TDSQL的安装教程(低配体验)
Posted 六眼飞鱼、
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TDSQL的安装教程(低配体验)相关的知识,希望对你有一定的参考价值。
一、了解TDSQL
tdsql腾讯云文档
TDSQL-C mysql 版(TDSQL-C for MySQL)是腾讯云自研的新一代云原生关系型数据库。融合了传统数据库、云计算与新硬件技术的优势,为用户提供具备极致弹性、高性能、海量存储、安全可靠的数据库服务。TDSQL-C MySQL 版100%兼容 MySQL 5.7、8.0。实现超百万级 QPS 的高吞吐,最高 PB 级智能存储,保障数据安全可靠。
TDSQL-C MySQL 版采用存储和计算分离的架构,所有计算节点共享一份数据,提供秒级的配置升降级、秒级的故障恢复,单节点可支持百万级 QPS,自动维护数据和备份,最高以GB/秒的速度并行回档。
TDSQL-C MySQL 版既融合了商业数据库稳定可靠、高性能、可扩展的特征,又具有开源云数据库简单开放、高效迭代的优势。TDSQL-C MySQL 版引擎完全兼容原生 MySQL,您可以在不修改应用程序任何代码和配置的情况下,将 MySQL 数据库迁移至 TDSQL-C MySQL 版引擎。
腾讯云私有文档:这个文档有详细的教程,是官方的说明安装文档。可以自行去看一下,我看网上都没有提到。 里面的内容如下:
感兴趣可以自行了解。
可以看到tdsql-mysql是完全兼容mysql的数据库,所有的操作都是mysql一样,只不过是多了分布式的集群化,拥有的更多的功能更加高效。
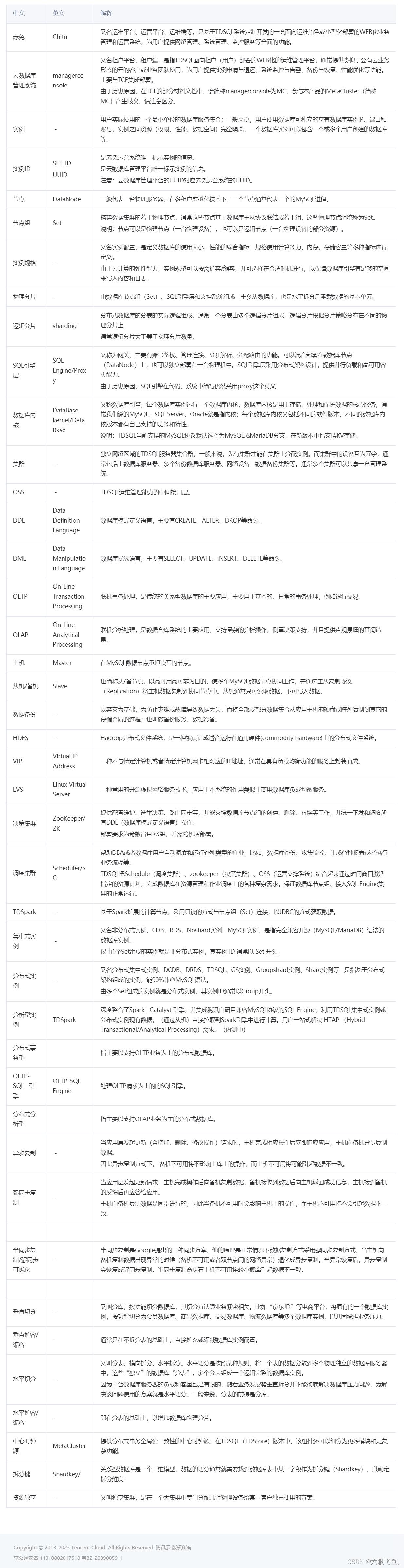
术语表
机器准备
部署方式请参考官方的手册。
由于本地环境资源不足,这里构建出三个虚拟机,使用三台虚拟机来搭建一个最小的TDSQL集群(2台用于DB、1台用于调度和运营体系部署)。
备注:虚拟机环境均为:
2核+AMD Ryzen 5 PRO 4650U+CentOS7+2G内存,配置可以说是极低(所以可选的组件本文就不安装了)。
三台虚拟机的配置如下:
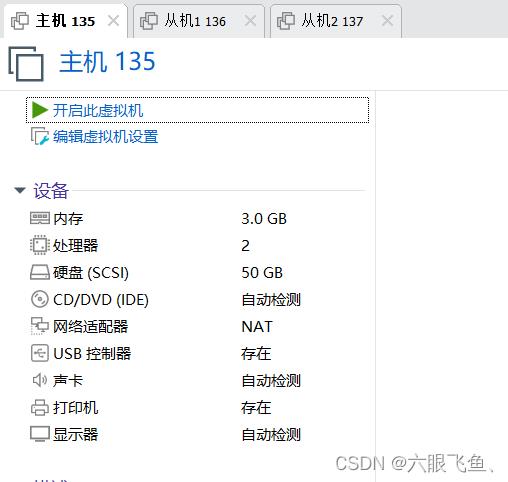
三台机器的规划如下:
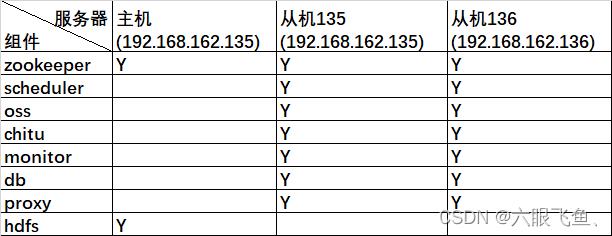
虚拟机系统推荐centos7
配置环境
1.下载安装包
终端执行命令下载文件
wget https://tdsql1031730-1300276124.cos.ap-beijing.myqcloud.com/tdsql_10.3.17.3.0.zip
解压文件
unzip tdsql_10.3.17.3.0.zip
2.配置文件
2.1免密配置
#以下指令都在主机执行 这里直接回撤就行不需要设置
ssh-keygen -t rsa
#这里需要输入从机1的密码
ssh-copy-id 192.168.162.136
#这里需要输入从机2的密码
ssh-copy-id 192.168.162.137
免密登录主要是安装的时候脚本自动连接从机安装需要的组件
2.2 修改 tdsql_hosts文件
文件在tdsql_install文件夹下面
# 填入所有机器的地址(包括主控机)
# 用于环境检测和初始化配置
# 同一个标签组内的ip地址不要重复,一个ip一行
# 序号从1递增,比如只有2台机器,那么序号保留tdsql_mac1 tdsql_mac2
# 后续如果有扩容,新扩容的机器也需要在这里补上
[tdsql_allmacforcheck]
tdsql_mac1 ansible_ssh_host=192.168.162.135
tdsql_mac2 ansible_ssh_host=192.168.162.136
tdsql_mac3 ansible_ssh_host=192.168.162.137
# zookeeper机器ip地址
# 数量只能是1、3、5, 正式环境建议3台或者5台
# 如果是使用自己已有的zk集群,这里同样要填写正确的zk地址
[tdsql_zk]
tdsql_zk1 ansible_ssh_host=192.168.162.135
tdsql_zk2 ansible_ssh_host=192.168.162.136
tdsql_zk3 ansible_ssh_host=192.168.162.137
# scheduler机器的ip地址,正式环境建议2个
[tdsql_scheduler]
tdsql_scheduler1 ansible_ssh_host=192.168.162.136
tdsql_scheduler2 ansible_ssh_host=192.168.162.137
# oss机器的ip地址, 正式环境建议2个
[tdsql_oss]
tdsql_oss1 ansible_ssh_host=192.168.162.136
tdsql_oss2 ansible_ssh_host=192.168.162.137
# 赤兔机器的ip地址, 正式环境建议2个
[tdsql_chitu]
tdsql_chitu1 ansible_ssh_host=192.168.162.136
tdsql_chitu2 ansible_ssh_host=192.168.162.137
# 监控采集模块的IP地址,正式环境建议2个
[tdsql_monitor]
tdsql_monitor1 ansible_ssh_host=192.168.162.136
tdsql_monitor2 ansible_ssh_host=192.168.162.137
# db机器地址
# 有多少台就填多少个ip地址
# 注意tdsql_db序号逐个递增,不要跳跃
[tdsql_db]
tdsql_db1 ansible_ssh_host=192.168.162.136
tdsql_db2 ansible_ssh_host=192.168.162.137
# proxy机器地址
[tdsql_proxy]
tdsql_proxy1 ansible_ssh_host=192.168.162.136
tdsql_proxy2 ansible_ssh_host=192.168.162.137
# hdfs机器地址
# 机器数量只能是1台或者3台
# 如果单节点部署,则只保留tdsql_hdfs1,其他删除
# 正式环境建议高可用部署,初始安装数量只能3台
[tdsql_hdfs]
tdsql_hdfs1 ansible_ssh_host=192.168.162.135
# lvs机器地址,数量固定2台
[tdsql_lvs]
tdsql_lvs1 ansible_ssh_host=172.16.16.30
tdsql_lvs2 ansible_ssh_host=172.16.16.48
# kafka机器地址,数量固定3台
[tdsql_kafka]
tdsql_kafka1 ansible_ssh_host=172.16.16.47
tdsql_kafka2 ansible_ssh_host=172.16.16.30
tdsql_kafka3 ansible_ssh_host=172.16.16.48
# 多源同步消费者服务ip地址,数量固定1台
[tdsql_consumer]
tdsql_consumer1 ansible_ssh_host=172.16.16.30
# es机器地址
[tdsql_es]
tdsql_es1 ansible_ssh_host=192.168.162.135
[tdsql_mc]
tdsql_mc1 ansible_ssh_host=192.168.162.135
tdsql_mc2 ansible_ssh_host=192.168.162.136
tdsql_mc3 ansible_ssh_host=192.168.162.137
#这里如果不需要可以不配置
[tdsql_newdb]
tdsql_newdb1 ansible_ssh_host=1.1.1.1
tdsql_newdb2 ansible_ssh_host=2.2.2.2
tdsql_newdb3 ansible_ssh_host=3.3.3.3
#这里如果不需要可以不配置
[tdsql_ansible_test]
tdsql_ansible_test1 ansible_ssh_host=1.1.1.1
tdsql_ansible_test2 ansible_ssh_host=2.2.2.2
tdsql_ansible_test3 ansible_ssh_host=3.3.3.3
按照上面规划的填写即可 这里的ip需要换成你自己的ip
2.2 修改group_vars配置(ansible变量)
文件在tdsql_install/group_vars/all文件
---
# scheduler,oss机器网卡
tdsql_sche_netif: ens33
# 操作系统账号tdsql的明文密码
# 如果有规划要部署两个集群做DCN同步, 则这两个集群的tdsql密码要一致
tdsql_os_pass: 12345
# tdsql在zk上的根路径, 保持默认不允许修改
tdsql_zk_rootdir: /tdsqlzk
# zk机器的域名配置, 会写入各配置文件, 并将域名配置到/etc/hosts中
# 正式环境必须用机房或者地区的关键字, 有意义的关键字来命名
# 如果部署多套TDSQL集群, 则名字需要唯一
# 例如: 深圳机房zk的域名可以定义为tdsql_sz_zk
tdsql_zk_domain_name: tdsql_test_zk
# zk端口配置, 保持默认不要改,如果是自建的zk, 则和已有zk端口保持一致
tdsql_zk_clientport: 2118
tdsql_zk_serverport1: 2338
tdsql_zk_serverport2: 2558
# 赤兔监控库配置, 赤兔初始化完成后需要将监控库信息在这里更新
tdsql_metadb_ip: 192.168.162.135
tdsql_metadb_port: 15001
tdsql_metadb_ip_bak: 192.168.162.135
tdsql_metadb_port_bak: 15001
tdsql_metadb_user: hanlon
tdsql_metadb_password: 123456
# hdfs机器的ssh端口
tdsql_hdfs_ssh: 22
# hdfs数据目录, 正式环境要求mount挂载比较大的数据盘
tdsql_hdfs_datadir: /data2/hdfs,/data3/hdfs,/data4/hdfs
# kafka日志目录,正式环境要求mount挂载比较大的数据盘
tdsql_kafka_logdir: /data2/kafka,/data3/kafka,/data4/kafka
# 多源同步消费服务的机器网卡
tdsql_consumer_netif: ens33
# es7配置
tdsql_es7_mem: 4
tdsql_es7_base_path: /data1/es
tdsql_helper_cluster_name: tdsql
# 一致性读MC机器的网卡, 需要安装MC时配置
tdsql_mc_netif: ens33
update_tdsqlinstall_packet: mysqlagent
注意 只需要修改网卡 和 赤兔监控库配置
网卡可以通过 命令查看
ifconfig
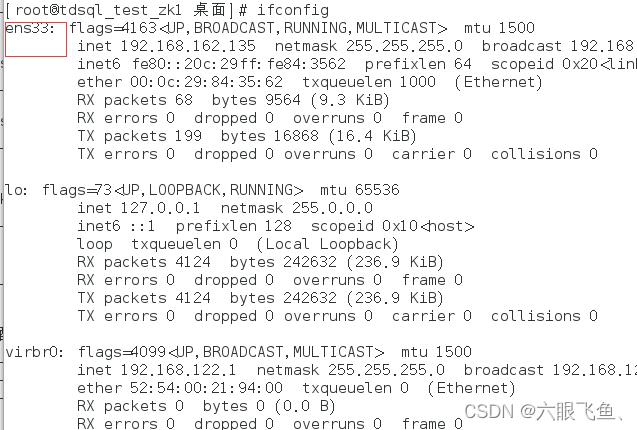
红色框里的就是自己的网卡
2.3安装ansible(主控机)
#指定环境配置
source scripts/environment_set
#执行安装脚本
sh scripts/install_ansible.sh
查看是否安装成功
ansible --version

2.4 关闭防火墙
注意一定要关闭防火墙 要不然无法连接到从机
#(关闭防火墙)
systemctl stop firewalld.service
#(关闭防火墙自动启动)
systemctl disable firewalld.service
#查看防火墙状态:
systemctl status firewalld.service
2.5 修改内存检测文件(如果内存满足要求 则不需要修改)
vim tdsql_install/roles/tdsql_env_check/files/checkenv/docheck.sh
#!/bin/bash
loglist=`ls /data/tools/checklog/`
initime=0
mintime=0
maxtime=0
initzone='hanlon'
for curlog in $loglist
do
curtime=`grep "cur_timestamp" /data/tools/checklog/$curlog |awk -F "[: ]+" 'print $2'`
if [ $initime -eq 0 ];then
initime=$curtime
mintime=$(($initime - 8))
maxtime=$(($initime + 8))
else
if [ $curtime -gt $maxtime ]; then
echo "/data/tools/checklog/$curlog time is not sync"
echo "/data/tools/checklog/$curlog time is not sync" > /data/tools/checkenv/err.log
exit 1
fi
if [ $curtime -lt $mintime ]; then
echo "/data/tools/checklog/$curlog time is not sync"
echo "/data/tools/checklog/$curlog time is not sync" > /data/tools/checkenv/err.log
exit 1
fi
fi
cur_cpu_capacity=`grep "cpu_capacity" /data/tools/checklog/$curlog |awk -F "[: ]+" 'print $2'`
if [ $cur_cpu_capacity -lt 2 ]; then
echo "/data/tools/checklog/$curlog cpu less than 2C"
echo "/data/tools/checklog/$curlog cpu less than 2C" > /data/tools/checkenv/err.log
exit 1
fi
cur_mem_capacity=`grep "mem_capacity" /data/tools/checklog/$curlog |awk -F "[: ]+" 'print $2'`
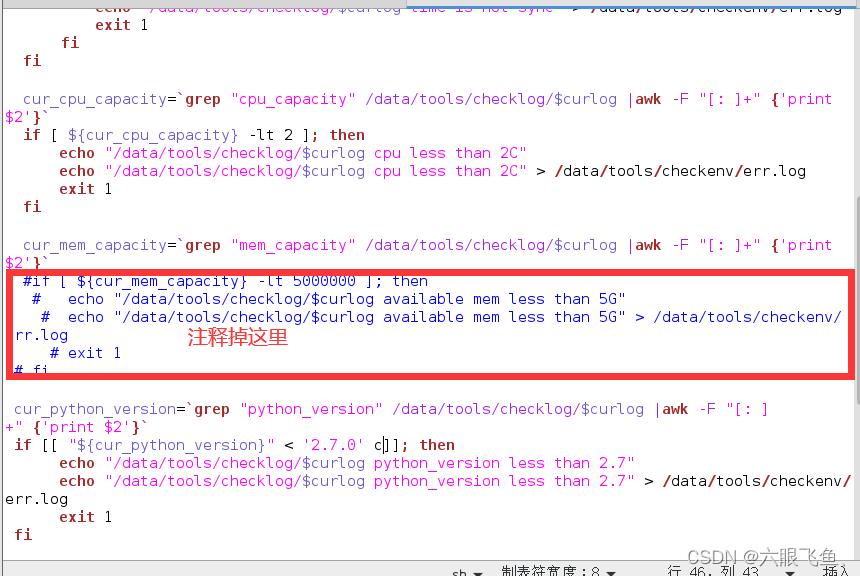
#注释掉这里 这里是检测机器的内存大小是否为5g
#if [ $cur_mem_capacity -lt 5000000 ]; then
# echo "/data/tools/checklog/$curlog available mem less than 5G"
# echo "/data/tools/checklog/$curlog available mem less than 5G" > /data/tools/checkenv/err.log
# exit 1
# fi
cur_python_version=`grep "python_version" /data/tools/checklog/$curlog |awk -F "[: ]+" 'print $2'`
if [[ "$cur_python_version" < '2.7.0' ]]; then
echo "/data/tools/checklog/$curlog python_version less than 2.7"
echo "/data/tools/checklog/$curlog python_version less than 2.7" > /data/tools/checkenv/err.log
exit 1
fi
curtimezone=`grep "cur_timezone" /data/tools/checklog/$curlog |awk -F "[: ]+" 'print $2'`
if [[ "$initzone" == 'hanlon' ]]; then
initzone=$curtimezone
fi
if [[ "$curtimezone" != "$initzone" ]]; then
echo "/data/tools/checklog/$curlog time_zone is not $initzone"
echo "/data/tools/checklog/$curlog time_zone is not $initzone" > /data/tools/checkenv/err.log
exit 1
fi
cur_sh=`grep "cur_sh" /data/tools/checklog/$curlog | awk -F "[: ]+" 'print $2' | awk -F'/' 'print $NF'`
if [[ "$cur_sh" != 'bash' ]]; then
echo "/data/tools/checklog/$curlog /bin/sh is not bash"
echo "/data/tools/checklog/$curlog /bin/sh is not bash" > /data/tools/checkenv/err.log
exit 1
fi
done
这里是检测机器的内存大小是否为5g 因为我不需要安装后面的一系列组件 只是测试一下是否能够安装 所有 这里取消了
3.开始安装
进入tdsql_install目录下
cd tdsql_10.3.17.3.0/tdsql_install/
安装命令
ansible-playbook -i tdsql_hosts playbooks/tdsql_part1_site.yml
他会自动安装 如果太久没有反应查看是否从机 卡住了
最后执行到没有错误那就是安装成功了
# 执行了近20多分钟 ,执行完成要无failed=0
PLAY RECAP ********************************************************************************************************************************************************
chitu1 : ok=20 changed=19 unreachable=0 failed=0
chitu2 : ok=20 changed=19 unreachable=0 failed=0
db1 : ok=13 changed=12 unreachable=0 failed=0
db2 : ok=13 changed=12 unreachable=0 failed=0
db3 : ok=13 changed=12 unreachable=0 failed=0
huyidb01 : ok=30 changed=19 unreachable=0 failed=0
huyidb02 : ok=27 changed=16 unreachable=0 failed=0
huyidb03 : ok=27 changed=16 unreachable=0 failed=0
huyidb04 : ok=27 changed=17 unreachable=0 failed=0
oss1 : ok=14 changed=11 unreachable=0 failed=0
oss2 : ok=14 changed=11 unreachable=0 failed=0
proxy1 : ok=13 changed=10 unreachable=0 failed=0
proxy2 : ok=13 changed=10 unreachable=0 failed=0
proxy3 : ok=13 changed=10 unreachable=0 failed=0
scheduler1 : ok=25 changed=23 unreachable=0 failed=0
scheduler2 : ok=22 changed=20 unreachable=0 failed=0
zk1 : ok=19 changed=17 unreachable=0 failed=0
zk2 : ok=19 changed=17 unreachable=0 failed=0
zk3 : ok=19 changed=17 unreachable=0 failed=0
可能出现的问题 ssh连接错误 那就是没有关闭防火墙 或者 没有配置免密登录
获取manager_varabie 错误 是网卡配置错误
4.初始化赤兔平台
网页访问安装chitu模块的机器地址,初始化chitu。
http://192.168.162.136/tdsqlpcloud
注意这里的ip为你hosts文件配置的ip地址
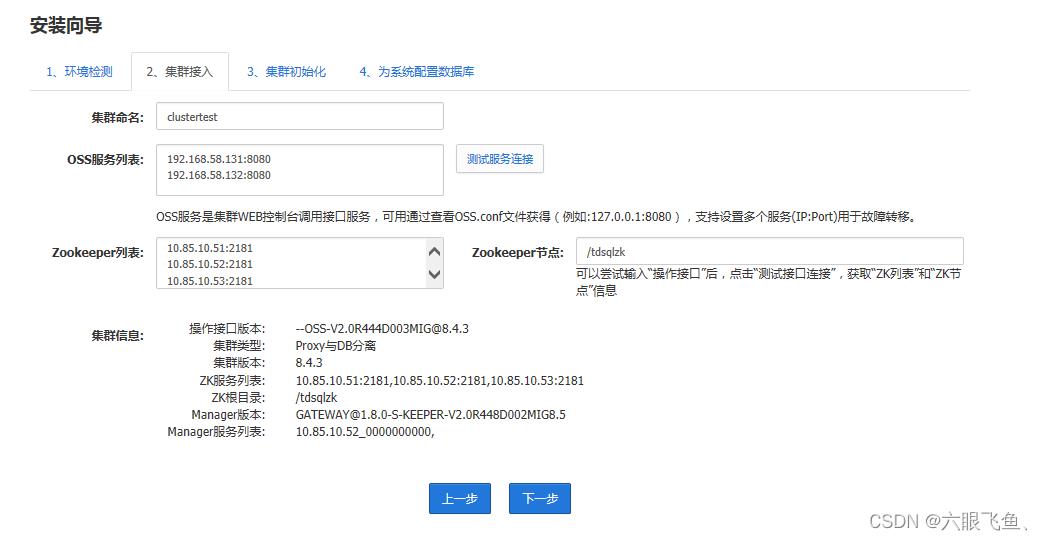
下一步 这里需要输入 配置文件配置的oss地址
就是从机1:8080 和从机2:8080 如有多个填写多个即可
集群初始化
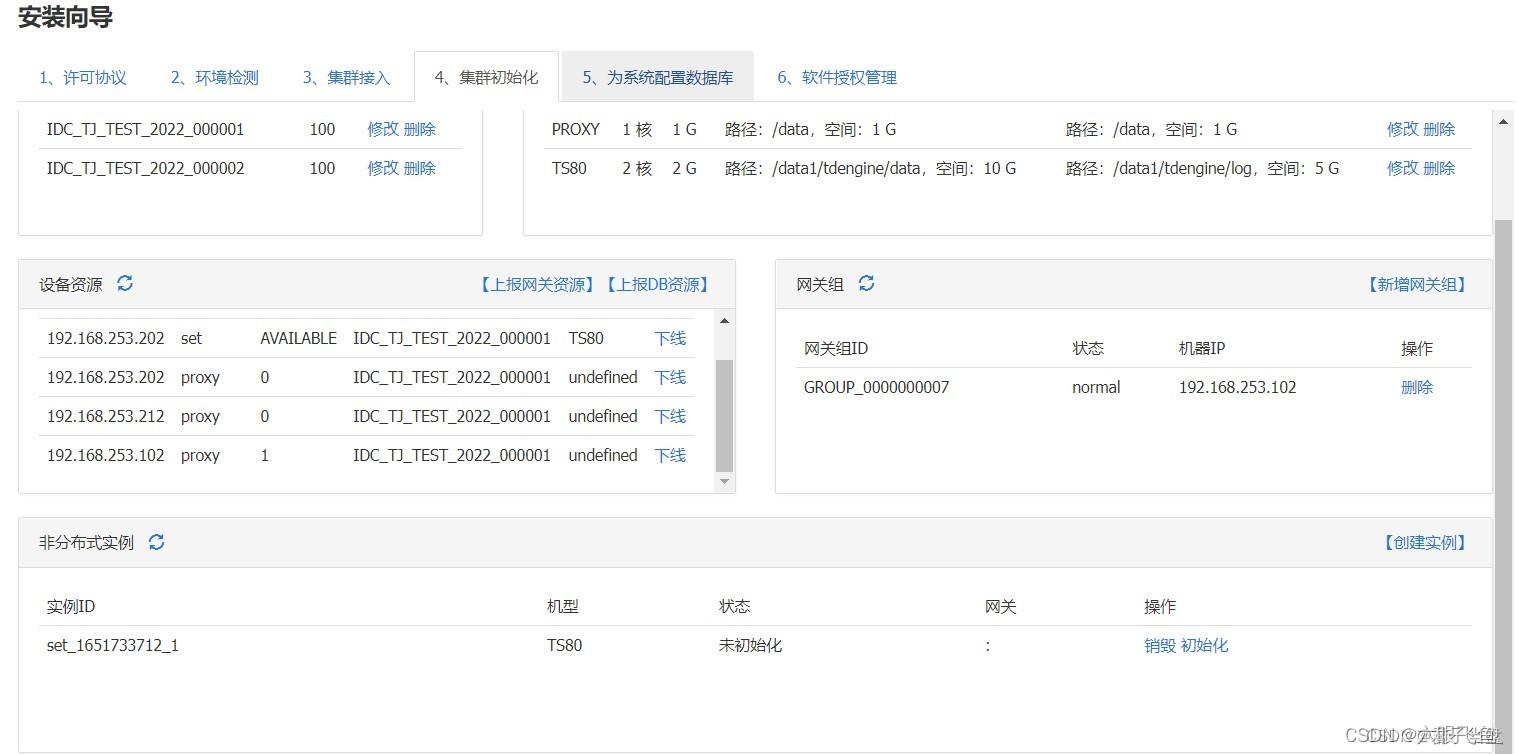
逐一配置IDC、机型规格、设备资源、网关组等信息,然后创建分布式实例。
然后初始化实例
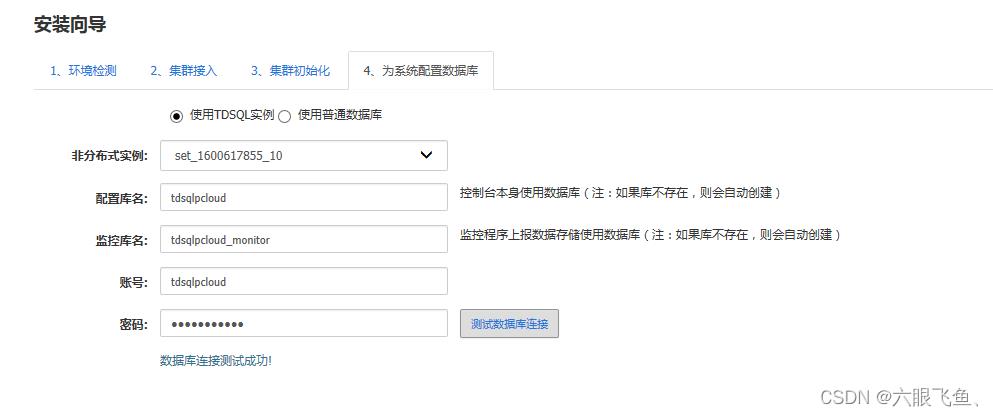
然后完成安装 进入平台
登录运营管理平台: 帐号密码 admin/123456
后续的就自己去尝试了
海量数据,极速体验——TDSQL-A核心架构详解来了
1
TDSQL-A产品定位
TDSQL-A是腾讯基于PostgreSQL自主研发的分布式超大规模在线关系型数据仓库,业务场景针对于在线高性能数据分析。
TDSQL-A有四个主要特点:
无共享MPP能实现无共享的存储,还可以实现线性的扩展;
在存储层面,通过自研列存储技术,能够做到行列混合存储;
在数据库规模方面,实现了超大规模集群的支持;
为了让客户有更好的体验,TDSQL-A还有超高速的计算能力,能够快速处理业务以及请求。
1
TDSQL-A发展历程
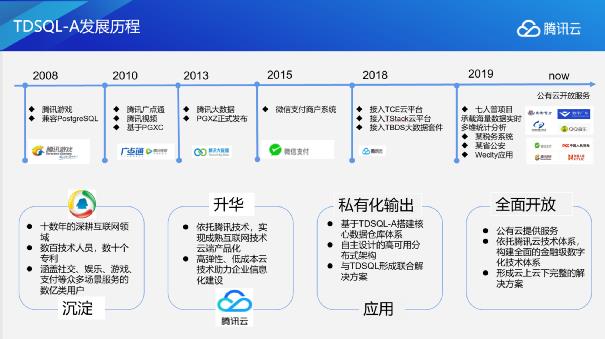
TDSQL-A是在腾讯业务发展过程中孵化出来的产品。最早的时候我们是用单机PG来做一些大数据平台小规模的数据分析以及结果缓存。但随着腾讯业务的扩张,我们发现单机的数据库已经无法支撑相关业务的数据量及请求量,就萌生了开发分布式数据库的想法。在2013年我们启动了第一个版本的开发。
开发完成后的TDSQL-PG(原TBase V2),最早用来支撑内部商户系统。随着业务的发展,我们在V2的基础上增加了列存储和分布式异步执行器、向量化等OLAP高级能力,在融入了腾讯云的几个主要平台后,逐渐对外提供服务。TDSQL-A最近一次闪亮亮相,是为去年第七次全国人口普查提供技术支撑。作为在线数据分析引擎,TDSQL-A很好地支撑了国家人口普查的执行,起到了加好的效果。
1
TDSQL-A技术架构
在对TDSQL-A产品进行研发和架构设计的时候,我们主要面临四个方面的挑战:

一是随着5G和loT时代的到来,数据呈现爆炸式的增长。单个数据库集群里面需要处理的数据的容量很容易就达到10PB级别的大小。这对传统的数据仓库及数据库来说,是一个非常有挑战的数据规模。
二是随着数据量的增大,我们需要处理的数据库业务以及各种类型的终端越来越多,对数据库的并发要求比之前更高了。我们最多的时候甚至需要处理数千个OLAP的并发。
三是随着业务系统的发展,查询会变得异常复杂,需要涉及到近十张大表的数据关联,这对数据存储和数据仓库查询优化都提出了很高的要求。
四是客户和业务对于延时的要求。客户希望我们越来越快地把结果处理完成,这样才能更好地去实现自己的商业价值和业务目标。
TDSQL-A产品的架构设计就是围绕这四个问题的解决展开的。
1. TDSQL-A实时数据仓库如何解决支持超大规模集群
对实时数据仓库来说,第一个要解决的问题就是如何去支持超大规模的集群。传统认知认为,分布式数据库集群的处理能力会随结点增多而变强。但实际上却并非如此。
下图就是我们进行分布式查询的时候需要建立的网络连接,或者说我们需要进行网络通信的管道。从图中我们可以看到,在两表进行JOIN查询时,我们少则需要两个网络连接,多则需要八个网络连接。随着SQL复杂度的提升和并发的增加,系统需要建立的网络数量则会越来越多,数据仓库的处理能力不一定会提升。
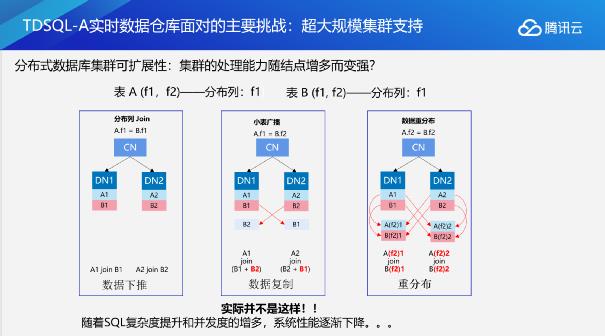
由此我们可以得出一个结论,即限制分布式数据库扩展性的核心问题之一,就是服务器连接数过高。那TDSQL-A是如何解决这个问题的呢?
全新设计的异步执行器解耦控制和数据交互
首先在执行逻辑方面,我们设计了全新的执行器,来解耦SQL执行的的控制逻辑和执行逻辑。
在查询优化阶段我们通过分析物理查询计划,对执行计划进行分片,由CN在各个节点创建执行进程。每个进程负责执行一个计划分片,这些进程不关注网络通信,相互独立执行。
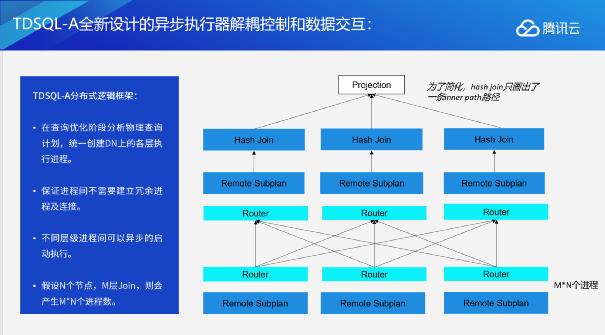
假设N个节点,M层join,则会产生M*N个进程。
这种设计一方面分离了SQL执行的控制逻辑和执行逻辑;另外一方面,也将网络连接从具体执行逻辑抽象了出来,变成了一组接口,SQL执行引擎只需要关注自己的执行逻辑,对于底层的通讯逻辑则不用专门去编写代码。而且,这些进程之间相互独立,没有相互的依赖关系,没有锁和进程同步,执行效率大大提升。
集中数据交互总线解决集群网络瓶颈
在通讯逻辑方面,我们进一步引入Forward Node(FN)来进行节点间数据交互。每台物理机一个FN节点。FN与CN/DN通过共享内存进行数据交互,本机数据交互还可以不走网络层,从而提供更高的性能。假设N个节点,M层Join,且不管查询多复杂,只有S*(N-1)个网络连接数。这对于服务器来说是并不算是一个很高的负载。
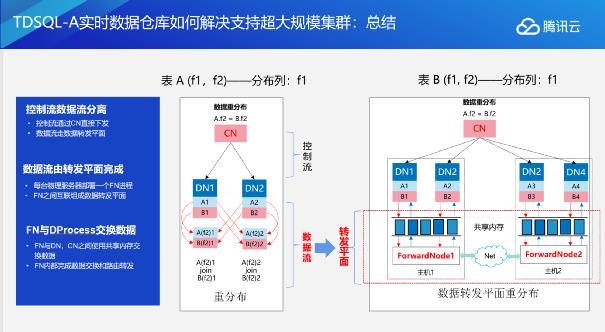
我们来小结一下TDSQL-A是如何实现超大规模数据集群支持的。
我们对整个数据库的执行逻辑进行了分流,把数据库分为了控制流和数据流。所谓的控制流由控制节点,CN节点完成,它去完成执行机构的生成,执行机构的下发以及运用资源的初始化。在执行的过程中控制平面就不会再参与执行的过程,执行过程完全由执行平台来完成,执行平台主要负责执行过程中数据的交互以及整个执行过程的达成。
在执行过程中,数据流由转发平面完成,即FN节点。每个服务器上面就会部署一个FN进程,不同的物理服务器之间的FN进程相互连接在一起会组成一个转发平面。FN跟每台服务器之间通过下面的共享内存和上面的CN或DN进行通信,FN内部完成数据的交换和路由转发。
2. TDSQL-A自研行列混合存储能力提升OLAP效率
下面介绍TDSQL-A全自研的行列混合的存储能力。数据库的存储有两种方式,一个是按行存储、一个是按列存储:
按行存储表:每行数据存储所有列、一次磁盘IO可以访问一行中所有列、适合OLTP场景。
按列存储表:每列单独存储,多个列逻辑组成一行;一次磁盘IO只包含一列数据;方便做数据压缩;适合OLAP场景。

TDSQL-A支持按列存储和按行存储两种方式来建表,同时在列表和行表之间,用户不用感知到下层的表是通过行表还是列表来建,行表和列表之间可以进行无缝的互操作——包括相互关联、相互交换数据,完全不需要感知到底下的存储逻辑。
除了操作的便利性之外,行表和列表之间混合查询还能保持完整的事务一致性,也就是说在查询运行的同时,整个事务(ACID)的能力也得到完整的保证。
3. TDSQL-A列存储压缩能力降低业务成本
作为OLAP场景下的产品来说,压缩是一项非常重要的能力,这里介绍TDSQL-A的列存储压缩能力。
目前我们支持两种压缩方式:
一是轻量级压缩。这是能够感知到数据内容的一种压缩方式。它可以针对用户数据的特点提供合适的压缩方式来降低用户的成本,在有规律时达到数百倍的压缩比。我们可以针对特殊的数据,比如重复率比较高的或者是有规律、有顺序的数据进行轻量级压缩。
二是透明压缩。透明压缩主要是用zstd和gzip压缩算法来提供压缩能力,可以帮用户进一步去压缩成本,提升处理效率。
4. 延迟物化原理
在分布式场景下,特别是超大规模分布式场景下,网络IO和CPU其实是非常重要的资源。如果在计算时,网络IO达到了瓶颈,或者CPU达到了瓶颈,都会从整体上影响集群的扩展性和集群的处理能力。
目前用数据库或数据仓库进行查询时,很多使用的都是提前物化。所谓的提前物化是相对于查询来说的。其在数据库里面会分解成几步:第一步需要从下面最底层的表里面把数据查询出来,再进行关联,join完成之后再进行投影,传给上层要使用的一些列。
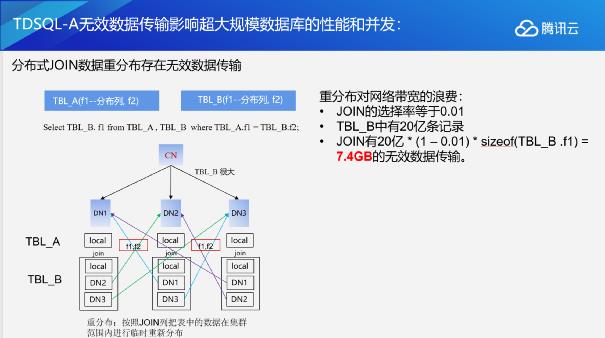
可以看到,在进行join时我们其实只关联了表b的f2这一列,但是投影时却投影了表b的f1这一列。这时对之前的数据库进行提前物化时,在传递数据给join时,我们就会把表b的f1和f2都吐出来。因为我们计算发现上层project需要f1这一列,但是join这里需要f2这一列,所以它就会把上层需要的所有列全部在这里算出来。但实际上如果在这个地方关联时过滤的比例很高的话,比如说现在有1%的满足率,其实大部分的f1是没有意义的,因为最终在这里通过join会被抛弃掉。在超大规模的分布式场景下,如果表里面有20亿条记录,选择率是0.01的话,这个时候就会有7.4GB的无效数据传输。对于十分依赖网络传播的分布式数据库来说,7.4个GB已经是非常可观的开销了。
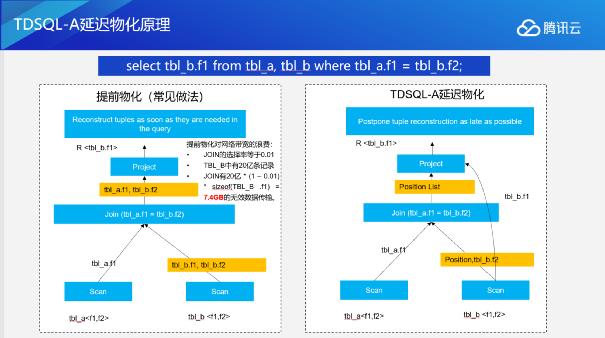
因此我们引入了另外一种物化算法,即延迟物化。延迟物化可以简单理解为不见兔子不撒鹰。所谓的不见兔子不撒鹰,就是在投影的时候只拉去满足条件的那些数据,减少中间这7.4个GB的传输。这就要我们在进行Scan时,只看上层join节点需要的一些列,把它传递到上层节点去,join完成之后把满足条件的那些列的位置信息传递给上层的project节点。根据我们的测试,随着表变得越来越复杂,随着查询变得越来越复杂,表变得越来越大,我们优化的效果也越来越明显。
5. TDSQL-A全并行能力、向量化计算能力
除了上面的延迟物化外,我们还引入了系统的全并行能力。全并行能力对数据库的OLAP场景数据库来讲是一个必经之路。MPP架构让我们具备了多节点并行的架构优势,同时我们还通过优化做到了节点内部的多进程进程间的进行,并在内部使用了CPU的特殊指令做到指令级并行,因此TDSQL-A可以做到三级并行,依次是:节点级并行,进程级并行以及指令级并行。这种全并行的能力能够进一步提升我们整体的处理效率。
向量化计算能力在OLAP上也是一个必须探讨的课题。TDSQL-A也进行了一些新的尝试,并实现了向量化计算能力:数据量越大,列存非向量化和列存向量化效果越明显,在最好的情况下,列存向量化运行时间是列村非向量化的1/2,列存向量化运行时间是行村的1/8。列存储的向量化执行能够达到行存储执行1/8左右。向量化计算能力对整个OLAP性能的提升是非常明显的。
6. TDSQL-A的多平面能力提供一致的读扩展性
在整体架构上,TDSQL-A也提供了比较好的一致性的读扩展能力。
一致性的读扩展能力是跟随业务场景的催生的技术特性。有一些客户反映过这种的情况,就是在数据库CPU,内存已经用满的情况下,还有更多的业务请求要加进来。为了满足这种读的扩展性需要,我们就研发出了能够提供读取能力的多平面特性,简单理解就是在读写平面的基础上,通过内部复制的方式来创建出一个只读平面,去处理只读的请求。相比之前新建数据库集群的方式,这种做法在降低了业务成本和系统复杂度的同时,也帮助客户解决了很多现实的问题。
7. TDSQL-A整体技术架构小结
TDSQL-A整体的技术架构可以总结成六点:
通过集中式的网络架构、网络融合通信技术以及后面在执行级层面引入的能力,可以进一步去拓展分布式MPP数据仓库的存储规模的上限,达到数千台的规模;
通过向量化技术,底层整个执行级的逻辑优化,做到极速OLAP的响应;
在存储层面通过多种高效的数据压缩方式,提供极高的压缩比,帮助业务去节省经营成本;
在接口层面完整兼容了SQL2003,同时对ORALE语法兼容性达到95%,包括存储过程、触发器等一系列内容;
支持行列混合存储及行列混合操作的能力;
借助特有能力去访问外部数据源,包括分布式对象存储,HDFS存储等,能够实现存储与计算分离。
1
TDSQL-A后续规划
TDSQL-A的后续规划分为两部分:
一方面是陆续将目前基于PG10的版本,merge到PG11、PG12、PG13等更高版本,持续地跟进社区版本丰富的特性,来提升用户的体验,为客户创造更多价值。
另一方面,随着硬件技术的不断发展,包括GPU、FGA以及APE这些新硬件的发展,给我们创造了为客户创造更高价值可能性,TDSQL-A也希望通过引入新硬件,来提升产品竞争力,为客户提供更好的服务。
- End -
更多精彩
↓↓更多惊喜点这儿~
以上是关于TDSQL的安装教程(低配体验)的主要内容,如果未能解决你的问题,请参考以下文章