深剖 Linux 进程控制
Posted 乔乔家的龙龙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深剖 Linux 进程控制相关的知识,希望对你有一定的参考价值。
目录
传统艺能😎
小编是双非本科大一菜鸟不赘述,欢迎大佬指点江山,QQ - 1319365055
🎉🎉非科班转码社区诚邀您入驻🎉🎉
小伙伴们,打码路上一路向北,彼岸之前皆是疾苦
一个人的单打独斗不如一群人的砥砺前行
诚邀各位有志之士加入!!
直达: 社区链接点我

pc 指针🤔
我们说进程调用 fork ,当控制转移到内核的 fork 代码后,内核会:
- 将父进程部分数据拷贝给子进程;
- 分配新的内存块和数据结构给子进程;
- 子进程添加到进程列表;
- fork 返回,开始调度
因此 fork 之前父进程独立执行,fork 后父子分别执行,但是谁先谁后完全取决于调度器。
fork 之后,共享的只有 fork 后的代码吗?一般情况下,是父子共享所有代码,虽然子进程执行后续代码,它是相当于共享了所有代码但是子进程只能从某个地方开始执行!什么原理呢?很简单,在 CPU 里面有一种寄存器能保存当前的执行进度,它叫 eip,普遍喜欢叫它程序计数器或者 pc 指针,通过保存当前正在执行指令的下一条指令,拷贝给子进程。
为什么要写时拷贝?🤔
我们创建子进程的时候,直接给父子进程单独拷一份把数据分开,这样不香吗?
首先,这种方法是肯定可行的,但是不是最优的。父进程的数据,子进程不一定全用,即使全用也不一定全部写入,这样会有浪费空间的嫌疑。那为什么不把要用的数据拷一份?先不说技术上有没有人能完美实现,就算我拷贝了要用的但是不进行写入或修改的话绕一圈还是在浪费嘛。第三如果 fork 时无脑给子进程拷贝还会增加 fork 的成本,不管是内存还是时间。
所以采取写时拷贝,只会拷贝父子修改的就是拷贝的最小成本,但是拷贝的成本是不可消除的,这时一种延迟拷贝策略,他最大的意义就是你想要但是不立马使用的会先给别人提高了使用效率。
退出码🤔
我们知道程序结束会 return 0,但是大部分情况我们都是在无脑返回 0,程序最终返回 0 说明得到了我想要的结果,不为 0 就是失败了,那么非 0 返回值就是在标识失败的原因:return x ,这个 x 就是进程退出码。
我们可以查看当前程序的退出码:
echo $?
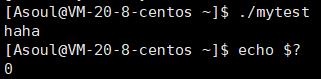
这个 $? 就是 bash 中最近一次执行完毕时对应的进程退出码。普通的 C++ 代码可以无脑搞个 return 0,但是系统编程时强烈建议搞清楚当前程序的退出码,一般来讲失败的这个非 0 值是可以自定义的,主要是不同返回值方便我们定位不同问题。
exit 与 _exit🤔
main 函数中 return 代表进程终止,但是其他函数为什么不能 return 呢?不代表,return 仅仅代表当前函数调用结束!但是在自己代码中任意位置调用 exit ,就可以直接终止进程,exit 是C库函数,exit(x)中这个 x 就是自义定的退出码。
exit 的底层原理就是利用 _exit 函数 ,功能上二者无异,exit 调用是终止进程并且刷新缓冲区关闭文件流,而 _exit 是直接终止进程,不会有任何其他动作。
slab 分配器🤔
创建对象的过程包括了开辟空间和初始化,对象创建了像 task_struct,mm_struct 这种内核数据结构可能并不会被系统释放,那么系统会维护一个废弃的链表,不要的数据结构就放在这里,所以系统不是去释放而是放在这里使其无效化,当我们再度开辟时,就进行迭代即可,这样节约了申请时间直接跳到初始化,这种结构叫做内核数据结构缓冲池,也叫他 slab 分配器。

进程等待🤔
这个概念是根据僵尸进程提出的,为什么进程结束后不直接终止(X 状态)而是要先进入僵尸进程(Z 状态)?
子进程退出后如果父进程不管就会造成所谓的僵尸进程,从而造成内存泄漏,另外一旦变成僵尸进程连 kill 指令也束手无策,因为逻辑上你无法杀死一个已经死去的进程。其次,父进程有义务知道子进程的完成情况且结果是否正确,我们说到的退出码这里也是这样,确认子进程的退出状态就是子进程的退出码需要被父进程所读取。
所以进程等待实际上是父进程回收子进程资源,获取子进程退出信息的重要渠道!
进程等待方法🤔
wait😎
函数原型以及所需头文件:
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);
返回值:等待成功则返回等待进程的PID,等待失败,返回-1;参数为输出型参数,获取子进程退出状态,不关心则可以设置成为 NULL 即可。
因此我们不妨用 wait 来验证一下僵尸进程和进程等待机制,通过 fork 创建子进程实现打印,然后终止掉子进程,子进程便处于僵尸状态,此时父进程是处于等待状态的,在10秒后开始对子进程进行处理(也就是获取子进程的pid),处理结束子进程退出,父进程此时再次等待10秒后退出 :
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
pid_t id = fork();
if(id == 0)
int ret = 5;
while(ret)
printf("child[%d] is running:ret is %d\\n", getpid(), ret);
ret--;
sleep(1);
exit(0);
sleep(10);
printf("father wait begin..\\n");
pid_t cur = wait(NULL);
if(cur > 0)
printf("father wait:%d success\\n", cur);
else
printf("father wait failed\\n");
sleep(10);
程序结果:
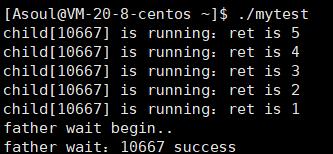
我们在运行的同时可以再复制一个 SSH 渠道的 shell 脚本来进行监视功能:
while :; do ps axj | head -1 && ps axj | grep mytest | grep -v grep; sleep 1; echo "**********************"; done
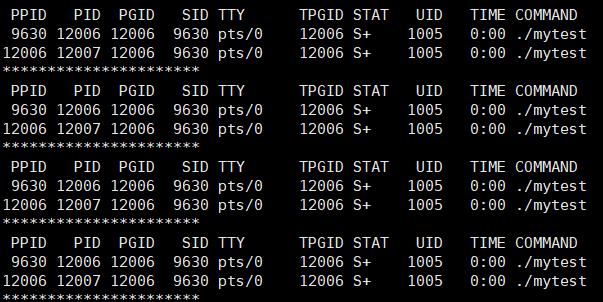
监视窗口如下,我们结果可以明显分为 4 大部分:
- 进程开始运行,父子进程同时运行。这里应该有 5 个因为打印 5 次,监视窗口手慢了漏了一次大家就当无事发生。
- 子进程结束,父进程继续,因此子进程变成僵尸进程,触发父进程等待机制
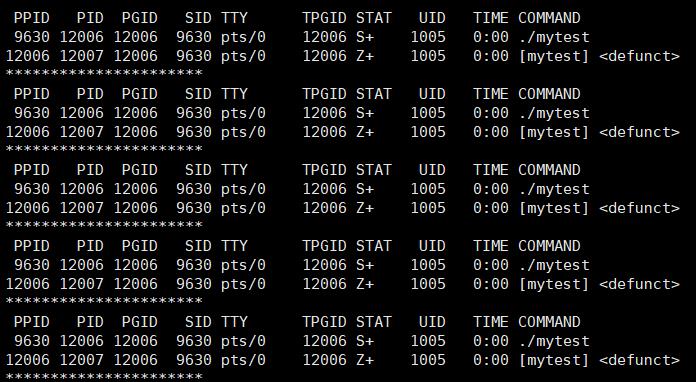
- 子进程开始向父进程返回自己 pid,父进程通过等待机制回收子进程:
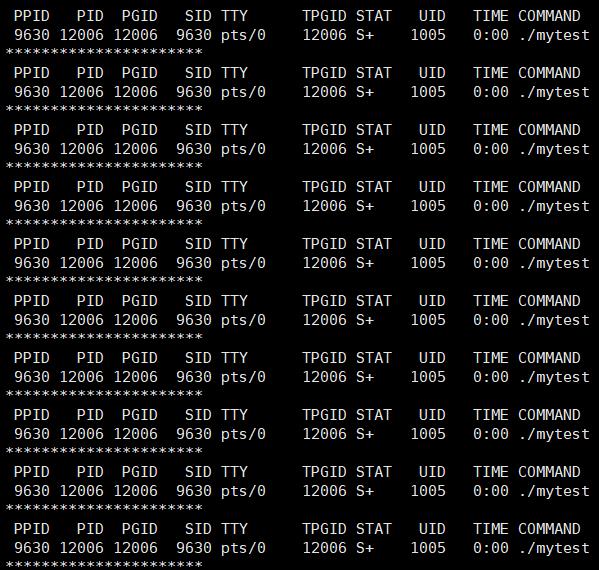
- 父进程得到子进程 pid 和 退出码,父进程退出,程序终止:

waitpid😎
所需头文件:
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *status, int options);
返回值:当正常返回的时候waitpid返回收集到的子进程的进程ID;如果设置了选项WNOHANG,而调用中 waitpid 发现没有已退出的子进程可收集,则返回0;如果调用中出错,则返回 -1,这时 errno 会被设置成相应的值以指示错误所在
三个参数:
pid:
Pid=-1,等待任一个子进程。与wait等效。
Pid>0.等待其进程ID与pid相等的子进程。
status:
WIFEXITED(status): 若为正常终止子进程返回的状态,则为真。(查看进程是否是正常退出)
WEXITSTATUS(status): 若WIFEXITED非零,提取子进程退出码。(查看进程的退出码)
options:
WNOHANG: 若pid指定的子进程没有结束,则waitpid()函数返回0,不予以等待。若正常结束,则返回该子进程的PID。
具体的实现
waitpid 函数两种情况:
- pid_t cur = waitpid(id, NULL, 0);//等待指定一个子进程
- pid_t cur = waitpid(-1, NULL, 0);//等待任意一个子进程
这里我们使用第二种情况,大体思路和 wait 是一样的,结果也是一样的:
pid_t cur = waitpid(-1, NULL, 0);//等待任意一个子进程
if(cur > 0)
printf("father wait:%d success\\n", cur);
else
printf("father wait failed\\n");
status 参数🤔
int* status 是一种输出型参数,其中 status 是由32个比特位构成的一个整数,目前阶段我们只使用低16个位来表示进程退出的结果,正常终止的话 8 比特位保存退出状态,7 比特位保存退出码 0;而如果是被信号 kill 了,他就会大有不同,在未使用空间后面的结尾空间用于保存终止信号,在未使用空间和终止信号之间还有一个比特位大小的core dump 标志
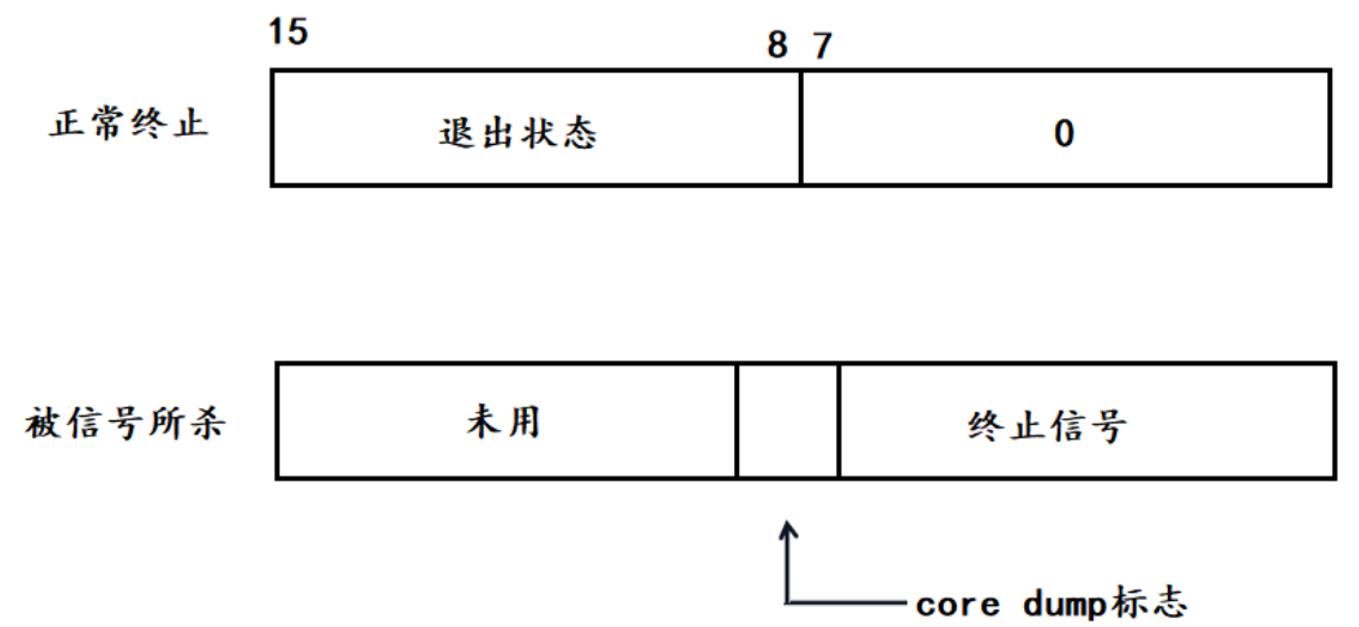
因此要获取 status 很简单,我们用次低8位表示进程退出时的退出状态,也就是退出码;用低7位表示进程终止时所对应的信号,我们想要拿到这个退出码和信号的值,只要拿到低 16 个比特位中的次低 8 位和低 7 位就可以了。
status >> 8 & 0xFF;//次低8位,退出码
status & 0x7F;//低7位,退出信号
注意不能简单理解 status 为一个单纯的整数,status 结果和子进程的退出方式强相关,因此具体情况具体分析!
退出码与退出信号🤔
我们就用上面的代码就可以测试出一段代码的退出码和退出信号:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
pid_t id = fork();
if(id == 0)
int ret = 3;
while(ret)
printf("child[%d] is running:ret is %d\\n", getpid(), ret);
ret--;
sleep(1);
exit(10);
printf("father wait begin..\\n");
int status = 0;
pid_t cur = waitpid(id, &status, 0);
if(cur > 0)
printf("father wait:%d success, status exit_code:%d, status exit_signal:%d\\n", cur, (status >> 8)& 0xFF, status & 0x7F);
else
printf("father wait failed\\n");

那么进程退出时先看退出码还是退出信号?
退出码对应了进程退出的两种情况:
- 代码跑完且结果正确;
- 代码跑完但结果不正确;
进程信号代表的是进程跑完还是没跑完,因此一个程序要能跑完才有资格谈退出码,进程异常只关心退出信号。
其实 Linux 也给我们提供一些宏供我们直接使用,懒得去敲神魔位运算:
WIFEXITTED(status):正常终止子进程返回的状态为真,用于查看是否正常退出
WEXITSTAUS(status):WIFEXITTED 非零时提取子进程退出码
aqa 芭蕾 eqe 亏内,代表着开心代表着快乐,ok 了家人们。
深剖mallocnew
如果问你:malloc和new有什么区别?讲讲malloc,越多越好?
malloc 和 new都是基于堆上开辟出对应的空间,这段空间除非进程结束不然不会释放,所以分别需要free 和 delete来释放。
new 还可以用 new[] 来开辟一段连续的空间,new和malloc不同,new在为一个类的对象开辟空间时还会调用对象的构造函数。
同理,delete 和 delete[] 在针对一个类的对象的空间时也会调用对应的析构函数,而malloc 和 free不会。
这样够吗????
够不够我不知道,我觉得,能回答的更好:
一.他们不是一类东西
new 是C++规则里给的一个关键字,它是一个运算符,可以被重载,而malloc 是一个函数,它的目的就是在堆上开辟一块空间。
new 的底层也是根据malloc 实现的,如果你有VS,完全可以调试时按F11 进new 过程看看。
可以发现,new 和 delete 一个NULL对象,是允许的,进去以后会有个判断,判断到NULL会直接返回,不会报错。
但是!!!!new 运算符是可以重载的,所以。它可以在堆以外的地方开辟空间吗???
完全可以!
因为本来new 底层是根据malloc 实现,行,我直接将其重载,让它在别的区域上起作用!这不就可以吗?
所以,要纠正这个误区,在没被重载的情况下,new 是在堆上开辟空间。
二.new是刘德华。
我们经常可以看到,每次malloc 后,都要判断一下是否malloc 成功,如果不成功就不执行接下来的操作了。
就比如如下代码:
1 char *p = (char *)malloc(sizeof(char) * 20); 2 if(NULL == p) 3 perror("malloc"),exit(1);
这是一个很好的习惯,在意外情况发生时能及时处理。
但是,我们却不常常在new 的后面见到意外情况的处理。
为什么?new 不会失败吗?
因为new 失败后,会直接报错,编译器会自动终止你的进程。
一个回不了头,一个还能挽救。
当然,如果要让new 在失败以后也是返回NULL,就需要特殊的处理方法:
1.在new 后面加上nothrow ,就比如用new(nothrow) A ,而不是new A 。
2.重载new 运算符,千万别忘了我们C++ 重要的特性之一——多态。
需要特别注明:每种编译器下new 的底层实现是不同的,所以返回NULL 还是报异常,都要看其底层的具体实现,所以,在使用一个编译器下的某种不确定的函数或关键字时,对底层的探索,重中之重。
三.new[ ] 是有区别对待的
new[ ] 一个有构造函数和析构函数的类的对象的数组时,new[ ] 开辟出的空间是要多开辟四个字节的区域在头部,用于记录对象个数。
但是,当new[ ] 的空间是一块基本类型的数组,或者是一个不带有析构函数的类的对象数组时,这块区域就不会出现。
让我们用代码探索一下:(这里我使用VS2013编辑代码)
1 #include <iostream> 2 3 using namespace std; 4 5 class Test_1 //构造+析构 6 { 7 public: 8 Test_1() 9 :mem(1) 10 {} 11 12 ~Test_1() 13 { 14 cout << "Test_1" << endl; 15 } 16 private: 17 int mem; 18 }; 19 20 class Test_2 //无析构 21 { 22 public: 23 Test_2() 24 :mem(2) 25 {} 26 private: 27 int mem; 28 }; 29 30 int main() 31 { 32 Test_1 *p1 = new Test_1[10]; 33 Test_2 *p2 = new Test_2[10]; 34 35 int *p3 = new int[10]; 36 system("pause"); 37 return 0; 38 }
我设立了一个带析构的类Test_1和一个不带析构的类Test_2,我们再看new 的底层实现:
1 void *__CRTDECL operator new[](size_t count) _THROW1(std::bad_alloc) 2 { // try to allocate count bytes for an array 3 return (operator new(count)); 4 }
可见new[ ] 底层调用了函数operator new ,并赋予一个参数count,用于记录开辟的空间大小。
让我们看一下对于3次调用new的count大小:
Test_1:

Test_2:

int:

由此可见,对于带析构函数的类,new[ ]在开辟空间时会多开辟4个字节的空间,用于什么呢?我们来看一下内存。

可以很明显看到,p1指针所在位置前一个地址的值为0x0000000a,化为10进制值为10,可知其就是为了保存所需要开辟的对象有多少个。
可以总结出:这里特地腾出的空间是专门为类的析构函数服务的,每次开辟空间的指针在释放空间时,都会根据空间前四个字节内的值来得出——是否需要调用析构函数?以及,调用多少次析构函数?
四.malloc所开辟的,可不止这么点点。
有没有想过?malloc 开辟一块堆上空间后,系统怎么去管理它?下次需要开辟空间时,系统怎么知道这块区域已被用?
没事,系统总会有办法的。
malloc 的作用,不是去堆上直接取,而是向操作系统申请这块空间的使用权,等CPU响应这个申请,然后执行相应的操作,当然,操作系统为了更好地管理malloc 完的这块空间,它会选择给这块空间之前加一个结构体,也就是一个装有这块空间的属性的包,在这块空间后一位的地址处内容是0xFCFCFCFC,可以理解为是这块空间的终止符,让系统能分辨出这块空间申请到何处。
malloc 有关的结构体:
1 typedef struct s_block *t_block; 2 struct s_block { 3 size_t size; /* 数据区大小 */ 4 t_block next; /* 指向下个块的指针 */ 5 int free; /* 是否是空闲块 */ 6 int padding; /* 填充4字节,保证meta块长度为8的倍数 */ 7 char data[1] /* 这是一个虚拟字段,表示数据块的第一个字节,长度不应计入meta */ 8 };
系统会根据当前操作系统空间块的分配算法,分配给malloc 合适的空间并附上结构体和收尾标识以助于管理。
所以,malloc 出来的空间会大于用户可见的空间。
以上是关于深剖 Linux 进程控制的主要内容,如果未能解决你的问题,请参考以下文章