数据结构与算法:贪心算法
Posted maligebilaowang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法:贪心算法相关的知识,希望对你有一定的参考价值。
1. 贪心算法的概念
所谓贪心算法是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的仅是在某种意义上的局部最优解。
贪心算法没有固定的算法框架,算法设计的关键是贪心策略的选择。必须注意的是,贪心算法不是对所有问题都能得到整体最优解,选择的贪心策略必须具备无后效性,即某个状态以后的过程不会影响以前的状态,只与当前状态有关。
所以对所采用的贪心策略一定要仔细分析其是否满足无后效性。
2. 基本思路
-
建立数学模型来描述问题。
-
把求解的问题分成若干个子问题。
-
对每一子问题求解,得到子问题的局部最优解
-
把子问题的解局部最优解合成原来解问题的一个解。
3. 适用的问题
贪心策略适用的前提是:局部最优策略能导致产生全局最优解。也就是当算法终止的时候,局部最优等于全局最优。
因为用贪心算法只能通过解局部最优解的策略来达到全局最优解,因此,一定要注意判断问题是否适合采用贪心算法策略,找到的解是否一定是问题的最优解。
如果确定可以使用贪心算法,那一定要选择合适的贪心策略;
4.LeetCode–870 优势洗牌(田忌赛马问题)
问题描述:
给定两个大小相等的数组 A 和 B,A 相对于 B 的优势可以用满足 A[i] > B[i] 的索引 i 的数目来描述。
返回 A 的任意排列,使其相对于 B 的优势最大化。
* 输入:2 7 11 15
* 1 10 4 11
* 输出:2 11 7 15
问题分析:
- 可以每次都从A中找出大于当前B[i]的最小值,如果存在就将A[i]改写为该最小值,如果不存在将A[i]改写为数组最小值;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.Scanner;
/**
* leetcode870:优势洗牌
* 给定两个大小相等的数组 A 和 B,A 相对于 B 的优势可以用满足 A[i] > B[i]
* 的索引 i 的数目来描述。返回 A 的任意排列,使其相对于 B 的优势最大化。
*
* 输入:2 7 11 15
* 1 10 4 11
* 输出:2 11 7 15
*
*/
public class TiantianTest1
public static void main(String[] args)
//采用了ACM模式,因此需要自己写输入输出程序,将字符串解析为int数组
Scanner scanner = new Scanner(System.in);
String s1= scanner.nextLine();
String s2 = scanner.nextLine();
String[] c1 = s1.split(" ");
String[] c2 = s2.split(" ");
int[] n1 = new int[c1.length];
int[] n2 = new int[c2.length];
for (int i=0;i<c1.length;i++)
n1[i] = Integer.parseInt(c1[i]);
for (int i=0;i<c2.length;i++)
n2[i] = Integer.parseInt(c2[i]);
int[] res = advantageCount(n1,n2);
for (int a:res)
System.out.print(a+" ");
// System.out.println(Arrays.toString(advantageCount(n1,n2)));
public static int[] advantageCount(int[] A,int[] B)
LinkedList<Integer> list = new LinkedList<>();
Arrays.sort(A);
for (Integer i:A)
list.add(i);//存储排序后的A数组
//贪心策略:每一步都从A中找出比当前B[i]大的最小值(田忌赛马)
for (int i=0;i<B.length;i++)
A[i] = findMin(list,B[i]);
//对于找不到比B[i]大的情况,A[i]取最小值
for (int i = 0; i < A.length; i++)
if (A[i]==-1)
A[i] = list.get(0);
list.remove(0);
return A;
//该函数从A中找到大于B[i]的最小值
public static int findMin(LinkedList<Integer> list,int x)
for (Integer i:list)
if (i>x)
list.remove(i);
return i;
return -1;
数据结构与算法简记--贪心算法
贪心算法
贪心算法问题解决步骤
- 第一步,当我们看到这类问题的时候,首先要联想到贪心算法:针对一组数据,我们定义了限制值和期望值,希望从中选出几个数据,在满足限制值的情况下,期望值最大。
- 第二步,我们尝试看下这个问题是否可以用贪心算法解决:每次选择当前情况下,在对限制值同等贡献量的情况下,对期望值贡献最大的数据。
- 第三步,我们举几个例子看下贪心算法产生的结果是否是最优的。
贪心算法实战分析
- 分糖果:有 m 个糖果和 n 个孩子。要把糖果分给这些孩子吃,但是糖果少,孩子多(m<n),所以糖果只能分配给一部分孩子。每个糖果的大小不等,这 m 个糖果的大小分别是 s1,s2,s3,……,sm。除此之外,每个孩子对糖果大小的需求也是不一样的,只有糖果的大小大于等于孩子的对糖果大小的需求的时候,孩子才得到满足。假设这 n 个孩子对糖果大小的需求分别是 g1,g2,g3,……,gn。我的问题是,如何分配糖果,能尽可能满足最多数量的孩子?
- 选出几个孩子,在满足其糖果大小需求的情况下,满足的孩子最多。
- 每次选择对糖果大小需求最小的孩子,给他最小的不小于其需求大小的糖果,直到不再有满足。
- 钱币找零:假设我们有 1 元、2 元、5 元、10 元、20 元、50 元、100 元这些面额的纸币,它们的张数分别是 c1、c2、c5、c10、c20、c50、c100。用这些钱来支付 K 元,最少要用多少张纸币呢?
- 选择几个纸币,满足总额K元,使用最少纸币。
- 初始总额为K,每次选择最大面值但不超过剩余总额的纸币,总额K减去此面值,再次选择,直到总额减至0。
- 区间覆盖:假设我们有 n 个区间,区间的起始端点和结束端点分别是 [l1, r1],[l2, r2],[l3, r3],……,[ln, rn]。我们从这 n 个区间中选出一部分区间,这部分区间满足两两不相交(端点相交的情况不算相交),最多能选出多少个区间呢?
- 选择几个区间,满足两两不相交,区间最多。
- 每次选择满足起点不与前区间相交,终点最小的区间,直到不再有满足。
- 最小数字:在一个非负整数 a 中,我们希望从中移除 k 个数字,让剩下的数字值最小,如何选择移除哪 k 个数字呢?
- 选择几个数字,满足移除后,剩下数字值最小。
- 依次遍历每位数字,每次选择第一个大于下一位的数字,将其移除,循环k次。
- 等待最短:假设有 n 个人等待被服务,但是服务窗口只有一个,每个人需要被服务的时间长度是不同的,如何安排被服务的先后顺序,才能让这 n 个人总的等待时间最短?
- 选择n个人,按照一定的顺序,满足等待总时间最短
- 每次选择服务时间最短的人优先服务,直到服务完成。
- 压缩算法:霍夫曼编码
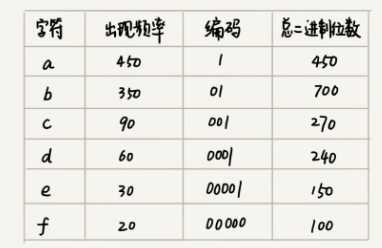
- 假设我有一个包含 1000 个字符的文件,每个字符占 1 个 byte(1byte=8bits)。
- 假设我们通过统计分析发现,这 1000 个字符中只包含 6 种不同字符,假设它们分别是 a、b、c、d、e、f。
- 假设这 6 个字符出现的频率从高到低依次是 a、b、c、d、e、f。我们把它们编码下面这个样子,任何一个字符的编码都不是另一个的前缀,在解压缩的时候,我们每次会读取尽可能长的可解压的二进制串,所以在解压缩的时候也不会歧义。经过这种编码压缩之后,这 1000 个字符只需要 2100bits 就可以了。
-
编码方法:
-
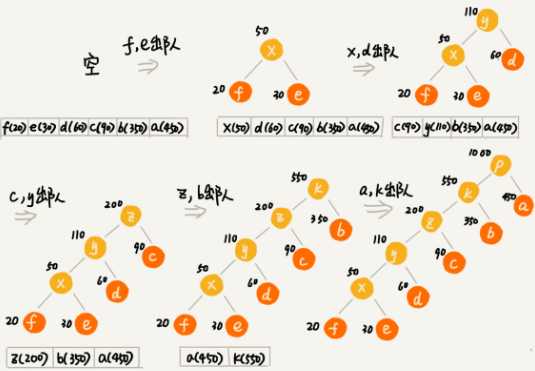
我们把每个字符看作一个节点,并且辅带着把频率放到优先级队列中。
-
我们从队列中取出频率最小的两个节点 A、B,然后新建一个节点 C,把频率设置为两个节点的频率之和,并把这个新节点 C 作为节点 A、B 的父节点。
-
最后再把 C 节点放入到优先级队列中。重复这个过程,直到队列中没有数据。
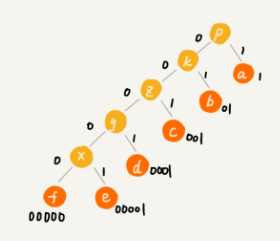
- 给每一条边加上画一个权值,指向左子节点的边我们统统标记为 0,指向右子节点的边,我们统统标记为 1。
- 从根节点到叶节点的路径就是叶节点对应字符的霍夫曼编码。
-
以上是关于数据结构与算法:贪心算法的主要内容,如果未能解决你的问题,请参考以下文章