从Hive源码解读大数据开发为什么可以脱离SQLJavaScala
Posted 虎鲸不是鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从Hive源码解读大数据开发为什么可以脱离SQLJavaScala相关的知识,希望对你有一定的参考价值。
从Hive源码解读大数据开发为什么可以脱离SQL、Java、Scala
前言
【本文适合有一定计算机基础/半年工作经验的读者食用。立个Flg,愿天下不再有肤浅的SQL Boy】
谈到大数据开发,占据绝大多数人口的就是SQL Boy,不接受反驳,毕竟大数据主要就是为机器学习和统计报表服务的,自然从Oracle数据库开发转过来并且还是只会写几句SQL的人不在少数,个别会Python写个spark.sql(“一个sql字符串”)的已经是SQL Boy中的人才。这种只能处理结构化表的最基础的大数据开发人员,就是我们常提到的梗:肤浅的SQL Boy。。。对大数据完全不懂,思想还停留在数据库时代,大数据组件也都是拿来当RDBMS来用。。。这种业务开发人员的技术水平其实不敢恭维。
还有从Java后端开发转过来的,虽然不适应,但还是可以一个Main方法流畅地操作Spark、Flink,手写个JDBC,做点简单的二开,这种就是平台开发人员,技术水平要更高一些。Java写得好,Scala其实上手也快。
但是。。。这并不代表做大数据只能用SQL/Java/Scala。。。这么局限的话,也不比SQL Boy强到哪里去。
笔者最早还搞过嵌入式开发,自然明白C/C#/C++也可以搞大数据。。。
本文将以大数据开发中最常见的数仓组件Hive的drop table为例,抛砖引玉,解读为神马大数据开发可以脱离SQL、Java、Scala。
为神马可以脱离SQL
数据不外乎结构化数据和非结构化数据,SQL只能处理极其有限的结构化表【RDBMS、整齐的csv/tsv等】,绝大多数的半结构化、非结构化数据SQL是无能为力的【log日志文件、音图等】。古代的MapReduce本身就不可以用SQL,Spark和Flink老版本都是基于API的,没有SQL的年代大家也活得好好的。大数据组件对SQL的支持日渐友好都是后来的事情,主要是为了降低门槛,让SQL Boy也可以用上大数据技术。
肤浅的SQL Boy们当然只知道:
drop table db_name.tb_name;
正常情况这个Hive表就会被drop掉,认知也就局限于Hive是个数据库。
但是大数据平台开发知道去翻看Hive的Java API:
https://svn.apache.org/repos/infra/websites/production/hive/content/javadocs/r3.1.3/api/index.html
知道还有这种方式:
package com.zhiyong;
import org.apache.hadoop.hive.conf.HiveConf;
import org.apache.hadoop.hive.metastore.HiveMetaStoreClient;
/**
* @program: zhiyong_study
* @description: 测试MetaStore
* @author: zhiyong
* @create: 2023-03-22 22:57
**/
public class MetaStoreDemo
public static void main(String[] args) throws Exception
HiveConf hiveConf = new HiveConf();
HiveMetaStoreClient client = new HiveMetaStoreClient(hiveConf);
client.dropTable("db_name","tb_name");
通过调用API的方式,同样可以drop掉表。显然不一定要用DDL。通过HiveMetaStoreClient的方式,还可以create建表等操作。
懂大数据底层的平台开发当然还有更狠的方式:直接连Hive存元数据的mysql,对元数据表的数据做精准crud。。。
对结构化表的ETL或者其它的运算处理完全可以用Spark的DataFrame、Flink的DataStream编程,纯API方式实现,SQL能实现的Java和Scala都能实现,至于SQL实现不了的Java和Scala也能实现。。。
笔者实在是想不到除了RDBMS和各类包皮产品【在开源的Apache组件基础上做一些封装】,还有哪些场景是只能用SQL的。。。
至此,可以说明大数据可以脱离SQL。
为神马可以脱离Java
虽然Hive底层是Java写的,但是这并不意味着只能用Java操作Hive。认知这么肤浅的话,也就活该一辈子调参调API了。。。
找到dropTable的实际入口
从Hive3.1.2源码,可以找到dropTable方法:
@Override
public void dropTable(String dbname, String name, boolean deleteData,
boolean ignoreUnknownTab) throws MetaException, TException,
NoSuchObjectException, UnsupportedOperationException
dropTable(getDefaultCatalog(conf), dbname, name, deleteData, ignoreUnknownTab, null);
@Override
public void dropTable(String dbname, String name, boolean deleteData,
boolean ignoreUnknownTab, boolean ifPurge) throws TException
dropTable(getDefaultCatalog(conf), dbname, name, deleteData, ignoreUnknownTab, ifPurge);
@Override
public void dropTable(String dbname, String name) throws TException
dropTable(getDefaultCatalog(conf), dbname, name, true, true, null);
@Override
public void dropTable(String catName, String dbName, String tableName, boolean deleteData,
boolean ignoreUnknownTable, boolean ifPurge) throws TException
//build new environmentContext with ifPurge;
EnvironmentContext envContext = null;
if(ifPurge)
Map<String, String> warehouseOptions;
warehouseOptions = new HashMap<>();
warehouseOptions.put("ifPurge", "TRUE");
envContext = new EnvironmentContext(warehouseOptions);
dropTable(catName, dbName, tableName, deleteData, ignoreUnknownTable, envContext);
虽然有多个同名方法,但是底层调用的还是同一个方法:
/**
* Drop the table and choose whether to: delete the underlying table data;
* throw if the table doesn't exist; save the data in the trash.
*
* @param catName catalog name
* @param dbname database name
* @param name table name
* @param deleteData
* delete the underlying data or just delete the table in metadata
* @param ignoreUnknownTab
* don't throw if the requested table doesn't exist
* @param envContext
* for communicating with thrift
* @throws MetaException
* could not drop table properly
* @throws NoSuchObjectException
* the table wasn't found
* @throws TException
* a thrift communication error occurred
* @throws UnsupportedOperationException
* dropping an index table is not allowed
* @see org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore.Iface#drop_table(java.lang.String,
* java.lang.String, boolean)
*/
public void dropTable(String catName, String dbname, String name, boolean deleteData,
boolean ignoreUnknownTab, EnvironmentContext envContext) throws MetaException, TException,
NoSuchObjectException, UnsupportedOperationException
Table tbl;
try
tbl = getTable(catName, dbname, name);
catch (NoSuchObjectException e)
if (!ignoreUnknownTab)
throw e;
return;
HiveMetaHook hook = getHook(tbl);
if (hook != null)
hook.preDropTable(tbl);
boolean success = false;
try
drop_table_with_environment_context(catName, dbname, name, deleteData, envContext);
if (hook != null)
hook.commitDropTable(tbl, deleteData || (envContext != null && "TRUE".equals(envContext.getProperties().get("ifPurge"))));
success=true;
catch (NoSuchObjectException e)
if (!ignoreUnknownTab)
throw e;
finally
if (!success && (hook != null))
hook.rollbackDropTable(tbl);
主要就是获取了表对象,然后做了preDropTable预提交和commitDropTable实际的提交。这种2PC方式表面上还是很严谨。。。
可以发现HiveMetaHook这其实是个接口:
package org.apache.hadoop.hive.metastore;
/**
* HiveMetaHook defines notification methods which are invoked as part
* of transactions against the metastore, allowing external catalogs
* such as HBase to be kept in sync with Hive's metastore.
*
*<p>
*
* Implementations can use @link MetaStoreUtils#isExternalTable to
* distinguish external tables from managed tables.
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public interface HiveMetaHook
public String ALTER_TABLE_OPERATION_TYPE = "alterTableOpType";
public List<String> allowedAlterTypes = ImmutableList.of("ADDPROPS", "DROPPROPS");
/**
* Called before a table definition is removed from the metastore
* during DROP TABLE.
*
* @param table table definition
*/
public void preDropTable(Table table)
throws MetaException;
/**
* Called after failure removing a table definition from the metastore
* during DROP TABLE.
*
* @param table table definition
*/
public void rollbackDropTable(Table table)
throws MetaException;
/**
* Called after successfully removing a table definition from the metastore
* during DROP TABLE.
*
* @param table table definition
*
* @param deleteData whether to delete data as well; this should typically
* be ignored in the case of an external table
*/
public void commitDropTable(Table table, boolean deleteData)
throws MetaException;
继承关系:
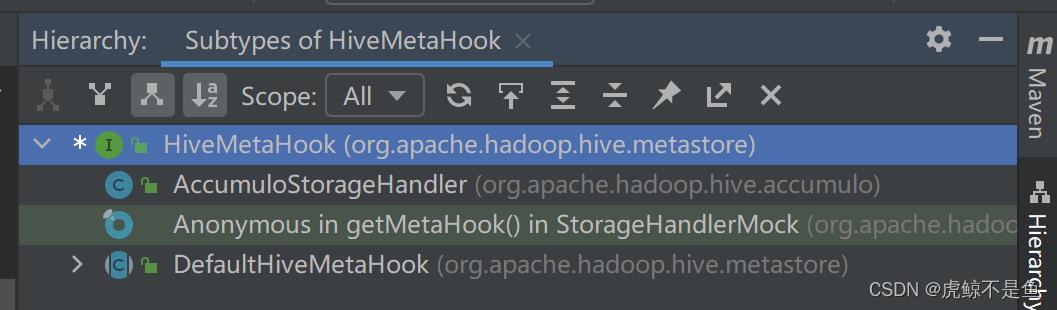
显然不是这个:
package org.apache.hadoop.hive.metastore;
public abstract class DefaultHiveMetaHook implements HiveMetaHook
/**
* Called after successfully INSERT [OVERWRITE] statement is executed.
* @param table table definition
* @param overwrite true if it is INSERT OVERWRITE
*
* @throws MetaException
*/
public abstract void commitInsertTable(Table table, boolean overwrite) throws MetaException;
/**
* called before commit insert method is called
* @param table table definition
* @param overwrite true if it is INSERT OVERWRITE
*
* @throws MetaException
*/
public abstract void preInsertTable(Table table, boolean overwrite) throws MetaException;
/**
* called in case pre commit or commit insert fail.
* @param table table definition
* @param overwrite true if it is INSERT OVERWRITE
*
* @throws MetaException
*/
public abstract void rollbackInsertTable(Table table, boolean overwrite) throws MetaException;
更不可能是这个test的Mock类:
/**
* Mock class used for unit testing.
* @link org.apache.hadoop.hive.ql.lockmgr.TestDbTxnManager2#testLockingOnInsertIntoNonNativeTables()
*/
public class StorageHandlerMock extends DefaultStorageHandler
所以是AccumuloStorageHandler这个类:
package org.apache.hadoop.hive.accumulo;
/**
* Create table mapping to Accumulo for Hive. Handle predicate pushdown if necessary.
*/
public class AccumuloStorageHandler extends DefaultStorageHandler implements HiveMetaHook,
HiveStoragePredicateHandler
但是:
@Override
public void preDropTable(Table table) throws MetaException
// do nothing
这个do nothing!!!一言难尽。这种2PC方式表面上确实很严谨。。。
所以dropTable的入口是:
@Override
public void commitDropTable(Table table, boolean deleteData) throws MetaException
String tblName = getTableName(table);
if (!isExternalTable(table))
try
if (deleteData)
TableOperations tblOpts = connectionParams.getConnector().tableOperations();
if (tblOpts.exists(tblName))
tblOpts.delete(tblName);
catch (AccumuloException e)
throw new MetaException(StringUtils.stringifyException(e));
catch (AccumuloSecurityException e)
throw new MetaException(StringUtils.stringifyException(e));
catch (TableNotFoundException e)
throw new MetaException(StringUtils.stringifyException(e));
按照最简单的内部表、需要删数据来看,实际上调用的是这个delete方法。而TableOperations又是个接口:
package org.apache.accumulo.core.client.admin;
/**
* Provides a class for administering tables
*
*/
public interface TableOperations
/**
* Delete a table
*
* @param tableName
* the name of the table
* @throws AccumuloException
* if a general error occurs
* @throws AccumuloSecurityException
* if the user does not have permission
* @throws TableNotFoundException
* if the table does not exist
*/
void delete(String tableName) throws AccumuloException, AccumuloSecurityException, TableNotFoundException;
继承关系简单:
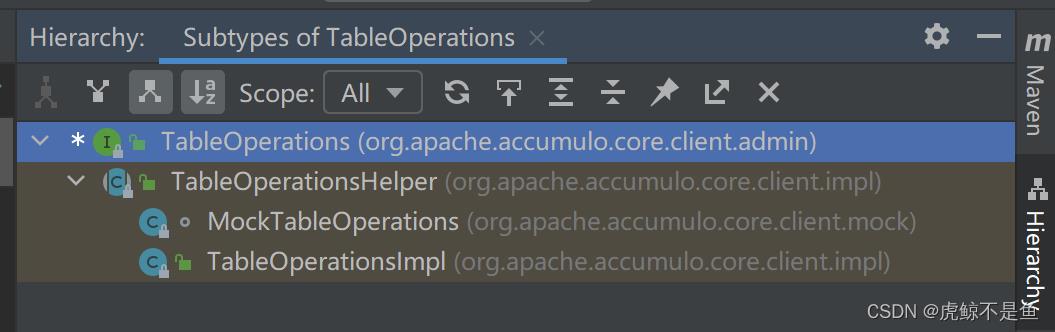
当然就是这个实现类:
package org.apache.accumulo.core.client.impl;
public class TableOperationsImpl extends TableOperationsHelper
@Override
public void delete(String tableName) throws AccumuloException, AccumuloSecurityException, TableNotFoundException
checkArgument(tableName != null, "tableName is null");
List<ByteBuffer> args = Arrays.asList(ByteBuffer.wrap(tableName.getBytes(UTF_8)));
Map<String,String> opts = new HashMap<>();
try
doTableFateOperation(tableName, TableNotFoundException.class, FateOperation.TABLE_DELETE, args, opts);
catch (TableExistsException e)
// should not happen
throw new AssertionError(e);
所以实际入口是这里的doTableFateOperation方法。枚举体的FateOperation.TABLE_DELETE=2。
找到doTableFateOperation方法的调用栈
跳转到:
private void doTableFateOperation(String tableOrNamespaceName, Class<? extends Exception> namespaceNotFoundExceptionClass, FateOperation op,
List<ByteBuffer> args, Map<String,String> opts) throws AccumuloSecurityException, AccumuloException, TableExistsException, TableNotFoundException
try
doFateOperation(op, args, opts, tableOrNamespaceName);
继续跳转:
String doFateOperation(FateOperation op, List<ByteBuffer> args, Map<String,String> opts, String tableOrNamespaceName) throws AccumuloSecurityException,
TableExistsException, TableNotFoundException, AccumuloException, NamespaceExistsException, NamespaceNotFoundException
return doFateOperation(op, args, opts, tableOrNamespaceName, true);
继续跳转:
String doFateOperation(FateOperation op, List<ByteBuffer> args, Map<String,String> opts, String tableOrNamespaceName, boolean wait)
throws AccumuloSecurityException, TableExistsException, TableNotFoundException, AccumuloException, NamespaceExistsException, NamespaceNotFoundException
Long opid = null;
try
opid = beginFateOperation();
executeFateOperation(opid, op, args, opts, !wait);
if (!wait)
opid = null;
return null;
String ret = waitForFateOperation(opid);
return ret;
catch (ThriftSecurityException e)
switch (e.getCode())
case TABLE_DOESNT_EXIST:
throw new TableNotFoundException(null, tableOrNamespaceName, "Target table does not exist");
case NAMESPACE_DOESNT_EXIST:
throw new NamespaceNotFoundException(null, tableOrNamespaceName, "Target namespace does not exist");
default:
String tableInfo = Tables.getPrintableTableInfoFromName(context.getInstance(), tableOrNamespaceName);
throw new AccumuloSecurityException(e.user, e.code, tableInfo, e);
catch (ThriftTableOperationException e)
switch (e.getType())
case EXISTS:
throw new TableExistsException(e);
case NOTFOUND:
throw new TableNotFoundException(e);
case NAMESPACE_EXISTS:
throw new NamespaceExistsException(e);
case NAMESPACE_NOTFOUND:
throw new NamespaceNotFoundException(e);
case OFFLINE:
throw new TableOfflineException(context.getInstance(), Tables.getTableId(context.getInstance(), tableOrNamespaceName));
default:
throw new AccumuloException(e.description, e);
catch (Exception e)
throw new AccumuloException(e.getMessage(), e);
finally
Tables.clearCache(context.getInstance());
// always finish table op, even when exception
if (opid != null)
try
finishFateOperation(opid);
catch (Exception e)
log.warn(e.getMessage(), e);
在这里可以发现一些奇怪的现象,居然catch了好多Thrift相关的Exception。继续跳转:
// This method is for retrying in the case of network failures; anything else it passes to the caller to deal with
private void executeFateOperation(long opid, FateOperation op, List<ByteBuffer> args, Map<String,String> opts, boolean autoCleanUp)
throws ThriftSecurityException, TException, ThriftTableOperationException
while (true)
MasterClientService.Iface client = null;
try
client = MasterCHive 源码解读 CliDriver HQL 语句拆分

Hive 版本:2.3.4
1. HQL 文件拆分
1.1 入口
从上一篇文章 Hive 源码解读 CliDriver HQL 读取与参数解析 中了解到,如果 Hive CLI 命令行中指定了 -f <query-file> 选项,需要调用 processFile 来执行文件中的一个或者多个 HQL 语句:
try
if (ss.fileName != null)
return cli.processFile(ss.fileName);
catch (FileNotFoundException e)
...
除了 -f <query-file> 选项需要调用 processFile 处理 HQL 文件之外,-i <filename> 选项也需要:
public void processInitFiles(CliSessionState ss) throws IOException
...
// 调用 processFile 处理初始文件
for (String initFile : ss.initFiles)
int rc = processFile(initFile);
...
...
1.2 文件处理 processFile
现在具体看一下 Hive 是如何通过 processFile 处理一个 HQL 文件中的语句。processFile 函数根据输入的文件路径名读取文件,实际处理逻辑交由 processReader 函数处理:
public int processFile(String fileName) throws IOException
Path path = new Path(fileName);
FileSystem fs;
// 绝对路径
if (!path.toUri().isAbsolute())
fs = FileSystem.getLocal(conf);
path = fs.makeQualified(path);
else
fs = FileSystem.get(path.toUri(), conf);
BufferedReader bufferReader = null;
int rc = 0;
try
bufferReader = new BufferedReader(new InputStreamReader(fs.open(path)));
rc = processReader(bufferReader);
finally
IOUtils.closeStream(bufferReader);
return rc;
我们可以看到 processReader 处理逻辑比较简单,只是去掉注释行,其他的调用 processLine 方法处理:
public int processReader(BufferedReader r) throws IOException
String line;
StringBuilder qsb = new StringBuilder();
// 一行一行的处理
while ((line = r.readLine()) != null)
// 跳过注释
if (! line.startsWith("--"))
qsb.append(line + "\\n");
return (processLine(qsb.toString()));
2. HQL 语句拆分
2.1 入口
除了上述 processFile 最终会调用 processLine 处理之外,hive -e <query-string> 执行查询字符串时也会调用:
CliDriver#executeDriver
if (ss.execString != null)
int cmdProcessStatus = cli.processLine(ss.execString);
return cmdProcessStatus;
除此之外,在交互式模式下从标准化输入中解析出 HQL 语句也会交由 processLine 来执行:
CliDriver#executeDriver
while ((line = reader.readLine(curPrompt + "> ")) != null)
...
// 直到遇到分号结尾才确定一个一条 HQL 语句的终结
if (line.trim().endsWith(";") && !line.trim().endsWith("\\\\;"))
line = prefix + line;
// HQL 语句的执行实际上交由 processLine 处理
ret = cli.processLine(line, true);
...
else
...
2.2 行处理 processLine
现在具体看一下 Hive 是如何通过 processLine 处理一个 HQL 语句。
首先第一部分的逻辑是对中断信号的处理。当调用的是 processLine(line, true) 方法时,表示当前作业可以被允许打断。当第一次用户输入 Ctrl+C 时,在交互式界面中输出 Interrupting... Be patient, this might take some time. 表示正在中断中,CLI 线程会中断并杀死正在进行的 MR 作业。当第一次用户输入 Ctrl+C 时,则会退出 JVM:
SignalHandler oldSignal = null;
Signal interruptSignal = null;
if (allowInterrupting)
interruptSignal = new Signal("INT");
oldSignal = Signal.handle(interruptSignal, new SignalHandler()
private boolean interruptRequested;
@Override
public void handle(Signal signal)
boolean initialRequest = !interruptRequested;
interruptRequested = true;
if (!initialRequest)
// 第二次 ctrl+c 退出 JVM
console.printInfo("Exiting the JVM");
System.exit(127);
// 第一次 Ctrl+C 中断 CLI 线程、停止当前语句并杀死正在进行的 MR 作业
console.printInfo("Interrupting... Be patient, this might take some time.");
console.printInfo("Press Ctrl+C again to kill JVM");
HadoopJobExecHelper.killRunningJobs();
TezJobExecHelper.killRunningJobs();
HiveInterruptUtils.interrupt();
);
第二部分逻辑是对 HQL 语句进行拆分:
// 拆分为不同的 HQL 命令
List<String> commands = splitSemiColon(line);
String command = "";
for (String oneCmd : commands)
if (StringUtils.endsWith(oneCmd, "\\\\"))
command += StringUtils.chop(oneCmd) + ";";
continue;
else
command += oneCmd;
if (StringUtils.isBlank(command))
continue;
// 交由 processCmd 处理命令
ret = processCmd(command);
command = "";
lastRet = ret;
boolean ignoreErrors = HiveConf.getBoolVar(conf, HiveConf.ConfVars.CLIIGNOREERRORS);
if (ret != 0 && !ignoreErrors)
CommandProcessorFactory.clean((HiveConf) conf);
return ret;
上游处理时只是针对每行末尾是分号 ; 时才调用 processLine 进行处理,所以一行中可能存在多条 HQL 命令,如下所示一行中就存在两条 HQL 命令:
hive > USE default;SELECT concat(uid, ";") FROM behavior LIMIT 1;
首先第一步就是将 HQL 语句拆分为不同的 HQL 命令,需要注意的是不能使用 split 函数直接根据 ; 进行拆分,因为 HQL 语句中可能存在 ;,例如上述语句中的第二个命令,所以需要单独调用 splitSemiColon 方法进行处理。最后将拆分后的 HQL 命令交由 processCmd 方法执行。
以上是关于从Hive源码解读大数据开发为什么可以脱离SQLJavaScala的主要内容,如果未能解决你的问题,请参考以下文章