Tardigrade:Trino 解决 ETL 场景的方案
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tardigrade:Trino 解决 ETL 场景的方案相关的知识,希望对你有一定的参考价值。
Presto 在 Facebook 的诞生最开始是为了填补当时 Facebook 内部实时查询和 ETL 处理之间的空白。Presto 的核心目标就是提供交互式查询,也就是我们常说的 Ad-Hoc Query,很多公司都使用它作为 OLAP 计算引擎。但是随着近年来业务场景越来越复杂,除了交互式查询场景,很多公司也需要批处理;但是 Presto 作为一个 MPP 计算引擎,将一个 MPP 体系结构的数据库来处理海量数据集的批处理是一个非常困难的问题,所以一种比较常见的做法是前端写一个适配器,对 SQL 进行预先处理,如果是一个即时查询就走 Presto,否则走 Spark。这么处理可以在一定程度解决我们的问题,但是两个计算引擎以及加上前面的一些 SQL 预处理大大加大我们系统的复杂度。
为了解决这个问题,PrestoDB 启动了 Presto Unlimited 以及 Presto on Spark 等项目用于解决这种问题,这些我们可以到 Presto on Spark:支持即时查询和批处理 和 Presto on Spark:通过 Spark 来扩展 Presto 文章中了解详情。今天我们要讲的是 Presto 的另外一个分支 Trino(PrestoSQL)ETL 之路。在过去的六个月时间里,Trino 社区一直在开发支持 ETL 的功能,其代号为 Tardigrade,也是通过修改 Trino 的代码来支持 ETL 的功能。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
什么是 Tardigrade 项目
大家喜欢使用 Trino 的地方在于它的查询速度很快,可以通过直观的错误消息、交互体验和联邦查询来解决业务问题。长期存在的一个大问题是,为长时间运行的 ETL 工作负载配置、调优和管理 Trino 是非常困难的。以下是你必须处理的一些问题:
•可靠的完成时间:运行数小时的查询可能会失败,从头开始重新启动它们会浪费资源,并使我们难以满足完成时间的要求。•具有成本效益的集群:我们需要 TB 级分布式内存的 Trino 集群来执行查询;•并发性:多个独立客户端可以并发提交查询。由于在某一时刻缺乏可用资源,其中一些查询可能需要终止并在一段时间后重新开始,这使得作业完成时间更加难以预测。
为了解决上面问题我们可能需要由专家团队来完成,但这对大多数用户来说是不可能的。Tardigrade 项目的目标是为上述问题提供一个“开箱即用”的解决方案。社区设计了一种新的容错执行架构(fault-tolerant execution architecture),它允许我们实现具有细粒度重试的高级资源感知调度(advanced resource-aware scheduling)。以下是 Tardigrade 项目带来的效果:
•当长时间运行的查询遇到故障时,我们不必从头开始再运行它们。•当查询需要的内存超过集群中当前可用的内存时,它们仍然能够运行成功;•当多个查询同时提交时,它们能够以公平的方式共享资源,并稳步运行。
Trino 在幕后完成所有分配、配置和维护查询处理的繁重工作。我们可以将时间花在分析和交付业务价值上,而不是花时间调优 Trino 集群以满足我们的工作负载需求,或者重新组织工作负载以满足我们 Trino 集群能力。
Tardigrade 项目原理简介
Trino 是一种无状态的计算引擎,所以为了实现 ETL,是需要对 Trino 进行很多修改的。在实现上,Trino 和 PrestoDB 有一些不一样,PrestoDB 为了同时支持 ETL 和即时查询,在初期是开发了代号为 Presto Unlimited 的项目,其主要是将表进行分桶,每个桶的数据是独立的,所以可以独立计算;如果单个桶的数据计算失败了,直接重试这个桶数据所涉及到的计算即可,关于这部分原理可以参见Presto on Spark:支持即时查询和批处理 和 Presto on Spark:通过 Spark 来扩展 Presto等文章。虽然 Presto Unlimited 解决了部分问题,但它并没有完全解决容错问题,也没有改善隔离和资源管理。要实现这些功能无疑需要对 Presto 进行很大的改造,而且这些工作在其他引擎(比如 Spark、Flink 等计算引擎都有)其实都有类似的实现,再在 Presto 上实现有点重复造轮子;所以 PrestoDB 社区引入了 Presto on Spark,Presto on Spark 是 Presto 和 Spark 之间的集成,它利用 Presto 的 compiler/evaluation 作为类库,并使用 Spark 的 RDD API 来管理 Presto embedded evaluation 的执行;这类似于 Google 选择将 F1 Query 嵌入其 MapReduce 框架的方式。
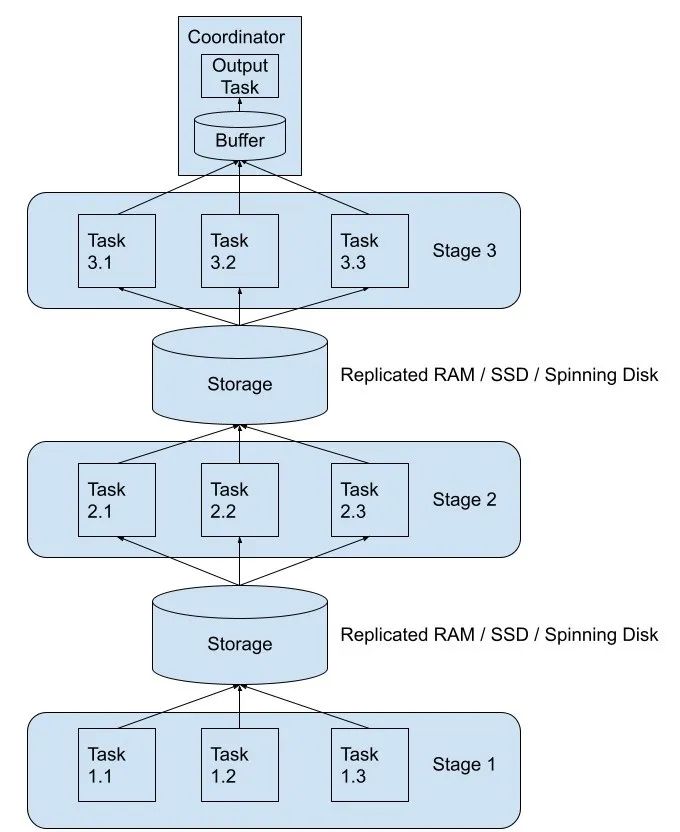
但是反过来看 Trino ,其实现思路和上面不太一样,Trino 的 Tardigrade 看起来是直接在 Trino 上实现了容错、查询/任务重试、shuffle 等核心功能。Trino 将上游 stage 的 shuffle 数据进行落盘,这个支持把数据写到 AWS A3、Google Cloud Storage、Azure Blob Storage 以及本地文件存储(这个是用于测试的),下游的 stage 从磁盘里面读取需要的数据。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
因为 stage 和 stage 之间交互的数据都落盘了,所以如果某个 task 挂了,我们直接再重启一个即可,这样就可以实现 Task 级别的重试。在实现将 Task 的数据落盘过程中,目前单个 Task 会生成 N 个文件(N代表下游 Stage 中的 Task 数)。熟悉 Spark 的同学肯定知道,这个问题在早期的 Spark 其实一样存在;不过 Trino 当前应该是早期开发阶段,用于快速实现容错机制,等整个框架都稳定运行了,在后期肯定是会对这个进行优化的。
关于这部分的内容我打算后面用一篇文章来详细介绍 Trino 社区的 Tardigrade 实现思路。
Trino 容错框架使用
Tardigrade 是从去年开始进行的,到目前为止已经进行了多次迭代。Trion 社区也对其进行了测试,主要是基于 TPCH,TPCDS 的数据集实现了100多个 ETL 作业,在 15 个 m5.8xlarge 型号的节点上对 10GB / 1TB / 10TB 规模的数据跑了上千次测试,在测试过程中通过随机关掉节点来模拟现实中节点挂了的情况。同时为了验证新的资源管理器的功能, Trion 社区跑了 22 条 TPCH 查询,在未开启容错执行时,只有2条SQL成功,其他的20条都是由于资源相关的问题而失败(比如 out of memory);而开启容错执行时,22条 SQL 均成功。
要开启容错机制,需要通过以下几个配置来实现:
给 Trino exchange manager 配置相关存储
Exchange spooling 负责存储和管理 Task 的输出数据,以便实现容错执行,这个需要配置一个基于文件系统的 exchange manager 来存储数据,当前实现中 Trino 支持 S3、GCS、Azure 对象存储以及本地磁盘作为写 shuffle 的存储。磁盘的配置需要到 Coordinator 和所有的 Worker 上的 etc 目录下创建一个名为 exchange-manager.properties 的文件,下面是使用 S3 作为存储的配置实例:
exchange-manager.name=filesystem
exchange.base-directories=s3://exchange-spooling-bucket
exchange.s3.region=us-west-1
exchange.s3.aws-access-key=example-access-key
exchange.s3.aws-secret-key=example-secret-key注意,exchange.base-directories 参数是可以配置多个目录的,比如:
exchange.base-directories=s3://exchange-spooling-bucket-1,s3://exchange-spooling-bucket-2启用 Task 级别的重试
这个需要到 config.properties 文件里面添加以下配置:
retry-policy=TASK
query.hash-partition-count=50当然,Trino 其实也支持 Query 级别的重试(retry-policy=QUERY),QUERY 级别的重试是不能配置 exchange manager 存储的,这个只有在集群的查询都是小查询时开启,其他情况建议使用 Task 级别的重试。
其他可选参数
将 shuffle 数据写到存储时推荐开启压缩(exchange.compression-enabled=true);将 query.low-memory-killer.delay 设置为 0来减少 low memory killer 延迟,防止阻塞其他小查询。此外,建议启用自动写入缩放功能,以优化用 Trino 创建的表的输出文件大小(scale-writer =true)。
最后,建议将长时间运行的 ETL 查询和短时间运行的交互式工作负载和用例分开,在不同的集群上运行。这可以确保长时间运行的 ETL 查询不会影响交互式工作负载并导致糟糕的用户体验。还要注意,由于检查点机制,容错集群上的任何短时间运行的交互式查询可能会遇到更高的延迟。
本文主要翻译自,Project Tardigrade delivers ETL at Trino speeds to early users:https://trino.io/blog/2022/05/05/tardigrade-launch.html
以上是关于Tardigrade:Trino 解决 ETL 场景的方案的主要内容,如果未能解决你的问题,请参考以下文章