Hadoop学习之hadoop安装JDK安装集群启动(完全分布式)
Posted Apathfinder
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop学习之hadoop安装JDK安装集群启动(完全分布式)相关的知识,希望对你有一定的参考价值。
作者简介:大家好我是Apathfinder,目前是一名在校大学生,软件工程专业,记录学习路上的点点滴滴。
个人主页:Apathfinder本文专栏:Hadoop学习
前言 :本文主要是对hadoop完全分布式环境安装过程中的hadoop安装以及JDK安装作详细的介绍,以及集群启动。
目录
正文
一.整体部署情况
| hadoop01 | hadoop02 | hadoop03 | |
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
以下操作在hadoop01节点上做(主节点),而后同步hadoop02,hadoop03
二.JDK安装
1.下载JDK
大家可以到官网选择相应版本下载
我的安装版本如下图所示:

2.上传JDK
在这里我用了mobaxterm来远程登录hadoop01,然后将Windows上下好的JDK压缩包以及hadoop压缩包上传
上传成功后则能登录hadoop01查看,如图
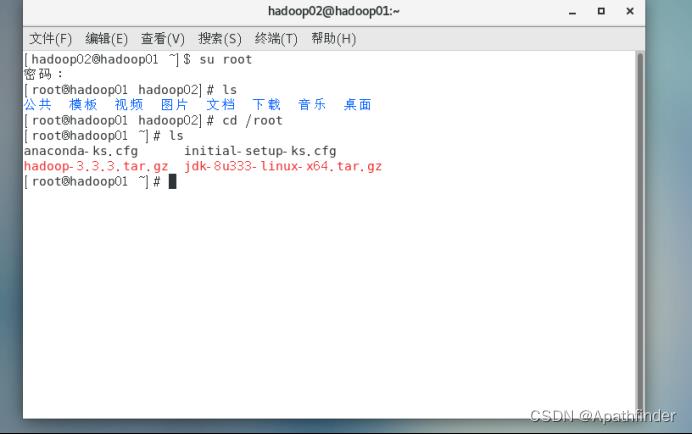
3.安装JDK
1.解压
在上传了之后,咱们就进行安装,使用解压命令解压到指定目录
tar -zxvf jdk-8u333-linux-x64.tar.gz -C /usr/local/ 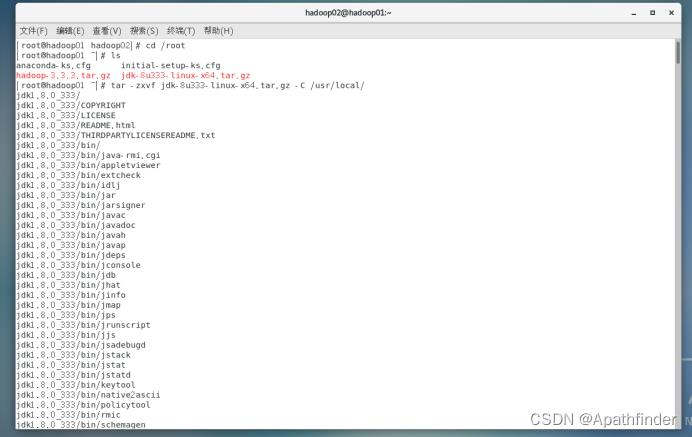
2.添加环境变量
使用命令
vi /etc/profile/ 打开文件,然后进行编辑,加入以下内容
export JAVA_HOME=/usr/local/jdk1.8.0_333
export PATH=$JAVA_HOME/bin:$PATH然后使用以下命令立即生效
source /etc/profile 3.验证安装
输入
java -version验证是否安装成功,成功则如下图

三.Hadoop安装
1.下载hadoop
大家可以到官网选择相应版本下载
我在这里下载的是hadoop3.3.3版本
2.上传hadoop
这里我在上传JDK的同时与hadoop一起上传了,具体操作可以看JDK部分
3.安装hadoop
1.解压
解压命令改个名称就行
tar -zxvf hadoop-3.3.3.tar.gz -C /usr/local/2.添加环境变量
与JDK操作相同,这里我就不过多叙述了,添加以下内容:
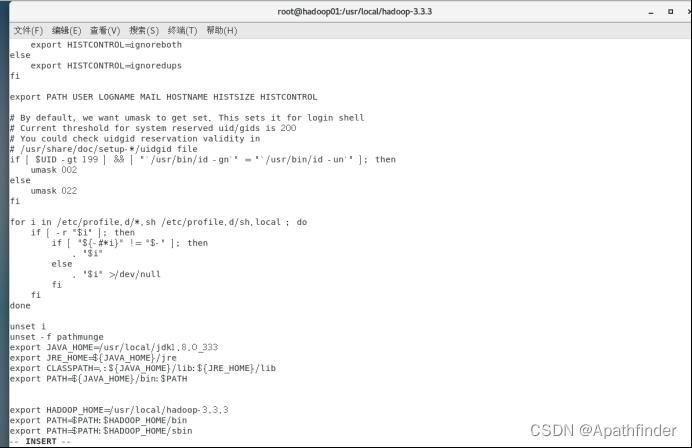
export HADOOP_HOME=/usr/local/hadoop-3.3.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin如下图底部:
3.修改配置文件
先切换到hadoop目录
cd /usr/local/hadoop-3.3.3/etc/hadoop然后进行下列配置文件的修改,用编辑命令即可
1.hadoop-env.sh
以下命令编辑
vi hadoop-env.sh加入
export JAVA_HOME=/usr/local/jdk1.8.0_333
2.yarn-env.sh
同上
3.mapred-env.sh
同上
4.core-site.xml
#在 <configuration></configuration> 之间加入 <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop-3.3.3/tmp</value> </property>
5.hdfs-site.xml
<property> <name>dfs.replication</name> <value>2</value> </property> <!-- 指定Hadoop辅助名称节点主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop03:50090</value> </property>
6.yarn-site.xml
<property> <name>yarn.resourcemanager.hostname</name> <value>hadoop02</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
7.mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
8.workers
vi workers加入以下内容
hadoop01 hadoop02 hadoop03
4.验证安装
在终端输入hadoop后,出现如图所示则成功,即命令使用提示

四.集群启动
1.传送文件
将hadoop01上的JDK,hadoop所在目录传到hadoop02,hadoop03节点上,命令如下
scp -r /usr/local/ root@hadoop02:/usr/
scp -r /usr/local/ root@hadoop03:/usr/
#同步环境配置文件
rsync -rvl /etc/profile root@hadoop02:/etc/profile
rsync -rvl /etc/profile root@hadoop03:/etc/profile 
然后与之前步骤一样验证hadoop02,03机上是否成功安装
2.格式化namenode节点
先切换到指定目录下
cd /usr/local/hadoop-3.3.3然后格式化
hadoop namenode -format #格式化NameNode3.集群的启动
为了偷懒,我使用start-all.sh来启动集群 ,每次在web访问完后,stop-all.sh关闭集群,下次启动集群访问,就不再需要格式化namenode。
启动集群之后,可以使用jps来查看是否每个节点都成功启动相应的服务。如下图:

4.web端访问
为了访问方便,你可以在C:\\Windows\\System32\\drivers\\etc\\hosts文件下做映射,加上IP与主机名,
hadoop3.x.x版本端口50070改为了9870
1.访问9870端口(即50070)
在浏览器输入hadoop01:9870


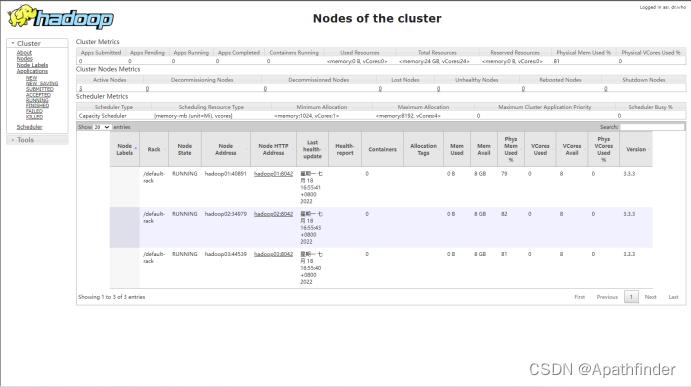
2.访问8088端口
在浏览器输入hadoop02:8088
写在最后
今天的文章就到这里,如果你觉得写的不错,可以动动小手给博主一个免费的关注和点赞👍;如果你觉得存在问题的话,欢迎在下方评论区指出和讨论。
谢谢观看,你的支持就是我前进的动力!
以上是关于Hadoop学习之hadoop安装JDK安装集群启动(完全分布式)的主要内容,如果未能解决你的问题,请参考以下文章