论文|AGREE-基于注意力机制的群组推荐,含代码(Attentive Group Recommendation)
Posted 搜索与推荐Wiki
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文|AGREE-基于注意力机制的群组推荐,含代码(Attentive Group Recommendation)相关的知识,希望对你有一定的参考价值。
文章目录
这篇文章主要分享的论文是2018年被CCF收录的一篇论文:Attentive Group Recommendation(基于注意力机制的群组推荐),第一作者是湖南大学的曹达老师,二作是论文Neural Collaborative Filtering的作者何老师。当然也会结合小编的工作来进行一些补充说明,写的不好,欢迎拍砖!
这篇文章结合了注意力机制和NCF框架,使得在群组推荐中有良好的效果。
关于Neural Collaborative Filtering可以参考:点击阅读
关于注意力的解释可以参考:点击阅读
1、聊一聊群组推荐
群组推荐在工业推荐系统中应用十分广泛,其主要作用在新老用户上。
对于新用户来讲, 则是冷启动,常规的冷启动解决办法是,根据新用户的注册信息(性别、地域等,这个一般和产品设计进行结合)找到其所属的群组,将群组下的Top信息返回推荐给当前来访的新用户。
对于老用户来讲,可以作为一路召回使用。比如对所有用户进行群组划分,再统计群组下的Top内容作为群组下用户的一路召回内容。当然也可以按照某种属性进行群组划分。
所以群组推荐的实际应用中是很广泛和有效的,上面举的例子只是冰山一角,实际中要比这个复杂和广泛。但往往我们在得到群组下Top内容的时候采用的方法简单粗暴,这一点论文中也提到了群组推荐中的一个基本问题是如何汇总小组成员的偏好以推断小组的决定,因为群组中不同的成员扮演的角色是不一样的, 常见的计算方法有:
- 均值策略,即认为群组中每个人贡献是等价的,计算群组内top内容时,取对某内容贡献的均值。
- 最小化策略,即取群组内对某内容的最低贡献作为该内容的排序值
- 最大化策略,和最小化策略相反,即取群组内对某内容的最高贡献作为该内容的排序值
- 专家策略,根据用户在项目上的专业知识为其赋予了个性化的权重
但是,这些预定义的策略和数据无关,因为这些策略很难灵活的捕获群组成员的动态权重。因此提出了self-Attention Mechanism + NCF的思路,即Attentive Group Recommendation(AGREE)。
AGREE的主要贡献点有:
- 第一次将神经网络中的注意力机制用于群组推荐,基于输入数据动态地学习融合策略。
- 引入用户和内容之间的交互行为,提升群组推荐的效果,同时在一定程度上能够缓解冷启动问题(首先根据某种策略得到群组,新用户来访时匹配其对应的群组,根据群组内其他成员选取的top内容作为新用户的冷启动内容)。
- 基于数据集(爬取的和公开的)进行了大量的实验,并进行公开,促进学术研究。
2、模型介绍
AGREE模型包含两部:
- (1):基于小组成员聚集和偏好表示的群组表示学习
- (2):通过NCF进行交互学习,为用户和群组推荐项目
2.1、符号表示含义和要解决的问题
符号表示的规则
- 粗体大写字母(eg: X \\mathbfX X)表示矩阵
- 粗体小写字母(eg: x \\mathbfx x)表示向量
- 粗体小写字母(eg: x x x)表示标量
- 花体字母(eg: c a l X cal X calX)表示集合
如果未特别说明,所有的向量都是列向量。
下图说明了群组推荐任务中输入数据形态:
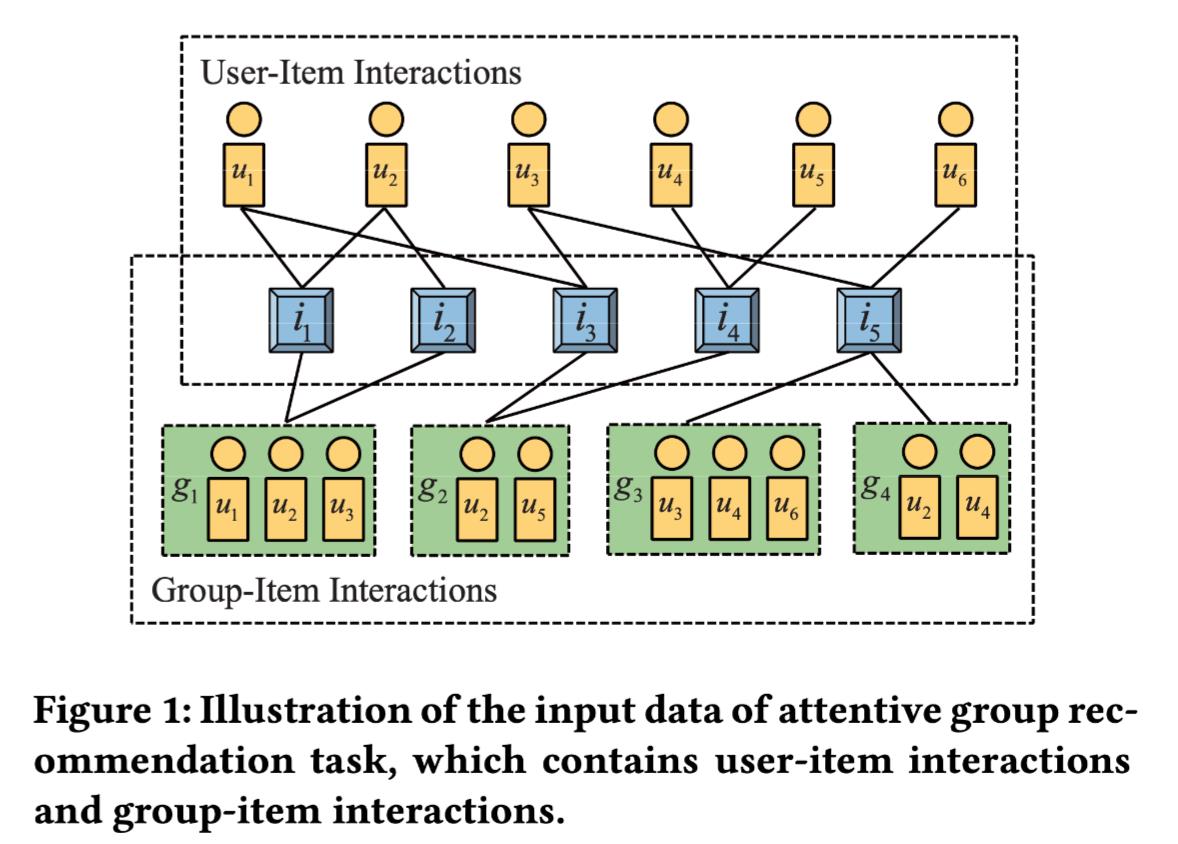
论文中给出的群组推荐问题定义的是:对于给定的群组,输出为该群组推荐的 Top-K物品。
整个模型训练的
- 输入是:用户集合 u 1 , u 2 , . . . . \\u_1, u_2, ....\\ u1,u2,....,群组集合 g 1 , g 2 , g 3 , . . . \\g_1, g_2, g_3, ...\\ g1,g2,g3,...,物品集合 v 1 , v 2 , v 3 , . . . \\v_1, v_2, v_3, ...\\ v1,v2,v3,...,群组和物品的交互矩阵 Y Y Y,用户和物品的交互矩阵 R R R
- 输出是:两个个性化的排序函数, f g f_g fg(将一个物品映射给一个群组的分值)、 f u f_u fu(将一个物品映射给一个用户的分值)
2.2、基于注意力的群组表征学习
论文建议基于表征学习解决群组推荐问题,在该框架下,每个实体都被表示为一个向量,该向量对实体的固有属性(eg:单词的语义,用户的兴趣等)进行编码,且可以从数据中学习。物品推荐中一个众所周知的矩阵分解方法就是一个表征学习模型,该模型将用户和物品通过嵌入向量联系起来。
u
i
u_i
ui表示用户向量,
v
j
v_j
vj表示物品向量,我们的目标是通过群组成员的兴趣偏好为每个群组学习到一个向量,要从数据中动态学习聚合策略,可以将群组向量定义成依赖用户和物品的向量,抽象表示为:
g
l
(
j
)
=
f
a
(
v
j
,
u
t
)
g_l(j) = f_a(v_j, \\u_t\\)
gl(j)=fa(vj,ut)
u
t
u_t
ut 表示
l
l
l群组中的用户。
g
l
(
j
)
g_l(j)
gl(j)表示群组
g
l
g_l
gl对物品
v
j
v_j
vj的偏好向量。在AGREE模型中,
g
l
(
j
)
g_l(j)
gl(j)包括两部分:用户向量聚合和群组偏好向量。形式化表示为:
g
l
(
j
)
=
∑
u
t
∈
g
l
a
(
j
,
t
)
u
t
+
q
l
g_l(j) = \\sum_u_t \\in g_l a(j,t)u_t + q_l
gl(j)=ut∈gl∑a(j,t)ut+ql
上面公式中加号左侧为用户向量,加号右侧为群组偏好向量。
用户向量聚合
对群组中的成员进行加权求和,系数 a ( j , t ) a(j,t) a(j,t)是一个可学习的参数,表示用户 u t u_t ut选择物品 v j v_j vj的影响力,很显然,如果一个用户在一个物品上的影响力比较大,则其对应的 a ( j , t ) a(j,t) a(j,t)也会比较大。例如在决定一个群组该去哪里旅行的决定中,如果一个用户去过中国很多次,那么这个用户对是否去中国旅行的决定权就会更大一些,这也比较符合人的期望。
在表征学习框架下,
u
t
u_t
ut表示用户的历史偏好,
v
j
v_j
vj表示物品的属性,我们将
a
(
j
,
t
)
a(j, t)
a(j,t)设置为注意力神经网络,输入为
u
t
u_t
ut和
v
j
v_j
vj:
o
(
j
,
t
)
=
h
T
R
e
L
U
(
P
v
v
t
+
P
u
u
t
+
b
)
o(j,t) = h^T ReLU(P_v v_t + P_u u_t +b)
o(j,t)=hTReLU(Pvvt+Puut+b)
a
(
j
,
t
)
=
s
o
f
t
m
a
x
(
o
(
j
,
t
)
)
=
e
x
p
(
o
(
j
,
t
)
)
∑
t
∈
g
l
e
x
p
(
o
(
j
,
t
)
)
a(j,t) = softmax(o(j,t)) = \\fracexp(o(j,t)) \\sum_t \\in g_l exp(o(j,t))
a(j,t)=softmax(o(j,t))=∑t∈glexp(o(j,t))exp(o(j,t))
其中:
- t ∈ g l t \\in g_l t∈gl表示群组 g l g_l gl 中用户的下标
- P v P_v Pv 和 P u P_u Pu表示物品 v j v_j vj和用户 u t u_t u以上是关于论文|AGREE-基于注意力机制的群组推荐,含代码(Attentive Group Recommendation)的主要内容,如果未能解决你的问题,请参考以下文章