大模型时代来临,智能文档处理该走向何方?
Posted 白水baishui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大模型时代来临,智能文档处理该走向何方?相关的知识,希望对你有一定的参考价值。
自去年ChatGPT发布以来,大语言模型(Large Language Model, LLM)的发展仿佛瞬间驶入了快车道,每天都能听到对相关话题的讨论。
cite: 清华大学人工智能国际治理研究院微博
按照现行的标准,能被称为大语言模型至少要满足以下四个条件:
- 模型:基于自回归语言模型,参数量超过百亿。
- 能力:具有思维链、情景学习等涌现能力,能够执行人类的指令。
- 对话:可以直接和人类进行对话。
- 对齐:符合人类价值观和思维方式,满足“有益(helpful)”、“诚实(honest)”和“无害(harmless)”三个原则。
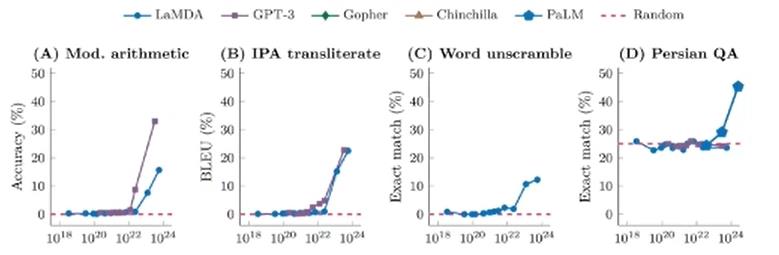
大语言模型的强大能力归因于巨大的参数量带来的涌现现象。当模型规模较小时,模型的性能和参数大致符合比例定律,即模型的性能提升和参数增长基本呈线性关系。然而,当 GPT-3/ChatGPT 这种千亿级别的大规模模型被提出后,模型的能力会产生质的飞跃(如,可以理解人类指令等)。
ChatGPT 的成功给人们带来了信心,因此很多科技公司和组织都在加快推出类似的产品。
在大模型来临的背景下,近期举办的CSIG企业行活动中,以“图文智能处理技术与多场景应用技术”为主题的技术分享会上,合合信息邀请了来自学界和业界的多位研究者共同探讨大语言模型在智能图文文档处理中所带来的新机遇以及所面临的挑战。
对话式大语言模型
复旦大学计算机学院邱锡鹏教授在 CSIG 企业行活动分享中分析到,ChatGPT之所以成功,是因为它打通了三项关键技术:
-
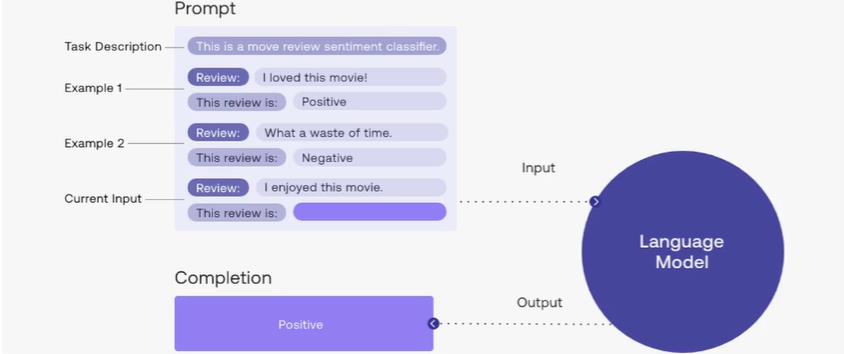
关键技术一:情景学习。所谓情景学习,就是将Prompt作为学习数据,一个Prompt包含任务描述、多个问答示例以及一个问题用例。情景学习主要学习答案的形式,而答案的实际内容主要来源于模型本身。
-
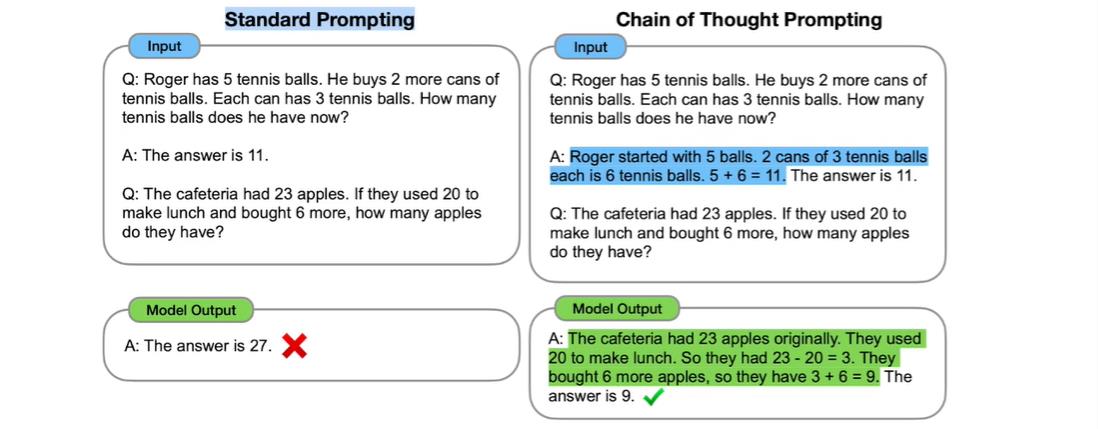
关键技术二:思维链。思维链通过构建更复杂数字Prompt来提供思维范式。例如,在解决数学问题时,Prompt应提供具体的分析过程。然而,思维链仅能学习问题分析形式,而无法直接分析出正确答案。因此,思维链通常需要与模型的计算能力相结合。
-
关键技术三:指令学习。指令学习旨在使机器理解人类指令。由于人类指令通常含糊不清,现有的语言模型仍无法完美响应人类指令。指令学习面临的最大挑战是泛化性,即模型需要通过学习已知指令来理解之前未见过的指令。但进行指令学习需要大量的人类指令数据。
这里,我们也不得不提国内已经上线几个大语言模型,虽然它们离ChatGPT还有一定的差距,但随着投资的加大和对技术路线的充沛信心,我相信迎头赶上也只是时间问题。
- 文心一言
文心一言拥有超过1000亿参数,涵盖了海量中文互联网数据,它专注于中文文本,对中文语境的理解较为深入。 - 腾讯ERNIE
腾讯AI Lab研发的预训练模型ERNIE,是基于Transformer架构的深度学习模型。ERNIE强调知识增强,通过整合多模态数据和知识图谱等外部知识,提高模型性能。 - 复旦MOSS
MOSS拥有超过200亿参数,可执行对话生成、编程、事实问答等一系列任务,打通了让生成式语言模型理解人类意图并具有对话能力的全部技术路径。
尽管类似ChatGPT的对话式大语言模型展示了通用人工智能的大框架,具有一定的思考能力,但图灵奖得主、人工智能三巨头之一 Yann LeCun 认为 ChatGPT 还是存在几个缺点,例如无法处理多模态信息、无法与自然场景相连接等等。
大模型时代的图文文档处理
在见识到大语言模型对文本的令人惊叹的处理能力之后,有不少工作将LLM模型扩展到多模态上,文档处理是其中重要的应用领域。
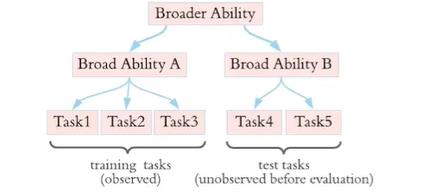
对于一线的研究人员来说,很希望出现一种工具,只需要我们甩一个PDF过去,它自己就能阅读,并且能三言两语用大白话解释清楚我们的疑惑。
NewBing和ChatPDF率先推出了分析PDF文档的功能,能够在几秒钟内解读长达几十页的文档内的文本、图像描述、公式和上下文结构,然后任由我们提问,它会根据文档内容进行回复。GPT-4更是有强大的推理能力,能够一步步推断出问题的正确答案。
复杂中文文档的结构建模
尽管交互式的大语言模型为文档处理带来了新的曙光,但对文档的复杂结构建模现在仍处于发展阶段。对于一个包含多行、多栏文本、表格、公式、图片、页眉和页脚等的文档,即使是GPT-4也不能在解析文本和识别内容结构方面做到完美。
这些复杂需求带动了复杂图像文档结构建模领域的研究。在早期的复杂文档研究存在很多缺陷,例如无法处理复杂排版、低分辨率和模糊图像,并且通常只适用于英文文档,对中文文档的泛化能力相对较弱。
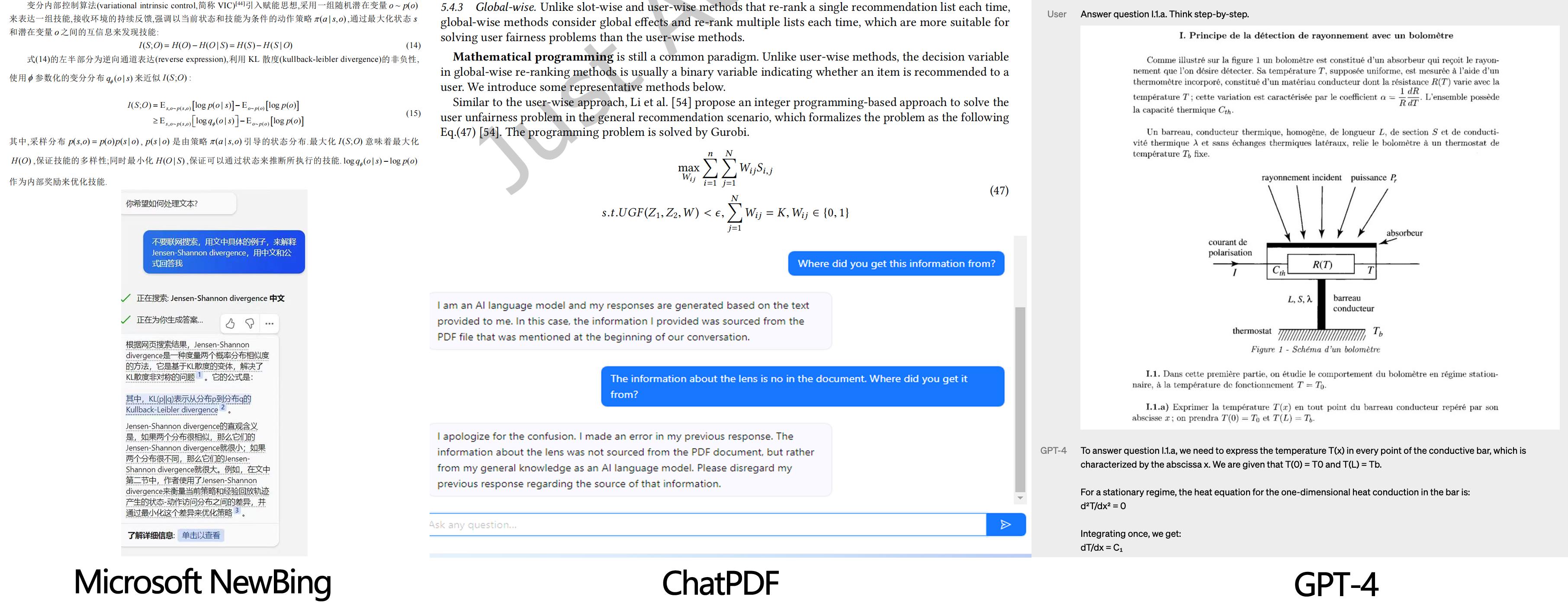
对此,中国科学技术大学杜俊副教授提到:对于中文文档的文档结构研究,应该从汉字、图表和篇章结构三个方面逐步完成。
杜俊副教授认为,汉字是一篇中文文档中最基本的构成单位。针对文档中的汉字,一方面需要实现汉字的识别,另一方面需要实现汉字的生成,这是一个联合优化的过程。
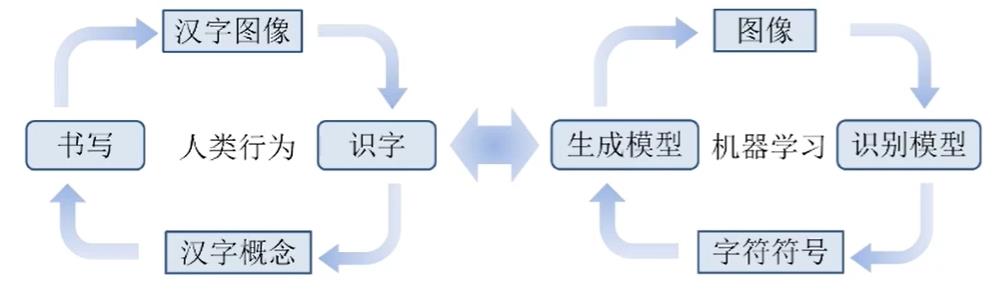
他提出,可以借鉴对公式处理的方式,首先对汉字的部首信息进行分割,并以树形结构进行组织。然后利用识别注意力机制识别汉字结构。在生成过程中,顺序正好相反:先给定汉字的结构,然后通过生成注意力机制来安排部首位置,从而实现汉字的生成。
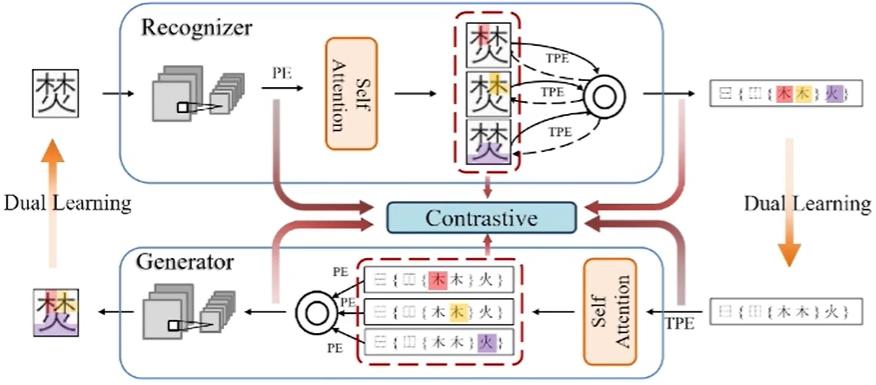
在解读汉字的基础之上更进一步,是识别和提取图表信息。具体到表格信息,杜俊副教授提出采用分割、嵌入和融合三大步骤实现更好地信息提取。
所谓分割,就是将表格图像拆分成一系列基础网格,利用行列分隔线的交点绘制表格的基本网格,从而呈现表格的整体框架。
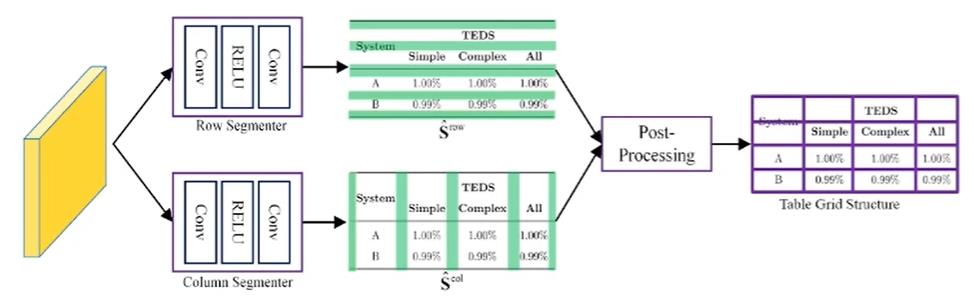
在完成分割任务之后,需要设计一个视觉模块以提取网格结构特征。同时,还需设计一个文本模块来提取网格中的文本特征。最后,通过一个融合模块将两种模态进行整合嵌入,得到最终的网格表征。
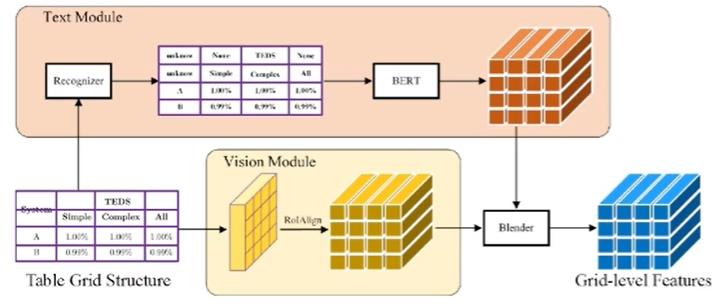
最后,通过应用Attention机制,逐步预测当前网格与其他网格的归并关系,实现跨行跨列单元的识别和提取。
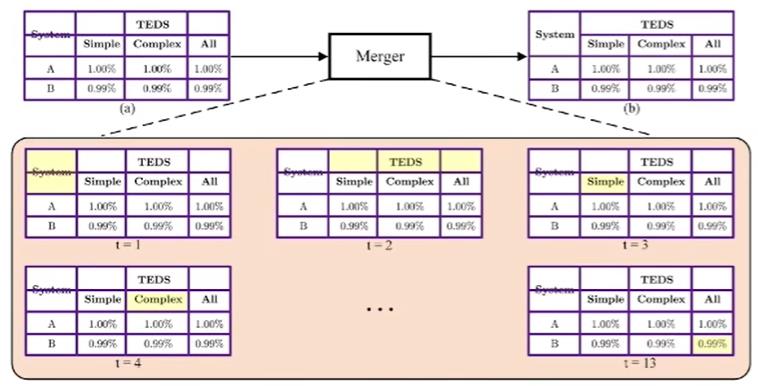
以上所述处于处理文档区域单元的阶段,实际上更重要的任务在于如何划分文本、图表、公式、段落、小节等区域。
过去的研究工作主要集中在单页文档内各类要素的检测、分类和关系预测。然而,在现实场景中,一篇文档的上下文元素之间的关系很可能跨越多个页面。
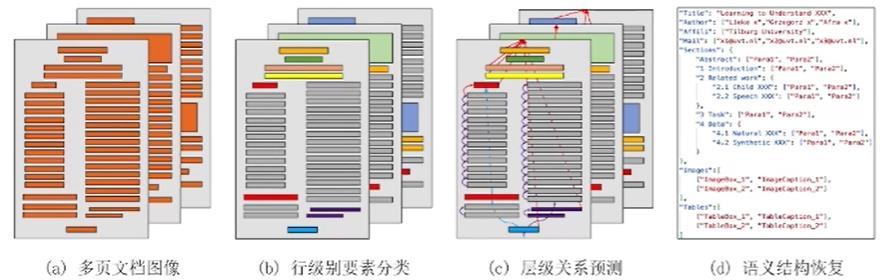
在处理多页文档时,我们需要识别并分类各个页面中的文档要素。这包括对文字、图片、表格等各类要素的检测和分类。此外,我们还需要重建文档的整体结构。这包括识别跨页的标题、段落和列表等要素之间的关系,以恢复文档的原始逻辑结构。
自然场景下的图文文档处理
尽管现在对中文文档的处理已经有了很深远的研究,但是仍然有很多重要问题还未解决,例如:
- 自然场景下的汉字建模:如何在噪声(光照不均、背景复杂等)图像上实现更好的手写、汉字生成与识别性能?
- 自然场景下的表格建模:如何在噪声(形变、倾斜等)图像上实现更加鲁棒的表格分割性能?
- 多模态文档建模:如何实现多模态大模型下的多版式文档(简历、海报、证件等)的理解和分析?

对于这些挑战,合合信息图像算法研发总监郭丰俊在 CSIG 企业行活动分享中给出了答案——在底层视觉任务中解决这些问题。
- 底层视觉任务:处理输入图像并输出图像。
这些任务包括:图像预处理、图像过滤、图像复原、图像增强等。 - 中层/顶层视觉任务:处理输入图像并输出特征或理解。
这些任务包括:图像分割、物体检测、场景识别等。
底层视觉研究的初衷在于,计算机所接收的现实图像常常受到噪音干扰,例如扭曲、模糊、光影等现象,因此,在进一步分析和理解输入图像之前,需要进行底层视觉处理,以对图像进行“预处理”。
以试卷文档处理为例,不规范的拍照方式会严重影响文本检测和提取的成功率。

智能文档处理中,底层视觉处理的Pipeline流程主要包括以下几个步骤:
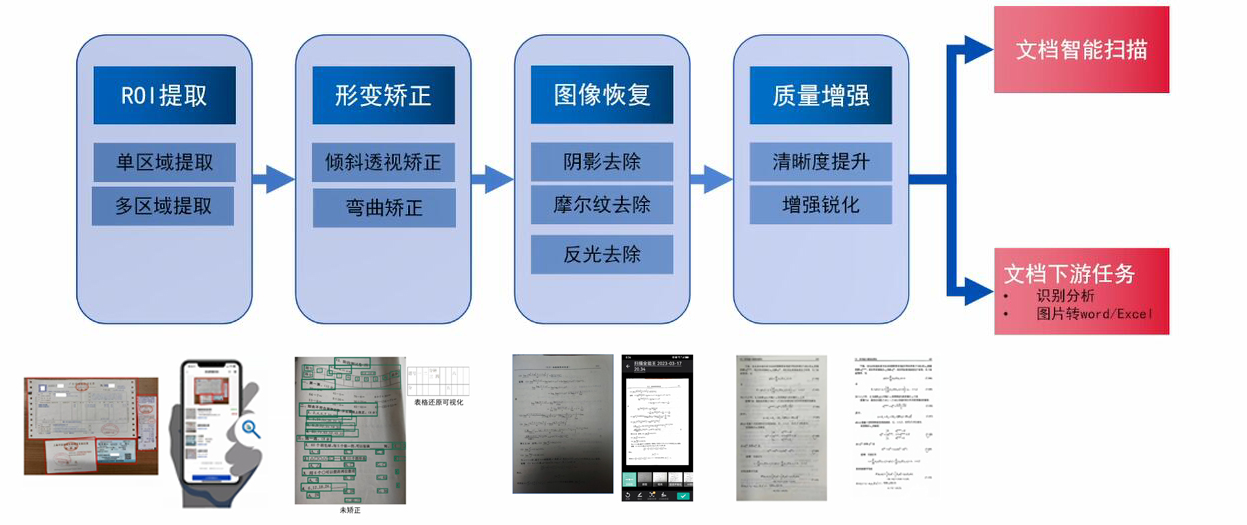
- ROI提取:在该步骤,图像中的关键区域被提取出来,以减少不相关区域对后续任务的干扰;
- 形变矫正:该步骤主要利用矫正方法对扭曲和倾斜的图像进行整平,为后续的OCR识别创造便利条件;
- 图像恢复:该步骤旨在消除阴影、反光、摩尔纹等干扰图像信息的噪声,从而提高图像的可识别程度;
- 质量增强:该步骤通过突出图像中的文本信息,有助于提高图像的可读性、可解释性和可感知质量。
可以看出,底层视觉技术主要包括图像预处理、特征提取、边缘检测、形态学变换等。当前,底层视觉技术的前沿难点有去除摩尔纹、去除反光、手写擦除和篡改检测等等。

经过数年的技术积累,合合信息已经在智能文档处理领域沉淀了丰富的经验,并将这些技术集成到了“扫描全能王”应用和“TextIn (https://www.textin.com/)”平台上。
立足大模型,下一站在何方?
站在多模态和自然场景的角度上继续延伸,以ChatGPT为代表的对话式大语言模型的潜力还可以进一步开发。厦门大学南强特聘教授纪荣嵘从语言和视觉两个方面强调了打通各个模态之间壁垒的重要性。可以说,构建多模态模型是助力机器理解人类指令的重要踏板,以文本和图像为例,当文本信息和图像信息能够完全相互代表时,人类对于图像的操作就可以仅通过一段话来完成。

IDC发布的《2022中国大模型发展白皮书》中提到:面向未来,大模型必然成为重要的AI新型基础设施之一。任何依靠人工智能展开的研究都可以在这种生成式大模型的基础上得到发展。上海交通大学人工智能研究院常务副院长杨小康就认为,生成式人工智能为构建基于视觉直觉的物理世界模型和虚拟数字人提供了可行的途径。未来,随着数学、物理、信息论、脑认知、计算机等学科的交叉,还可以进一步夯实生成式人工智能的基础理论,实现“物理+数据”联合驱动、“虚拟+现实”深度融合,从而加速科学发现、物质合成以及世界模型的构建。
虽然通用人工智能的大门尚未完全叩开,但是我们已经看到了光明的前景,我们还有许多可以探索和实现的事物,山高水远,道阻且长。
云数据库时代,DBA将走向何方?
摘要:伴随云计算的迅猛发展,数据库也进入了云时代。云数据库不断涌现,产品越来越成熟和智能,作为数据库管理员的DBA将面临哪些机遇和挑战?又应该具备什么能力,才能应对未来的不确定性?
本文分享自华为云社区《云数据库时代,DBA将走向何方?》,作者: GaussDB 数据库。
伴随云计算的迅猛发展,数据库也进入了云时代。云数据库不断涌现,产品越来越成熟和智能,作为数据库管理员的DBA将面临哪些机遇和挑战?又应该具备什么能力,才能应对未来的不确定性?
近日,华为云数据库营销专家Tony Chen和GaussDB伙伴生态总监、高级培训讲师张虎以及dbaplus社群联合发起人杨建荣开展了一场名为《云数据库时代,DBA将走向何方?》的主题对话,围绕DBA工作内容,探讨了DBA未来转型与出路,并针对性地提出了几点建议。下面是本次对话的文字记录。

Q1:DBA主要负责哪些工作内容?一个合格的DBA应该具备哪些基础能力?
杨建荣:DBA工作内容可从两个维度回答,第一个维度是从数据库整个工作范围来看,包括运维管理、数据迁移、架构优化三个部分,这三个部分是一个技术迭代的过程,对技能要求逐次递增。运维管理通常指的是安装部署、监控报警、备份恢复、在线变更等常规操作。在云时代,这些工作可以被云数据库替代。数据迁移指的是数据流转,包括数据库的升级、不同数据库之间的迁移等,会涉及到整个数据域的范畴。架构优化属于更高维度的内容,包含架构和优化两部分,比如:高可用架构、分布式架构、SQL优化、数据模型优化等。
第二个维度是从数据库分层来看,可分为四层。最上层是数据服务层,涉及到专家服务、云服务等内容。第二层是打造一个安全、稳定、高效的数据存储平台。第三层是架构支持层,包括高可用、公司架构、数据模型等内容。第四层是基础资源规划层,不同的数据库存储引擎对应不同技术栈,通过架构串联起底层资源,为上层提供稳定高效的数据存储平台。
一个合格的DBA需要具备的能力可简单分为三点,第一是对数据库的基本原理有更深入的理解;第二是关注时代变化,学习和研究前沿技术;第三是在架构层面持续技术演进,因为很多工作不是短期或者是一次性能完成的过程,需要不断去迭代升级。
Q2:目前,云数据库是行业发展大势,从云服务角度来看,云数据库给传统DBA带来了哪些挑战?同时也给了哪些新的机会?
张虎:与传统数据库相比,云数据库具备即开即用、一键安装部署、高可用、高可靠、监控告警等能力,极大释放了DBA一部分重复繁琐的运维工作,但也带来了一定挑战,比如云数据库设置了细粒密度权限,DBA无法访问宿主机文件系统;云数据库基于云服务构建,需要DBA掌握一定的云计算知识。
但挑战也意味着机遇,云数据库时代,DBA需要从数据库管理员角色转换为架构师。因为云数据库已经提供了基础运维的功能,DBA需要将重心转移到整个数据库架构层面,跟业务更紧密结合。
Q3:云数据库时代,DBA可以从哪些方面增强自身的知识和经验积累,提升自身竞争力,保持良好的职业发展?
杨建荣:云数据库时代,DBA需要提升数据库整体认知,从数据管理层面向架构设计层面演进,具体可以从以下四个方面提升能力:
1.夯实数据库基础知识。重新审视DBA在云数据库时代中需要具备的能力,衡量哪些是DBA必须要去做的的事情,不断巩固和提升基础知识。
2.融合公有云和私有云的能力。公有云和私有云的基本逻辑是相通的,结合两者的能力更有助于理解和学习数据库知识。
3.识别和强化核心能力。在掌握基础知识的基础上,不断强化数据库核心能力,比如架构设计、内核研发等,持续打造核心竞争力。
4.紧密结合业务。所有产品都是为客户业务服务的,DBA需要结合业务场景不断练就技术内功,比如SQL管理、慢日志管理、索引优化等,才能更好地为业务服务。
Q4:当前数据库行业对人才有哪些诉求?
张虎:当前国内数据库行业蓬勃发展,现在网上能查到的数据库产品有200多个。数据库作为数据存储和流转的基础平台,人才需求非常大,人才要求也多样化。
目前数据库领域对人才的诉求主要有以下几个方面,从数据库领域来划分,第一个是数据库内核开发;第二个是围绕数据库内核周边生态工具的开发,比如审计工具、数据库安全管理工具、数据库迁移工具等;第三个是数据库运维和调优,无论使用哪一家云厂商数据库或者是开源数据库,都必须保障系统稳定高效地运行;第四个是数据库应用开发,比如企业办公系统、企业内部的资源管理系统ERP、人力资源管理系统等。
从角色来划分,首先是开发者,无论是做内核、工具,还是相关信息系统应用开发,基本都属于开发者范畴。其次是测试。第三是市场售前,告诉客户数据库的特点或工具特性、产品卖点等。第四是售后实施。每一种角色对数据库的掌握侧重点都不一样,但无论从事哪些领域,担任什么角色,掌握数据库入门知识都是一个必备的能力。数据库人才需求很大,华为云数据库也在联合整个产业和高校,一起推动数据库人才的培养,为业界及华为自身业务发展保障数据库人才供给。
Q5:作为一名DBA,是否需要掌握一门编程语言?
杨建荣:这个需要具体问题具体分析。首先,从工作目标来看,先确认目标是什么,根据目标去决定是否需要学习一门编程语言。比如一个工作年限很长或者是经验非常丰富的资深人员,他应该本身已经具备这样的能力,这时应该强调的是具备编程思维,而不是去学习某一门编程语言。其次,善用外力,因地制宜。如果我们想实现某个能力,可以借用业界成熟经验,既避免了重复造轮子,又实现事半功倍的效果。最后,DBA和部分开发的薪资有一定差异,有些人想做开发,但是一直没有开始,所以在这个层面上,建议大家先动起来,先去落地实践。但除了开发之外,还有很多类似方向的事情值得我们去做,比如说数据的管理,从数据库管理员到架构师方向的转变。其实数据可以挖掘更多价值,如果往数据分析方向发展,反而更具优势。在这个过程中,开发语言可以大大提高我们的工作效率。
Q6:如何快速掌握一门技术,提升自己的技术认知?
张虎:要快速掌握一门技术,比较好的途径就是培训认证。考证是对自身学习能力的巩固和验证,备考的过程也是一个系统化的学习过程。认证可分为入门级、工作级和专家级三个层面,大家可根据自身情况进行选择。比如想从事数据库基本岗位,可以考取入门级或工作级认证,想进一步深耕,可以选择专家级认证。
考证面向的对象也很广泛,第一类,云厂商合作伙伴。很多云厂商对合作伙伴都有认证要求。比如华为拥有庞大的生态体系,人员能力认证在生态体系中是一个非常重要的环节,一般会要求华为合作伙伴通过一定数量的认证和考试。第二类,云厂商数据库领域工作人员。比如从事数据库相关工作的华为人,需要通过认证来识别员工能力,更好地为业务服务。第三类,银行、证券、政府等客户,他们对内部的IT从业人员也有考证要求。第四类,高校学生。从学校就开始接触数据库,然后去学习考证,对未来走向工作岗位是很有帮助的。
杨建荣认为,考证还是好处多多的。首先,通过培训认证可以快速了解本产品的完整体系知识,在掌握整体基础知识方面有一定的竞争力。其次,系统化地培训认证可以节省大量宝贵时间,能快速抓住重点,提升学习效率。最后,培训认证可以对个人学习成果进行验收。因为技术是不断演进的,考证不仅验收了自身阶段性学习成果,还能驱动自己去主动学习,持续打造核心竞争力。
华为云GaussDB开发者认证,助力DBA驰骋职场
近十年来数据库的形态发生了很大变化,各类数据库不断涌现,数据库架构也随之演进。云时代下,精力有限的个体如何快速掌握数据库新技能,为职场添光加彩,成为数据库从业人士提升能力的关键所在。因此,各种数据库相关认证应运而生。
考证的好处前面两位嘉宾已经讲得很清晰明了,这里就不再赘述。
想考证的小伙伴们,福音来了!华为云最近推出了GaussDB入门级开发者认证-Java方向,面向数据库初学者,培训理论知识和实操能力,掌握基于GaussDB数据库的Java编程实操,无论是DBA还是零基础小白都可以轻松胜任。
速戳:GaussDB入门级学习认证_GaussDB入门级开发者认证-Java_华为云开发者学堂-华为云
以上是关于大模型时代来临,智能文档处理该走向何方?的主要内容,如果未能解决你的问题,请参考以下文章