MySQL_select distinct无法实现只对单列去重,并显示多列结果的解决方法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL_select distinct无法实现只对单列去重,并显示多列结果的解决方法相关的知识,希望对你有一定的参考价值。
参考技术A 可以看到表中的value字段有重复,如果想筛选去重,使用select distinct语句如下:得到结果会是
| value
| a
| b
| c
| e
| f
筛选去重是实现了,可是只有选中的value列显示了出来,如果我想知道对应的id呢?
尝试一下把id字段加入sql语句,如下:
得到结果:
| value | id
| a | 1
| b | 2
| c | 3
| c | 4
| e | 5
| f | 5
更换一下sql语句中id和value的顺序,如下:
得到结果:
| id |value
| 1 | a
| 2 | b
| 3 | c
| 4 | c
| 5 | e
| 5 | f
好像看明白它的作用结果了,只有id和value两个字段同时重复时,select distinct语句才会把它列入“去重”清单
所以能看到id为3和4的value虽然都是4,但由于select语句中写了id字段,它也默认会对id字段起效。
而且如果sql语句中把DISTINCT放到只想起效的字段前,那也是不行的....比如sql语句改为:
会提示sql报错。
那到底怎么样能得到我想要的只对value字段内容去重,显示结果又能保留其他字段内容呢....
找到的解决方法是使用group by函数,sql语句如下:
得到结果:
| min(id) |value
| 1 | a
| 2 | b
| 3 | c
| 5 | e
| 5 | f
完成目标了✔!
如果把sql语句中的min()换成max()呢?
得到结果:
| min(id) |value
| 1 | a
| 2 | b
| 4 | c
| 5 | e
| 5 | f
也完成目标了✔!
同时比对两次sql运行结果可以发现,
第一次使用min(id)时,由于重复结果存在两条而id最小的为为3,符合min(id)的筛选条件,所以结果中把id等于4的重复记录删除了。
第二次使用max(id)时结果中,也就把id等于3的重复记录删除了
可以推论到假如还存在一条id=5,value=c的记录,使用max(id)时得到的结果里就会是>5 c这条了。
再来尝试一下,如果min()和max()用在value字段里呢:
得到结果:
| id |min(value)
| 1 | a
| 2 | b
| 3 | c
| 4 | c
| 5 | e
得到结果:
| id |min(value)
| 1 | a
| 2 | b
| 3 | c
| 4 | c
| 5 | f
再仔细想想,这种需求也只出现在不是那么care显示结果中,非去重目标字段的内容时才能使用,如果需要指定这些字段的值,可能筛选条件就不是min()和max()那么简单了....
以上。
HIVE-----count(distinct ) over() 无法使用解决办法
HIVE-----count(distinct ) over() 无法使用解决办法
在使用hive时发现count(distinct ) over() 报错
hive> with da as (
> select 1 a, ‘a‘ b union all
> select 1 a, ‘a‘ b union all
> select 2 a, ‘a‘ b union all
> select 2 a, ‘a‘ b union all
> select 2 a, ‘a‘ b union all
> select 3 a, ‘b‘ b union all
> select 3 a, ‘b‘ b union all
> select 3 a, ‘b‘ b union all
> select 3 a, ‘b‘ b union all
> select 3 a, ‘b‘ b union all
> select 3 a, ‘b‘ b union all
> select 3 a, ‘b‘ b
> )
> select
> a
> ,b
> ,sum(a) over(partition by b)
> , count(distinct a) over(partition by b)
> from da;
FAILED: SemanticException Failed to breakup Windowing invocations into Groups. At least 1 group must only depend on input columns. Also check for circular dependencies.
Underlying error: org.apache.hadoop.hive.ql.parse.SemanticException: Line 18:26 Expression not in GROUP BY key ‘b‘
经过测试将
with da as ( select 1 a, ‘a‘ b union all select 1 a, ‘a‘ b union all select 2 a, ‘a‘ b union all select 2 a, ‘a‘ b union all select 2 a, ‘a‘ b union all select 3 a, ‘b‘ b union all select 3 a, ‘b‘ b union all select 3 a, ‘b‘ b union all select 3 a, ‘b‘ b union all select 3 a, ‘b‘ b union all select 3 a, ‘b‘ b union all select 3 a, ‘b‘ b ) select count(distinct a) over(partition by b) from da
当且仅当至于count(distinct ) over()一个时段时能够使用,原因可能时内部实现distinct出错 不知道是否和版本有关 使用版本为Hive version 1.1.0

解决办法:如下使用collect_set(a) over(partition by b)函数将合并成一个分好组的集合 然后求出集合的值个数
因为collect_set()不能放入重复函数所以使用size()求集合元素数量时能达到count(distinct )的效果
with da as ( select 1 a, ‘a‘ b union all select 1 a, ‘a‘ b union all select 2 a, ‘a‘ b union all select 2 a, ‘a‘ b union all select 2 a, ‘a‘ b union all select 3 a, ‘b‘ b union all select 3 a, ‘b‘ b union all select 3 a, ‘b‘ b union all select 3 a, ‘b‘ b union all select 3 a, ‘b‘ b union all select 3 a, ‘b‘ b union all select 3 a, ‘b‘ b ) select a ,b ,sum(a) over(partition by b) ,size(collect_set(a) over(partition by b)) from da
结果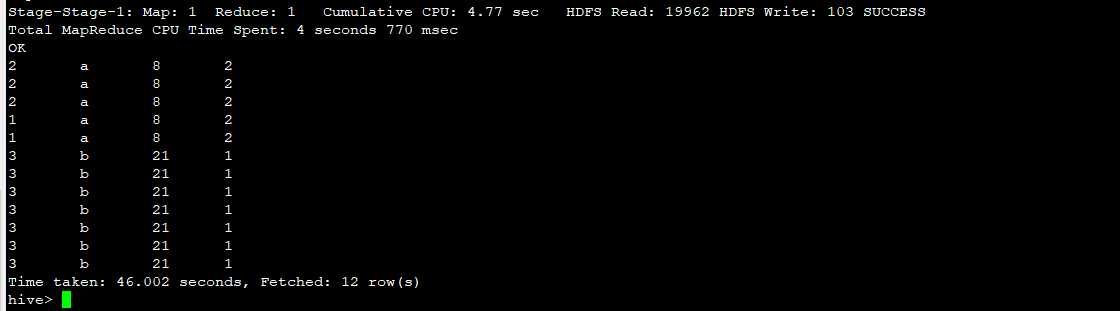
以上是关于MySQL_select distinct无法实现只对单列去重,并显示多列结果的解决方法的主要内容,如果未能解决你的问题,请参考以下文章