MySQL缓存策略详解
Posted Lion Long
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL缓存策略详解相关的知识,希望对你有一定的参考价值。
前提:读多写少,单个主节点能支撑项目数据量;数据的主要依据是mysql。
一、MySQL缓存方案目的分析
mysql 有自己缓冲层,它的作用也是用来缓存热点数据,这些数据包括索引、记录等。mysql 缓冲层是从自身出发,跟具体的业务无关。这里的缓冲策略主要是 lru。
mysql 数据主要存储在磁盘当中,适合大量重要数据的存储;磁盘当中的数据一般是远大于内存当中的数据。
一般业务场景的关系型数据库(mysql)是作为主要数据库的。
1.1、缓存层的作用
MySQL缓存方案用来缓存用户定义的热点数据 ,用户直接从缓存获取热点数据,降低数据库的读写压力。
1.2、缓存层选择
缓存数据库可以选用 redis,memcached;它们所有数据都存储在内存当中,当然也可以将内存当中的数据持久化到磁盘当中。
1.3、场景分析
(1)内存访问速度是磁盘访问速度10W倍,访问磁盘的速度比较慢,尽量使获取数据是从内存中获取。
(2)读的需求远远大于写的需求。主要解决读的性能;因为写没必要优化,必须让数据正确的落盘。如果写性能出现问题,那么请使用横向扩展集群方式来解决。
(3)MySQL自身缓冲层跟业务无关。由于 mysql 的缓冲层不由用户来控制,也就是不能由用户来控制缓存具体数据。
(4)MySQL作为项目主要数据库,便于统计分析。项目中需要存储的数据应该远大于内存的容量,同时需要进行数据统计分析,所以数据存储获取的依据应该是关系型数据库。
(5)缓存数据库作为辅助数据库,存放热点数据。缓存数据库可以存储用户自定义的热点数据。
二、提升MySQL访问性能的方式
(1)读写分离。
(2)连接池。
(3)异步连接。
(4)预处理。
(5)更换存储引擎。
(6)分库分表。(淘汰的技术)
(7)mycat。(淘汰的技术)
(8)tidb。
2.1、MySQL主从复制
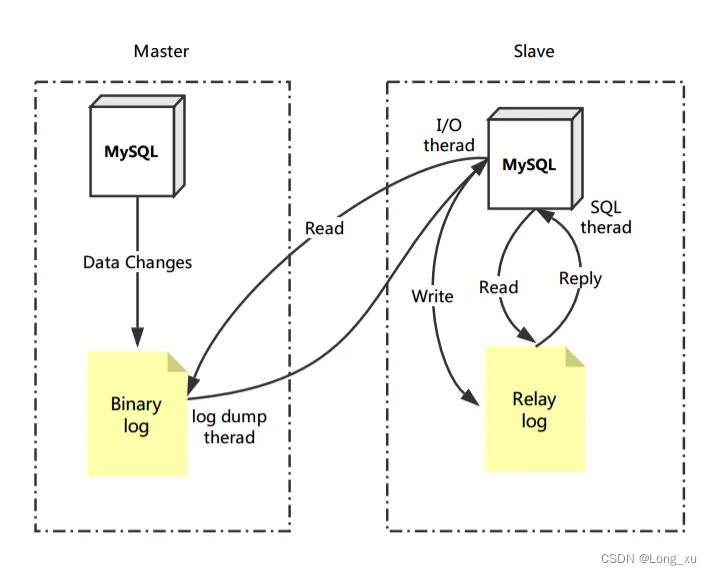
- 主库更新事件 ( update、insert、delete ) 通过 io-thread写到 binlog。
- 从库请求读取 binlog,通过 io-thread 写入从库本地 relaylog(中继日志)。
- 从库通过 sql-thread 读取 relay-log,并把更新事件在从库中重放(replay)一遍。
复制流程:
- Slave 上面的 IO 线程连接上 Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容。
- Master 接收到来自 Slave 的 IO 线程的请求后,负责复制的IO 线程会根据请求信息读取日志指定位置之后的日志信息,返回给 Slave 的 IO 线程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息已经到 Master 端的 binlog 文件的名称以及 binlog 的位置。
- Slave 的 IO 线程接收到信息后,将接收到的日志内容依次添加到 Slave 端的 relay-log 文件的最末端,并将读取到的
Master 端的 binlog 的文件名和位置记录到master-info 文件中,以便在下一次读取的时候能够清楚的告诉 Master 从何
处开始读取日志。 - Slave 的 sql 进程检测到 relay-log 中新增加了内容后,会马上解析 relay-log 的内容成为在 Master 端真实执行时候的那
些可执行的内容,并在自身执行。
由于MySQL的主从复制是异步的,所以同一时刻主数据库和从数据库的数据可能存在不一致的现象,这就造成可能从数据库中读取的数据不是最新的。
2.2、读写分离
读写分离会设置多个从数据库,从数据库可能会在多个机器中。
写操作依然在主数据库中,主数据库提供数据的主要依据。
读写分离通过设置多个从数据库解决读压力。
读写分离主要依据MySQL的主从复制原理,因为MySQL的主从复制是异步复制的,所以读写分离只能保证数据的最终一致性,不能保证实时一致性。
如果读操作有强一致性要求,那么需要读操作去读主数据库。
2.3、连接池
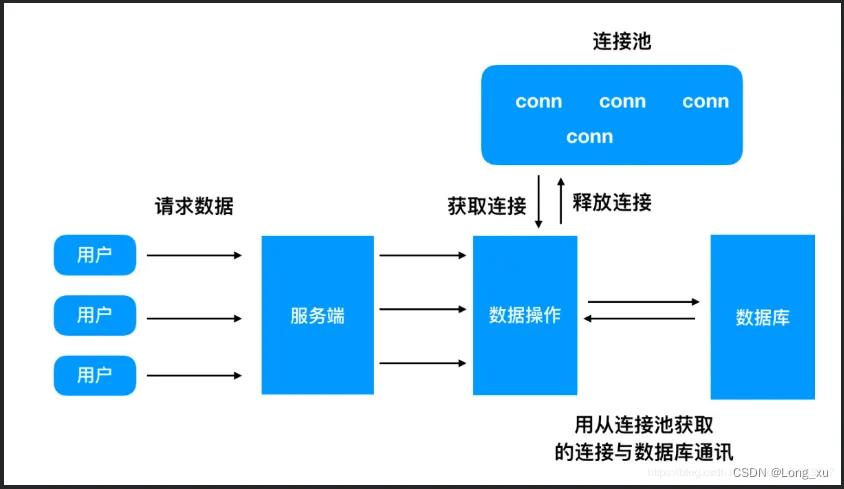
连接池的定义:在服务端当中创建多个与数据库的连接线程。
解决的问题:并发提升数据库访问性能;同时复用连接,避免连接建立、断开依据安全验证的开销。
原理:利用MySQL的网络模型创建多个连接,每个连接复用去出路SQL语句。值得注意的是,如果发送一个事务(多条SQL语句),这个事务必须要在一个连接里面完成。
2.4、异步连接
在服务端创建一个连接,针对这个连接采用非阻塞IO。这种方式可以节省网络传输时间。
三、redis作为主数据库的常用方法
- 以redis为主,在redis中读写数据,MySQL作为数据备份,过程中可能需要分布式消息队列(kafka)进行异步同步。这种方式性能最高,但安全性较差。仅适合小项目。工程中要会在效率和安全直接做权衡。
- 针对redis持久化较差的情况,最早使用leveldb伪装成从数据库,不断从redis中获取数据来实时持久化。
随着技术提升,leveldb的方式被淘汰,使用了更完善的pika方式。pika内部使用的rocksdb,支持redis协议。
四、缓存方案
4.1、缓存和MySQL一致性状态分析
没有缓冲层之前,对数据的读写都是基于 mysql;所以不存在同步问题;这句话也不是必然,比如读写分离就存在同步问题(数据一致性问题)。
引入缓冲层后,对数据的获取需要分别操作缓存数据库和mysql,那么这个时候数据可能存在以下状态:
- mysql 有,缓存无。
- mysql 无,缓存有。
- 都有,但数据不一致。
- 都有,数据一致。
- 都没有。