Springboot项目快速实现过滤器功能
Posted 凡夫贩夫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Springboot项目快速实现过滤器功能相关的知识,希望对你有一定的参考价值。
前言
很多时候,当你以为掌握了事实真相的时间,如果你能再深入一点,你可能会发现另外一些真相。比如面向切面编程的最佳编程实践是AOP,AOP的主要作用就是可以定义切入点,并在切入点纵向织入一些额外的统一操作,避免与业务代码过度耦合。熟悉java web项目的都知道,另外还有过滤器(filter)、拦截器(interceptor)也有类似AOP的功能特性,那么问题来了:为什么一般说面向切面编程就是指AOP,而不是过滤器和拦截器?过滤器和拦截器在Spring boot中怎么实现?这三者之间有什么区别?Springboot项目快速实现Aop功能中分享了AOP的相关实现,下面将再用两到三篇文章,分别和大家分享一下过滤器、拦截器的实现,以及AOP、过滤器、拦截器之间的横向对比,以便在业务开发中,能够快速、正确选对具体实现方法。
环境配置
jdk版本:1.8
开发工具:Intellij iDEA 2020.1
springboot:2.3.9.RELEASE
Filter简介
Filter, 中文意思是过滤器,Filter的全限定类名是javax.servlet.Filter,可以看出这是与servelt相关的一个接口;SpringMVC核心是DispatcherServlet,而DispatcherServlet又继承了Servlet,进而可以推测出Filter与SpringMVC也是关联关系。
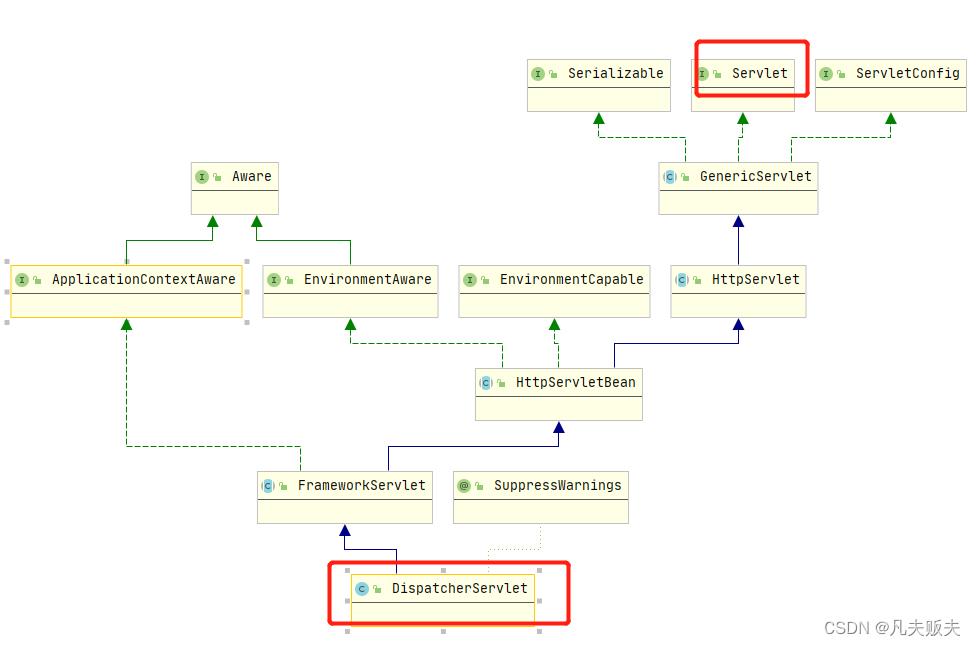
事实上这样的推测也是正确的,在SpringMVC项目中,filter在浏览器与服务器之间起过滤的作用,可以截取客户端和服务端之间的请求和响应信息,并根据这些请求-响应信息作一些其他的操作,但是要注意,filter并不能改变请求-响应信息;
核心类
Filter
Filter接口的全限定类名是javax.servlet.Filter,该接口有三个方法,分别是
1、init(...):用于初始化Filter;
2、doFilter(...):过滤请求和拦截响应信息的具体实现在这个方法里;
3、destroy(...):Filter对象被销毁时触发,主要用于做一些收尾工作,如资源的释放等;
FilterConfig
FilterConfig接口的全限定类名是javax.servlet.FilterConfig,该接口主要有四个方法,分别是:
1、getFilterName() 获取Filter的名字;
2、getServletContext() 获取ServletContext对象(即application);
3、getInitParameter() 获取Filter的初始化参数;
4、getInitParameterNames() 获取所有初始化参数的名字;
FilterChain
FilterChainr接口的全限定类名是javax.servlet.FilterChain,该接口只有一个方法,是doFilter()方法,用于调用Filter链上的下一个过滤器,如果当前过滤器为最后一个或只有一个过滤器,则该过滤器则将请求发送到目标资源。
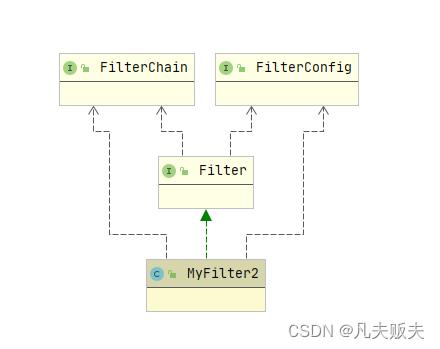
MyFilter2是自己实现的过滤器,实现了Filter接口;Filter接口依赖FilterChain接口和FilterConfig接口,其中FilterChain接口的实现类是org.apache.catalina.core.ApplicationFilterChain,FilterConfig接口的实现类是org.apache.catalina.core.ApplicationFilterConfig;
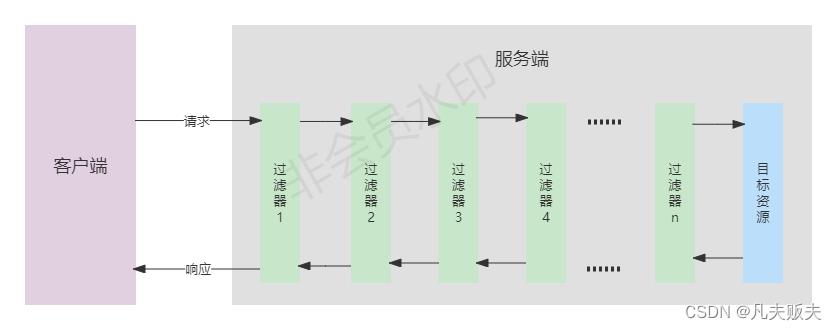
工作原理
1、项目启动的时候,先执行Filter的构造方法,完成相关Filter对象的注册;
2、紧接着,Filter对象的init()方法被调用,开始对Filter做一些初始化操作;
3、项目启动完成后,客户端每次向服务端发起请求时,如果请求地址与过滤器定义的地址匹配,则会执行Filter的doFilter();如果匹配上多个过滤器,则会形成一个链路,依次调用各个过滤器对象的doFilter();服务端作出响应后,也会再次执行到各个过滤器对象的doFilter();请求和响应时,过滤器链的执行顺序是先进后出;
4、服务器停止时调用Filter的destroy()方法,用来释放资源。
实现方式
Springboot项目中一般有两种方式:
1、@WebFilter注解,即javax.servlet.annotation.WebFilter;
2、FilterRegistrationBean,即org.springframework.boot.web.servlet.FilterRegistrationBean;
两种方式,都需要在启动类上增加注解@ServletComponentScan,用于开启servlet相关bean的扫描,其中包含有过滤器(Filter);
@SpringBootApplication
@ServletComponentScan
public class FanfuApplication
public static void main(String[] args)
SpringApplication.run(FanfuApplication.class, args);
代码实现
1、WebFilter注解里,定义一下过滤器的名字,以及要对哪些请求进行过滤,“/*”表示对所有的请求都过滤,在实际业务中,可具体对待;如果在初始化的时候,需要携带一些初始化的参数,可以在initParams属性上,使用@WebInitParam注解来定义初始化参数名称和具体的值,这些参数可以在filter对象初始化的时候获取到;MyFIlter1和MyFIlter2使用的注解方式定义的过滤器;
@Slf4j
@WebFilter(filterName = "myFilter1", urlPatterns = "/*", initParams = @WebInitParam(name = "creator", value = "fanfu"))
public class MyFilter1 implements Filter
@Override
public void init(FilterConfig filterConfig) throws ServletException
log.info("//myFilter1初始化开始");
String creator = filterConfig.getInitParameter("creator");
log.info("//初始化参数creator:",creator);
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException
log.info("//myFilter1开始执行");
chain.doFilter(request, response);
log.info("//myFilter1结束执行");
@Override
public void destroy()
log.info("//myfilter1被销毁");
@Slf4j
@WebFilter(filterName = "myFilter2", urlPatterns = "/*")
public class MyFilter2 implements Filter
@Override
public void init(FilterConfig filterConfig) throws ServletException
log.info("//myFilter2初始化开始");
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException
log.info("//myFilter2开始执行");
chain.doFilter(request, response);
log.info("//myFilter2结束执行");
@Override
public void destroy()
log.info("//myFilter2被销毁");
2、FilterRegistrationBean方式
在Springboot项目的配置类中,使用FilterRegistrationBean来包装自定义的过滤器,这种方式的最大好处就是可以自定义过滤器的执行顺序,数字越小,执行时的优先级就越高;MyFIlter3和MyFIlter4是使用FilterRegistrationBean方式定义的过滤器;
@Configuration
public class WebConfig
@Bean
public FilterRegistrationBean filterRegistration1()
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean();
filterRegistrationBean.setFilter(new MyFilter3());
filterRegistrationBean.addUrlPatterns("/*");//定义过滤器对哪些请求路径进行过滤,/*表示对所有请求都过滤
filterRegistrationBean.setOrder(2);//定义过滤器的执行优先级,数据越小优先级越高
return filterRegistrationBean;
@Bean
public FilterRegistrationBean filterRegistration2()
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean();
filterRegistrationBean.setFilter(new MyFilter4());
filterRegistrationBean.addUrlPatterns("/*");
filterRegistrationBean.setOrder(1);
return filterRegistrationBean;
@Slf4j
public class MyFilter3 implements Filter
@Override
public void init(FilterConfig filterConfig) throws ServletException
log.info("//MyFilter3初始化开始");
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException
log.info("//MyFilter3开始执行");
chain.doFilter(request,response);
log.info("//MyFilter3结束执行");
@Override
public void destroy()
log.info("//MyFilter3被销毁");
@Slf4j
public class MyFilter4 implements Filter
@Override
public void init(FilterConfig filterConfig) throws ServletException
log.info("//MyFilter4初始化开始");
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException
log.info("//MyFilter4开始执行");
chain.doFilter(request,response);
log.info("//MyFilter4结束执行");
@Override
public void destroy()
log.info("//MyFilter4被销毁");
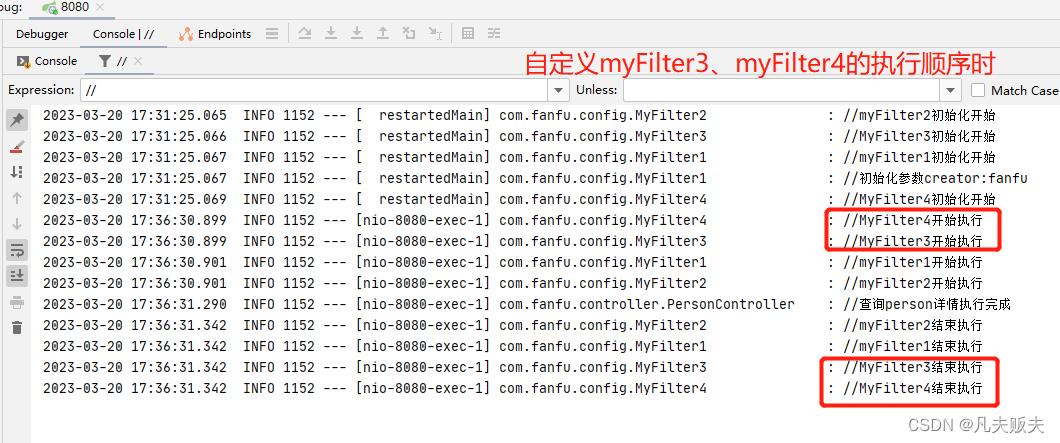
未定义myFilter3、myFilter4的执行优先级,即采取自然排序时的执行结果:在请求前myFilter3的执行时机早于myFilter4,响应后myFilter3的执行时机要晚于myFilter4;
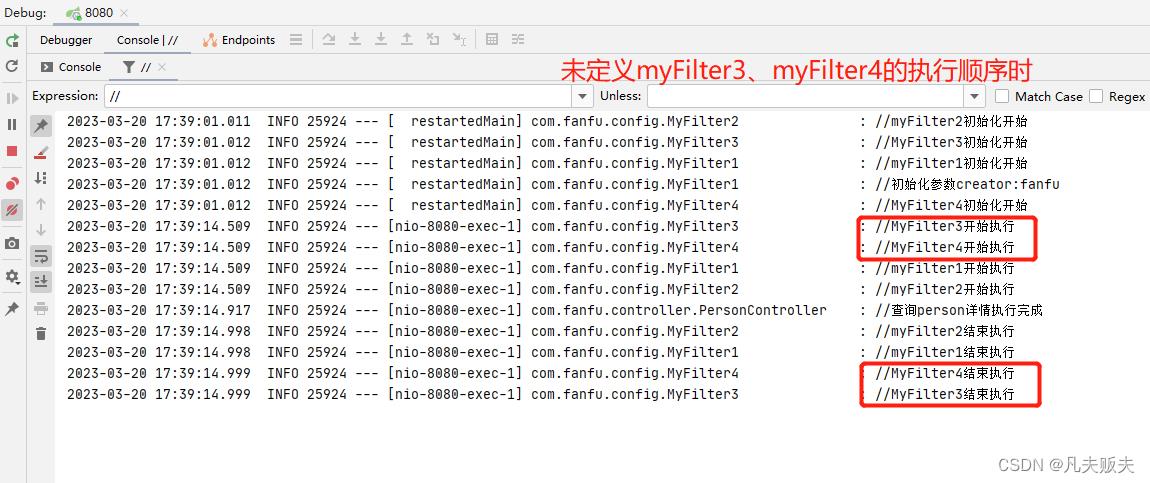
定义myFilter4的优先级高于myFilter3时,执行结果:在请求前myFilter4的执行时机早于myFilter3,响应后的myFilter4的执行时机要晚于myFilter3;
总结
过滤器的实现是比较简单,通过梳理这个过程,我get到以下几个点:
1、过滤器是用于SpringMVC项目中,即与servlet相关的项目;
2、过滤器的执行时机是在请求前和响应后,有两种实现方式,即@WebFilter注解和FilterRegistrationBean;如果对过滤器的执行顺序没有限制要求,则可以使用第一种;如果对过滤器的执行顺序有明确限制,则可以使用第二种;
3、如果有多个过滤器对象时,会形成一个过滤器链,过滤器的执行顺序是先进后出;
4、过滤器可以过滤请求和拦截响应,但是不能改变请求值和响应值;
手写SpringBoot项目XSS攻击过滤器实现
一、先来个简介
什么是XSS?
百度百科的解释: XSS又叫CSS (Cross Site Script) ,跨站脚本攻击。它指的是恶意攻击者往Web页面里插入恶意html代码,当用户浏览该页之时,嵌入其中Web里面的html代码会被执行,从而达到恶意用户的特殊目的。
它与SQL注入攻击类似,SQL注入攻击中以SQL语句作为用户输入,从而达到查询/修改/删除数据的目的,而在xss攻击中,通过插入恶意脚本,实现对用户游览器的控制,获取用户的一些信息。
二、XSS分类
xss攻击可以分成两种类型:
1.非持久型攻击
2.持久型攻击
非持久型xss攻击:顾名思义,非持久型xss攻击是一次性的,仅对当次的页面访问产生影响。非持久型xss攻击要求用户访问一个被攻击者篡改后的链接,用户访问该链接时,被植入的攻击脚本被用户游览器执行,从而达到攻击目的。
持久型xss攻击:持久型xss,会把攻击者的数据存储在服务器端,攻击行为将伴随着攻击数据一直存在。
也可以分成三类:
反射型:经过后端,不经过数据库
存储型:经过后端,经过数据库
三、代码走起
先加pom文件加上依赖

1 <dependency> 2 <groupId>org.apache.commons</groupId> 3 <artifactId>commons-text</artifactId> 4 <version>1.4</version> 5 </dependency>
1.首先是要写个过滤器的包装类,这也是实现XSS攻击过滤的核心代码。
这边因为业务需要,我拆分了两种的xss包装类,针对于不同的接口来使用。
第一中写法如下:
package com.hrt.zxxc.fxspg.xss;
import com.alibaba.fastjson.JSON;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.text.StringEscapeUtils;
import javax.servlet.ReadListener;
import javax.servlet.ServletInputStream;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletRequestWrapper;
import java.io.*;
import java.nio.charset.Charset;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
/**
* @program: fxspg
* @description: XSS过滤具体核心代码(第一种)
* @author: liumingyu
* @date: 2020-01-10 14:28
**/
public class XssAndSqlHttpServletRequestWrapper extends HttpServletRequestWrapper {
//声明sql注入的关键词key
private static String key = "and|exec|insert|select|delete|update|count|*|%|chr|mid|master|truncate|char|declare|;|or|-|+";
private static Set<String> notAllowedKeyWords = new HashSet<String>(0);
private static String replacedString="INVALID";
static {
String keyStr[] = key.split("\|");
//将key添加到Set集合中
for (String str : keyStr) {
notAllowedKeyWords.add(str);
}
}
/**
* @return
* @Author liumingyu
* @Description //TODO 构造函数,传入参数,执行超类
* @Date 2020/1/10 2:29 下午
* @Param [request]
**/
public XssAndSqlHttpServletRequestWrapper(HttpServletRequest request) {
super(request);
}
/**
* @return java.lang.String
* @Author liumingyu
* @Description //TODO 重写getParameter方法 ,getParameter方法是直接通过request获得querystring类型的入参调用的方法
* @Date 2020/1/10 2:31 下午
* @Param [name]
**/
@Override
public String getParameter(String name) {
String value = super.getParameter(name);
if (!StringUtils.isEmpty(value)) {
//调用Apache的工具类:StringEscapeUtils.escapeHtml4
value = StringEscapeUtils.escapeHtml4(value);
value = cleanSqlKeyWords(value);
}
return value;
}
/**
* @return java.lang.String[]
* @Author liumingyu
* @Description //TODO 重写getParameterValues
* @Date 2020/1/10 2:32 下午
* @Param [name]
**/
@Override
public String[] getParameterValues(String name) {
String[] parameterValues = super.getParameterValues(name);
if (parameterValues == null) {
return null;
}
for (int i = 0; i < parameterValues.length; i++) {
String value = parameterValues[i];
//调用Apache的工具类:StringEscapeUtils.escapeHtml4
parameterValues[i] = StringEscapeUtils.escapeHtml4(value);
parameterValues[i] = cleanSqlKeyWords(parameterValues[i]);
}
return parameterValues;
}
@Override
public String getHeader(String name) {
//过滤xss攻击
String value = StringEscapeUtils.escapeHtml4(super.getHeader(name));
if (value == null){
return null;
}
//过滤sql注入
return cleanSqlKeyWords(value);
}
@Override
public String getQueryString() {
return StringEscapeUtils.escapeHtml4(super.getQueryString());
}
/**
* @return javax.servlet.ServletInputStream
* @Author liumingyu
* @Description //TODO 过滤JSON数据中的XSS攻击
* @Date 2020/1/10 4:58 下午
* @Param []
**/
@Override
public ServletInputStream getInputStream() throws IOException {
//调用方法将流数据return为String
String str = getRequestBody(super.getInputStream());
//如果str为"",则返回0
if ("".equals(str)) {
return new ServletInputStream() {
@Override
public int read() throws IOException {
return 0;
}
@Override
public boolean isFinished() {
return false;
}
@Override
public boolean isReady() {
return false;
}
@Override
public void setReadListener(ReadListener readListener) {
}
};
}
//将数据存放至map
Map<String, Object> map = JSON.parseObject(str, Map.class);
//声明个存放过滤后数据的hashMap
Map<String, Object> resultMap = new HashMap<>(map.size());
//开始遍历数据
for (String key : map.keySet()) {
Object val = map.get(key);
//如果key=富文本字段名,就不去过滤
if ("content".equals(key)) {
//不过滤
resultMap.put(key, val);
} else {
//不为富文本字段才会过滤
if (map.get(key) instanceof String) {
//通过escapeHtml4去过滤
resultMap.put(key, StringEscapeUtils.escapeHtml4(cleanSqlKeyWords(val.toString())));
} else {
//不过滤
resultMap.put(key, val);
}
}
}
str = JSON.toJSONString(resultMap);
final ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(str.getBytes());
return new ServletInputStream() {
@Override
public int read() throws IOException {
return byteArrayInputStream.read();
}
@Override
public boolean isFinished() {
return false;
}
@Override
public boolean isReady() {
return false;
}
@Override
public void setReadListener(ReadListener readListener) {
}
};
}
/**
* @return java.lang.String
* @Author liumingyu
* @Description //TODO 获取JSON数据
* @Date 2020/1/10 4:58 下午
* @Param [stream]
**/
private String getRequestBody(InputStream stream) {
String line = "";
StringBuilder body = new StringBuilder();
int counter = 0;
// 读取POST提交的数据内容
BufferedReader reader = new BufferedReader(new InputStreamReader(stream, Charset.forName("UTF-8")));
try {
while ((line = reader.readLine()) != null) {
//拼接读取到的数据
body.append(line);
counter++;
}
} catch (IOException e) {
e.printStackTrace();
}
if (body == null) {
return "";
}
//最后返回数据
return body.toString();
}
/**
* @Author liumingyu
* @Description //TODO 过滤可能造成sql注入的关键字
* @Date 2020/1/13 9:11 上午
* @Param [value]
* @return java.lang.String
**/
private String cleanSqlKeyWords(String value) {
String paramValue = value;
for (String keyword : notAllowedKeyWords) {
if (paramValue.length() > keyword.length() + 4
&& (paramValue.contains(" "+keyword)||paramValue.contains(keyword+" ")||paramValue.contains(" "+keyword+" "))) {
paramValue = StringUtils.replace(paramValue, keyword, replacedString);
}
}
return paramValue;
}
}
第二种如下:
package com.hrt.zxxc.fxspg.xss;
import org.springframework.util.StreamUtils;
import org.springframework.util.StringUtils;
import javax.servlet.ReadListener;
import javax.servlet.ServletInputStream;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletRequestWrapper;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
/**
* @ClassName XssHttpServletRequestWrapper3
* @Description TODO xss过滤核心代码(第二种)
* @Author liumingyu
* @Date 2020/2/4 15:51
* @Version 1.0
**/
public class XssHttpServletRequestWrapper3 extends HttpServletRequestWrapper {
private static String key = "and|exec|insert|select|delete|update|count|*|%|chr|mid|master|truncate|char|declare|;|or|-|+";
private static Set<String> notAllowedKeyWords = new HashSet<String>(0);
private static String replacedString="INVALID";
static {
String keyStr[] = key.split("\|");
for (String str : keyStr) {
notAllowedKeyWords.add(str);
}
}
private String currentUrl;
private byte[] body;
/**
* @Author liumingyu
* @Description //TODO 构造函数
* @Date 2020/2/5 19:58
* @Param [servletRequest]
* @return
**/
public XssHttpServletRequestWrapper3(HttpServletRequest servletRequest) throws IOException {
super(servletRequest);
currentUrl = servletRequest.getRequestURI();
//获取到json数据
this.body = StreamUtils.copyToByteArray(servletRequest.getInputStream());
}
/**
* @Author liumingyu
* @Description //TODO 重写该方法过滤json数据
* @Date 2020/2/5 19:59
* @Param []
* @return javax.servlet.ServletInputStream
**/
@Override
public ServletInputStream getInputStream() throws IOException {
ServletInputStream inputStream = null;
String bodyStr = new String(body);
if (!StringUtils.isEmpty(bodyStr)) {
bodyStr = xssEncode(bodyStr, 1);
bodyStr = cleanSqlKeyWords(bodyStr);
final ByteArrayInputStream bais = new ByteArrayInputStream(bodyStr.getBytes());
return new ServletInputStream() {
@Override
public boolean isFinished() {
return false;
}
@Override
public boolean isReady() {
return false;
}
@Override
public void setReadListener(ReadListener readListener) {
}
@Override
public int read() throws IOException {
return bais.read();
}
};
}
return inputStream;
}
/**
* @Author liumingyu
* @Description //TODO 将容易引起xss漏洞的半角字符直接替换成全角字符
* @Date 2020/2/5 19:57
* @Param [s, type]
* @return java.lang.String
**/
private static String xssEncode(String s, int type) {
if (s == null || s.isEmpty()) {
return s;
}
StringBuilder sb = new StringBuilder(s.length() + 16);
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (type == 0) {
switch (c) {
case ‘‘‘:
// 全角单引号
sb.append(‘‘‘);
break;
case ‘"‘:
// 全角双引号
sb.append(‘“‘);
break;
case ‘>‘:
// 全角大于号
sb.append(‘>‘);
break;
case ‘<‘:
// 全角小于号
sb.append(‘<‘);
break;
case ‘&‘:
// 全角&符号
sb.append(‘&‘);
break;
case ‘\‘:
// 全角斜线
sb.append(‘\‘);
break;
case ‘#‘:
// 全角井号
sb.append(‘#‘);
break;
// < 字符的 URL 编码形式表示的 ASCII 字符(十六进制格式) 是: %3c
case ‘%‘:
processUrlEncoder(sb, s, i);
break;
default:
sb.append(c);
break;
}
} else {
switch (c) {
case ‘>‘:
// 全角大于号
sb.append(‘>‘);
break;
case ‘<‘:
// 全角小于号
sb.append(‘<‘);
break;
case ‘&‘:
// 全角&符号
sb.append(‘&‘);
break;
case ‘#‘:
// 全角井号
sb.append(‘#‘);
break;
// < 字符的 URL 编码形式表示的 ASCII 字符(十六进制格式) 是: %3c
case ‘%‘:
processUrlEncoder(sb, s, i);
break;
default:
sb.append(c);
break;
}
}
}
return sb.toString();
}
public static void processUrlEncoder(StringBuilder sb, String s, int index) {
if (s.length() >= index + 2) {
// %3c, %3C
if (s.charAt(index + 1) == ‘3‘ && (s.charAt(index + 2) == ‘c‘ || s.charAt(index + 2) == ‘C‘)) {
sb.append(‘<‘);
return;
}
// %3c (0x3c=60)
if (s.charAt(index + 1) == ‘6‘ && s.charAt(index + 2) == ‘0‘) {
sb.append(‘<‘);
return;
}
// %3e, %3E
if (s.charAt(index + 1) == ‘3‘ && (s.charAt(index + 2) == ‘e‘ || s.charAt(index + 2) == ‘E‘)) {
sb.append(‘>‘);
return;
}
// %3e (0x3e=62)
if (s.charAt(index + 1) == ‘6‘ && s.charAt(index + 2) == ‘2‘) {
sb.append(‘>‘);
return;
}
}
sb.append(s.charAt(index));
}
/**覆盖getParameter方法,将参数名和参数值都做xss过滤。
* 如果需要获得原始的值,则通过super.getParameterValues(name)来获取
* getParameterNames,getParameterValues和getParameterMap也可能需要覆盖
*/
@Override
public String getParameter(String parameter) {
String value = super.getParameter(parameter);
if (value == null) {
return null;
}
return cleanXSS(value);
}
@Override
public String[] getParameterValues(String parameter) {
String[] values = super.getParameterValues(parameter);
if (values == null) {
return null;
}
int count = values.length;
String[] encodedValues = new String[count];
for (int i = 0; i < count; i++) {
encodedValues[i] = cleanXSS(values[i]);
}
return encodedValues;
}
@Override
public Map<String, String[]> getParameterMap(){
Map<String, String[]> values=super.getParameterMap();
if (values == null) {
return null;
}
Map<String, String[]> result=new HashMap<>();
for(String key:values.keySet()){
String encodedKey=cleanXSS(key);
int count=values.get(key).length;
String[] encodedValues = new String[count];
for (int i = 0; i < count; i++){
encodedValues[i]=cleanXSS(values.get(key)[i]);
}
result.put(encodedKey,encodedValues);
}
return result;
}
/**
* 覆盖getHeader方法,将参数名和参数值都做xss过滤。
* 如果需要获得原始的值,则通过super.getHeaders(name)来获取
* getHeaderNames 也可能需要覆盖
*/
@Override
public String getHeader(String name) {
String value = super.getHeader(name);
if (value == null) {
return null;
}
return cleanXSS(value);
}
private String cleanXSS(String valueP) {
String value = valueP.replaceAll("<", "<").replaceAll(">", ">");
value = value.replaceAll("<", "& lt;").replaceAll(">", "& gt;");
value = value.replaceAll("\(", "& #40;").replaceAll("\)", "& #41;");
value = value.replaceAll("‘", "& #39;");
value = value.replaceAll("eval\((.*)\)", "");
value = value.replaceAll("[\"\‘][\s]*javascript:(.*)[\"\‘]", """");
value = value.replaceAll("script", "");
value = cleanSqlKeyWords(value);
return value;
}
private String cleanSqlKeyWords(String value) {
String paramValue = value;
for (String keyword : notAllowedKeyWords) {
if (paramValue.length() > keyword.length() + 3
&& (paramValue.contains(" "+keyword)||paramValue.contains(keyword+" ")||paramValue.contains(" "+keyword+" "))) {
paramValue = StringUtils.replace(paramValue, keyword, replacedString);
System.out.println(this.currentUrl + "已被过滤,因为参数中包含不允许sql的关键词(" + keyword
+ ")"+";参数:"+value+";过滤后的参数:"+paramValue);
}
}
return paramValue;
}
2.看到这里你就已经完成了一半了加油!接下来的事情很简单写个过滤器就over 。
package com.hrt.zxxc.fxspg.xss;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.module.SimpleModule;
import org.springframework.context.annotation.Bean;
import org.springframework.http.converter.json.Jackson2ObjectMapperBuilder;
import org.springframework.stereotype.Component;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/**
* @ClassName XssFilter2
* @Description TODO
* @Author liumingyu
* @Date 2020/2/4 15:45
* @Version 1.0
**/
@WebFilter
@Component
public class XssFilter3 implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse,
FilterChain filterChain) throws IOException, ServletException {
//获取请求数据
HttpServletRequest req = (HttpServletRequest) servletRequest;
//获取请求的url路径
String path = ((HttpServletRequest) servletRequest).getServletPath();
//声明要被忽略请求的数组
String[] exclusionsUrls = {".js", ".gif", ".jpg", ".jpeg", ".png", ".css", ".ico", "health", "uploadPic", "file", "savePrintTemp", "goods/create", "goods/edit", "goodsBatchImport", "goodsBatchExport","platformtestreport"};
//声明带有富文本的接口数组
String[] richTextUrls = {"addarticles", "editarticles", "advert"};
//第一种xss过滤
XssAndSqlHttpServletRequestWrapper XssAndSqlHttpServletRequestWrapper = new XssAndSqlHttpServletRequestWrapper(req);
//遍历忽略的请求数组,若该接口url为忽略的就调用原本的过滤器,不走xss过滤
for (String str : exclusionsUrls) {
if (path.contains(str)) {
filterChain.doFilter(servletRequest, servletResponse);
return;
}
}
//若为带有富文本的接口,走第一种xss过滤
for (String rtu : richTextUrls) {
if (path.contains(rtu)) {
filterChain.doFilter(XssAndSqlHttpServletRequestWrapper, servletResponse);
return;
}
}
//将请求放入XSS请求包装器中,返回过滤后的值
XssHttpServletRequestWrapper3 xssRequestWrapper3 = new XssHttpServletRequestWrapper3(req);
filterChain.doFilter(xssRequestWrapper3, servletResponse);
}
@Override
public void destroy() {
}
}
以上是关于Springboot项目快速实现过滤器功能的主要内容,如果未能解决你的问题,请参考以下文章