Python 连接clickhouse数据库以及新建表结构,csv导入数据
Posted 水w
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 连接clickhouse数据库以及新建表结构,csv导入数据相关的知识,希望对你有一定的参考价值。
目录
三、DBeaver 连接clickhouse 用csv文件导入数据
ClickHouse是近年来备受关注的开源列式数据库(DBMS),主要用于数据联机分析(OLAP)领域,于2016年开源。
一、Python 连接clickhouse数据库
◼ clickhouse对外的接口协议通常有两种形式:
- 常规的http协议,java的jdbc就采用这种方式,端口一般是8123;
- 面向python的tcp协议,端口号通常为9000(对,是“通常”)。
端口问题,HTTP协议(默认端口8123);TCP (Native)协议(默认端口号为9000),Python里的clickhouse_driver用的tcp端口9000,DBeaver使用的是HTTP协议所以可以使用8123端口。
◼ 代码实现部分:
(1)我们首先需要安装第三方库clickhouse_driver,

(2)完整代码:使用clickhouse_driver 包中的Client类,其中需要修改的参数有host,user,password,
from clickhouse_driver import Client
client = Client(host='127.0.0.1',port='9000',user=clickhouse_user ,password=clickhouse_pwd)
sql = 'select * from db_name.tb_name limit 0, 1000'
ans = client.execute(sql)

二、使用客户端工具DBeaver连接clickhouse
前提:Clickhouse客户端工具为dbeaver,首先需要安装连接工具Dbeaver。
Dbeaver安装教程地址:DBeaver安装与使用教程(超详细安装与使用教程)_多喝清晨的粥的博客-CSDN博客_dbeaver安装配置
(1)打开Dbeaver,通过操作界面菜单中“数据库”创建配置新连接,如下图所示,选择并下载ClickHouse驱动(默认不带驱动),

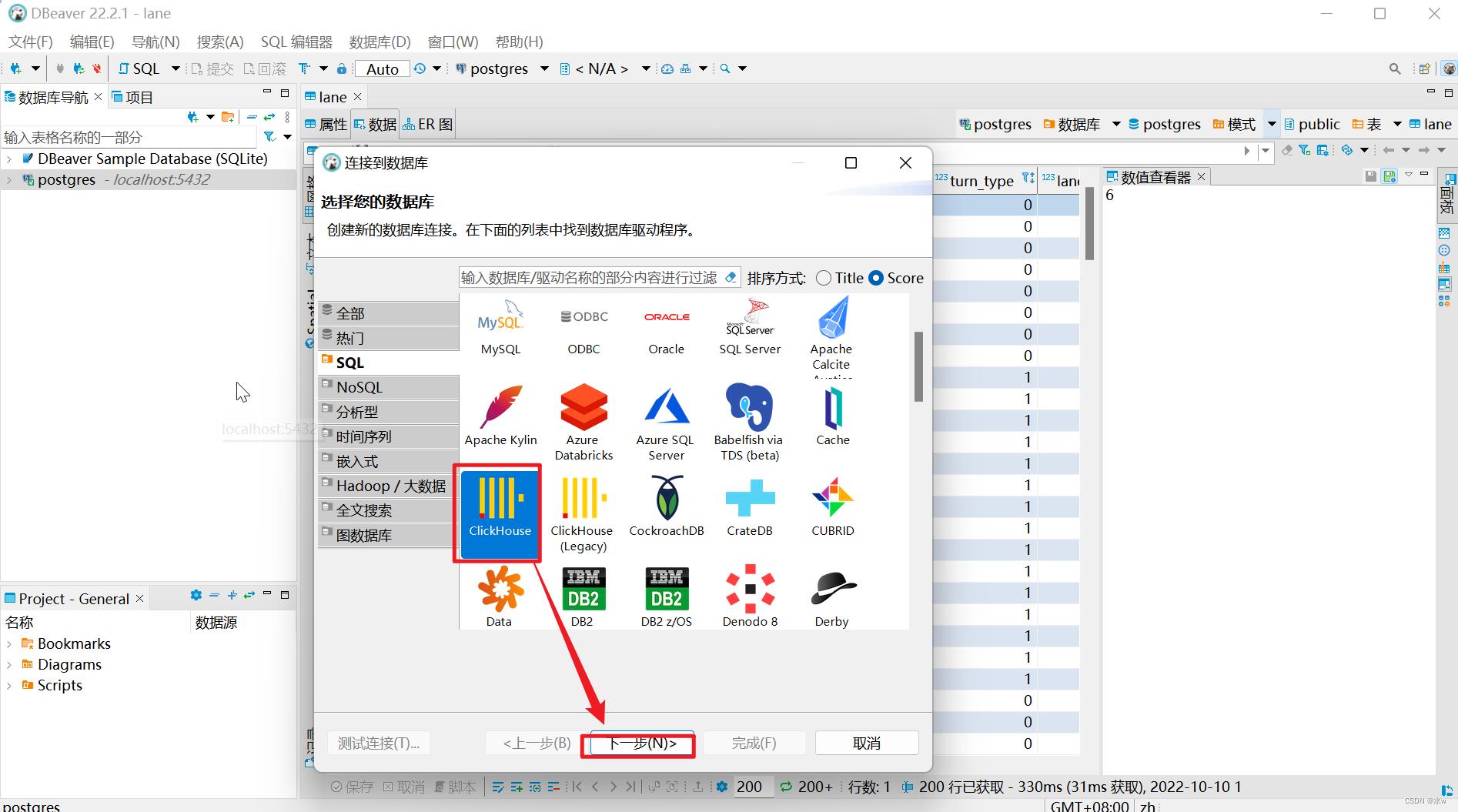
(2)填写基础配置
DBeaver配置是基于Jdbc方式,一般默认URL和端口如下:
jdbc:clickhouse://192.168.17.61:8123
如下图所示。在是用DBeaver连接Clickhouse做查询时,有时候会出现连接或查询超时的情况,这个时候可以在连接的参数中添加设置socket_timeout参数来解决问题。
jdbc:clickhouse://host:port[/database]?socket_timeout=600000

(3)测试连接,提示未安装驱动
到了这一步,说明连接配置信息填写完成,在弹出来的地方选择下载按钮,等它全部下载完驱动后即可测试连接。
如下图所示,开始下载驱动文件:
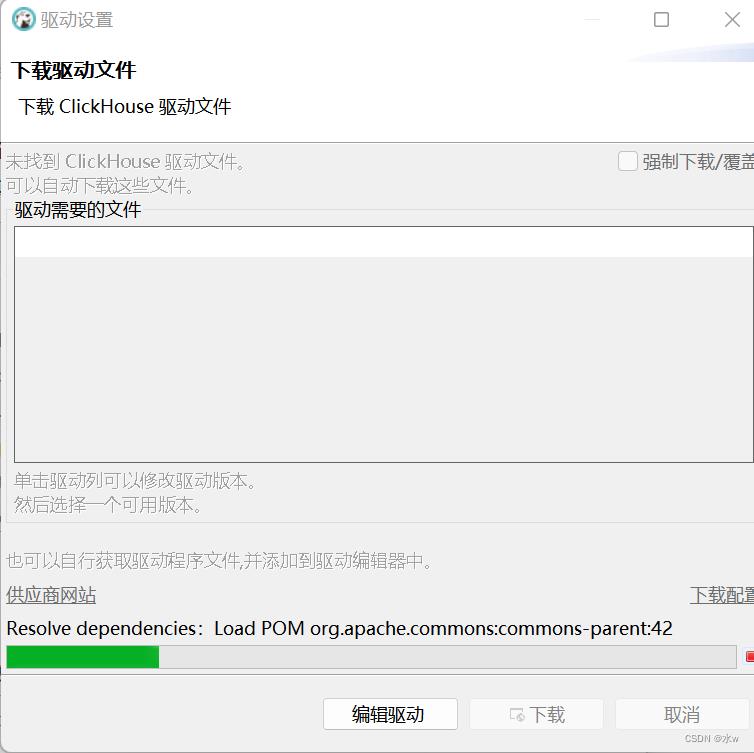

点击“下载”,
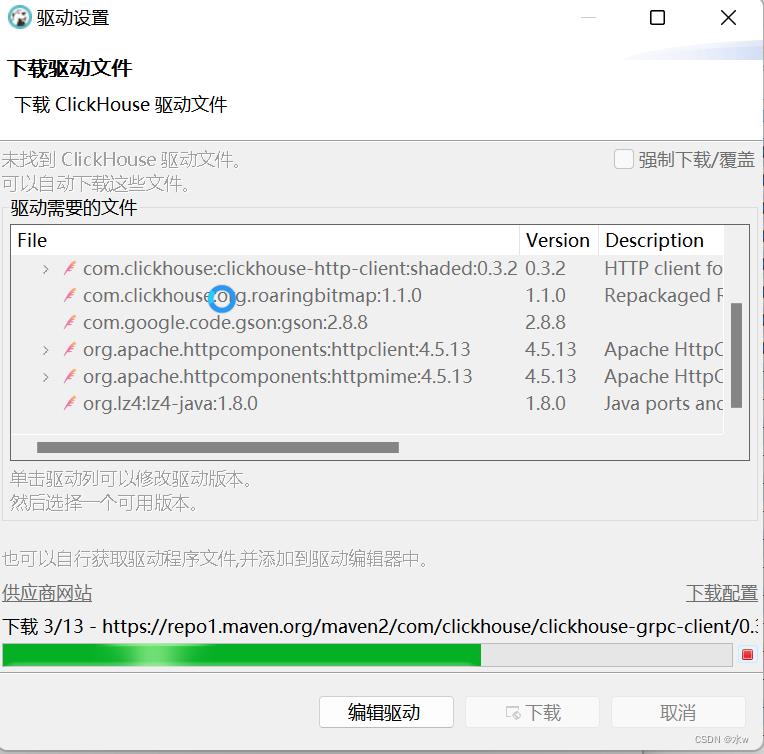
等待下载完成,
(4)再次测试连接,连接成功,

可以看到已经成功连接到了Clickhouse。

◼ 新建clickhouse表
(1)右击,选择“新建列”,进行创建表,

(2)或者使用代码进行创建表,
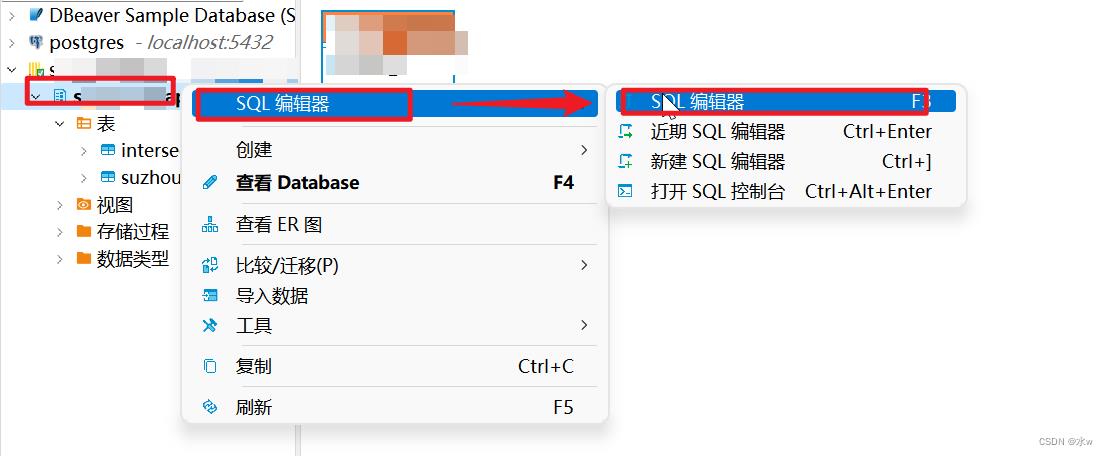
在sql编辑器中写入想要创建的表结构代码,
CREATE TABLE table_name (
node_id Int128,
node_name VARCHAR(100),
ll Int16,
ink VARCHAR(500),
onk VARCHAR(500),
fne VARCHAR(500),
tne VARCHAR(500)
) Engine = MergeTree()
ORDER BY node_id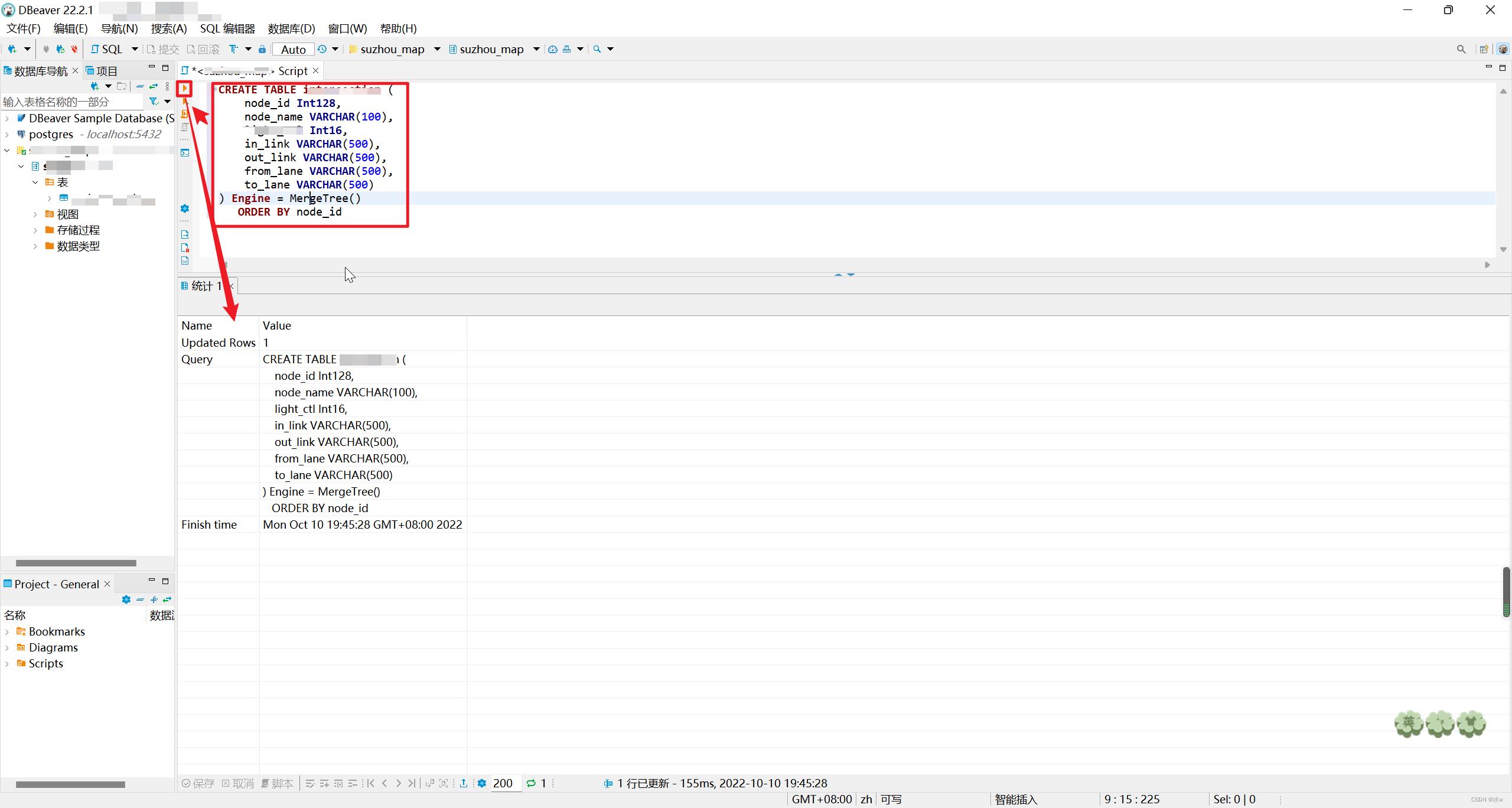
这样表就创建好了。
三、DBeaver 连接clickhouse 用csv文件导入数据
◼ 导入方式:
(1)先再需要导入的数据表中 插入几条数据 然后 导出 csv 格式的数据。【目的是为了查看导出的cxv 的数据是是什么格式, 我们导入也按照这个格式导入】


(2)再导出的表格中 加入我们需要导入的数据,格式和导出的数据格式保持一致。

(3)然后 通过csv 的方式导入数据到数据库表。
方法一:使用DBeaver自带导入数据功能;
右击需要导入csv文件的表,选择“导入数据”,依次进行一下步骤,




导入数据成功了。
方法二:具体方式如下:
- 首先将待导入的csv数据表传输到clickhouse所在的服务器;
- 在数据库中提前建好表,和等待导入数据匹配;
- 在客户端输入以下命令:
clickhouse-client --databse="testdb" --query="INSERT INTO testdb.TEST_table FORMAT CSV" < /dataset/data.csv若出现问题,可以试一下 将FORMAT CSV 改为 FORMAT CSVWithNames
解决问题:数据导入之后,出现中文乱码。
解决方法:将csv 表格文件用记事本打开 另存为的方式 保存新的文件 ,编码格式选择为为UTF-8 然后保存。 然后从新的修改编码格式之后的文件导入数据库表格, 中文乱码的问题就解决了。
Clickhouse Alter操作造成zk连接丢失的问题分析
参考技术A 业务方数据在出现错误后需要重跑数据,由于业务方没有使用MergeTree的折叠表,需要删除旧的数据后,再重新跑数据写入新的正确的数据。之前这种模式一直运转的比较好,没有出现过问题,不过近期发现,对该表发起Alter语句时,出现了ZK Connection Loss的错误,但是对其他的表发起Alter语句没有出现相同的错误。
本文主要分析一下定位问题的过程以及确定问题所在,也希望大家就该问题进行讨论提供更好的解决方案。
Clickhouse版本:20.9.3.45
表结构:
Alter语句以及响应的报错信息:
首先查看了一下clickhouse的错误日志,错误日志中有相关的堆栈信息
再查看了一下zk的错误日志
然后大致对比了一下系统的表的大小,目前出问题的表是最大的。
从上面可以看出表的数据分片很多。
分析ZK的日志发现,ZK认为客户端发送的消息格式不正确,从而主动断开了clickhouse的连接。从clickhouse的异常日志有可以看出正在执行zk操作时出现了连接断开的错误。
现在我们从代码层面去看看问题的根因,当clickhouse执行alter操作时,如果对应的mutation如果涉及到分片数据的变更时,就需要对分片进行锁定,而分片的锁定操作是在对应的分片对应的zk子目录下面创建一个临时节点,如下面代码所示:
clickhouse在zk的访问中,采用了大量批量操作,在上面的分片锁定操作中,它针对所有影响到的分片的锁定批量一次性提交命令到zk中,而zk的传输使用了jute,jute缺省最大的包大小为1M,具体细节可以参考一下关于zookeeper写入数据超过1M大小的踩坑记。
这里clickhouse的问题在于它没有做分包,而是对所有影响的分片合并请求后,批量向zk发起请求,从而造成了超过zk最大的传输包大小,从而造成连接断开。
为什么这里需要一次性的批量提交呢?具体的原因有朋友了解的可以分享一下,我理解可能clickhouse需要做类似事务级别的保证。
知道了问题的根因首先考虑到增加zk的jute缺省的最大包大小,zookeeper本身,我们可以在配置上实现。但是我们查看了一下clickhouse的zk配置相关参数,能够调整的主要是ip、port和会话时长,没有看到jute大小的控制参数,所以这条路基本上行不通,经过只修改zk的参数重启后,测试也发现不能成功。
控制Alter DELETE影响的数据范围,从原来的Alter语句来看我们已经制定了时间的范围,但是看起来Clickhouse不会主动根据条件来做分区裁剪。查看源码也发现没有这块逻辑,但是从最新的clickhouse的文档中,我们可以看到Delete语句支持分区操作。
以上是关于Python 连接clickhouse数据库以及新建表结构,csv导入数据的主要内容,如果未能解决你的问题,请参考以下文章