linux 文本内容替换(awk/sed)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux 文本内容替换(awk/sed)相关的知识,希望对你有一定的参考价值。
麻烦高手们指导,提供替换的脚本和解释,谢谢!
1)原始文本内容如下,数据间逗号为分隔符,但存在问题是日期格式有问题,需要调整正确:(源文件的记录数10W条左右)
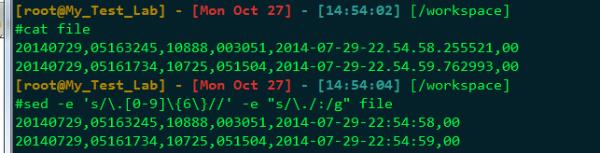
20140729,05163245,10888,003051,2014-07-29-22.54.58.255521,00
20140729,05161734,10725,051504,2014-07-29-22.54.59.762993,00
2)目的:希望将第5列的字段进行替换,每行数据的时间都是不一样的。
“2014-07-29-22.54.58.255521”由于输出有误,需要将数据调整为正确的日期格式,如:
“2014-07-29 22:54:58”
#删除字符'.'后跟着六位数字的字符串
#可以先手动测试一下,符合要求加个-i参数修改源文件。
use strict;
use warnings;
my $log_path="./aoyou.txt"; #修改你的日志路径
open LOG,"$log_path" or die "Can not open log file: $!";
foreach (<LOG>)
if ($_ =~ m!(.*\\,.*\\,.*\\,.*)\\,(\\d+\\-\\d+\\-\\d+)\\-(\\d+\\.\\d+\\.\\d+)\\.\\d+,(.*)!)
print "$1,$2 $3,$4 \\n";
close LOG 参考技术B
假设你的文件叫做filename,敲
sed 's/\\([0-9]\\4\\-[0-9][0-9]-[0-9][0-9]\\)-\\([0-9][0-9]\\).\\([0-9][0-9]\\).\\([0-9][0-9]\\).\\([0-9]\\6\\\\)/\\1 \\2:\\3:\\4/g' filename > output新的结果就会存在outpu文件里了
20140729,05163245,10888,003051,2014-07-29 22:54:58,00
20140729,05161734,10725,051504,2014-07-29 22:54:59,00
这是用你的数据得到的样板答案
追问您好,按照您的方法执行,能解决大部分的问题了,但输出结果如下“2014-07-29 22:54:58.255521”,秒后加上小数点还有7位需要截掉,能帮忙补充完成吗,谢谢!
追答不知道你为什么会有那样的问题哎,我测试的时候明明好好的,已经把尾巴截掉了
那你再试试这个吧
sed 's/\\([0-9]\\4\\-[0-9][0-9]-[0-9][0-9]\\)-\\([0-9][0-9]\\).\\([0-9][0-9]\\).\\([0-9][0-9]\\).\\([0-9]*\\)/\\1 \\2:\\3:\\4/g' filename > output本回答被提问者采纳 参考技术C [root@localhost shell]# gawk -f script file1.txt20140729,05163245,10888,003051,2014-07-29-22.54.58,00
20140729,05161734,10725,051504,2014-07-29-22.54.59,00
file1.txt里存得是你给的数据,script里内容如下:
[root@localhost shell]# cat script
BEGIN
FS="."
print $1 "." $2 "." $3 ",00"
linux学习:sed与awk与tr用法整理
流编辑器:sed
sed ‘s/pattern/replace_string/‘ file #从给定文本中的字符串利用正则表达式进行匹配并替换每一行中第一次符合样式的内容
sed ‘s/text/replace/‘ file > newfile #替换每一行中第一次符合样式的内容并将替换结果重定向到新文件
sed -i ‘s/test/replace/‘ file #参数-i使用替换每一行中第一次符合样式的内容结果应用于源文件
sed ‘s/pattern/replace_string/g‘ file #后缀/g意味着会替换每一处匹配,而不是每一行中第一次匹配
sed ‘s:test:rep;ace:g‘ #使用:替换/,这两个符号都是定界符,用其他符号也无所谓,但是当定界符在匹配的样式内部时,需要加\进行转义
sed ‘expression; expression‘ #组合多个表达式
sed ‘/^$/d‘ file #移除空白行,^$表示空白行,/d表示将匹配的样式移除
echo thisthisthisthis | sed ‘s/this/THIS/2g‘ #后缀/2g表示从第2处开始(包括第二次)开始匹配。第N处,就使用/Ng。结果:thisTHISTHISTHIS
cat file | sed ‘s/pattern/replace_string/‘ file #从stdin中读取输入并替换每一行中第一次符合样式的内容
echo this is an example | sed ‘s/\w\+/[&]/g‘ #符号&表示已匹配的字符串。正则表达式\w\+匹配每一个单词,并用[&]替换它,结果:[this] [is] [an] [example]
echo this is digit 7 in a number | sed ‘/digit \([0-9]\)/\l/‘ #参数\1(数字1)将digit 7转换为7
---------------------------------------------------------------
text=hello
echo hello world | sed "s/$text/Hello/" #输出结果HELLO world
---------------------------------------------------------------
文本混乱与恢复正常(替换空格,换行符,制表符等)
cat test.js | sed ‘s/;/;\n/g; s/{/{\n\n/g; s/}/\n\n}/g‘ # s/;/;\n/g将;替换为\n; s/{/{\n\n/g将{替换为{\n\n s/}/\n\n/g将}替换为\n\n}
cat test.js | sed ‘s/;/;\n/g‘ |sed ‘s/{/{\n\n/g‘ | sed ‘s/}/\n\n}/g‘ #同上
sed ‘s/ [^.]*mobbile phones[^.]*\.//g‘ test.txt #移除文件test.txt中包含单词“mobile phones”的句子
数据流工具:awk
工作方式:awk ‘BEGIN{ PRINT "start" } pattern { commands } END{print "END" } file
首先执行BEGIN语句块,然后从文件或stdin中读取一行,然后执行pattern{ commands }。直到文件全部读取完毕。读到输入流末尾时,执行END{ commands } 语句块。三个语句块都是可选的。如果没有提供pattern语句块则默认打印每一个读取到行。
awk的特殊变量:
NR:表示记录数量,在执行过程中对应于当前行号。
NF:表示字段数量,在执行过程中相对于当前行的字段数。
$NF:表示当前行的最后一个字段。$(NF-1)表示当前行的倒数第二个字段。依次类推
$0:这个变量包含执行过程中当前行的文本内容。
$1:这个变量包含第一个字段的文本内容。
$2:这个变量包含第二个字段的文本内容。依次类推。
awk ‘BEGIN { i=0 } { i++ } END{ print i }‘ filename #逐行读取文件并打印行数
echo -e "line1\nline2" | awk ‘BEGIN{ print "Start" } { print } END { print "END" } ‘
echo | awk ‘{ var1="v1"; var2="v2"; var3="v3"; print var1"-"var2"-"var3;}‘
echo -e "line1 f2 f3\nline2 f4 f5\nline3 f6 f7" | awk ‘{ print "Line no:"NR",No of fields:"NF, "$0="$0,"$1="$1,"$2="$2,"$3="$3 }‘
awk ‘{ print $3,$2 }‘ file #打印文件中每一行的第2和第3个字段。
awk ‘END{ print NR }‘ file #统计文件中的行数,只加END语句块表示文件执行到最后一行时再输出行号
awk ‘NR < 5‘ file #打印文件中行号小于5的行
awk ‘NR==2,NR==5‘ file #打印文件中行号在2到5之间的行
awk ‘/linux/‘ file #打印文件中包含样式linux的行(样式可以使用正则表达式)
awk ‘1/linux/‘ file #打印文件中不包含包含样式linux的行
awk -F: ‘{ print $NF }‘ /etc/passwd #读取并打印/etc/passwd文件的内容,设置定界符为":",默认的定界符为空格
var1=‘test‘; var2=‘text‘ #(1)外部变量
echo | awk ‘{ print v1,v2 } v1=$var1 v2=var2 #(2)打印多个从标准输入传给awk的外部变量
awk ‘{ print v1,v2 }‘ v1=$var1 v2=var2 filename #(3)输入来自文件
cat test.txt | getline output #将cat的输出读入变量output中。
awk ‘BEGIN { FS=":" } { print $NF }‘ /etc/passwd #BEGIN语句块中则使用FS="delimiter"设置输出字段的定界符
awk ‘{arr[$1]+=1 }END{for(i in arr){print arr[i]"\t"i}}‘ FILE_NAME | sort -rn #统计每个单词的出现频率并排序
seq 5 | awk ‘BEGIN{ sum=0;print "Summation:" } { print $1"+"; sum+=$1 } END{ print "=="; print sum }‘ #将每一行第一个字段的值按照给定形式进行累加
echo | awk ‘{ "grep root /etc/passwd" | getline cmdout; print cmdout }‘ #通过getline将外部shell命令的输出读入变量cmdout。变量cmdout包括命令grep root /etc/passwdde 的输出,然后打印包含root的行。
awk中使用循环与awk的内建函数
for(i=0;i<10;i++){ print $i; } 或者 for( i in array ) { print array[i]; }
length(string):返回字符串的长度
index(string ,search_string):返回search_string在字符串中出现的位置。
split(string, array, delimiter):用界定符生成一个字符串列表,并将该列表存入数组
substr(string, start-position, end-position):在字符串中用字符起止偏移量生成子串,并返回该子串。
sub(regex, replacement_str, string):将正则表达式匹配到的第一处内容替换成replacement_str。
gsub(regex, replacement_str, string):将正则表达式匹配到的所有内容替换成replacement_str。
match(regex ,string):检查正则表达式是不能够匹配字符串,若能,返回非0值;否则,返回0.
替换工具:tr
echo 12345 | tr ‘0-9‘ ‘9876543210‘ #加密
echo 87654 | tr ‘9876543210‘ ‘0-9‘ #解密
echo "Hello 123 world 456" | tr -d ‘0-9‘ #使用-d将stdin中的数字删除并打印出来
cat test.txt | tr -d ‘0-9‘ #同上
echo "hello 1 char 2 next 3 " | tr -d -c ‘0-9 \n‘ #参数-c是使用补集。删除stdin中的所有数字和换行符之外的字符(这些字符是‘0-9 \n‘这个集合的补集)
echo "this is a test !" | tr -s ‘ ‘ #参数-s压缩多个空格为单个
------------------------------------------------
tr可以像使用集合一样使用各种不同的字符类:
alnum:字母和数字
alpha:字母
cntrl:控制(非打印)字符
digit:数字
graph:图形字符
lower:小写字母
print:可打印字符
punct:标点符号
space;空白字符
upper:大写字母
xdigit:十六进制字符
使用方式:
tr [:class:] [:class:]
例如:
tr ‘[:lower:]‘ ‘[:upper:]‘ #将所有小写字母换成大写字母
----------------------------------------------------
以上是关于linux 文本内容替换(awk/sed)的主要内容,如果未能解决你的问题,请参考以下文章
如何根据来自不同命令的多行打印输出的输入将文本文件内容替换为“sed”或“awk”?