Unity基础学习之C#学习
Posted qingtian_111
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Unity基础学习之C#学习相关的知识,希望对你有一定的参考价值。
C#基础语法部分
1. 开发环境搭建
1.1 Visual Studio
- 下载路径
- 可下载2016版本以上的
1.2 Unity
1.3 MSDN
- MSDN工具站网址
- msdn library技术文档路径
- 这是一个Microsoft当前提供的有关编程信息的最全面的资源网站
2. 进制
在进制中,比较重要的两个是二进制和十进制,二进制是机器理解的数据,十进制是人常用理解的数据。
2.1 进制概念
- 进制概念:人为定义带进位计数方法
- 二进制:逢二进一,0和1
- 十进制:逢十进一,0~9
- 八进制:逢八进一,0~7
- 十六进制:逢十六进一,0-9和A-F
- 计算机为什么能理解二进制:数据以电信号传输(高电频和低电频)
- 计算机如何理解数字和文字:数字转换成二进制,文字用编码转换再转换成二进制
2.2 进制转换
- 二进制转十进制

1字节=8比特,因此二进制写法以八位起步,即1字节可以存储255(1111 1111)大小的数 - 八进制转十进制

- 十六进制转十进制

A8B6 = 6 ∗ 1 6 0 + 11 ∗ 1 6 1 + 8 ∗ 1 6 2 + 10 ∗ 1 6 3 6*16^0+11*16^1+8*16^2+10*16^3 6∗160+11∗161+8∗162+10∗163 - X进制转十进制

- 十进制转二进制

- 八进制转二进制

- 十六进制转二进制

3. 原码、反码、补码
- 原码、反码和补码都是针对二进制计算的。
- 1字节中的8位并不一定都是用来存储数据的,还会用来存储符号,比如正负数
3.1 正负数三码的计算方式


- 在有符号数据中,0的二进制表示有两个,即+0(0 000 0000)和-0(1 000 0000)。
- -0转换成补码后会变成0000 0000,这是因为在反码+1后,补码长度变成了9位,而存储空间只有8位,舍去了最高位。

3.2 使用三码的原因
- 计算机底层只能做加法运算,减法运算是通过将第二个数转换成负数后再进行加法运算来实现的
- 使用三码主要是为了精确计算机底层进行加法运算后得出的结果
- 用原码来进行含有负数的加法运算,会导致得出的结果偏差很大

4. C#开发语言介绍
- 计算机只能读取二进制,因此创造除了编程语言,用编程语言实现程序后,将代码编译成二进制,方便计算机读取
- C#开发语言特点:面向对象,简单
- 继承C和C++强大功能,去除C和C++的复杂特性(C面向过程,指针复杂;C++中有很多手动操作,例如手动操作内存等)
- 使用任何一门编程语言,都需要基于框架
- C#语言使用.NET Framework和.NET Core开源框架
- 写代码要注意代码阅读性和维护性
4.1 用VS创建一个项目
- 创建项目过程如下:

- 如何在解决方案中新建项目:

- 一个解决方案中可创建多个项目,但只可以运行一个项目
- 可运行的项目会被标粗
- 切换运行项目:设置需要运行的项目为启动项目
- 设置启动项目操作:右键项目–>设置为启动项目
- 如何在项目中创建.cs文件:
- 右键项目–>添加–>新文件–>找类文件
4.2 第一个C#文件
- 写C#程序:
using System; //引用了一个命名空间(又叫库)
namespace aCSharpBase //声明命名空间
class MainClass //声明一个类
//Main函数是程序的入口
public static void Main(string[] args)
//在控制台上打印一句话
Console.WriteLine("Hello World!");
- 编译当前程序:
- C#程序程序员可以看懂,但机器不能看懂;然而执行程序的是机器
- 将C#程序编译(翻译)成机器可以看懂的语言,即二进制后,程序可以被执行
- 运行当前程序 :
- 获取执行结果
4.3 注释

- 注释不会被编译,也不会被执行
- 注释作用:
- 解释说明当前代码含义(在开发程序时,每段代码都要写注释)
- 暂时取消某些代码的执行
- 多行注释放于文件前部,说明文件创建人以及修改人等信息,起到软件开发认责作用
- Windows下VS的注释快捷键:
- 注释:Ctrl+K+C
- 取消注释:Ctrl+K+U
- 对于区域性划分注释,可以使用标签
region- 快捷键:输入#re后,按两下tab键
5. 数据类型
- 机器含有的东西:CPU、内存条、硬盘、显存/显卡…
- 程序执行前,先将已知的数据存储到机器中(硬盘、内存、CPU缓存)
- 数据类型:存储不同类型数据的容器
- 开辟数据存储内存(根据设置的数据类型),用完数据后,返还内存
- 值类型和引用类型的区别在于:
- 进行数据存储时,值类型变量直接保存变量的值
- 引用类型的变量保存的是数据的引用类型,引用类型的变量也叫对象
- 进行数据操作时,对于值类型,由于每个变量有自己的值,因此对一个变量的操作不会影响其他变量
- 对于引用类型的变量,对一个变量的数据进行操作就是对这个变量在堆中的数据进行操作,因此对一个变量的操作就会影响到引用同一个对象的另一个变量
- 判断数据类型是值类型还是引用类型方法:
- 用两个变量进行数据操作,一个变量进行赋初值,另一个变量赋前一个变量
- 改变其中一个变量值,查看另一个变量值是否被影响而产生变化
- 另一个变量不变化,说明数据类型是值类型
- 另一个变量值和改变的变量值仍然保持一致,说明数据类型是引用类型
- 数据的量级:
- 1024字节(byte) = 1KB
- 1024KB = 1MB
- 1024MB = 1GB
- 1024GB = 1TB
- 1024TB = 1PB
5.1 值类型
- 值类型源于System.ValueType家族
- 每个值类型的对象都有一个独立的内存区域用于保存自己的值
- 值类型数据所在的内存区域称为栈
- 值类型主要包括整型、浮点型、字符型、布尔型、枚举型等
- 对值类型,不同的变量会分配不同的存储空间,并且存储空间中存储的是该变量的值
5.1.1 基本数据类型
- 下面两张表罗列了13个基础数据类型:


- 不同数据类型可以存储的数据大小不一样,在选择数据类型时,要注意其取值范围,选择最适宜的数据类型
- short是Int16结构的别称,int是Int32结构的别称,long是Int64结构的别称




5.1.2 枚举类型(自定义数据类型)
- 枚举类型的定义:

- 不可在方法内定义枚举类型
- 枚举类型的使用:
- 自定义一个枚举类,相当于自己创建一个数据类型
- 与声明基本数据类型的变量一样,声明枚举类型变量
- 可以为枚举类型变量赋自定义中的枚举值

- 使用枚举类型,可以加强代码的可读性以及维护性
- 想要列举的值,都可以直接添加到定义好的枚举类型中
- 在Unity中使用枚举类型,可以产生下拉菜单
- 枚举类型可以强制转换成整型;0可以隐式转换成枚举类型,其余整型要强制转换成枚举类型
- 可以对枚举类型变量进行加减运算
5.1.3 结构类型(自定义数据类型)
- 结构体类型的定义如下:

- 不可在方法内定义结构体类型
- 结构体类型的使用:

- 对于给结构体中变量进行初始化,可以使用构造函数实现:

- 在结构体的构造函数中,空构造函数是冗余的,要自定义构造函数,函数必须含参
- 构造函数创建好后,在给结构体变量开辟内存空间时,就可以利用构造函数进行变量初始化
- eg:Student xiaoming = new Student(“”,“”,…);
5.2 引用类型
- 引用类型源于System.Object家族
- 引用类型数据所在的内存区域称为堆
- 在C#中引用类型主要包括数组、类、接口、委托、字符串等
- 对引用类型,赋值是把原对象的引用传递给另一个引用
- 对数组而言,当数组引用赋值给另一个数组引用后,这两个引用指向同一个数组,也就是指向同一块存储空间
5.3 指针类型(仅用于非安全代码)
- 指针类型变量存储另一种类型的内存地址
- 声明指针类型的语法如下:
- type * identifier;
- eg:char* cptr;
6. 常量和变量
- 对于浮点型数据,无论常量还是变量都要注意,数字是小数时:
- float类型的数据后面要加f
- eg:float money = 100.35f;
- double类型的数据后面要加d,可以不加(因为一般小数默认为double类型)
- eg:double damage = 1.223d;
- decimal类型的数据后面要加m
- eg:decimal number = 1.3m;
- float类型的数据后面要加f
- 浮点型数字是整数,数字后可以不加后缀
- eg:float score = 90;
- 对于字符类型,赋值,一定要用单引号括起来
- eg:char sex = ‘M’;
6.1 常量
- 什么是常量:

- 常量声明:
- const 数据类型 变量名 = 初值;
- 必须要赋初值,后面不可再修改
6.2 变量
- 什么是变量:

- 变量定义(声明):
- 变量可以不赋初值,但在特殊情况下必须要赋初值
- 不赋初值,则当前变量的值是默认值
- int/float默认值是0
- char默认值是’\\0’(表示空字符)

- 变量可以不赋初值,但在特殊情况下必须要赋初值
- 有两个变量相加,先对分配好的变量内存空间进行命名(声明变量),根据变量名来获取存储的数据,最后进行变量运算

6.3 常量与变量之间的区别
- 程序运行期间表示的是:
- 程序开始到程序结束
- 常量和变量之间的区别:
- 在程序运行期间,能否被改变
- 常量只有在写定义的时候,可以改变值,后续不可再被赋值
- 变量在定义时可以给初值,后续仍然可以被赋值
6.4 常量及变量命名规则和规范
- 命名规则如下图所示前三条:(其中,要注意的是,中文变量名语法上是可行的,但不推荐使用)

- 命名规范
- 命名用英文单词,不要使用拼音
- 驼峰命名法
- 大驼峰:每个单词首字母大写,其余字母小写
- eg:MyHeroDamage,HeroAttack
- 方法名、类名、接口名要使用大驼峰
- 小驼峰:第一个单词首字母不大写,后面每个单词首字母大写,其余字母小写
- eg:myHeroDamage,heroAttack
- 变量用小驼峰
- 大驼峰:每个单词首字母大写,其余字母小写
- 见名知意:看到变量名,能够知道它是用来存储什么东西的
7. 运算符、表达式及语句
7.1 运算符
- 数据存储完成后,要对数据进行处理,这就要用到运算符了




- 注意:
- 赋值运算符是一个等号,表示的是一个运算
- 算术运算符中,+、-、*、/、%是二元运算符;++、- -是一元运算符
- 自增、自减符号位置不同,会产生不同结果
- age++:整体结果保持原值,age变量结果增1;先赋值后自增
- ++age:整体结果增1,age变量结果增1;先自增后赋值
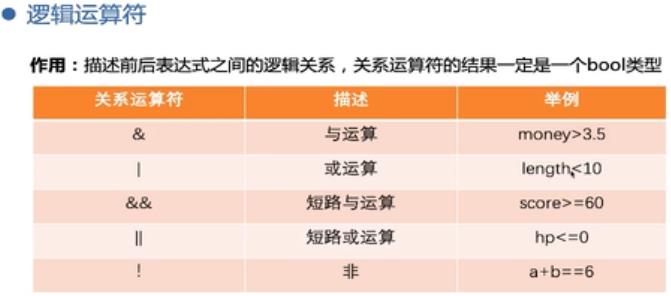
- 逻辑运算是两个bool型数据之间的运算
- &(与运算):一假则假
- |(或运算):一真则真
- !(非运算):相反
- &运算和&&短路与运算之间的区别:
- &运算——无论第一个条件是真是假,都会继续判断第二个条件
- &&短路与运算——若判断第一个条件已经是假,则不会继续判断第二个条件
- |运算和||短路与运算之间的区别:
- |运算——无论第一个条件是真是假,都会继续判断第二个条件
- ||短路与运算——若判断第一个条件已经是真,则不会继续判断第二个条件
- 短路&&和短路||:
- 优点:
- 第一个条件已经得知整个逻辑运算的结果后(&&的第一个条件为假/||的第一个条件为真),不会去判断第二个条件
- 节约运算量
- 缺点:
- 当判断中带有运算时,若不进行第二个条件判断,则第二个条件中的运算不会被执行
- 优点:
- 条件运算符是一个三目运算符
- 在进行两个数值运算过程中,若想要保留小数位数,有两种方法:
- ToString(“0.根据要保留的小数位数写0”),这种方法最后得到的是字符串结果
- eg:保留两位——ToString(“0.00”)
- Math.Round(数字,保留几位),这是一种数学计算公式
- eg:保留两位——Math.Round(数字,2)
- ToString(“0.根据要保留的小数位数写0”),这种方法最后得到的是字符串结果
7.2 表达式
- 表达式可以不以分号为结尾,其组成部分是常变量与运算符

7.3 语句
- 一个分号隔开一个语句

8. 输入与输出
- 用户与程序之间的交互,主要通过输入实现
- 用户输入数据,经过程序对数据的处理后,返回一个输出给用户
- 输入需要用到设备,一般的输入设备是鼠标与键盘,当然还有手柄、触屏(虚拟摇杆)等输入设备
- 下面介绍C#中的输出函数与输入函数:

9. 数据类型转换
- 数据类型之间的转换,根据不同情况,分为隐式转换和强制转换
- 当小容器中的数据要存储到大容器中,则系统自动采用隐式转换
- 当大容器中的数据要存储到小容器中,则在程序编写时要加修饰(强制转换修饰符)来达成强制转换
9.1 隐式转换

- 数据类型之间由小到大排序
- b o o l < c h a r < i n t < f l o a t < s t r i n g bool<char<int<float<string bool<char<int<float<string
- 所有整型之间的排序: s b y t e ( 1 字 节 ) < s h o r t ( 2 字 节 ) < i n t ( 4 字 节 ) < l o n g ( 8 字 节 ) sbyte(1字节)<short(2字节)<int(4字节)<long(8字节) sbyte(1字节)<short(2字节)<int(4字节)<long(8字节)
- 隐式转换只发生在将占用字节小的、取值范围小的、精度小的,转换成占用字节大的、取值范围大的、精度高的
- 系统自动转换
- 不需要其它修饰
- 赋值运算符左侧为占用字节大的、取值范围大的、精度高的,右侧为占用字节小的、取值范围小的、精度低的
- eg:float score = 32; ——>int型转换成float型
- 字符型数据会自动根据编码表,转换成整型数据
- eg:输入字符’a’,得到结果97
9.2 强制(显式)转换

- 强制转换发生在将占用字节大的、取值范围大的、精度高的,转换成占用字节小的、取值范围小的、精度小的
- 需要强制转换修饰符
- 会有精度缺失,甚至会出现数据错误(这是因为数据在计算机底层是以二进制形式存储,存储空间变小会舍去超出存储空间部分的高位数据,最终导致数据错误)
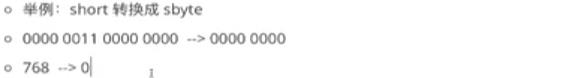
- 一般在两个不同类型的数值之间使用强制转换时要注意,需要转换的数值是处于小的数据类型取值范围内
- 浮点型数据强制转换成整型数据,会导致小数点后面的内容被舍去
- 数值转换成其他数据类型
- 对于字符,在存储时,一般会先将字符用编码表转换成数值后,以二进制数据进行存储
- int型数据转换成char型数据——根据编码表得到字符
- eg:int data = 97;
char change = (char) data;
- eg:int data = 97;
- int型数据无法转换成bool型数据
- 字符串(string)与其他类型之间的转换
- 其他类型转换成字符串:
- 其他类型数据加上双引号后,就变成了字符串数据类型
- eg:“false”,“10”,“3.14”,“A”
- 其他类型的变量.ToString()
- eg:int data = 97;
string str_data = data.ToString();
- eg:int data = 97;
- 其他类型数据加上双引号后,就变成了字符串数据类型
- 字符串转换成其他类型:
- 转换方法:
- 使用System.Convert类下相对应的方法,即:
- System.Convert.ToBoolean()
- System.Convert.ToInt32()
- System.Convert.ToSingle()
- System.Convert.ToDouble()
- System.Convert.ToChar()
- System.Convert.ToBoolean()
- 使用数据类型.Parse()方法,即:
- bool.Parse()
- int.Parse()
- float.Parse()
- double.Parse()
- char.Parse()
- 使用System.Convert类下相对应的方法,即:
- 字符串转换成bool型
- eg:string str = “false”;
bool bl = Convert.ToBoolean(str); - eg:bool bl2 = bool.Parse(str);
- eg:string str = “false”;
- 字符串转换成int型
- eg:string str = “312”;
int it = Convert.ToInt32(str); - eg:int it2 = int.Parse(str);
- eg:string str = “312”;
- 字符串转换成float型
- eg:string str = “3.1415”;
float fl = Convert.ToSingle(str); - eg:float fl2 = float.Parse(str);
- eg:string str = “3.1415”;
- 字符串转换成double型
- eg:string str = “3.1456415”;
double dl = Convert.ToDouble(str); - eg:double dl2 = double.Parse(str);
- eg:string str = “3.1456415”;
- 转换方法:
- 其他类型转换成字符串:
10. 访问修饰符
- 什么是访问修饰符(用于限制程序员):

- 代码位置层级划分:

- 常用修饰符:

11. 总结
- 数据类型:选择存储容器,不同类型可以存储的数据大小不一样
- 常量与变量:数据存储区域命名后,可根据名称来获取存储的数据
- 运算符:数据处理需要用到的符号
- 表达式:相当于一个计算公式,由常变量和运算符组成
- 语句:一个程序由多条语句构成,是计算机执行的最小单位;一个表达式加一个分号就可以形成一条语句
- 输入与输出:主要针对的是用户与机器的交互
- 数据类型转换:在处理数据过程中,会遇到数据类型不匹配情况,通过转换,可以使得等式两侧数据类型一致
- 在写代码的时候,一个方法内容有很多,为了能更好的阅读代码,可以用标签
#region [段名]...#endregion来划分代码区域 - 设定访问修饰符,可以提高代码的安全性,写一段代码,一定要设置好其访问修饰符
C#基础学习之继承
继承是在类之间建立一种相交的关系,使得新定义的派生类的实例可以继承已有的基类的特征并且还可以添加新的功能。以前对继承的理解仅仅限于定义,下面是我查了些资料、写了点代码的总结。
1.C#继承的特点
(1) 派生类是对基类的扩展,派生类可以添加新的成员,但不能移除已经继承的成员的定义。
(2)继承是可以传递的。如果C从B中派生,B又从A中派生,那么C不仅继承了B中声明的成员,同样也继承了A中声明的成员。
(3)构造函数和析构函数不能被继承,除此之外其他成员能被继承。基类中成员的访问方式只能决定派生类能否访问它们。
(4)派生类如果定义了与继承而来的成员同名的新成员,那么就可以覆盖已继承的成员,但这兵不是删除了这些成员,只是不能再访问这些成员。
(5)类可以定义虚方法、虚属性及虚索引指示器,它的派生类能够重载这些成员,从而使类可以展示出多态性。
(6)派生类只能从一个类中继承,可以通过接口来实现多重继承。
2.一个简单的基础实现
//从运行结果可以看到很重要的一点,继承时先执行父类构造函数, //接着再执行子类构造函数,最后再执行方法 class Program { static void Main(string[] args) { Man man = new Man(); man.Eat(); //在派生类中访问基类中的成员一般有2种方式,一是调用base.<成员> 调用基类的方法,二是显示类型转换为父类 ((People)man).Eat(); } } public class People { public People() { Console.WriteLine("父类的构造函数"); } public void Eat() { Console.WriteLine("父类吃饭"); } } class Man:People { public Man() { Console.WriteLine("子类构造函数"); } public void WhoEat() { base.Eat(); } }
3.隐藏基类成员
//当派生类需要覆盖基类的方法时,C#使用new修饰符来实现隐藏基类成员 class Program { static void Main(string[] args) { Man man = new Man(); man.Eat(); } } public class People { public People() { Console.WriteLine("父类的构造函数"); } public void Eat() { Console.WriteLine("我是父类"); } } class Man:People { public Man() { Console.WriteLine("子类构造函数"); } public new void Eat() { Console.WriteLine("我是子类"); } }
4.抽象类、密封类、抽象方法和虚方法
首先还有一种类需要注意,那就是密封类。如果我们对类不作任何约束,也就是说所有类都可以被继承,这种继承的滥用会导致类的层次结构十分庞大,类与类之间的关系会变得很乱导致无法理解。因此C#提供了密封类,我们只需在父类前加上sealed修饰符,那这个类将不能被继承了。密封方法也是在方法前加上sealed修饰符。
抽象类和密封类刚好相反,它是为继承而生的。抽象类不能实例化,抽象方法没有具体执行代码,必须在非抽象的派生类中重写。也就是基类并不实现任何执行代码,只是进行定义。这一点和接口有相同的地方。
class Program { static void Main(string[] args) { Man man = new Man(); man.Eat(); man.Say(); } } public abstract class People { //注意:如果类中有抽象方法,则类必须声明为抽象类。 public People() { Console.WriteLine("父类的构造函数"); } public abstract void Eat(); //有时候不想把类声明为抽象类,但又想实现方法在基类里不具体实现, //而是想实现方法由派生类重写。遇到这种情况时可使用virtual关键字将方法声明为虚方法 public virtual void Say() { //注意虚方法必须声明方法主体,抽象方法则不需要 Console.WriteLine("我是父类的虚方法"); } } class Man:People { public Man() { Console.WriteLine("子类构造函数"); } public override void Eat() { Console.WriteLine("我是子类"); } public override void Say() { Console.WriteLine("我是子类的Say方法"); } }
5.有参数的构造函数
class Program { static void Main(string[] args) { Man man = new Man("构造函数"); //结果仍然是先输出父类构造函数,然后再输出子类构造函数 } } public class People { public People(string s) { Console.WriteLine("父类"+s); } } class Man:People { //在继承时,如果基类构造函数是有参数的,子类构造函数也必须有一个有参数的构造函数,否则会报错 public Man(string s):base(s) { Console.WriteLine("子类构造函数"); } }
以上是关于Unity基础学习之C#学习的主要内容,如果未能解决你的问题,请参考以下文章