Java 8实战- Java 8基础知识
Posted Super_Leng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 8实战- Java 8基础知识相关的知识,希望对你有一定的参考价值。
文章目录
一、认识 Java 8
自1998年JDK 1.0(Java 1.0)发布以来,Java已经受到了学生、项目经理和程序员等一大批活跃用户的欢迎。这一语言极富活力,不断被用在大大小小的项目里。从Java 1.1(1997年) 一直到Java 7(2011年),Java通过增加新功能,不断得到良好的升级。Java 8则是在2014年3月发布的。那么,问题来了:为什么你应该关心Java 8?
我们的理由是,Java 8所做的改变,在许多方面比Java历史上任何一次改变都深远。而且好消息是,这些改变会让你编起程来更容易,用不着再写类似下面这种啰嗦的程序了(对inventory中的苹果按照重量进行排序):
Collections.sort(inventory, new Comparator<Apple>()
public int compare(Apple a1, Apple a2)
return a1.getWeight().compareTo(a2.getWeight());
);
在Java 8里面,你可以编写更为简洁的代码,这些代码读起来更接近问题的描述:
它念起来就是“给库存排序,比较苹果的重量”
inventory.sort(comparing(Apple::getWeight));
Java 8对硬件也有影响:平常我们用的CPU都是多核的——你的笔记本电脑或台式机上的处理器可能有四个CPU内核,甚至更多。但是,绝大多数现有的Java程序都只使用其中一个内核,其他三个都闲着,或只是用一小部分的处理能力来运行操作系统或杀毒程序。
在Java 8之前,专家们可能会告诉你,必须利用线程才能使用多个内核。问题是,线程用起来很难,也容易出现错误。从Java的演变路径来看,它一直致力于让并发编程更容易、出错更少。
Java 1.0里有线程和锁,甚至有一个内存模型——这是当时的最佳做法,但事实证明,不具备专门知识的项目团队很难可靠地使用这些基本模型。Java 5添加了工业级的构建模块,如线程池和并发集合。Java 7添加了分支/合并(fork/join)框架,使得并行变得更实用,但仍然很困难。而Java 8对并行有了一个更简单的新思路,不过你仍要遵循一些规则。
Java 8提供了一个新的API(称为“流”,Stream),它支持许多处理数据的并行操作,其思路和在数据库查询语言中的思路类似——用更高级的方式表达想要的东西,而由“实现”(在这里是Streams库)来选择最佳执行机制。这样就可以避免用synchronized编写代码,这一代码不仅容易出错,而且在多核CPU上执行所需的成本也比你想象的要高。
多核CPU的每个处理器内核都有独立的高速缓存。加锁需要这些高速缓存同步运行,然而这又需要在内核间进行较慢的缓存一致性协议通信。
从有点修正主义的角度来看,在Java 8中加入Streams可以看作把另外两项扩充加入Java 8的直接原因:1.把代码传递给方法的简洁方式(方法引用、Lambda)2.接口中的默认方法。
如果仅仅“把代码传递给方法”看作Streams的一个结果,那就低估了它在Java 8中的应用范围。它提供了一种新的方式,这种方式简洁地表达了行为参数化。
比方说,你想要写两个只有几行代码不同的方法,那现在你只需要把不同的那部分代码作为参数传递进去就可以了。采用这种编程技巧,代码会更短、更清晰,也比常用的复制粘贴更不容易出错。高手看到这里就会想,在Java 8之前可以用匿名类实现行为参数化呀——但是想想本章开头那个Java 8代码更加简洁的例子,代码本身就说明了它有多清晰!
Java 8里面将代码传递给方法的功能(同时也能够返回代码并将其包含在数据结构中)还让我们能够使用一整套新技巧,通常称为函数式编程。一言以蔽之,这种被函数式编程界称为函数的代码,可以被来回传递并加以组合,以产生强大的编程语汇。
二、Java 8编程概念
1. 流处理
第一个编程概念是流处理。介绍一下,流是一系列数据项,一次只生成一项。程序可以从输入流中一个一个读取数据项,然后以同样的方式将数据项写入输出流。一个程序的输出流很可能是另一个程序的输入流。
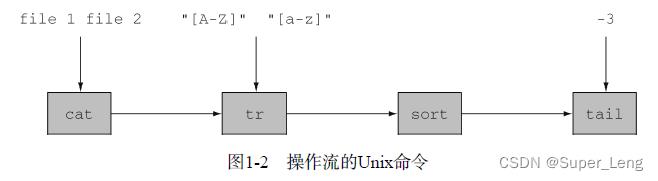
一个实际的例子是在Unix或Linux中,很多程序都从标准输入(Unix和C中的stdin,Java中的System.in)读取数据,然后把结果写入标准输出(Unix和C中的stdout,Java中的System.out)。首先我们来看一点点背景:Unix的cat命令会把两个文件连接起来创建一个流,tr会转换流中的字符,sort会对流中的行进行排序,而tail -3则给出流的最后三行。Unix命令行允许这些程序通过管道(|)连接在一起,比如:cat file1 file2 | tr “[A-Z]” “[a-z]” | sort | tail -3
会(假设file1和file2中每行都只有一个词)先把字母转换成小写字母,然后打印出按照词典排序出现在最后的三个单词。我们说sort把一个行流(有语言洁癖的人会说“字符流”,不过认为sort会对行排序比较简单)作为输入,产生了另一个行流(进行排序)作为输出,如图1-2所示。请注意在Unix中,命令(cat、tr、sort和tail)是同时执行的,这样sort就可以在cat或tr完成前先处理头几行。就像汽车组装流水线一样,汽车排队进入加工站,每个加工站会接收、修改汽车,然后将之传递给下一站做进一步的处理。尽管流水线实际上是一个序列,但不同加工站的运行一般是并行的。
基于这一思想,Java 8在java.util.stream中添加了一个Stream API;Stream就是一系列T类型的项目。你现在可以把它看成一种比较花哨的迭代器。Stream API的很多方法可以链接起来形成一个复杂的流水线,就像先前例子里面链接起来的Unix命令一样。
推动这种做法的关键在于,现在你可以在一个更高的抽象层次上写Java 8程序了:思路变成了把这样的流变成那样的流(就像写数据库查询语句时的那种思路),而不是一次只处理一个项目。另一个好处是,Java 8可以透明地把输入的不相关部分拿到几个CPU内核上去分别执行你的Stream操作流水线——这是几乎免费的并行,用不着去费劲搞Thread了。
2. 用行为参数化把代码传递给方法
Java 8中增加的另一个编程概念是通过API来传递代码的能力。这听起来实在太抽象了。在Unix的例子里,你可能想告诉sort命令使用自定义排序。虽然sort命令支持通过命令行参数来执行各种预定义类型的排序,比如倒序,但这毕竟是有限的。
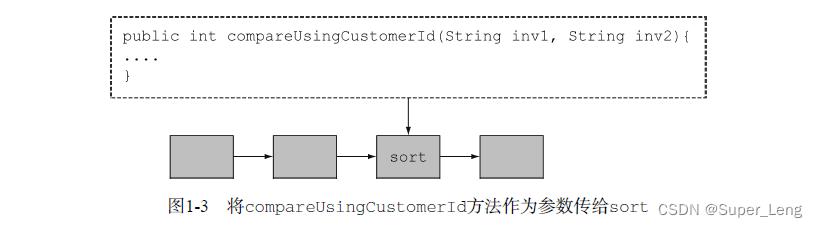
比方说,你有一堆发票代码,格式类似于2013UK0001、2014US0002……前四位数代表年份,接下来两个字母代表国家,最后四位是客户的代码。你可能想按照年份、客户代码,甚至国家来对发票进行排序。你真正想要的是,能够给sort命令一个参数让用户定义顺序:给sort命令传递一段独立代码。
那么,直接套在Java上,你是要让sort方法利用自定义的顺序进行比较。你可以写一个compareUsingCustomerId来比较两张发票的代码,但是在Java 8之前,你没法把这个方法传给另一个方法。你可以像本章开头时介绍的那样,创建一个Comparator对象,将之传递给sort方法,但这不但啰嗦,而且让“重复使用现有行为”的思想变得不那么清楚了。Java 8增加了把方法(你的代码)作为参数传递给另一个方法的能力。图1-3是基于图1-2画出的,它描绘了这种思路。我们把这一概念称为行为参数化。它的重要之处在哪儿呢?Stream API就是构建在通过传递代码使操作行为实现参数化的思想上的,当把compareUsingCustomerId传进去,你就把sort的行为参数化了。
3. 并行与共享的可变数据
第三个编程概念更隐晦一点,它来自我们前面讨论流处理能力时说的“几乎免费的并行”。你的行为必须能够同时对不同的输入安全地执行。一般情况下这就意味着,你写代码时不能访问共享的可变数据。这些函数有时被称为“纯函数”或“无副作用函数”或“无状态函数”。前面说的并行只有在假定你的代码的多个副本可以独立工作时才能进行。但如果要写入的是一个共享变量或对象,这就行不通了。
Java 8的流实现并行比Java现有的线程API更容易,因此,尽管可以使用synchronized来打破“不能有共享的可变数据”这一规则,但这相当于是在和整个体系作对,因为它使所有围绕这一规则做出的优化都失去意义了。在多个处理器内核之间使用synchronized,其代价往往比你预期的要大得多,因为同步迫使代码按照顺序执行,而这与并行处理的宗旨相悖。
这两个要点(没有共享的可变数据,将方法和函数即代码传递给其他方法的能力)是我们平常所说的函数式编程范式的基石。与此相反,在命令式编程范式中,你写的程序则是一系列改变状态的指令。“不能有共享的可变数据”的要求意味着,一个方法是可以通过它将参数值转换为结果的方式完全描述的;换句话说,它的行为就像一个数学函数,没有可见的副作用。
三、Java 中的函数
编程语言中的函数一词通常是指方法,尤其是静态方法;这是在数学函数,也就是没有副作用的函数之外的新含义。幸运的是,你将会看到,在Java 8谈到函数时,这两种用法几乎是一致的。
Java 8中新增了函数——值的一种新形式。它有助于使用流,有了它,Java 8可以进行多核处理器上的并行编程。我们首先来展示一下作为值的函数本身的有用之处。
想想Java程序可能操作的值吧。首先有原始值,比如42(int类型)和3.14(double类型)。其次,值可以是对象(更严格地说是对象的引用)。获得对象的唯一途径是利用new,也许是通过工厂方法或库函数实现的;对象引用指向类的一个实例。例子包括"abc"(String类型),new Integer(1111)(Integer类型),以及new HashMap<Integer,String>(100)的结果——它显然调用了HashMap的构造函数。甚至数组也是对象。那么有什么问题呢?
为了帮助回答这个问题,我们要注意到,编程语言的整个目的就在于操作值,要是按照历史上编程语言的传统,这些值因此被称为一等值(或一等公民,这个术语是从20世纪60年代美国民权运动中借用来的)。编程语言中的其他结构也许有助于我们表示值的结构,但在程序执行期间不能传递,因而是二等公民。前面所说的值是Java中的一等公民,但其他很多Java概念(如方法和类等)则是二等公民。用方法来定义类很不错,类还可以实例化来产生值,但方法和类本身都不是值。这又有什么关系呢?还真有,人们发现,在运行时传递方法能将方法变成一等公民。这在编程中非常有用,因此Java 8的设计者把这个功能加入到了Java中。顺便说一下,你可能会想,让类等其他二等公民也变成一等公民可能也是个好主意。有很多语言,如Smalltalk和javascript,都探索过这条路。
1. 方法和Lambda 作为一等公民
Scala和Groovy等语言的实践已经证明,让方法等概念作为一等值可以扩充程序员的工具库,从而让编程变得更容易。一旦程序员熟悉了这个强大的功能,他们就再也不愿意使用没有这一功能的语言了。因此,Java 8的设计者决定允许方法作为值,让编程更轻松。此外,让方法作为值也构成了其他若干Java 8功能(如Stream)的基础。
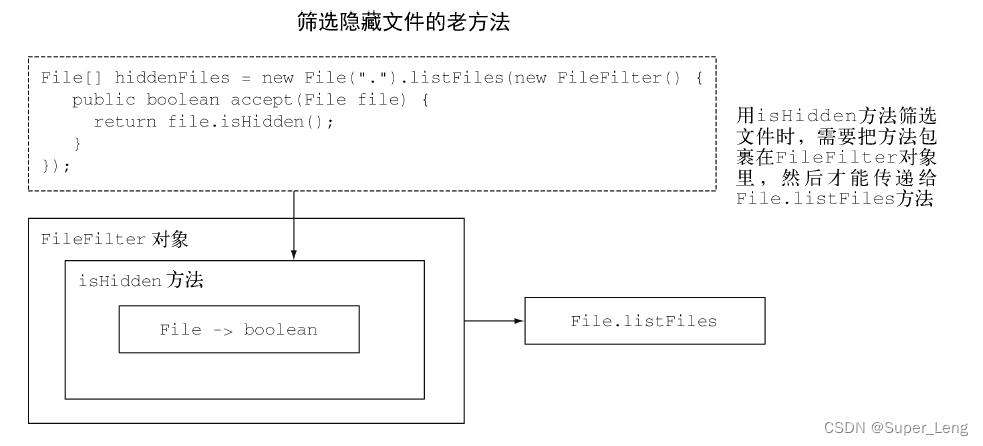
我们介绍的Java 8的第一个新功能是方法引用。比方说,你想要筛选一个目录中的所有隐藏文件。你需要编写一个方法,然后给它一个File,它就会告诉你文件是不是隐藏的。幸好,File类里面有一个叫作isHidden的方法。我们可以把它看作一个函数,接受一个File,返回一个布尔值。但要用它做筛选,你需要把它包在一个FileFilter对象里,然后传递给File.listFiles方法,如下所示:
File[] hiddenFiles = new File(".").listFiles(new FileFilter()
public boolean accept(File file)
// 筛选隐藏文件
return file.isHidden();
);
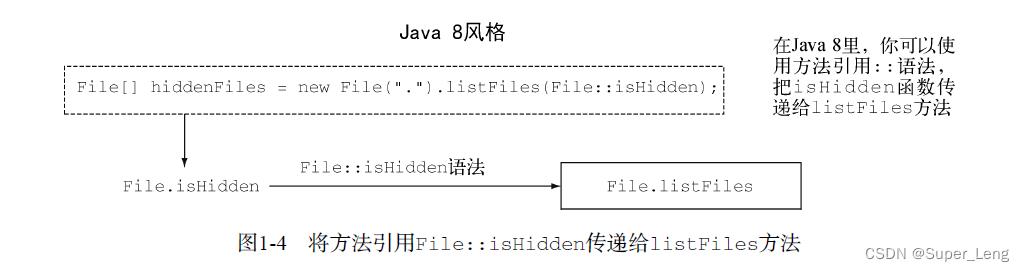
如今在Java 8里,你可以把代码重写成这个样子:
File[] hiddenFiles = new File(".").listFiles(File::isHidden);
你已经有了函数isHidden,因此只需用Java 8的方法引用::语法(即“把这个方法作为值”)将其传给listFiles方法;请注意,我们也开始用函数代表方法了。稍后我们会解释这个机制是如何工作的。一个好处是,你的代码现在读起来更接近问题的陈述了。方法不再是二等值了。与用对象引用传递对象类似(对象引用是用new创建的),在Java 8里写下File::isHidden的时候,你就创建了一个方法引用,你同样可以传递它。只要方法中有代码(方法中的可执行部分),那么用方法引用就可以传递代码。图1-4说明了这一概念。
老方法:
Java 8风格:
Lambda——匿名函数
除了允许(命名)函数成为一等值外,Java 8还体现了更广义的将函数作为值的思想,包括Lambda(最初是根据希腊字母λ命名的。虽然Java中不使用这个符号,名称还是被保留了下来)(或匿名函数)。比如,你现在可以写(int x) -> x + 1,表示“调用时给定参数x,就返回x + 1值的函数”。你可能会想这有什么必要呢?因为你可以在MyMathsUtils类里面定义一个add1方法,然后MyMathsUtils::add1嘛!确实是可以,但要是你没有方便的方法和类可用,新的Lambda语法更简洁。我们称使用这些概念的程序为函数式编程风格,这句话的意思是“编写把函数作为一等值来传递的程序”。
2. 传递代码:一个例子
假设你有一个Apple类,它有一个getColor方法,还有一个变量inventory保存着一个Apples的列表。你可能想要选出所有的绿苹果,并返回一个列表。通常我们用筛选(filter)一词来表达这个概念。在Java 8之前,你可能会写这样一个方法filterGreenApples:
public static List<Apple> filterGreenApples(List<Apple> inventory)
List<Apple> result = new ArrayList<>();
for (Apple apple: inventory)
if ("green".equals(apple.getColor()))
result.add(apple);
return result;
但是接下来,有人可能想要选出重的苹果,比如超过150克,于是你心情沉重地写了下面这个方法,甚至用了复制粘贴:
public static List<Apple> filterHeavyApples(List<Apple> inventory)
List<Apple> result = new ArrayList<>();
for (Apple apple: inventory)
if (apple.getWeight() > 150)
result.add(apple);
return result;
我们都知道软件工程中复制粘贴的危险——给一个做了更新和修正,却忘了另一个。嘿,这两个方法只有一行不同:if里面的那行条件。如果这两个方法之间的差异仅仅是接受的重量范围不同,那么你只要把接受的重量上下限作为参数传递给filter就行了,比如指定(150, 1000)来选出重的苹果(超过150克),或者指定(0, 80)来选出轻的苹果(低于80克)。
但是,我们前面提过了,Java 8会把条件代码作为参数传递进去,这样可以避免filter方法出现重复的代码。现在你可以写:
public static boolean isGreenApple(Apple apple)
return "green".equals(apple.getColor());
public static boolean isHeavyApple(Apple apple)
return apple.getWeight() > 150;
// 写出来是为了清晰(平常只要从java.util.function导入就可以了)
public interface Predicate<T>
boolean test(T t);
static List<Apple> filterApples(List<Apple> inventory, Predicate<Apple> p)
List<Apple> result = new ArrayList<>();
for (Apple apple: inventory)
if (p.test(apple))
result.add(apple);
return result;
要用它的话,你可以写:
filterApples(inventory, Apple::isGreenApple);
或者:
filterApples(inventory, Apple::isHeavyApple);
2.1 什么是谓词?
前面的代码传递了方法Apple::isGreenApple ( 它接受参数Apple 并返回一个boolean)给filterApples,后者则希望接受一个Predicate参数。谓词(predicate)在数学上常常用来代表一个类似函数的东西,它接受一个参数值,并返回true或false。你在后面会看到,Java 8也会允许你写Function<Apple,Boolean>——在学校学过函数却没学过谓词的读者对此可能更熟悉,但用Predicate是更标准的方式,效率也会更高一点儿,这避免了把boolean封装在Boolean里面。
3. 从传递方法到Lambda
把方法作为值来传递显然很有用,但要是为类似于isHeavyApple和isGreenApple这种可能只用一两次的短方法写一堆定义有点儿烦人。不过Java 8也解决了这个问题,它引入了一套新记法(匿名函数或Lambda),
让你可以写 filterApples(inventory, (Apple a) -> “green”.equals(a.getColor()) );
或者 filterApples(inventory, (Apple a) -> a.getWeight() > 150 );
甚至 filterApples(inventory, (Apple a) -> a.getWeight() < 80 || “brown”.equals(a.getColor()) );
所以,你甚至都不需要为只用一次的方法写定义;代码更干净、更清晰,因为你用不着去找自己到底传递了什么代码。但要是Lambda的长度多于几行(它的行为也不是一目了然)的话,那你还是应该用方法引用来指向一个有描述性名称的方法,而不是使用匿名的Lambda。你应该以代码的清晰度为准绳。
Java 8的设计师几乎可以就此打住了,要是没有多核CPU,可能他们真的就到此为止了。我们迄今为止谈到的函数式编程竟然如此强大,在后面你更会体会到这一点。本来,Java加上filter和几个相关的东西作为通用库方法就足以让人满意了
比如:
static <T> Collection<T> filter(Collection<T> c, Predicate<T> p);
这样你甚至都不需要写filterApples了,因为比如先前的调用:
filterApples(inventory, (Apple a) -> a.getWeight() > 150 );
就可以直接调用库方法filter:
filter(inventory, (Apple a) -> a.getWeight() > 150 );
但是,为了更好地利用并行,Java的设计师没有这么做。Java 8中有一整套新的类集合API——Stream,它有一套函数式程序员熟悉的、类似于filter的操作,比如map、reduce,还有在Collections和Streams之间做转换的方法。
四、流
1. 外部迭代与内部迭代
几乎每个Java应用都会制造和处理集合。但集合用起来并不总是那么理想。比方说,你需要从一个列表中筛选金额较高的交易,然后按货币分组。你需要写一大堆套路化的代码来实现这个数据处理命令,如下所示:
// 建立累积交易分组的Map
Map<Currency, List<Transaction>> transactionsByCurrencies = new HashMap<>();
// 遍历交易的List
for (Transaction transaction : transactions)
// 筛选金额较高的交易
if(transaction.getPrice() > 1000)
// 提取交易货币
Currency currency = transaction.getCurrency();
List<Transaction> transactionsForCurrency = transactionsByCurrencies.get(currency);
// 如果这个货币的分组Map是空的,那就建立一个
if (transactionsForCurrency == null)
transactionsForCurrency = new ArrayList<>();
transactionsByCurrencies.put(currency, transactionsForCurrency);
// 将当前遍历的交易添加到具有同一货币的交易List中
transactionsForCurrency.add(transaction);
此外,我们很难一眼看出来这些代码是做什么的,因为有好几个嵌套的控制流指令。有了Stream API,你现在可以这样解决这个问题了:
Map<Currency, List<Transaction>> transactionsByCurrencies =
transactions.stream()
.filter((Transaction t) -> t.getPrice() > 1000)
// 按货币分组
.collect(groupingBy(Transaction::getCurrency));
现在值得注意的是,和Collection API相比,Stream API处理数据的方式非常不同。用集合的话,你得自己去做迭代的过程。你得用for-each循环一个个去迭代元素,然后再处理元素。我们把这种数据迭代的方法称为外部迭代。相反,有了Stream API,你根本用不着操心循环的事情。数据处理完全是在库内部进行的。我们把这种思想叫作内部迭代。
使用集合的另一个头疼的地方是,想想看,要是你的交易量非常庞大,你要怎么处理这个巨大的列表呢?单个CPU根本搞不定这么大量的数据,但你很可能已经有了一台多核电脑。理想的情况下,你可能想让这些CPU内核共同分担处理工作,以缩短处理时间。理论上来说,要是你有八个核,那并行起来,处理数据的速度应该是单核的八倍。
多核
所有新的台式和笔记本电脑都是多核的。它们不是仅有一个CPU,而是有四个、八个,甚至更多CPU,通常称为内核(从某种意义上说,这个名字不太好。一块多核芯片上的每个核都是一个五脏俱全的CPU。但“多核CPU”的说法很流行,所以我们就用内核来指代各个CPU)。问题是,经典的Java程序只能利用其中一个核,其他核的处理能力都浪费了。类似地,很多公司利用计算集群(用高速网络连接起来的多台计算机)来高效处理海量数据。Java 8提供了新的编程风格,可以更好地利用这样的计算机。
Google的搜索引擎就是一个无法在单台计算机上运行的代码的例子。它要读取互联网上的每个页面并建立索引,将每个互联网网页上出现的每个词都映射到包含该词的网址上。然后,如果你用多个单词进行搜索,软件就可以快速利用索引,给你一个包含这些词的网页集合。想想看,你会如何在Java中实现这个算法,哪怕是比Google小的引擎也需要你利用计算机上所有的核。
2. 多线程并非易事
通过多线程代码来利用并行(使用先前Java版本中的Thread API)并非易事。你得换一种思路:线程可能会同时访问并更新共享变量。因此,如果没有协调好,数据可能会被意外改变。
传统上是利用synchronized关键字,但是要是用错了地方,就可能出现很多难以察觉的错误。Java 8基于Stream的并行提倡很少使用synchronized的函数式编程风格,它关注数据分块而不是协调访问
Java 8也用Stream API(java.util.stream)解决了这两个问题:集合处理时的套路和晦涩,以及难以利用多核。
这样设计的第一个原因是,有许多反复出现的数据处理模式,类似于前一节所说的filterApples或SQL等数据库查询语言里熟悉的操作,如果在库中有这些就会很方便:根据标准筛选数据(比如较重的苹果),提取数据(例如抽取列表中每个苹果的重量字段),或给数据分组(例如,将一个数字列表分组,奇数和偶数分别列表)等。
第二个原因是,这类操作常常可以并行化。例如,如图1-6所示,在两个CPU上筛选列表,可以让一个CPU处理列表的前一半,第二个CPU处理后一半,这称为分支步骤(1)。CPU随后对各自的半个列表做筛选(2)。最后(3),一个CPU会把两个结果合并起来(Google搜索这么快就与此紧密相关,当然他们用的CPU远远不止两个了)。
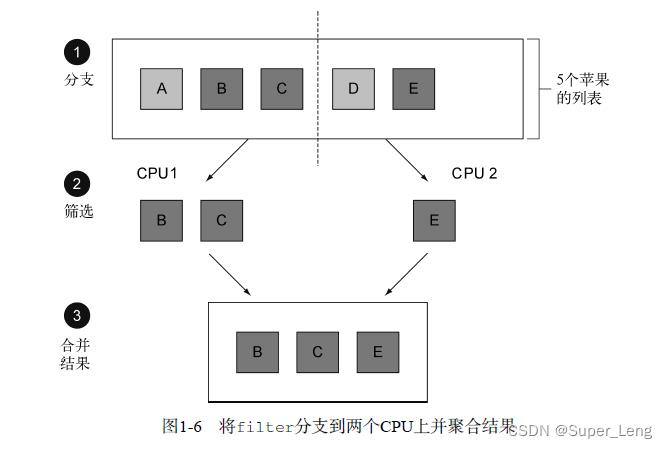
到这里,我们只是说新的Stream API和Java现有的集合API的行为差不多:它们都能够访问数据项目的序列。不过,现在最好记得,Collection主要是为了存储和访问数据,而Stream则主要用于描述对数据的计算。这里的关键点在于,Stream允许并提倡并行处理一个Stream中的元素。
虽然可能乍看上去有点儿怪,但筛选一个Collection(将上一节的filterApples应用在一个List上)的最快方法常常是将其转换为Stream,进行并行处理,然后再转换回List,下面举的串行和并行的例子都是如此。我们这里还只是说“几乎免费的并行”,让你稍微体验一下,如何利用Stream和Lambda表达式顺序或并行地从一个列表里筛选比较重的苹果。
顺序处理:
import static java.util.stream.Collectors.toList;
List<Apple> heavyApples = inventory.stream().filter((Apple a) -> a.getWeight() > 150).collect(toList());
并行处理:
import static java.util.stream.Collectors.toList;
List<Apple> heavyApples = inventory.parallelStream().filter((Apple a) -> a.getWeight() > 150).collect(toList());
在加入所有这些新玩意儿改进Java 的时候, Java 8 设计者发现的一个现实问题就是现有的接口也在改进。比如,Collections.sort方法真的应该属于List接口,但却从来没有放在后者里。理想的情况下,你会希望做list.sort(comparator),而不是Collections.sort(list, comparator)。这看起来无关紧要,但是在Java 8之前,你可能会更新一个接口,然后发现你把所有实现它的类也给更新了——简直是逻辑灾难!这个问题在Java 8里由默认方法解决了。
Java中的并行与无共享可变状态
大家都说Java里面并行很难,而且和synchronized相关的玩意儿都容易出问题。那Java 8里面有什么“灵丹妙药”呢?事实上有两个。首先,库会负责分块,即把大的流分成几个小的流,以便并行处理。其次,流提供的这个几乎免费的并行,只有在传递给filter之类的库方法的方法不会互动(比方说有可变的共享对象)时才能工作。但是其实这个限制对于程序员来说挺自然的,举个例子,我们的Apple::isGreenApple就是这样。确实,虽然函数式编程中的函数的主要意思是“把函数作为一等值”,不过它也常常隐含着第二层意思,即“执行时在元素之间无互动”。
五、默认方法
Java 8中加入默认方法主要是为了支持库设计师,让他们能够写出更容易改进的接口。这一方法很重要,因为你会在接口中遇到越来越多的默认方法,但由于真正需要编写默认方法的程序员相对较少,而且它们只是有助于程序改进,而不是用于编写任何具体的程序。
之前,我们给出了下面这段Java 8示例代码:
List<Apple> heavyApples1 = inventory.stream().filter((Apple a) -> a.getWeight() > 150).collect(toList());
List<Apple> heavyApples2 = inventory.parallelStream().filter((Apple a) -> a.getWeight() > 150).collect(toList());
但这里有个问题:在Java 8之前,List并没有stream或parallelStream方法,它实现的Collection接口也没有,因为当初还没有想到这些方法嘛!可没有这些方法,这些代码就不能编译。换作你自己的接口的话,最简单的解决方案就是让Java 8的设计者把stream方法加入Collection接口,并加入ArrayList类的实现。
可要是这样做,对用户来说就是噩梦了。有很多的替代集合框架都用Collection API实现了接口。但给接口加入一个新方法,意味着所有的实体类都必须为其提供一个实现。语言设计者没法控制Collections所有现有的实现,这下你就进退两难了:你如何改变已发布的接口而不破坏已有的实现呢?
Java 8的解决方法就是打破最后一环——接口如今可以包含实现类没有提供实现的方法签名了!那谁来实现它呢?缺失的方法主体随接口提供了(因此就有了默认实现),而不是由实现类提供。
这就给接口设计者提供了一个扩充接口的方式,而不会破坏现有的代码。Java 8在接口声明中使用新的default关键字来表示这一点。
例如,在Java 8里,你现在可以直接对List调用sort方法。它是用Java 8 List接口中如下所示的默认方法实现的,它会调用Collections.sort静态方法:
default void sort(Comparator<? super E> c)
Collections.sort(this, c);
这意味着List的任何实体类都不需要显式实现sort,而在以前的Java版本中,除非提供了sort的实现,否则这些实体类在重新编译时都会失败。
不过慢着,一个类可以实现多个接口,不是吗?那么,如果在好几个接口里有多个默认实现,是否意味着Java中有了某种形式的多重继承?是的,在某种程度上是这样。我们在后续会谈到,Java 8用一些限制来避免出现类似于C++中臭名昭著的菱形继承问题。
java笔试要点(java.sql包)
提供JAVA存取数据库能力的包是 ( )
A: java.sql B: java.awt C: java.lang D: java.swing
解析:
java(TM),那个TM,指的是Trade Mark,也就是商标,以前是sun公司持有,现在卖给Oracle了。
java.sql 包中包含用于以下方面的 API:
通过 DriverManager 实用程序建立与数据库的连接
DriverManager 类:建立与驱动程序的连接
SQLPermission 类:代码在 Security Manager(比如 applet)中运行时提供权限,试图通过 DriverManager 设置一个记录流
Driver 接口:提供用来注册和连接基于 JDBC 技术(“JDBC驱动程序”)的驱动程序的 API,通常仅由 DriverManager 类使用
DriverPropertyInfo 类:提供 JDBC 驱动程序的属性,不是供一般用户使用的向数据库发送 SQL 语句
Statement:用于发送基本 SQL 语句
PreparedStatement:用于发送准备好的语句或基本 SQL 语句(派生自 Statement)
CallableStatement:用于调用数据库存储过程(派生自 PreparedStatement)
Connection 接口:提供创建语句以及管理连接及其属性的方法
Savepoint:在事务中提供保存点获取和更新查询的结果ResultSet 接口SQL 类型到 Java 编程语言中的类和接口的标准映射关系
Array 接口:SQL ARRAY 的映射关系
Blob 接口:SQL BLOB 的映射关系
Clob 接口:SQL CLOB 的映射关系
Date 类:SQL DATE 的映射关系
NClob 接口:SQL NCLOB 的映射关系
Ref 接口:SQL REF 的映射关系
RowId 接口:SQL ROWID 的映射关系
Struct 接口:SQL STRUCT 的映射关系
SQLXML 接口:SQL XML 的映射关系
Time 类:SQL TIME 的映射关系
Timestamp 类:SQL TIMESTAMP 的映射关系
Types 类:提供用于 SQL 类型的常量自定义映射 SQL 用户定义类型 (UDT) 到 Java 编程语言中的类
SQLData 接口:指定 UDT 到此类的一个实例的映射关系
SQLInput 接口:提供用来从流中读取 UDT 属性的方法
SQLOutput 接口:提供用来将 UDT 属性写回流中的方法元数据
DatabaseMetaData 接口:提供有关数据库的信息
ResultSetMetaData 接口:提供有关 ResultSet 对象的列的信息
ParameterMetaData 接口:提供有关 PreparedStatement 命令的参数的信息异常
SQLException:由大多数方法在访问数据出问题时抛出,以及因为其他原因由其他一些方法抛出
SQLWarning:为了指示一个警告而抛出
DataTruncation:为了指示数据可能已经被截断而抛出
BatchUpdateException:为了指示并不是批量更新中的所有命令都成功执行而抛出


以上是关于Java 8实战- Java 8基础知识的主要内容,如果未能解决你的问题,请参考以下文章