;接着,对每一个list扩展产生的字,将用来为var扩展后命名的变量赋值;然后text引用该变量扩展;因此它每次扩展都不相同。结果是由空格隔开的text。在list中多次扩展的字组成的新的 list。text多次扩展的字串联起来,字与字之间由空格隔开,如此就产生了函数foreach的返回值。
实例:
A = a b c
B = $(foreach f, &(A), $(f).o)
all:
@echo B = $(B)
结果:
B = a.o b.o c.o
3.2 函数filter/filter-out[过滤]
函数filter/filter-out语法如下:
$(filter pattern...,text) # 在text中取出符合patten格式的值
$(filter-out pattern...,text) # 在text中取出不符合patten格式的值
实例:
C = a b c d/
D = $(filter %/, $(C))
E = $(filter-out %/, $(C))
all:
@echo D = $(D)
@echo E = $(E)
结果:
D = d/
E = a b c
3.3 Wildcard函数[通配符]
函数Wildcard语法如下:
$(wildcard pattern) # pattern定义了文件名的格式, wildcard取出其中存在的文件。
这个函数wildcard会以pattern这个格式,去寻找存在的文件,返回存在文件的名字。
实例:
在该目录下创建三个文件:a.c b.c c.c
files = $(wildcard *.c)
all:
@echo files = $(files)
结果:
files = a.c b.c c.c
我们也可以用wildcard函数来判断,真实存在的文件
实例:
files2 = a.c b.c c.c d.c e.c abc
files3 = $(wildcard $(files2))
all:
@echo files3 = $(files3)
结果:
files3 = a.c b.c c.c
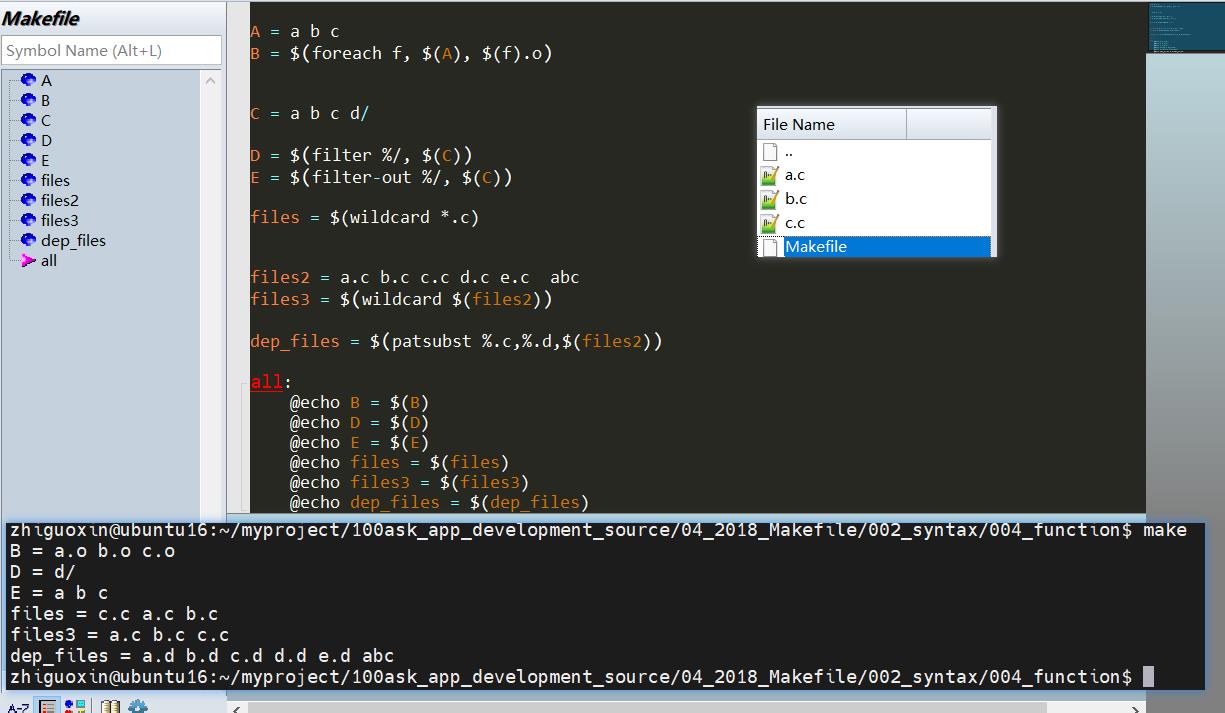
3.4 patsubst函数
函数patsubst语法如下:
$(patsubst pattern,replacement,$(var))
patsubst函数是从var变量里面取出每一个值,如果这个符合pattern格式,把它替换成replacement格式
实例:
files2 = a.c b.c c.c d.c e.c abc
dep_files = $(patsubst %.c,%.d,$(files2))
all:
@echo dep_files = $(dep_files)
结果:
dep_files = a.d b.d c.d d.d e.d abc
四、Makefile实例
在c.c里面,包含一个头文件c.h,在c.h里面定义一个宏,把这个宏打印出来。

c.c
#include <stdio.h>
#include <c.h>
void func_c()
printf("This is C = %d\\n", C);
c.h
#define C 1
然后上传编译,执行./test,打印出
This is B
This is C =1
测试没有问题,然后修改c.h
#define C 2
重新编译,发现没有更新程序,运行,结果不变,说明现在的Makefile存在问题。
test:a.o b.o c.o
gcc -o test $^
%.o : %.c
gcc -c -o $@ $<
clean:
rm *.o test
.PHONY: clean
为什么会出现这个问题呢, 首先我们test依赖c.o,c.o依赖c.c,如果我们更新c.c,会重新更新整个程序。但c.o也依赖c.h,我们更新了c.h,并没有在Makefile上体现出来,导致c.h的更新,Makefile无法检测到。因此需要添加:
c.o : c.c c.h
也就是
test:a.o b.o c.o
gcc -o test $^
c.o : c.c c.h
%.o : %.c
gcc -c -o $@ $<
clean:
rm *.o test
.PHONY: clean
现在每次修改c.h,Makefile都能识别到更新操作,从而更新最后输出文件。
这样又冒出了一个新的问题,**我们怎么为每个.c文件添加.h文件呢?**对于内核,有几万个文件,不可能为每个文件依次写出其头文件。因此需要做出改进,让其自动生成头文件依赖,可以参考这篇文章:http://blog.csdn.net/qq1452008/article/details/50855810
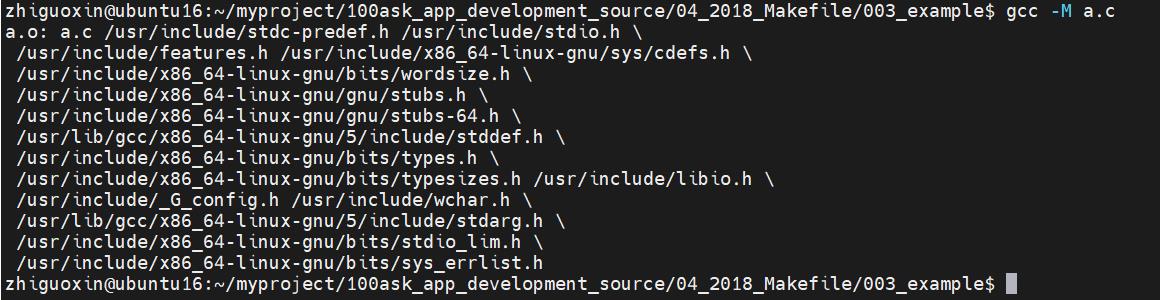
gcc -M a.c // 打印出依赖a.c所需要的依赖文件
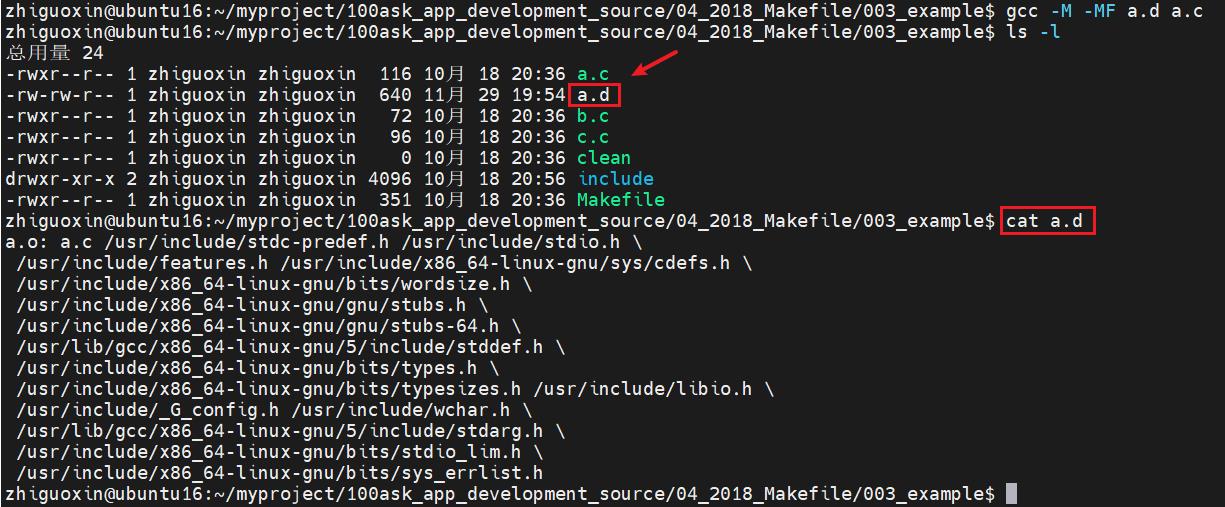
gcc -M -MF a.d a.c // 把a.c所需要的依赖文件写入文件a.d
gcc -c -o a.o a.c -MD -MF a.d // 编译a.o, 把a.c需要的依赖文件写入文件a.d
修改Makefile如下
# 用objs变量将.o文件放在一块
objs = a.o b.o c.o
# 把obj里所有文件都变为.%.d格式,并用变量dep_files表示
dep_files := $(patsubst %,.%.d, $(objs))
# 执行上面命令之后dep_files = a.o.d b.o.d c.o.d
# 判断dep_files是否存在
dep_files := $(wildcard $(dep_files))
# 目标文件test依赖所有的.o文件
test: $(objs)
gcc -o test $^
# 如果dep_files变量不为空,就将其包含进来
ifneq ($(dep_files),)
include $(dep_files)
endif
%.o : %.c
gcc -c -o $@ $< -MD -MF .$@.d
clean:
rm *.o test
distclean:
rm $(dep_files)
.PHONY: clean
首先用obj变量将.o文件放在一块。利用前面讲到的函数,把obj里所有文件都变为.%.d格式,并用变量dep_files表示。利用前面介绍的wildcard函数,判断dep_files是否存在。然后是目标文件test依赖所有的.o文件。如果dep_files变量不为空,就将其包含进来。然后就是所有的.o文件都依赖.c文件,且通过-MD -MF生成.d依赖文件。清理所有的.o文件和目标文件清理依赖.d文件。
现在我门修改了任何.h文件,最终都会影响最后生成的文件,也没任何手工添加.h、.c、.o文件,完成了支持头文件依赖。
下面再添加CFLAGS,即编译参数。比如加上编译参数-Werror,把所有的警告当成错误。
CFLAGS = -Werror -Iinclude
......
%.o : %.c
gcc $(CFLAGS) -c -o $@ $< -MD -MF .$@.d
现在重新make,发现以前的警告就变成了错误,必须要解决这些错误编译才能进行。在a.c里面声明一下函数:
void func_b();
void func_c();
重新make,错误就没有了。

除了编译参数-Werror,还可以加上-I参数,指定头文件路径,-Iinclude表示当前的inclue文件夹下。此时就可以把c.c文件里的#include ".h"改为#include <c.h>,前者表示当前目录,后者表示编译器指定的路径和GCC路径。
五、通用Makefile的设计思想
A. 在Makefile文件中确定要编译的文件、目录,比如:
obj-y += main.o
obj-y += a/
Makefile文件总是被Makefile.build包含的。
B. 在 Makefile.build 中设置编译规则,有 3 条编译规则:
- 1、怎么编译子目录? 进入子目录编译:
$(subdir-y):
make -C $@ -f $(TOPDIR)/Makefile.build
- 2、怎么编译当前目录中的文件?
%.o : %.c
$(CC) $(CFLAGS) $(EXTRA_CFLAGS) $(CFLAGS_$@) -Wp,-MD,$(dep_file) -c -o $@ $<
- 3.当前目录下的.o 和子目录下的 built-in.o 要打包起来:
built-in.o : $(cur_objs) $(subdir_objs)
$(LD) -r -o $@ $^
C. 顶层 Makefile 中把顶层目录的built-in.o链接成 APP
$(TARGET) : built-in.o
$(CC) $(LDFLAGS) -o $(TARGET) built-in.o
以上是关于Linux | 手把手教你写一个进度条小程序的主要内容,如果未能解决你的问题,请参考以下文章