educoder:实验十一 函数
Posted 白昼57
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了educoder:实验十一 函数相关的知识,希望对你有一定的参考价值。
第1关:定义判断质数的函数
任务描述
本关任务:编写一个能判断质数的函数。若参数是质数,返回true;否则返回false。 主程序输入一个数n,然后调用该函数判断其是否是质数,是则显示n是质数,否则显示n不是质数。
相关知识
为了完成本关任务,你需要掌握:如何定义函数。
定义函数
def <函数名> (<参数列表>): <函数体> return <返回值列表>
编程要求
根据提示,在右侧编辑器补充代码,将定义质数的函数补充完整。
测试说明
平台会对你编写的代码进行测试:
测试输入15; 预期输出: 15不是质数
测试输入:113 预期输出: 113是质数
穷则独善其身,达则兼济天下 开始你的任务吧,祝你成功!
代码:
n=eval(input("请输入一个数"))
def isprime(n):
if n > 1:
for i in range(2,n):
if (n % i) == 0:
print(n,"不是一个质数")
break
else:
print(n,"是一个质数")
else:
print(n,"不是一个质数")
isprime(n)第2关:绝对质数
任务描述
本关任务:编写一个输出所有两位数的绝对质数的小程序。 每行显示3个数,每个数后面四个空格 注意:isprime函数已经定义在本文件夹的程序isprime.py中
相关知识
为了完成本关任务,你需要掌握:1.什么是绝对质数,2.如何调用函数。
什么是绝对质数
一个质数,当它的数字位置对换以后仍为质数,这样的数称为绝对质数。例如17和71都是质数,所以17和71是绝对质数
调用函数
程序调用一个函数需要执行以下四个步骤: (1)调用程序在调用处暂停执行; (2)在调用时将实参复制给函数的形参; (3)执行函数体语句; (4)函数调用结束给出返回值,程序回到调用前的暂停处继续执行 函数名可以作为表达式的一部分,可以直接输出,可以出现在赋值语句,也可以作为其他函数的参数
测试说明
平台会对你编写的代码进行测试:

学而不思则罔,思而不学则殆。 开始你的任务吧,祝你成功!
代码:
from isprime import *
#代码开始
x=0
for i in range(11,100):
y=str(i)
if isprime(eval(y[0]+y[1]))and isprime(eval(y[1]+y[0])):
print(i,end=" ")
x+=1
if x%3==0:
print()
#代码结束第3关:验证哥赫巴德猜想
任务描述
本关任务:验证100之内大于2的偶数符合哥赫巴德猜想。
哥赫巴德猜想是任一大于2的偶数都可写成两个质数之和。
注意:调用isprime函数(在isprime.py文件中)判断是否质数 每行显示五个式子。每个式子的整数显示两位,每个式子后面显示tab(\\t)

有志者,事竟成,破釜沉舟,百二秦关终属楚;苦心人,天不负,卧薪尝胆,三千越甲可吞吴。 开始你的任务吧,祝你成功!
代码:
from isprime import *
z,items=0,[]
for i in range(4,100,2):
for x in range(2,100):
for y in range(2,100):
if isprime(x) and isprime(y) and i==x+y and i not in items:
items.append(i)
print(":2d=:2d+:2d".format(i,x,y),end="\\t")
z+=1
if z%5==0:
print()第4关:判断三角形类型
任务描述
本关任务:编写一个根据三条边长判断三角形类型的函数。 若不能构成三角形,返回0. 若构成等边三角形,返回1. 若构成等腰三角形,返回2 若构成直角三角形,返回3. 若是其他三角形,返回4.
在主程序中,根据函数的返回值,显示对应的三角形类型
相关知识
为了完成本关任务,你需要掌握: 1.如何定义函数 2.如何调用函数
定义函数
def 函数名(形式参数): 函数内容 return 返回值
调用函数
函数名(实际参数)
测试输入:3,3,3;
预期输出: 等边三角形
测试输入:1,2,3;
预期输出: 不能构成三角形
测试输入:3,4,5;
预期输出: 直角三角形
人的心灵是有翅膀的,会在梦中飞翔。 开始你的任务吧,祝你成功!
代码:
def sjx(a,b,c):
lx=0
if a+b<c and a+c<b and b+c<a:
lx=0
elif a==b==c:
lx=1
elif a==b or a==c or b==c:
lx=2
elif a**2+b**2==c**2 or a**2+c**2==b**2 or b**2+c**2==a**2:
lx=3
return lx
x=eval(input())
y=eval(input())
z=eval(input())
m=sjx(x,y,z)
if m==0:
print("不能构成三角形")
elif m==1:
print("等边三角形")
elif m==2:
print("等腰三角形")
elif m==3:
print("直角三角形")
else:
print("一般三角形")第5关:成语字典精确查询
任务描述
本关任务:编写一个能查询成语字典的小程序。 sy10文件夹的成语.txt的图片如下图所示
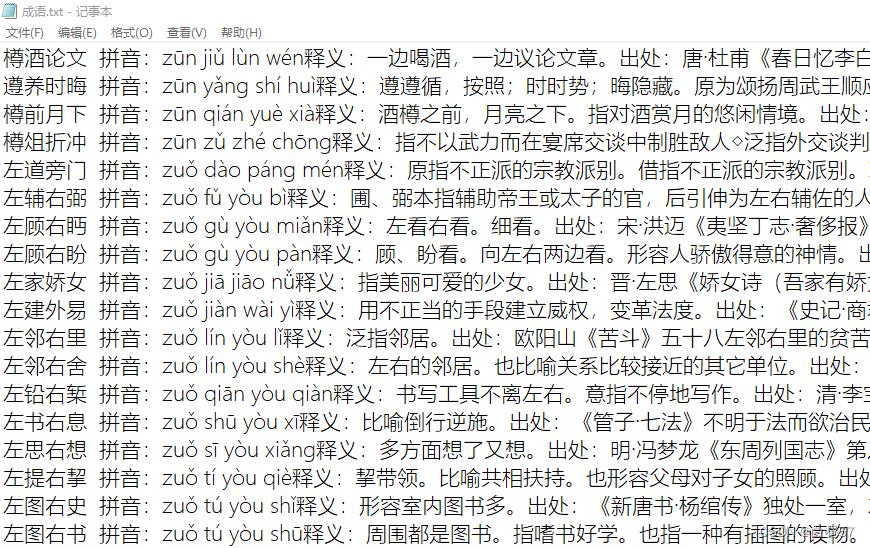
编程要求
根据提示,将函数cyjl补充完整,将文件成语.txt的成语加入到cyzd字典,键为成语,值为后面的内容。 将函数精确查询jqcx补充完整,输入成语,显示该成语的所有信息。若成语不存在,显示成语不存在 将主程序补充完整,用户可循环输入1进行精确查找;输入0,退出程序
测试说明
平台会对你编写的代码进行测试:
测试输入: 1精确查询0退出1 请输入成语事半功倍 拼音:shì bàn gōng bèi释义:指做事得法,因而费力小,收效大。出处:《孟子·公孙丑上》故事半古之人,功必倍之,惟此时为然。”示例:如能善用他的特长和经验,比较地容易获得~的效果。★邹韬奋《经历·前途》 1精确查询0退出1 请输入成语飞飞飞飞 没有此成语 1精确查询2模糊查询0退出0
开始你的任务吧,祝你成功!
代码:
cyzd =
c = input("1精确查询0退出")
def cyjl():
f1 = open("sy10//成语.txt", "r", encoding="utf8")
for line in f1:
cy = line[:line.find(" ")].strip()
js = line[line.find(" ") + 1:].strip()
cyzd[cy] = js
f1.close()
def jqcx():
x = input("请输入成语")
if x not in cyzd:
print("没有此成语")
else:
print(cyzd[x])
cyjl()
while c != "0":
if c == "1":
jqcx()
c = input("1精确查询0退出")第6关:成语字典模糊查询
任务描述
本关任务:编写一个能查询成语字典的小程序。 sy10文件夹的成语.txt的图片如下图所示
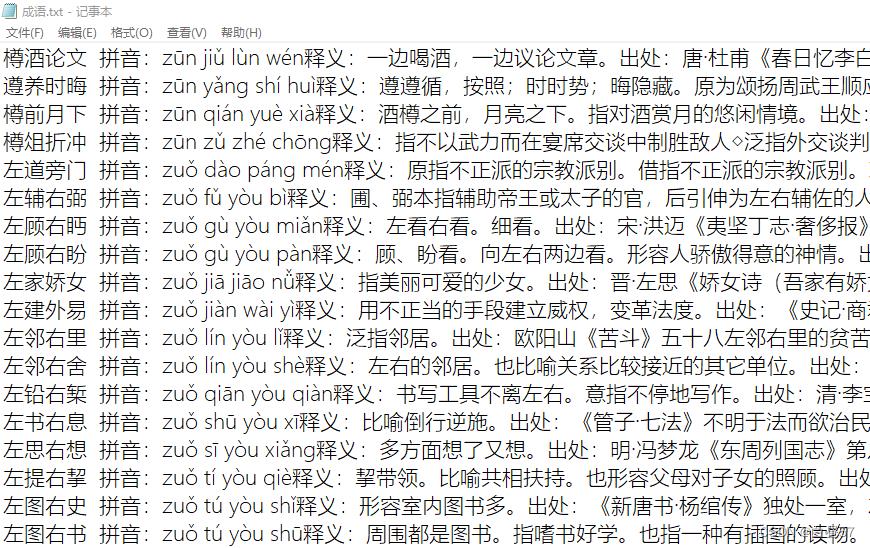
编程要求
根据提示, 将函数模糊查询mhcx补充完整,输入词语,显示所有包含该词语的成语
将主程序补充完整,用户可循环输入1,进行精确查找;输入2,进行模糊查找;输入0,退出程序
测试说明
平台会对你编写的代码进行测试:
测试输入: 1精确查询2模糊查询0退出2 请输入词语梦 醉生梦死 醉死梦生 庄周梦蝶 庄生梦蝶 昼想夜梦 重温旧梦 至人无梦 云梦闲情 一梦华胥 一场春梦 夜长梦短 夜长梦多 哑子托梦 哑子寻梦 哑子做梦 熊罴入梦 同床各梦 同床异梦 如梦初觉 如梦初醒 如梦方醒 如梦如醉 如醉如梦 如痴如梦 人生如梦 鹏游蝶梦 南柯一梦 梦笔生花 梦断魂劳 梦幻泡影 梦魂颠倒 梦见周公 梦里南轲 梦寐以求 梦撒寮丁 梦撒撩丁 梦想颠倒 梦熊之喜 梦中说梦 眠思梦想 江淹梦笔 魂劳梦断 魂牵梦萦 魂驰梦想 魂颠梦倒 黄梁美梦 黄梁一梦 黄粱美梦 黄粱一梦 恍如梦境 恍如梦寐 槐南一梦 好梦不长 好梦难成 好梦难圆 酣然入梦 更长梦短 浮生若梦 分床同梦 飞熊入梦 丹漆随梦 大梦初醒 大梦方醒 春梦无痕 楚梦云雨 痴人说梦 半梦半醒 白日作梦 白日做梦 1精确查询2模糊查询0退出2 请输入词语拳 揎拳拢袖 揎拳掳袖 揎拳捋袖 揎拳裸臂 揎拳裸手 揎拳裸袖 揎拳攞袖 揎拳捰袖 揎拳舞袖 掀拳裸袖 无拳无勇 握拳透掌 握拳透爪 捰袖揎拳 袒臂挥拳 三拳不敌四手 三拳两脚 拳不离手,曲不离口 拳打脚踢 拳拳服膺 拳拳盛意 拳拳在念 拳拳之枕 拳头上立得人,胳膊上走得路 拳中掿沙 摩拳擦掌 磨拳擦掌 捋袖揎拳 裸袖揎拳 攞袖揎拳 毒手尊拳 撺拳拢袖 赤手空拳 嗔拳不打笑面 擦拳磨掌 擦拳抹掌 擦掌磨拳 猜拳行令 饱飨老拳 饱以老拳 白手空拳 1精确查询2模糊查询0退出0
开始你的任务吧,祝你成功!
代码:
cyzd =
c = input("1精确查询2模糊查询0退出")
def cyjl():
f1 = open("sy10//成语.txt", "r", encoding="utf8")
for line in f1:
cy = line[:line.find("拼音")].strip()
cyjx = line[line.find("拼音"):].strip()
cyzd[cy] = cyjx
f1.close()
def mhcx(x):
for i in cyzd:
if x in i:
print(i)
def jqcx(x):
if x in cyzd.keys():
print(cyzd[x])
else:
print("成语不存在")
cyjl()
while c != "0":
if c != "1":
x = input("请输入词语")
mhcx(x)
else:
x = input("请输入成语")
jqcx(x)
c = input("1精确查询2模糊查询0退出")第7关:成语接龙小游戏
任务描述
本关任务:编写一个成语接龙小游戏。 在sy10文件夹下,有一个成语.txt文件,如下所示
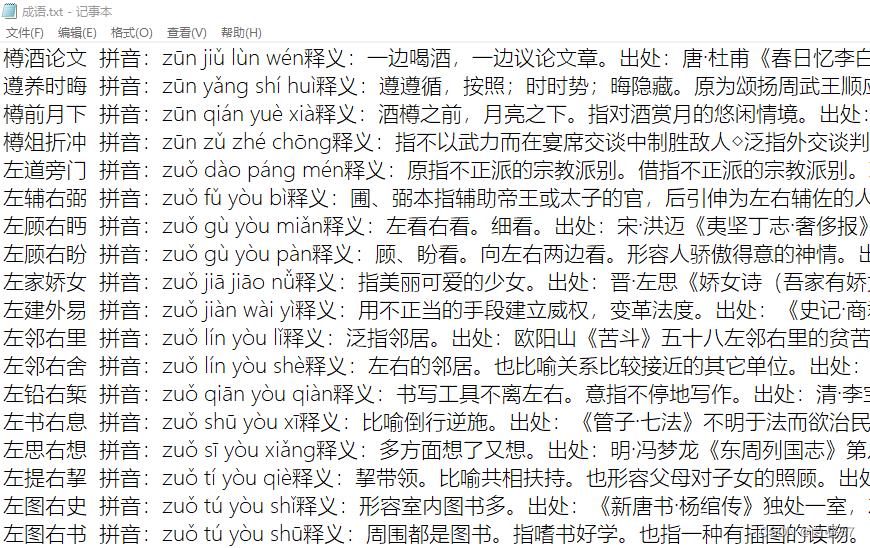
在上述成语字典程序中,增加一个成语接龙的选项。 游戏规则如下: 用户输入一个成语,若用户输入的不是文件中的成语,则显示“非法成语,你输了” 若输入正确成语,系统会到成语文件中找到以你输入成语的最后一个字开始的成语。 若系统没有找到,则显示“你赢了。”退出接龙。 若系统找到了,则显示该成语。 用户继续输入以该成语结尾的字开始的成语,若输入的成语符合要求,则系统继续接龙。 若成语没有接龙,系统提示“没有接龙"
测试说明
补充yx函数,实现游戏过程
测试输入: 3 走马观花 花残月缺 缺衣少食 食案方丈 丈二和尚 尚虚中馈 溃不成军 没有接龙,你输了
测试输入: 3 狐假虎威 威风八面 面面俱到 你赢了
测试输入: 3 天下太平 平安无事 事半功倍 倍道而进 进出两难 非法成语,你输了
开始你的任务吧,祝你成功!
代码:
cyzd =
c = input("1精确查询2模糊查询3成语接龙0退出")
def cyjl():
f1 = open("sy10//成语.txt", "r", encoding="utf8")
for line in f1:
cy = line[:line.find("拼音")].strip()
cyjx = line[line.find("拼音"):].strip()
cyzd[cy] = cyjx
f1.close()
def mhcx(x):
for y in cyzd.keys():
if x in y:
print(y)
def jqcx(x):
if x in cyzd.keys():
print(cyzd[x])
else:
print("成语不存在")
def yx1(x):
y = []
for i in cyzd:
y.append(i)
if x in y:
for i in y:
if x[-1] == i[0]:
print(i)
x = input("请输入成语")
if x not in y or x[0] == i[-1]:
yx1(x)
else:
print("没有接龙,你输了")
break
else:
print("你赢了")
else:
print("非法成语,你输了")
cyjl()
while c != "0":
if c == "1":
x = input("请输入成语")
jqcx(x)
elif c == "2":
x = input("请输入词语")
mhcx(x)
elif c == "3":
x = input("请输入成语")
yx1(x)
c = input("1精确查询2模糊查询3成语接龙0退出")头歌Educoder云计算与大数据——实验五 Java API分布式存储
实验五 Java API分布式存储
第1关: 利用shell把电商数据上传到HDFS
任务描述
原始电商数据都是存储在关系型数据库或 NoSQL 数据库上的,是面向OLTP(联机事务处理过程)的;数据都是面向业务的,而不是面向分析。因此数据比较复杂,表很多关联的数据是分散的,不利于统计分析;因此需要把数据从多个表里导出来、联合起来,找出分析所需要的数据项,然后把这些数据存入到 HDFS 中。
另一方面,因为数据量很大,可能上百 GB 甚至 TB,这些数据超过了单台服务器的内存容量甚至硬盘容量,而且如果都存到一台服务器上,那么读写起来花费时间也是很长的,如果把数据分摊到多个服务器上,那么原本的读写时间就能减倍,HDFS 就能做到这一点。
HDFS 是 Hadoop 中的分布式文件系统,可以高效的利用多台(数百、数千都可以)服务器的存储能力,因此把电商数据存储到 HDFS 中,可以借助强大的 Hadoop 来管理、分析海量的电商数据,以挖掘最大的潜在商业价值。
本关任务:使用 HDFS shell 命令把电商数据从本地上传到 HDFS 中。
相关知识
为了完成本关任务,你需要掌握:HDFS shell常见命令:
HDFS shell常见命令
如果你熟悉 linux 命令,你会发现 HDFS shell 命令类似 linux 的shell命令,在终端直接输入命令行来管理HDFS中的文件、文件夹。常用的HDFS命令如下:
hdfs dfs -ls / 查看目录/下的文件和文件夹;
hdfs dfs -mkdir /images 创建新文件夹/images;
hdfs dfs -rmdir /images 删除文件夹/images;
hdfs dfs -rm /citys.csv 删除文件citys.csv;
hdfs dfs -put data02.csv /dataset 上传本地文件data02.csv到HDFS的文件夹/dataset内;
hdfs dfs -copyFromLocal data02.csv /dataset 上传本地文件data02.csv到HDFS的文件夹/dataset内;
hdfs dfs -get /dataset/data02.csv data02_v2.csv 拷贝HDFS的/dataset/data02.csv到本地文件data02_v2.csv;
hdfs dfs -copyToLocal /dataset/data02.csv data02_v2.csv 拷贝HDFS的/dataset/data02.csv到本地文件data02_v2.csv;
hdfs dfs -cp /user/userinfo.txt /data/userinfo.txt 拷贝HDFS的数据文件/user/userinfo.txt到/data/userinfo.txt;
hdfs dfs -mv /user/userinfo.txt /data/userinfo.txt 移动HDFS的数据文件/user/userinfo.txt到/data/userinfo.txt;
hdfs dfs -text /itemsinfo.csv 以文本格式输出/itemsinfo.csv文件;
hdfs dfs -tail /itemsinfo.csv 以文本格式输出/itemsinfo.csv文件,但是只显示末尾1KB大小的数据。
编程要求
本关不需要编写 Java 代码,直接在命令行完成关卡。根据任务提示,启动 hadoop, 把数据文件上传到 HDFS 中。
- 使用
start-all.sh或start-dfs.sh启动 hadoop 或 hdfs; - 把
/data/workspace/···/dataset/user_behavior.csv文件拷贝到/root目录内(…里面的都是单文件夹,可以用tab建自动补全); - 在HDFS中创建一个新文件夹
/dataset; - 把
user_behavior.csv文件上传到刚创建的文件夹中; - 打印文件内容,以检测文件是否上传成功。(文件比较大,可使用
hdfs dfs -cat /yourpath | tail -10只显示末尾10行数据,减少输出量)
测试说明
平台会查看你刚上传的文件路径是否正确,并核对文件最后 10 行数据是否一致,如果一致则通过。
代码实现
//一行一步
start-all.sh
cp /data/workspace/myshixun/dataset/user_behavior.csv /root/
hdfs dfs -mkdir /dataset
hdfs dfs -put user_behavior.csv /dataset
第2关:利用Java API把电商数据上传到HDFS
任务描述
目的与第一关一致,部分任务描述可参考第一关。有时候,我们并不想直接用 HDFS 命令来上传输入,比如当上传的文件很多、文件名很长的时候,一次又一次的打 HDFS 命令很慢也可能会出错,这时候可以使用 Java API 的方式,HDFS Java API 是 HDFS 提供的可供 Java 程序调用的接口,类似 JDBC。本关卡将通过 Java 编程的方式来向 HDFS 上传数据文件。
本关任务:使用 HDFS Java API 命令把电商数据user_behavior.csv从本地上传到 HDFS 中。
相关知识
为了完成本关任务,你需要掌握:常用 HDFS Java接口的使用。
常用 HDFS Java接口的使用
1、获得 HDFS 的 FileSystem 实例,该实例是操作 HDFS 的主要入口;
Configuration configuration = new Configuration();
fileSystem fs = FileSystem.get(configuration);
2、FileSystem对象的常用方法
- 用法举例,使用FileSystem对象的mkdir(Path filePath)方法创建一个新 HDFS 文件目录代码如下:
// 创建新目录 "/newPath"
Path newPath = new Path("/newPath");
fs.mkdir(newPath);
- 其他方法用法相似,常用方法介绍:
void mkdir(Path filePath) 创建一个新目录;
boolean exists(Path filePath) 判断文件是否存在;
FSDataInputStream open(Path filePath) 读取文件;
boolean rename(Path oldPath, Path newPath) 重命名文件;
boolean delete(Path filePath, boolean isRecursion) 删除一个目录或文件,第二个参数如果为 true 则递归删除一个目录所有内容;
void copyFromLocalFile(Path src, Path dst) 把本地路径的文件拷贝到HDFS指定路径中;
void copyToLocalFile(Path src, Path dst) 把 HDFS 上的文件拷贝到 本地路径中。
编程要求
根据提示,在右侧编辑器补充代码,把本地数据文件上传到 HDFS 中。
1、所使用的本地数据文件路径为/root/user_behavior.csv;
2、上传至 HDFS 的目录路径为 /dataset。
测试说明
平台会对你编写的代码进行测试:
- 核对数据文件是否成功上传至HDFS;
- 且数据文件末尾10行数据是否符合预期。
代码实现
//什么都不需要输,“点测评”,但前提是第一关没有出现任何错误!!!
以上是关于educoder:实验十一 函数的主要内容,如果未能解决你的问题,请参考以下文章
头歌Educoder云计算与大数据——实验五 Java API分布式存储