五分钟打造自己的sql性能分析工具
Posted 草长莺飞飞满天
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了五分钟打造自己的sql性能分析工具相关的知识,希望对你有一定的参考价值。
五分钟打造自己的sql性能分析工具
1.首先要有一个trace文件
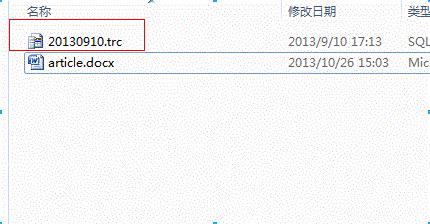
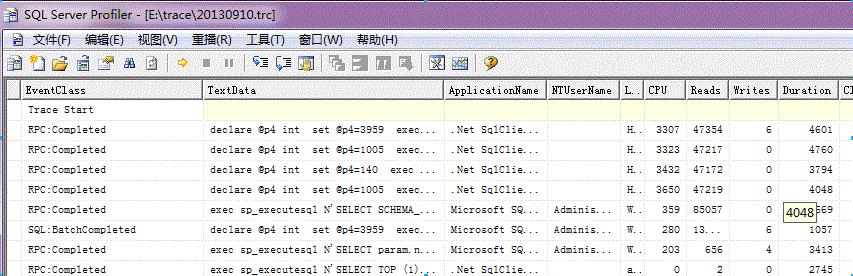
2. 打开trace文件
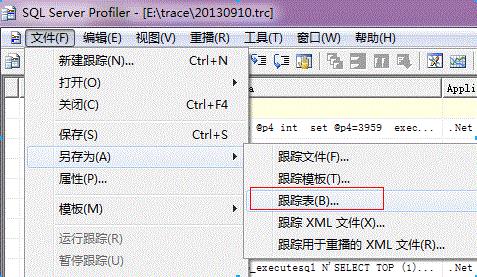
3. 另存为跟踪表
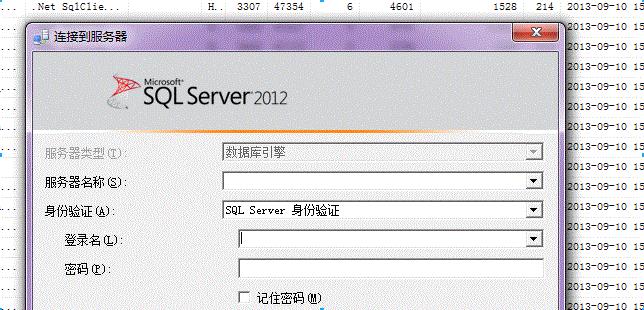
4.登录你要保存到的目标sqlserver服务器
5. 选择要保存的数据库和表名称
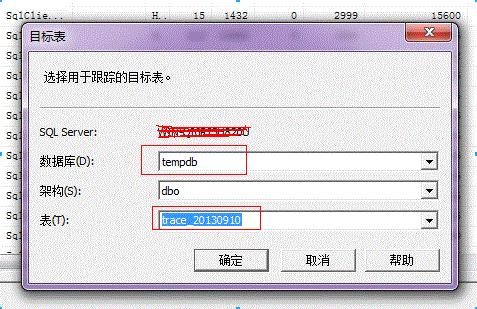
6. 保存完成(左下角出现进度直到显示“已完成”)
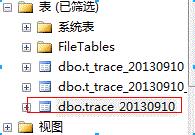
7. 在数据库中找到该表(在第5步选择的数据库中找)
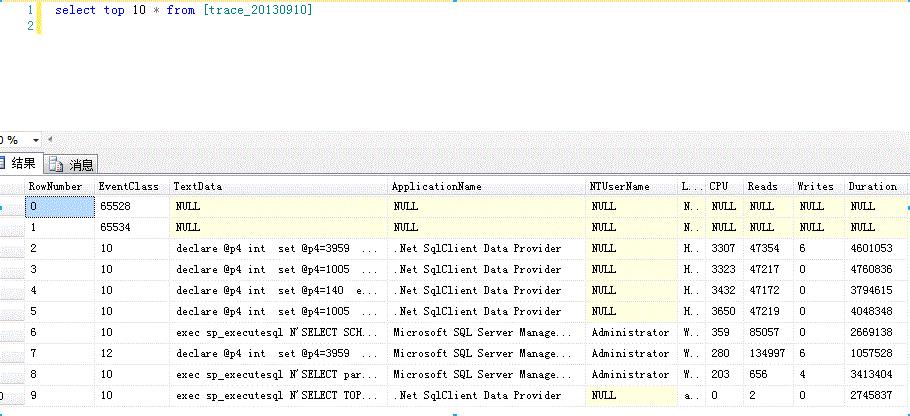
8.查看部分结果(TextData就是查询的sql语句,Duration就是查询的时间,这里duration除以1000才是毫秒)
9. 然后我们来分析TextData,如何找到相同的语句,不同的参数。我的分析,TextData主要有3种
1)带参数sql语句(以 exec sp_executesql N 打头,以 ,N 结尾可以找出对应的sql语句),如下图
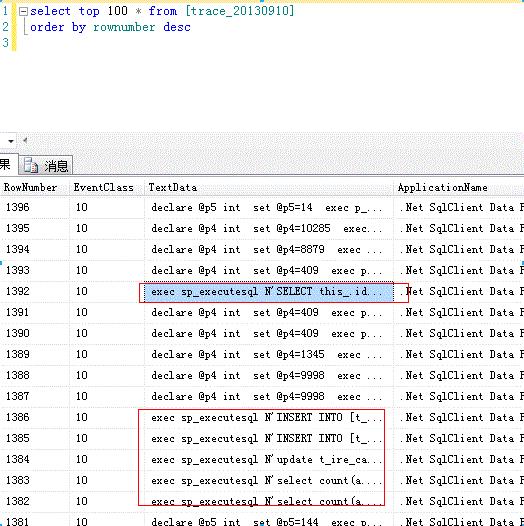
2)存储过程(类似 exec porc_user_insert @username, exec 和 @ 之间为存储过程名),如下图
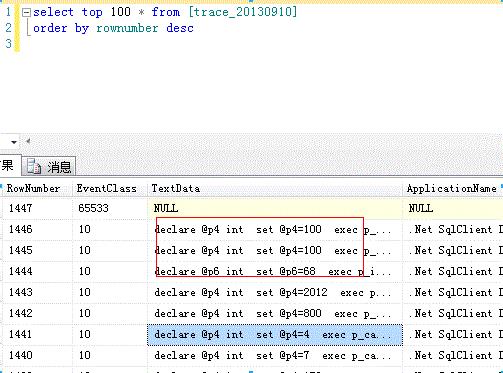
3)不带参数的sql语句
10. 对trace表的数据进行处理前的一些准备:
1)update trace_20130910 set duration = duration / 1000 where duration is not null -- 时间改为毫秒
2)修改 textdata 为 nvarchar(max)类型,因为textdata默认保存为ntext类型,处理不方便
alter table trace_20130910 alter column textdata nvarchar(max)
3)新增两个字段
alter table [trace_20130910] add proc_sql nvarchar(max) -- 保存该textdata调用的存储过程,原始sql等;
alter table [trace_20130910] add proc_sql_id int -- 为存储过程和原始sql指定一个编号
11. 处理trace数据
1)找出执行的sql脚本(带参数) ,更新到 proc_sql 字段
update [trace_20130910]
set proc_sql = replace(left(textdata,charindex(,N,textdata) - 1),exec sp_executesql N,)
where (proc_sql is null or proc_sql = )
and charindex(exec sp_executesql N, textdata ) = 1
2)找出执行的存储过程,更新到 proc_sql 字段
update [trace_20130910]
set proc_sql =
replace(
replace(
left(
right(textdata,len(textdata) - charindex(exec ,textdata) + 3),
charindex(@,
right(textdata,len(textdata) - charindex(exec ,textdata) + 3)
)
),exec ,)
,@,)
where (proc_sql is null or proc_sql = )
and charindex(exec ,textdata) > 0
3)找出没有参数的sql脚本,更新到 proc_sql 字段
update [trace_20130910] set proc_sql = textdata where proc_sql is null and textdata is not null
12. 统计
1)新建表,用于保存统计数据,trace_20130910每个proc_sql对应一行
create table [trace_20130910_stat]
(
id int identity(1,1) primary key,
databaseid int,
proc_sql nvarchar(max), -- 对应trace_20130910的proc_sql
total_duration bigint, -- 总耗时
max_duration int, -- 该语句最大耗时
min_duration int, -- 该语句最小耗时
rate_duration int -- 所耗时间百分比
)
2)生成统计数据,存入1)步的表中 trace_20130910_stat]
;with cte
(
databaseid,
proc_sql,
total_duration,
max_duration ,
min_duration
) as
(
select databaseid,
proc_sql,
sum(duration) as total_duration,
max(duration) as max_duration,
min(duration) as min_duration
from [trace_20130910]
where proc_sql is not null and proc_sql <>
group by databaseid,proc_sql
)
, cte2 as
(
-- 总耗时,用来计算百分比
select sum(total_duration) as total_duration from cte
)
insert into [trace_20130910_stat]
(
databaseid,
proc_sql,
total_duration,
max_duration ,
min_duration ,
rate_duration
)
select
databaseid,
proc_sql,
total_duration,
max_duration ,
min_duration ,
100 * total_duration / ( select total_duration from cte2 ) as rate_duration
from cte
order by rate_duration desc
3)更新记录表[trace_20130910]的 proc_sql_id
update [trace_20130910] set proc_sql_id = b.id
from [trace_20130910] a inner join [trace_20130910_stat] b
on a.databaseid = b.databaseid and a.proc_sql = b.proc_sql
13. 查询统计结果
1)查出最耗时的语句或过程
select * from [trace_20130910_stat] order by total_duration desc
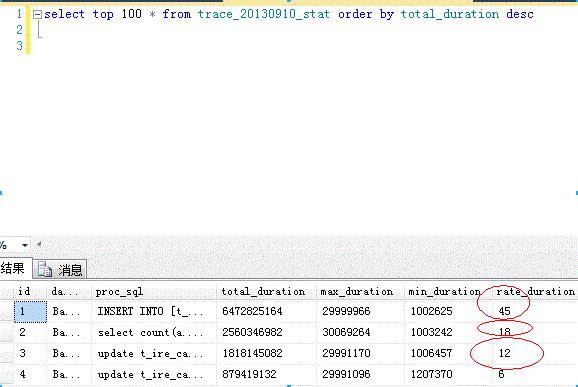
2)查询某个过程或者sql语句详情
select * from [trace_20130910] where proc_sql_id = 1
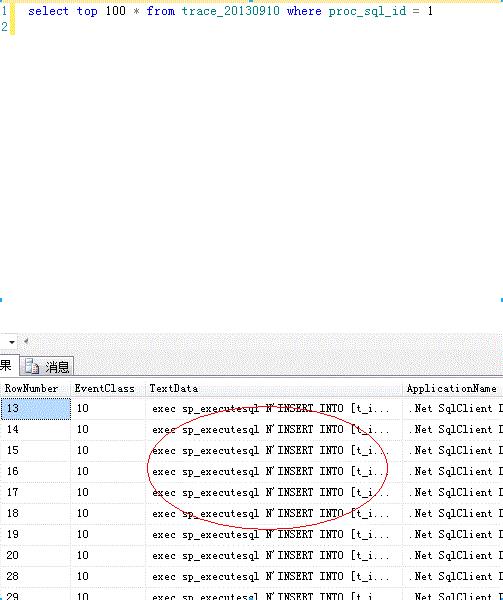
这是根据duration排序,稍微改下就可以按reads排序,因为步骤毕竟多,而且经常会用到,所以整理成一个存储过程。方便以后分析性能问题。
找了半天发现不能上传附件。
分类: sqlserver, 高性能数据库

鸽子飞扬
« 上一篇: sqlserver常用调优脚本(转)
» 下一篇: 镜像配置见证机失败解决方案
1.首先要有一个trace文件
2. 打开trace文件
3. 另存为跟踪表
4.登录你要保存到的目标sqlserver服务器
5. 选择要保存的数据库和表名称
6. 保存完成(左下角出现进度直到显示“已完成”)
7. 在数据库中找到该表(在第5步选择的数据库中找)
8.查看部分结果(TextData就是查询的sql语句,Duration就是查询的时间,这里duration除以1000才是毫秒)
9. 然后我们来分析TextData,如何找到相同的语句,不同的参数。我的分析,TextData主要有3种
1)带参数sql语句(以 exec sp_executesql N 打头,以 ,N 结尾可以找出对应的sql语句),如下图
2)存储过程(类似 exec porc_user_insert @username, exec 和 @ 之间为存储过程名),如下图
3)不带参数的sql语句
10. 对trace表的数据进行处理前的一些准备:
1)update trace_20130910 set duration = duration / 1000 where duration is not null -- 时间改为毫秒
2)修改 textdata 为 nvarchar(max)类型,因为textdata默认保存为ntext类型,处理不方便
alter table trace_20130910 alter column textdata nvarchar(max)
3)新增两个字段
alter table [trace_20130910] add proc_sql nvarchar(max) -- 保存该textdata调用的存储过程,原始sql等;
alter table [trace_20130910] add proc_sql_id int -- 为存储过程和原始sql指定一个编号
11. 处理trace数据
1)找出执行的sql脚本(带参数) ,更新到 proc_sql 字段
update [trace_20130910]
set proc_sql = replace(left(textdata,charindex(,N,textdata) - 1),exec sp_executesql N,)
where (proc_sql is null or proc_sql = )
and charindex(exec sp_executesql N, textdata ) = 1
2)找出执行的存储过程,更新到 proc_sql 字段
update [trace_20130910]
set proc_sql =
replace(
replace(
left(
right(textdata,len(textdata) - charindex(exec ,textdata) + 3),
charindex(@,
right(textdata,len(textdata) - charindex(exec ,textdata) + 3)
)
),exec ,)
,@,)
where (proc_sql is null or proc_sql = )
and charindex(exec ,textdata) > 0
3)找出没有参数的sql脚本,更新到 proc_sql 字段
update [trace_20130910] set proc_sql = textdata where proc_sql is null and textdata is not null
12. 统计
1)新建表,用于保存统计数据,trace_20130910每个proc_sql对应一行
create table [trace_20130910_stat]
(
id int identity(1,1) primary key,
databaseid int,
proc_sql nvarchar(max), -- 对应trace_20130910的proc_sql
total_duration bigint, -- 总耗时
max_duration int, -- 该语句最大耗时
min_duration int, -- 该语句最小耗时
rate_duration int -- 所耗时间百分比
)
2)生成统计数据,存入1)步的表中 trace_20130910_stat]
;with cte
(
databaseid,
proc_sql,
total_duration,
max_duration ,
min_duration
) as
(
select databaseid,
proc_sql,
sum(duration) as total_duration,
max(duration) as max_duration,
min(duration) as min_duration
from [trace_20130910]
where proc_sql is not null and proc_sql <>
group by databaseid,proc_sql
)
, cte2 as
(
-- 总耗时,用来计算百分比
select sum(total_duration) as total_duration from cte
)
insert into [trace_20130910_stat]
(
databaseid,
proc_sql,
total_duration,
max_duration ,
min_duration ,
rate_duration
)
select
databaseid,
proc_sql,
total_duration,
max_duration ,
min_duration ,
100 * total_duration / ( select total_duration from cte2 ) as rate_duration
from cte
order by rate_duration desc
3)更新记录表[trace_20130910]的 proc_sql_id
update [trace_20130910] set proc_sql_id = b.id
from [trace_20130910] a inner join [trace_20130910_stat] b
on a.databaseid = b.databaseid and a.proc_sql = b.proc_sql
13. 查询统计结果
1)查出最耗时的语句或过程
select * from [trace_20130910_stat] order by total_duration desc
2)查询某个过程或者sql语句详情
select * from [trace_20130910] where proc_sql_id = 1
这是根据duration排序,稍微改下就可以按reads排序,因为步骤毕竟多,而且经常会用到,所以整理成一个存储过程。方便以后分析性能问题。
找了半天发现不能上传附件。
以上是关于五分钟打造自己的sql性能分析工具的主要内容,如果未能解决你的问题,请参考以下文章
五分钟看懂微信团队打造的新 Sketch 插件 WeSketch
NLP | 打造一个‘OpenAI智能’机器人,只需要五分钟