《GAMES104-现代游戏引擎:从入门到实践》-05 学习笔记
Posted 发呆3
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《GAMES104-现代游戏引擎:从入门到实践》-05 学习笔记相关的知识,希望对你有一定的参考价值。
目录
渲染计算的三大组成部分
- 光照
- 材质
- 着色

渲染方程及挑战
渲染方程式
1986年,元老级人物James Kajiya提出了渲染方程式,这一方程可抽象概括所有的渲染计算。

渲染方程式表明:经过任意点x反射到观察点中的辐射通量由x点自身发光和其他点反射到x点的辐射通量组成,其中其他点反射到x点的光照又可分为直接光照和间接光照。

渲染方程在实际运用中非常复杂,包含诸多影响因素。
具体分析可参考大佬的文章:王江荣:路径追踪(Path Tracing)与渲染方程(Render Equation)
挑战一
阴影(Shadow)是我们判断物体空间关系的重要条件,我们该如何模拟出真实的阴影呢?
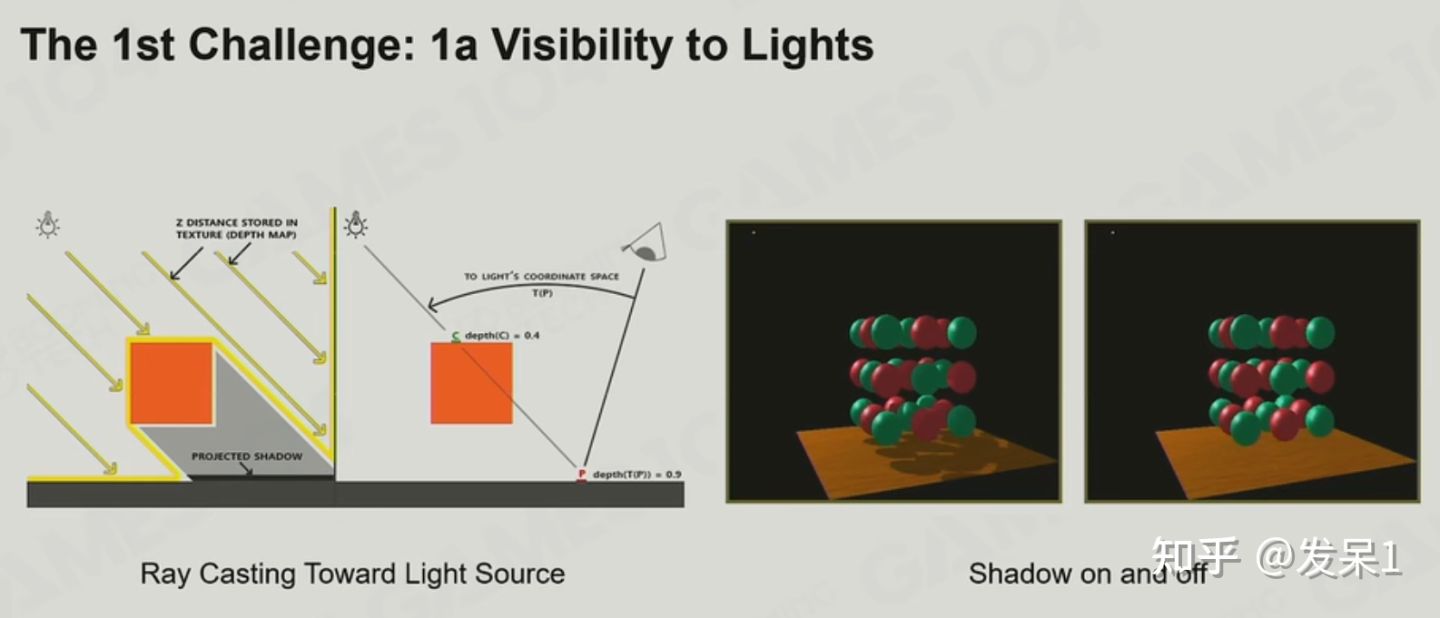
光源的复杂性,光源有点光源、方向光源、面光源等不同种类,在实际应用中光照强度也有所不同。

radiance指光照射到物体上反射出的能量;而irradiance则指入射的能量。
挑战二
如何高效的对双向反分布函数(BRDF,Bidirectional Reflectance Distribution Function)和入射辐射率的乘积进行积分,这里可以使用Monte Carlo积分(在上面大佬的文章中也有具体分析)。

挑战三
因为光可以反射,所以全局范围内任何一个物体都可以作为光源,即一束Output的光下一次可能作为Input输入,这样形成了一个递归的过程,典型案例Cornell Box。

总结一下三个挑战
- 对于任一给定方向如何获得irradiance
- 对于光源和表面shading的积分运算
- 对于入射光和反射光不断递归过程的计算

简易光照解决方案
光源的简化
我们使用方向光源、点光源、锥形光源等作为Main Light,取Ambient Light作为除主光外的环境光的均值,以此简化复杂的计算。

对于能够反射环境的材质,我们可以设计一种环境贴图,通过采样环境数据来表现

材质的简化
基于一个光照可以线性叠加的假设(在渲染方程式中也有用到),Blinn-Phong模型通过叠加Ambient(环境)、Diffuse(漫反射)、和Specular(高光)来简单粗暴的描述材质的着色计算

当然,Blinn-Phong模型也有缺陷。
能量不保守,使用Blinn-Phong模型的出射光照能量可能大于入射光照的能量,这在计算光线追踪时会带来很大的问题:这一过程在光线追踪中经过无限次反弹后,会使得本该暗的地方变得过于明亮。
难以表现真实的质感,Blinn-Phong模型虽然比较经典,但它却很难表现出物体在真实世界中的模样,总是有一种”塑料“感。

阴影的简化
Shadow简单说来就是人眼可见区域中,光线无法照到的地方。在过去十几年中,对于Shadow最常见的处理方式便是Shadow Map
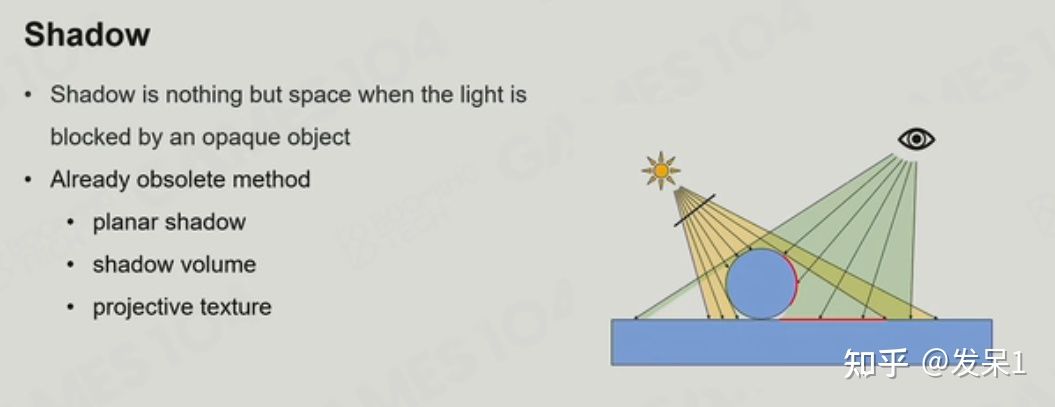
Shadow Map的思想可以简单概括为:第一次先在光源处放置相机,以z-buffer的方式储存一张对应的深度缓冲,第二次将相机放置在观察的位置,并将视锥内的点的深度和深度缓冲中的对应点(三维坐标转换为二维坐标后,在平面坐标系中对应的点)的深度进行对比,若前者大于后者,则认为视锥中的点处于阴影中
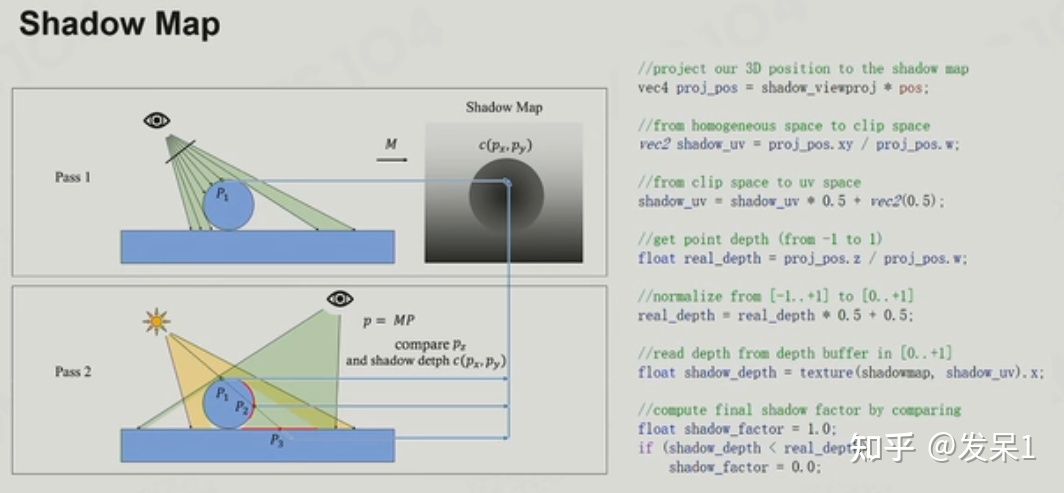
Shadow Map在使用时也会出现问题,光源处的采样率和观察处的采样率不一样,会出现走样,最经典的就是处理精细结构时的自遮挡问题

到这里我们就实现了对于三个挑战的一个简易光照解决方案

基于预计算的全局光照
只用直接光照会使得场景的平面感很强,而使用全局光照(直接光照+间接光照)能很大程度上的还原真实情况

如何表现全局光照
- 我们需要储存数以万计的光照探测器,因此我们需要一个很好的压缩比率
- 材质的BRDF卷积运算涉及到复杂的多项式积分运算,我们需要利用数学方法简化积分运算

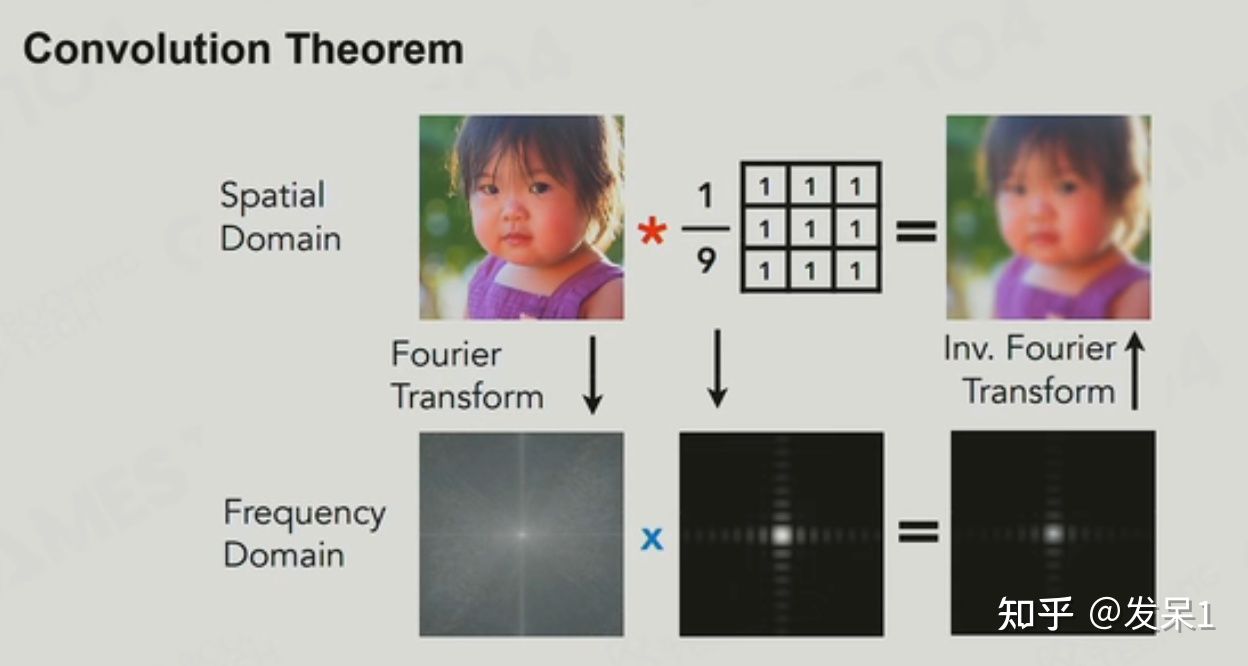
卷积定理(Convolution Theorem)
百度百科:卷积定理是傅立叶变换满足的一个重要性质。卷积定理指出,函数 卷积的 傅立叶变换是函数傅立叶变换的乘积。具体分为时域卷积定理和频域卷积定理,时域卷积定理即时域内的卷积对应频域内的乘积;频域卷积定理即频域内的卷积对应时域内的乘积,两者具有对偶关系。
对于空间域中的一个数字信号(下图以照片为例),我们可以通过傅里叶变换将其转化为频率域的一段频率,截取频率的一小段就可以实现对频率整体的一个粗糙的表达,这时我们再通过反向傅里叶变换就可以得到原数字信号的大概情况。通过这一数学性质,我们不需要再去进行复杂的乘积累加和运算
球谐函数(Spherical Harmonics)
球谐函数就是一组基函数的集合,并且基函数越多,它的表达能力就越强(我个人理解就是回归性越强)
球谐函数有以下性质:
- 正交性,这些基函数卷积在一起时值为0
- 球谐函数的二阶导数为0,它的图像变换是光滑的
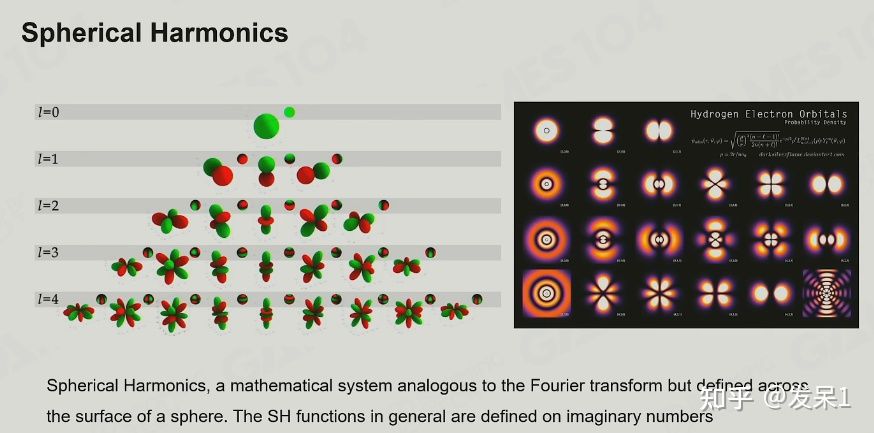
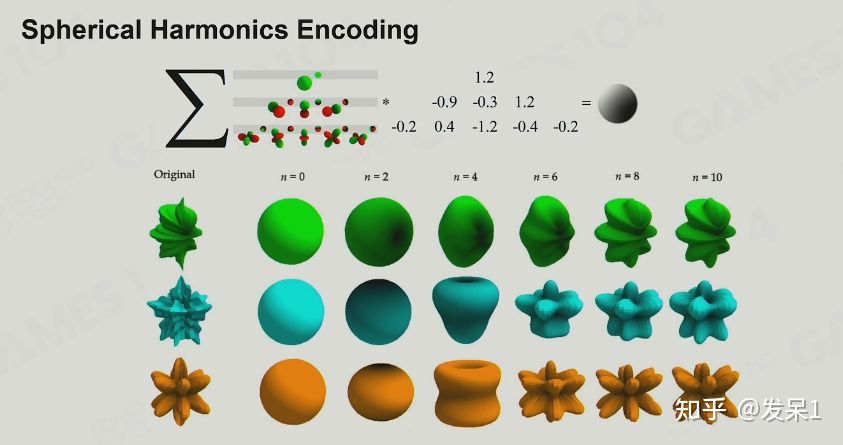
使用球谐函数,我们就可以通过一阶多项式近似的表达一个球面光照(低频信号)
Lightmap
有了球谐函数这一便捷工具,我们就可以将许多几何物体拍下存放在一张贴图上(这张贴图通常被称为“atlas”),这一过程又分为几个步骤
首先我们需要将几何物体进行简化,而后在参数空间内为每个几何物体分配近似的texel精度

下面我们在场景内加入全局光照,就可以表现出非常真实的效果

相应的,使用Lightmap有以下优缺点:
- Pros:1.实时运行效率很高;2.可以表现出全局光照的许多细节
- Cons:1.漫长的预计算时间;2.只能处理静态的场景和静态的光照;3.内存换时间,占用空间较大

Light Probe
我们可以在空间内放置许多采样点,对于每个采样点采集其对应的光场,当有物体移动经过某一采样点时,通过寻找附近的采样点并计算插值,就可以得到该采样点的光照

那么这么多的采样点我们该如何生成呢?我们首先在空间内均匀的产生采样点,再根据玩家的可到达区域和建筑物的几何结构进行延拓,相对均匀的分布采样点

Reflection Probe
我们还会做一些数量不多但采样精度非常高的Reflection Probe用于表现环境,一般它们与Light Probe分开采样

综合使用Light Probes和Reflection Probes,我们已经可以实现一个不错的全局光照的效果,它给我们带来以下好处:
- 实时运行效率很高
- 既可以处理动态物体又可以处理静态物体,并且可以实时更新
- 既可以处理漫反射也可以处理镜面着色
当然它也有一些缺陷:
- 大量的Light probes需要我们进行预计算
- 相比于Lightmap,它对于全局光照和重叠部分的软阴影的细节处理精度较低

基于物理的材质
微平面理论(Microfacet Theory)
这一理论的思想可以概括为:一个平面表面的光滑程度取决于它的法向量的聚集度,法向量全都集中在一起时,它的反光就相对较好
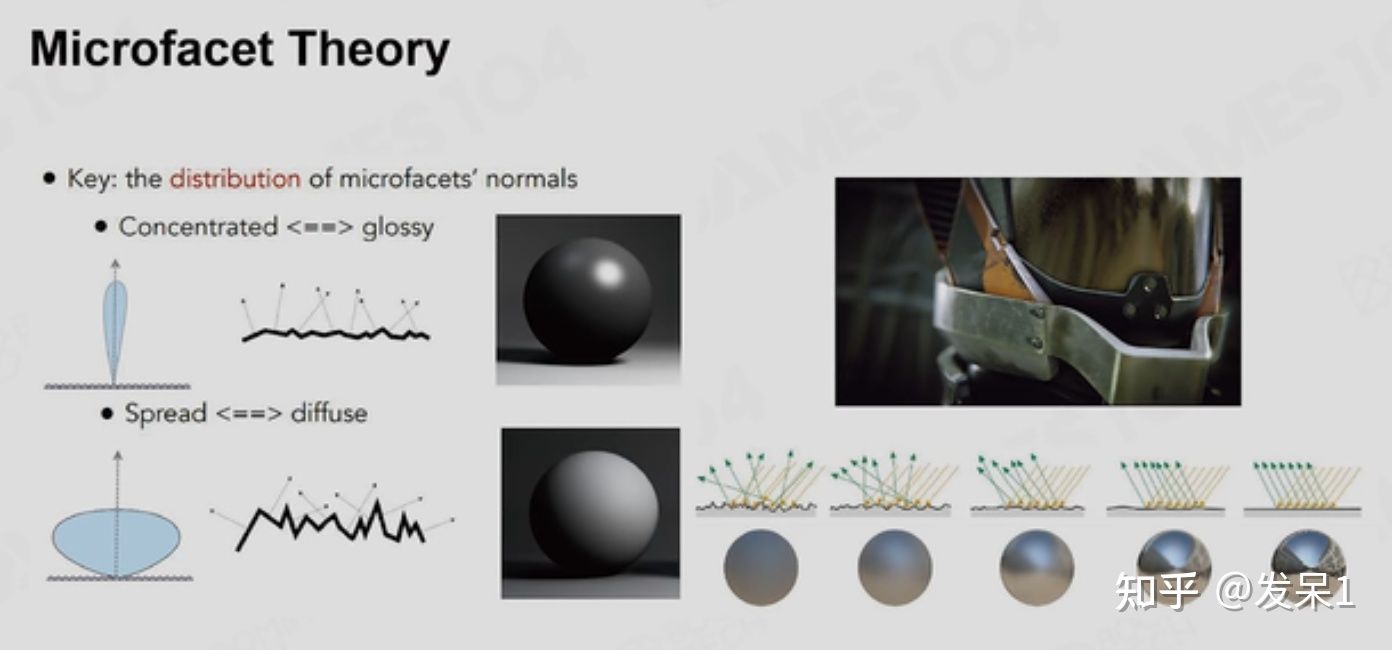
基于微平面理论的BRDF模型
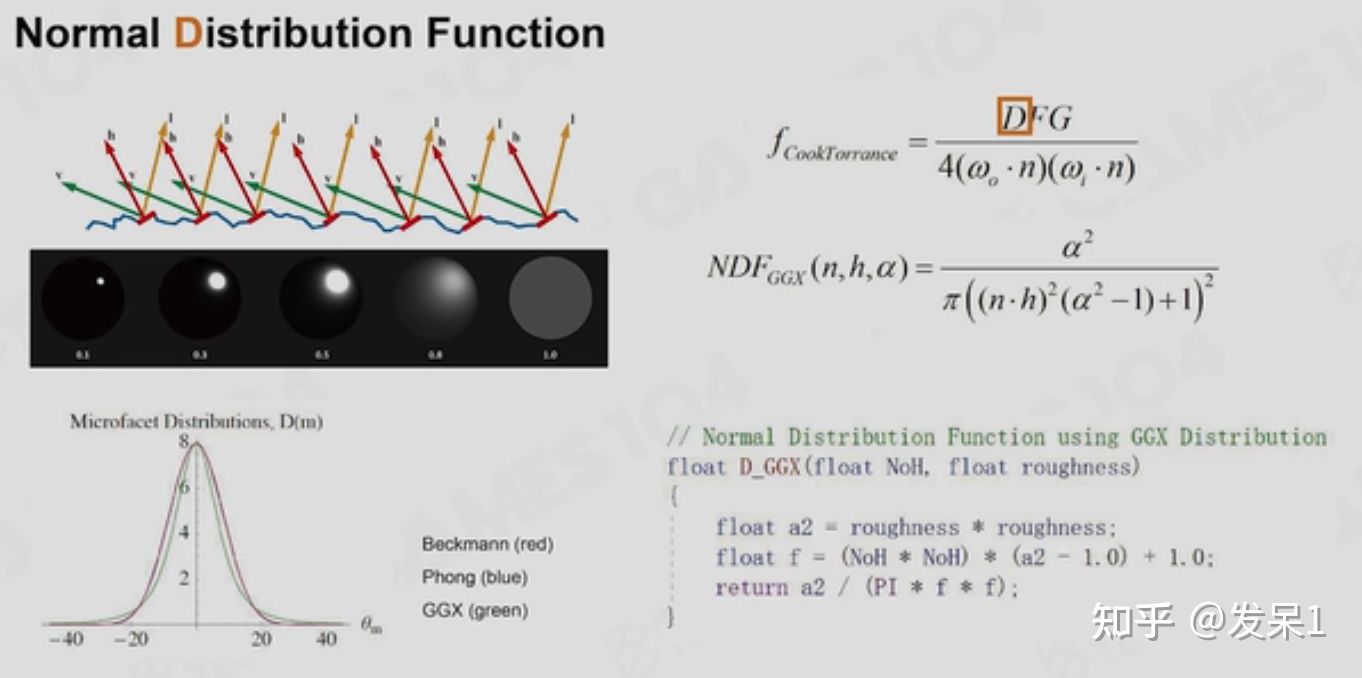
通过微平面理论我们可以将BRDF分为两部分,一部分是漫反射(diffuse)(这一部分的积分值为c/Π,c取决于入射的能量),另一部分则是高光(spectual),在该部分中引入了CookTorrance模型,其中DFG模型是CookTorrance模型中的核心元素。漫反射和高光的区别在于材质是金属还是非金属,金属中的电子能够吸收光子,它的高光就比较明显;而非金属中的电子不能吸收光子,光子只能在其内部进行一系列的漫反射

DFG模型中的D指法向分布方程(Normal Distribution Function)、F指菲涅尔现象(Fresnel Equation)、G指微表面几何内部的自遮挡(Geometric attenuation term)


MERl BRDF
为了便于艺术家们的使用,引擎工作者们对大量现实物体采样,构造出了MERL BRDF数据库,其中包含大量材质的BRDF参数

Disney BRDF Principle
- 使用的物理材质参数应当直白易懂
- 材质参数应当尽可能的少
- 参数取值范围尽量由0到1
- 各种参数的组合应当合理且有意义

PBR主流模型
Specular Glossiness(SG),这个模型中Diffuse控制漫反射部分,Specular控制菲涅尔现象,Glossiness控制材质的光滑程度。这一模型的参数设置较少,便于艺术家们使用,但也因其过于灵敏而容易导致奇怪的现象

Metallic Roughness(MR),这一模型中首先设置一个Base Color,而后通过金属度(Metallic)来控制Diffuse和菲涅尔现象。仅调节金属度虽然使得灵活度下降了,但却不容易出问题,这也使得MR模型现今被更多的使用
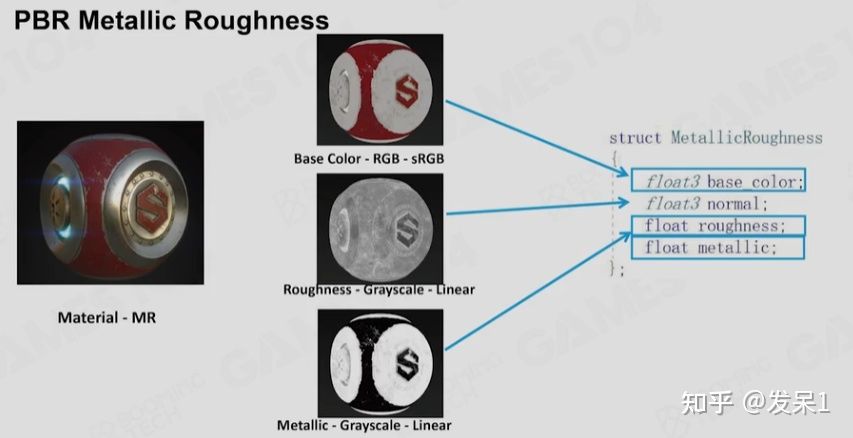
我们可以从MR模型转换为SG模型

下图为MR模型和SG模型优缺点的对比

Image-Based Lighting(IBL)
IBL的核心思想是:若我们能对环境光照的信息进行一些预处理,是否能减少光照处理中积分运算消耗的时间

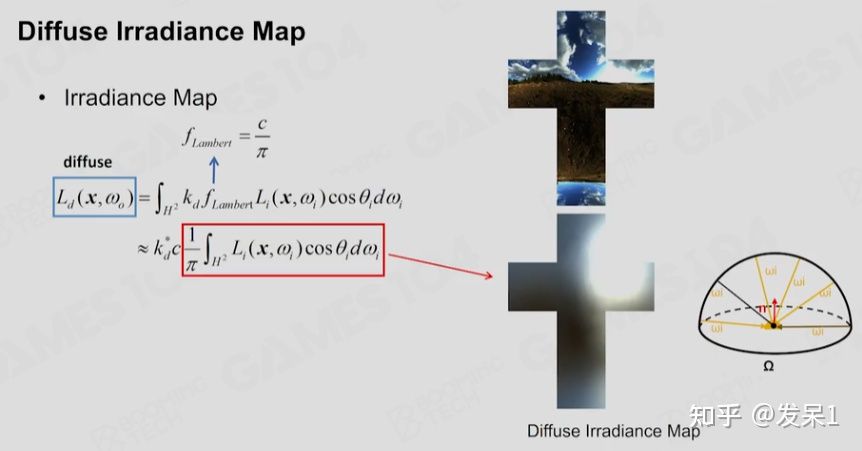
对于漫反射部分的光照,我们可以预先进行对应的卷积运算,并将其储存在Irradiance Map中
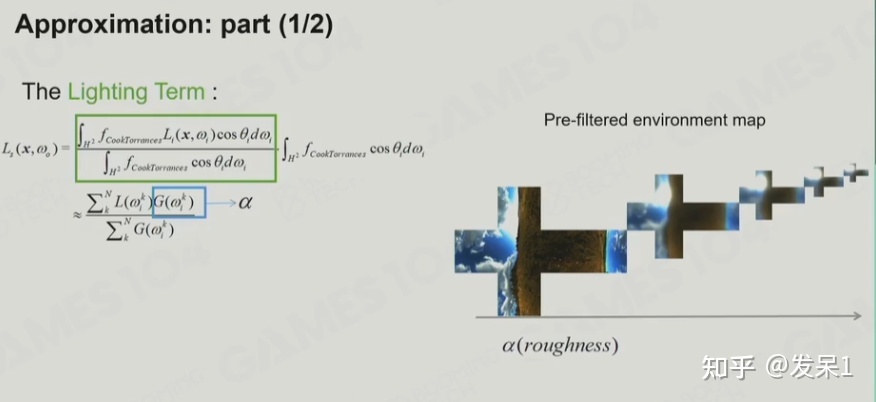
对于Specular部分,它涉及大量复杂的计算,可以近似为Lighting Term和BRDF Term的乘积


听到这里已经懵逼了,这一节课好难QAQ,先在这里留个坑,等把其他知识补了再回来填……
课程传送门:05.渲染中光和材质的数学魔法 | GAMES104-现代游戏引擎:从入门到实践_哔哩哔哩_bilibili
GAMES104实录 | 引擎架构分层(中)
本期为GAMES104《现代游戏引擎:从入门到实践》视频公开课文字实录第5期。本课程由GAMES(图形学与混合现实研讨会)发起,游戏引擎技术专家王希携手游戏引擎一线开发者共同研发。
课程共计22个课时,将介绍现代游戏引擎所涉及的系统架构,技术点,引擎系统相关的知识。为配合学习实践,课程组在 GitHub 上开源了小引擎Piccolo,上线1个月即获得了2900+star, 累计下载量已超过20000+。
以下内容为公开课视频转文字版本,为阅读通顺,有删减
引言
上节我们讲了游戏引擎的五层架构,这节课会真正给大家讲清楚现代游戏引擎的五层架构到底是什么,具体是怎么做的。
学一个东西最好的方式是什么?是练习它。我们给小明同学出了一道难题:学了上节课,你觉得已经懂了游戏引擎怎么做,那就做个小小的挑战吧:在游戏中做一个可以动起来的角色,然后从下往上把这些代码写到游戏里面去。
小明想,既然知道了引擎的五层架构,我就要去想每一个功能模块到底怎么写。这其实是一个非常有意思的脑力劳动,同学们可以先停一下,回顾一下我们讲的游戏引擎的五层架构:平台层、核心层、资源层、功能层和工具层。

如果小明想做一个可以动起来的角色,在游戏引擎中的代码该怎么去写呢?这件事情比大家想象的稍微复杂一点。
在这一讲中,我会跟大家讲每一层是什么以及每一层的要点是什么。
我们就从小明的挑战“做一个动起来的角色”开始,逐步带领大家进入引擎的深水区航行。
01「资源层」
从资源(resource)到资产
首先,小明遇到的第一个挑战:好不容易求做美术的好朋友用3DMax做了一个很可爱的小角色,还做了很多的贴图和动画。那这些东西叫什么?叫resource,资源。
每一个数据的格式都是不一样的,有的是Max文件,有的是PSD文件,这些数据肯定不可能在引擎中一一打开。大家想想看,如果写个小软件,要加载个声音,我要去问你声音是什么格式?MP3还是WMV?但在游戏引擎那么复杂的环境里面,不可能去读这么多复杂的数据格式。
比如像PSD、Max、Maya这些数据格式,它们工具做得非常复杂,这些数据如果直接在游戏引擎中加载,效率会非常低。所以会做一步转换,会把这些数据全部转换成引擎的高效数据,这个转换发生之后,我们就把它叫做Asset(资产)。
从资源(resource)到资产,有一个很大的不同是什么呢?
举一个简单的例子,如果是一张贴图,无论是JPG还是PNG,它里面有很多的压缩算法,如果在GPU中以它的数据格式存储的话,绘制起来效率是很低的,但在这一步处理(转换)的时候,会把所有的贴图,不管你是什么格式,都把它转成DPS格式。我们在游戏中看到的所有漂亮花材的颜色,都是用这种格式直接放到显存中。
这一步导入帮我们做了很多工作,包括在Max里面编辑一个漂亮的mesh。如果发现mesh文件特别大,一旦把它导成引擎的asset,你会发现很多编辑的数据全部扔掉了,这种感觉像什么?
就像这篇文章,我用word去写,那word保存下来的文件会比较大。但是,如果只取文章里的内容,把它变成txt,我们就会发现这个txt文件非常小,导入做的工作就是这个。所以小明同学第一步就要把这些数据引擎化,变成资产。
GUID,游戏资产的身份识别号
大家要关注的第二个问题是什么呢?
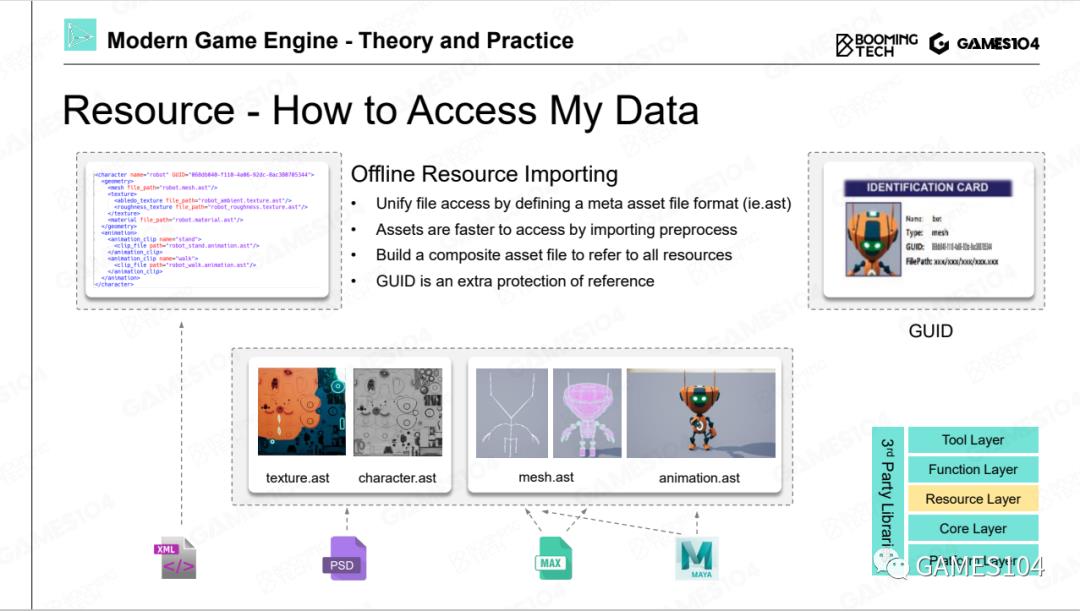
比如要表达这个可爱的小机器人(上图),首先这个小机器人有形体、贴图以及一大堆的动画资源,这些资源实际上是关联在一起的,但在引擎代码中没有一行代码说明这些资源之间是什么关系,这时候我们要定义另外一个资产。
这个资产就叫做composed asset。
它相当于一个关系脚本,我简单地做了个案例,定义了一个资产叫做Robot,它的mesh是什么?纹理是什么?该用什么动画?当引擎读取这一段composed asset的时候,它就知道要加载这些资源,所以它本身也是资产之一。
这里面要讲个概念,在游戏引擎中,特别在现代游戏中,其实核心的功能是数据之间的关联,或者叫做reference。大家如果打开任何一个现代游戏的安装目录,会看到很多很多文件,现在游戏发布的时候,一般都会把它打包成几个大的package,那里面有大概几十万甚至上百万个文件,而这些文件之间,有的是贴图,有的是声音,有的是动作,它们都像无数的网关联在一起。这里面大家会遇到一个非常有意思的概念,叫做GUID(唯一识别号)。
在现代游戏引擎中,我们希望给每个资产设置一个唯一识别号。打个最简单的比方,比如这个小机器人,贴图、mesh这些资产,现在是通过路径找到的,但这就像你只记得朋友的住址,那朋友搬家了怎么办?
很简单,每个人有一个身份证号,这样你的朋友搬到哪里都没有关系,只要这个身份证号在,你永远可以找到他。这个GUID的全称叫做全局唯一编号,实际上是游戏资产的身份识别号。
runtime asset manager
把游戏原始散乱的文件变成资产,进入到资源系统的时候,我们需要一个实时的资产管理器,这个资产管理器其实非常简单。

读了这么多文件,在引擎中就会管理,如同刚才讲的那个Reference关系一样,这些资产在资产管理器中,一般叫runtime asset manager(这里runtime指运行时或者实时)。
游戏跑起来也是一个一个文件,放在这掐头去尾就只是内容,但它们会互相指向对方。在游戏引擎设计中有一个很重要的系统,叫做handle系统。handle系统简单解释就像邮箱一样,你可以搬来搬去,我也不知道你在不在,但是我始终有你邮箱的钥匙,我知道你是105号邮箱,邮箱也知道你是105号邮箱的主人,这样,邮箱的主人在不在,我只要问这个邮箱就知道了。(这个地方比较深,我们以后会细讲)
简单来讲,游戏中最核心的是管理所有这些资产的生命周期,所以资源层是游戏引擎非常核心的一个层次。

为什么生命周期管理会这么重要?大家可能没有意识到,现代游戏中,比如我一路闯关杀降,从关卡A到关卡B再到关卡C,每一次闯关卡的时候,其实很多资产就要失效了,要加载很多新的资产,这些资产再根据当前玩家进度不断地加载和卸载,这个关系是非常复杂的。
前面讲的GUID系统和handle系统都在解决这个问题。大家如果有一定的编程基础,如果你学过C#, Java,知道有个概念叫做GC——垃圾回收。
在现代游戏里面,一般来讲,GC做不好就会让整个系统的效率变得非常低。如果去观察现代游戏引擎的架构,特别是很多游戏产品,你会发现它突然就会变得很慢,很多时候其实就是GC没有做好。一个关卡打完了要下去,另一个关卡要起来,大量的资源一下子加载进来,如果没有做好GC,机器就卡在那一帧了。这里面有很多很难的策略。
另外一个叫做延迟加载,延迟加载指的是希望人走到哪,这些资源再加载,因为内存很小、硬盘很大,希望根据我玩到哪,再不断地去加载。大家如果玩虚幻引擎做的游戏的时候经常有个细节(不知道最新版本有没有修改):一个角色出现在你的面前,一开始看到那个贴图很模糊,然后一点点变得更清晰,这个东西就是延迟加载导致的。
资源层是游戏非常核心的一个管理层,它管理能让整个游戏引擎跑起来的生态资源池的分配,它管理每个资产实时的生命周期,所以如果要做个游戏,我会建议大家先去看一下资源怎么去分配。
02「功能层」
Tick的魔力—— Tick Logic 和 Tick Render
有了这些资源,小明同学就可以开始做他游戏真正的玩法了,开始的那个挑战还记得吗?我们要做一个会动的角色。那怎么让角色动起来呢?
我们在上一节课立过一个Flag:希望全部课程上完之后,同学们看到一个引擎,知道从哪下手,这个部分要讲的就是真正的游戏引擎的功能,首先要讲一个有趣的概念:Tick。
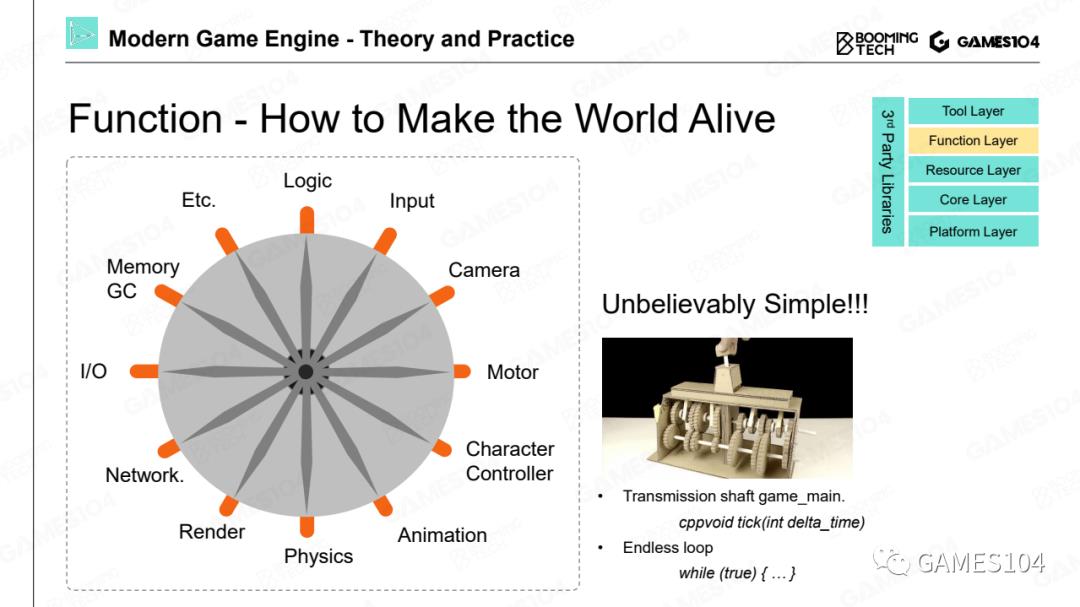
我蛮喜欢tick这个词的(一直没有找到一个很好的翻译词),非常像一台永动机,每隔一个固定间隔,就会把这个世界再往前推一小格,我是个狂热的民间物理科学爱好者,我认为上帝也是在Tick我们。上帝的Tick是多少呢?是一个普朗克时间。(大家如果有时间可以去研究一下普朗克,如普朗克速度、普朗克长度、普朗克能量等)
普朗克时间,非常非常小的一个时间片段,我们认为任何一个物理过程可能不能小于普朗克时间。在游戏中,每一个Tick,就是我们构建的这个世界里的普朗克时间,当一个Tick之后,系统就会依次把所有该做的事情做完。
比如我先去看看输入输出,动一下相机,动一下人物和角色,播一下动画,还可以绘制一帧的画面,还可以做一些刚才讲的memory GC……
在游戏的世界里面,是如何让这个世界动起来的?
其实就是利用现代计算机非常高的计算速度,在每隔1/30秒把整个世界的逻辑和绘制全部跑了一遍,这就是Tick的魔力。

十年前我在做引擎的时候,第一个半年并没有像大家想象的,写了很多的graph feature,写了很漂亮的rendering、shader。我们首先定义的是数据、数据格式以及这些数据在引擎、编辑器、文件中应该怎么呈现,这些其实是引擎开发真正的核心。
大家看现代游戏引擎,我会非常推荐找到这个tick函数,但它在源码里面不一定叫tick,一般在main函数里面会看到一个Tick。在Tick里面,就会出现两大神兽,一个叫Tick Logic,一个叫Tick Render。在第一讲里提到过游戏引擎不只是渲染,或者更确切地说渲染只是引擎的其中一部分,不是很大的一部分。也就是说一般会先Tick Logic,再Tick Render,它们的关系是什么呢?
继续回到我的这个民间物理科学家的思维方式,上帝如果把整个世界虚拟出来,首先会把整个世界的物理规则全部计算一遍。比如说现在有个姿态,无论绘不绘制它,这个姿态已经存在了,如果这个时候有惯性,那在下个Tick来的时候,是不是要再往前走一步?这也是自动符合物理学规律的。
但这个时候如果小明出现了,他有两双眼睛,他会选择一个视角去观察这个世界。我们以小明的眼睛生成一个二维的画面,这就是他所看见的东西,这个过程叫什么?就叫渲染。
所以说我们是以对这个世界的模拟为先——Tick Logic把这个世界模拟出来,然后再去渲染它,这就是现代游戏两大神兽的操作流程。
大家去看游戏,基本上就是先是逻辑后是渲染。逻辑把各个物体的输入输出读一遍,把整个世界的物理算一遍(比如把相机调一调、把角色动一动、把碰撞检测一下)。
比如张三有没有打中李四这件事是逻辑的事还是渲染的事?上完104课程的同学就会知道,那是逻辑的事。因为大家知道,无论你看见没看见,张三就是打中了李四,而且扣了李四的5点血,这就是逻辑。(以后讲到网络的时候,这个过程会更复杂)。
逻辑和绘制一定要严格细分,一个没有受过系统训练的游戏引擎开发者,很容易把两边的代码写混在一起,但是,如果把绘制和逻辑分开,基本上无论怎么写,都不会重合在一起。
渲染就更专业了,比如各种裁剪、光照、阴影、预计算等等(后面几节课会给大家介绍,这里不作为重点展开)。

所以每隔30秒tick,很多在屏幕上显示不出来的东西就会被裁掉,你只能看到你看得见的东西,你看到的人物的动作、树叶的飘落,都是一帧一帧地在变化,所以motion graph整个动画的基础理论就是依靠人的视觉残留感,从而产生一个连续的世界。这一点会在现代游戏中被充分地利用起来。
今天只是讲了一个功能层,最简单的东西就是从Logic到Render。
我想给大家讲一个概念,其实功能层是非常庞大的。我继续引用上古神书《游戏引擎架构》,这本书中关于功能层这一块的内容是最多的,真的是无所不有。
功能层有些模块是很清晰的属于游戏引擎的,比如绘制、渲染和管线,整个资产的管理等等,这些一定是属于引擎的。所以功能层在未来也会作为我们介绍的重点。
但功能层在很多引擎的架构中,它经常和具体的游戏关联在一起,让你无法区分。
比如相机控制,你觉得是游戏引擎提供的功能,还是说只要提供基础的相机绘制能力,相机的控制就交给某一个特定的游戏?比如说第三人称的射击游戏,希望这个相机有手持摄像机的摇晃感,那这个时候相机的摇晃、镜头的模糊、拉远拉伸等等,它其实是跟这个游戏有密切的关系的。这个模块是不是应该作为游戏的代码,而不是作为游戏引擎的代码呢?所以很多时候哪些功能属于游戏,哪些功能属于引擎,基本上就会在功能层上打架。

多核时代的游戏引擎架构
希望同学们能注意到一件事情:现在计算机的架构,已经在十几年前逐渐从单核走向多核。未来的多核时代,也会是游戏引擎架构的一个核心方向。
大家知道最早的游戏引擎是单线程的,就是一个线程跑道,后来有多核了。

最简单的做法是什么呢?比如说刚才讲了一个叫tick logic,一个叫tick render,我把logic和render分到两个线程里面去,当然还有额外的线程,比如做加载的。这是一个比较基础的多线程的算法。
现在的商业引擎,比如Unity或者Unreal,他们会再往前走一步,会把一些特别容易并行化的计算(比如物理、一些其他的animation等)单独地fork出来,分散到很多很多引擎。现在很多主流引擎都是这样的一个架构。
我们认为未来的引擎架构,能不能把所有的任务变成一个原子的,我们叫做job。你有4个核、8个核、16个核,没关系,我就一直扔,把你每个核吃得满满的。从上面的图来看,是不是觉得好像第三种方案看上去更漂亮点?
引擎到底是按照哪一种架构,其实有一个很简单的做法:你打开一个游戏,打开Windows的CPU profiling工具,去看每个CPU代表的那个小窗口是不是都吃得满满的?如果出现了有的吃得很满、有的吃不掉的情况,那它的多线程大概率是没有采取高级的job系统去做的。
这件事情可能比大家想象的要复杂得多。当真的去写游戏功能层的时候,你会发现很多计算中间是有一个依赖关系的,学术术语叫做dependency。
比如我现在拿手一挥,手上想打出个特效,那首先这个动画系统要算完,直到我的手到达特定位置,这时候才能把位置传导给粒子系统,然后把一个个小的光的粒子发出来。粒子系统的计算和动画系统的计算,对于角色来讲必须要有个先后关系。这一套非常高效率的多核并行架构,它难就难在dependency的管理上面,能够让它不出乱子。
我希望大家建立一个概念:未来的引擎架构一定是个多核架构。大家开始进行底层架构的时候,非常强烈推荐从多核开始去设计和思考整个底层代码。
我们的引擎之旅,到了功能层之后,小明同学已经非常厉害了。他已经知道把自己动画系统的角色挂到主的tick上了,他知道去做动作的时候,要在tick logic里面加一个tick animation,这样每次从资源里面把一个个的动画帧读进来,再把它骨骼驱动起来,那这个人就可以动起来了,然后在render里面每一帧去绘制,那个角色就绘制出来了。
小明肯定不止于此,因为我们是要做完整的游戏引擎的。因此下节课将和大家分享引擎架构分层的其他内容,如核心层、平台层等。
我们且听下回分解。
本文编辑:GAMES104编委会 张嘉瑶

如对本节课有任何问题,欢迎加入我们的社群或给我们发送邮件:
piccolo-gameengine@boomingtech.com
关注我们
以上是关于《GAMES104-现代游戏引擎:从入门到实践》-05 学习笔记的主要内容,如果未能解决你的问题,请参考以下文章