关于SVM的基本问题(过学习,欠学习,推广性,学习精度)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于SVM的基本问题(过学习,欠学习,推广性,学习精度)相关的知识,希望对你有一定的参考价值。
何谓 “过学习”,和“欠学习”?发生这些现象的原因?
何谓分类器的”推广性”,和“学习精度”?学习精度高的分类器一定有好的推广性吗?为什么?
在1963年提出的一种新的非常有潜力的分类技术, SVM是一种基于统计学习理论的模式识别方法,主要应用于模式识别领域.由于当时这些研究尚不十分完善,在解决模式识别问题中往往趋于保守,且数学上比较艰涩,因此这些研究一直没有得到充的重视.直到90年代,一个较完善的理论体系—统计学习理论 ( StatisticalLearningTheory,简称SLT) 的实现和由于神经网络等较新兴的机器学习方法的研究遇到一些重要的困难,比如如何确定网络结构的问题、过学习与欠学习问题、局部极小点问题等,使得SVM迅速发展和完善,在解决小样本、非线性及高维模式识别问题中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中.从此迅速的发展起来,现在已经在许多领域(生物信息学,文本和手写识别等)都取得了成功的应用。
SVM的关键在于核函数,这也是最喜人的地方。低维空间向量集通常难于划分,解决的方法是将它们映射到高维空间。但这个办法带来的困难就是计算复杂度的增加,而核函数正好巧妙地解决了这个问题。也就是说,只要选用适当的核函数,我们就可以得到高维空间的分类函数。在SVM理论中,采用不同的核函数将导致不同的SVM算法
它是一种以统计学理论为基础的,以结构风险最小化的学习机学习方法,要优于神经网络学习。
参考资料:http://hi.baidu.com/changpengfeng/blog/item/7115e6c8bcf647167e3e6f35.html 参考技术A 机器学习问题中.从此迅速的发展起来,现在已经在许多领域(生物信息学,文本和手写识别等)都取得了成功的应用。 参考技术B http://hi.baidu.com/changpengfeng/blog/item/7115e6c8bcf647167e3e6f35.html 参考技术C http://info.cqvip.com/qk/91690X/20064232/23216221.html 参考技术D 运气好,今天我恰好上网,搞SVM的人少得可怜
机器学习100天(二十三):023 欠拟合与过拟合
机器学习100天,今天讲的是欠拟合与过拟合!
《机器学习100天》完整目录:目录
一、过拟合与欠拟合
机器学习中,我们构建一个模型,通常可能会遇到欠拟合或者过拟合的问题。以这张图为例,面对同样一批数据,我们建立了 3 个不同的回归模型。左边这张图是简单的一次线性模型,中间这张图是二次多项式模型,右边这张图是复杂的高阶多项式模型。
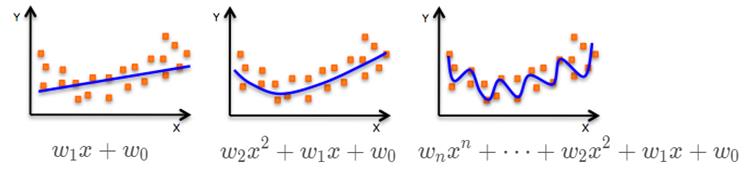
直观上可以看到,左边的线性模型对数据拟合的效果一般,这种情况称之为欠拟合。什么是欠拟合呢?欠拟合就是是指模型不能在训练集上获得足够低的误差。换句换说,就是模型复杂度低,没法学习到数据背后的规律。
再来看右边的高阶多项式模型,它对数据拟合的非常好,好的有点过了,这种情况称之为过拟合。什么是过拟合呢?过拟合是指训练误差和测试误差之间的差距太大。换句换说,就是模型复杂度高于实际问题,模型在训练集上表现很好,但在测试集上却表现很差,即泛化能力差。
中间的二次多项式模型虽然在训练集上有些误差,但是却反应了数据分布的整体趋势,可以说是最好最合适的模型。
二、为什么发生过拟合
知道了欠拟合和过拟合的概念之后,我们来看为什么会发生欠拟合和过拟合。欠拟合主要是由于模型过于简单,选取的特
以上是关于关于SVM的基本问题(过学习,欠学习,推广性,学习精度)的主要内容,如果未能解决你的问题,请参考以下文章