各种安装2
Posted 大小曲奇(´ε` )
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了各种安装2相关的知识,希望对你有一定的参考价值。
各种安装2
- 一、八阶段-第四章-==案例导入说明==
- 一、八阶段-第四章-==安装OpenResty==
- 一、八阶段-第四章-==安装和配置Canal==
- 1.开启MySQL主从
- 2.安装Canal
- 二、八阶段-第五章-==RabbitMQ部署指南==
一、八阶段-第四章-案例导入说明
为了演示多级缓存,我们先导入一个商品管理的案例,其中包含商品的CRUD功能。我们将来会给查询商品添加多级缓存。
1.安装mysql
后期做数据同步需要用到MySQL的主从功能,所以需要大家在虚拟机中,利用Docker来运行一个MySQL容器。
1.1.准备目录
为了方便后期配置MySQL,我们先准备两个目录,用于挂载容器的数据和配置文件目录:
# 进入/tmp目录
cd /tmp
# 创建文件夹
mkdir mysql
# 进入mysql目录
cd mysql
1.2.运行命令
进入mysql目录后,执行下面的Docker命令:
docker run \\
-p 3306:3306 \\
--name mysql \\
-v $PWD/conf:/etc/mysql/conf.d \\
-v $PWD/logs:/logs \\
-v $PWD/data:/var/lib/mysql \\
-e MYSQL_ROOT_PASSWORD=123 \\
--privileged \\
-d \\
mysql:5.7.25
1.3.修改配置
在/tmp/mysql/conf目录添加一个my.cnf文件,作为mysql的配置文件:
# 创建文件
touch /tmp/mysql/conf/my.cnf
文件的内容如下:
[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/var/lib/mysql
server-id=1000
1.4.重启
配置修改后,必须重启容器:
docker restart mysql
2.导入SQL
接下来,利用Navicat客户端连接MySQL,然后导入课前资料提供的sql文件:

其中包含两张表:
- tb_item:商品表,包含商品的基本信息
- tb_item_stock:商品库存表,包含商品的库存信息
之所以将库存分离出来,是因为库存是更新比较频繁的信息,写操作较多。而其他信息修改的频率非常低。
3.导入Demo工程
下面导入课前资料提供的工程:

项目结构如图所示:

其中的业务包括:
- 分页查询商品
- 新增商品
- 修改商品
- 修改库存
- 删除商品
- 根据id查询商品
- 根据id查询库存
业务全部使用mybatis-plus来实现,如有需要请自行修改业务逻辑。
3.1.分页查询商品
在com.heima.item.web包的ItemController中可以看到接口定义:

3.2.新增商品
在com.heima.item.web包的ItemController中可以看到接口定义:

3.3.修改商品
在com.heima.item.web包的ItemController中可以看到接口定义:

3.4.修改库存
在com.heima.item.web包的ItemController中可以看到接口定义:

3.5.删除商品
在com.heima.item.web包的ItemController中可以看到接口定义:

这里是采用了逻辑删除,将商品状态修改为3
3.6.根据id查询商品
在com.heima.item.web包的ItemController中可以看到接口定义:

这里只返回了商品信息,不包含库存
3.7.根据id查询库存
在com.heima.item.web包的ItemController中可以看到接口定义:

3.8.启动
注意修改application.yml文件中配置的mysql地址信息:(更改IP地址,数据库名称,数据库密码)

需要修改为自己的虚拟机地址信息、还有账号和密码。
修改后,启动服务,访问:http://localhost:8081/item/10001即可查询数据
4.导入商品查询页面
商品查询是购物页面,与商品管理的页面是分离的。
部署方式如图:
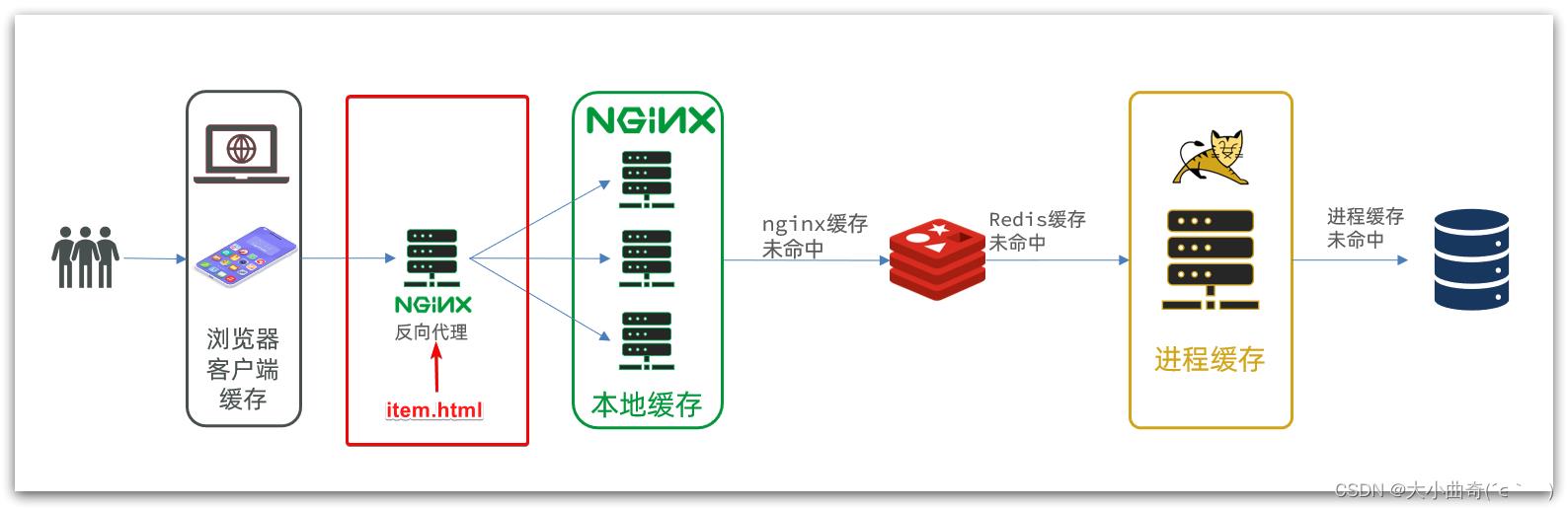
我们需要准备一个反向代理的nginx服务器,如上图红框所示,将静态的商品页面放到nginx目录中。
页面需要的数据通过ajax向服务端(nginx业务集群)查询。
4.1.运行nginx服务
这里我已经给大家准备好了nginx反向代理服务器和静态资源。
我们找到课前资料的nginx目录:

将其拷贝到一个非中文目录下,运行这个nginx服务。
运行命令:
start nginx.exe
然后访问 http://localhost/item.html?id=10001即可:

4.2.反向代理
现在,页面是假数据展示的。我们需要向服务器发送ajax请求,查询商品数据。
打开控制台,可以看到页面有发起ajax查询数据:

而这个请求地址同样是80端口,所以被当前的nginx反向代理了。
查看nginx的conf目录下的nginx.conf文件:
其中的关键配置如下:(需要更改IP地址)

其中的192.168.150.101是我的虚拟机IP,也就是我的Nginx业务集群要部署的地方:
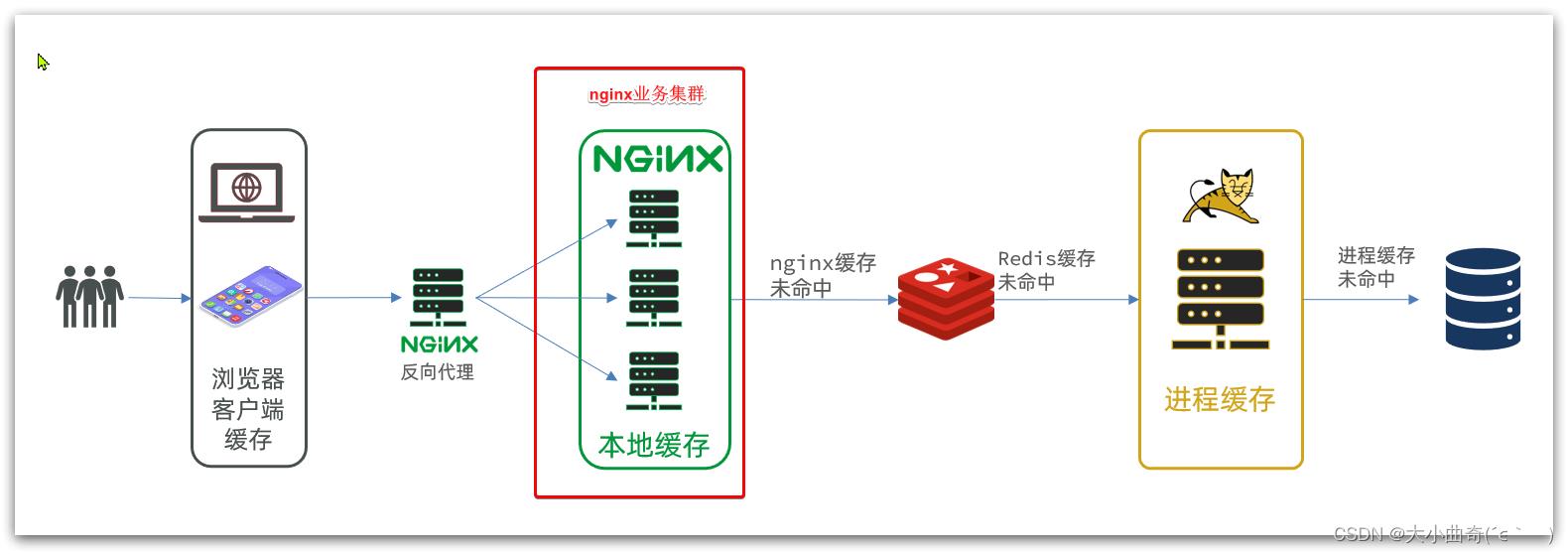
完整内容如下:
#user nobody;
worker_processes 1;
events
worker_connections 1024;
http
include mime.types;
default_type application/octet-stream;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
upstream nginx-cluster
server 192.168.150.101:8081;
server
listen 80;
server_name localhost;
location /api
proxy_pass http://nginx-cluster;
location /
root html;
index index.html index.htm;
error_page 500 502 503 504 /50x.html;
location = /50x.html
root html;
一、八阶段-第四章-安装OpenResty
1.安装
首先你的Linux虚拟机必须联网
1)安装开发库
首先要安装OpenResty的依赖开发库,执行命令:
yum install -y pcre-devel openssl-devel gcc --skip-broken
2)安装OpenResty仓库
你可以在你的 CentOS 系统中添加 openresty 仓库,这样就可以便于未来安装或更新我们的软件包(通过 yum check-update 命令)。运行下面的命令就可以添加我们的仓库:
yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo
如果提示说命令不存在,则运行:
yum install -y yum-utils
然后再重复上面的命令
3)安装OpenResty
然后就可以像下面这样安装软件包,比如 openresty:
yum install -y openresty
4)安装opm工具
opm是OpenResty的一个管理工具,可以帮助我们安装一个第三方的Lua模块。
如果你想安装命令行工具 opm,那么可以像下面这样安装 openresty-opm 包:
yum install -y openresty-opm
5)目录结构
默认情况下,OpenResty安装的目录是:/usr/local/openresty
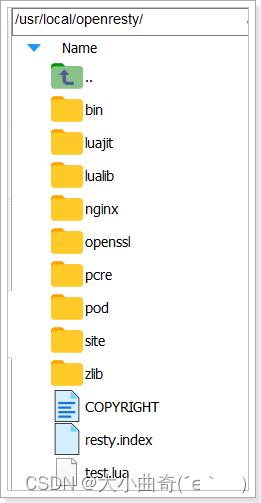
看到里面的nginx目录了吗,OpenResty就是在Nginx基础上集成了一些Lua模块。
6)配置nginx的环境变量
打开配置文件:
vi /etc/profile
在最下面加入两行:
export NGINX_HOME=/usr/local/openresty/nginx
export PATH=$NGINX_HOME/sbin:$PATH
NGINX_HOME:后面是OpenResty安装目录下的nginx的目录
然后让配置生效:
source /etc/profile
2.启动和运行
OpenResty底层是基于Nginx的,查看OpenResty目录的nginx目录,结构与windows中安装的nginx基本一致:

所以运行方式与nginx基本一致:
# 启动nginx
nginx
# 重新加载配置
nginx -s reload
# 停止
nginx -s stop
nginx的默认配置文件注释太多,影响后续我们的编辑,这里将nginx.conf中的注释部分删除,保留有效部分。
修改/usr/local/openresty/nginx/conf/nginx.conf文件,内容如下:
#user nobody;
worker_processes 1;
error_log logs/error.log;
events
worker_connections 1024;
http
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server
listen 8081;
server_name localhost;
location /
root html;
index index.html index.htm;
error_page 500 502 503 504 /50x.html;
location = /50x.html
root html;
在Linux的控制台输入命令以启动nginx:
nginx
然后访问页面:http://192.168.150.101:8081,注意ip地址替换为你自己的虚拟机IP:
3.备注
加载OpenResty的lua模块:
#lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
#c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
common.lua
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path,
method = ngx.HTTP_GET,
args = params,
)
if not resp then
-- 记录错误信息,返回404
ngx.log(ngx.ERR, "http not found, path: ", path , ", args: ", args)
ngx.exit(404)
end
return resp.body
end
-- 将方法导出
local _M =
read_http = read_http
return _M
释放Redis连接API:
-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)
local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒
local pool_size = 100 --连接池大小
local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.log(ngx.ERR, "放入redis连接池失败: ", err)
end
end
读取Redis数据的API:
-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)
-- 获取一个连接
local ok, err = red:connect(ip, port)
if not ok then
ngx.log(ngx.ERR, "连接redis失败 : ", err)
return nil
end
-- 查询redis
local resp, err = red:get(key)
-- 查询失败处理
if not resp then
ngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)
end
--得到的数据为空处理
if resp == ngx.null then
resp = nil
ngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)
end
close_redis(red)
return resp
end
开启共享词典:
# 共享字典,也就是本地缓存,名称叫做:item_cache,大小150m
lua_shared_dict item_cache 150m;
一、八阶段-第四章-安装和配置Canal
下面我们就开启mysql的主从同步机制,让Canal来模拟salve
1.开启MySQL主从
Canal是基于MySQL的主从同步功能,因此必须先开启MySQL的主从功能才可以。
这里以之前用Docker运行的mysql为例:
1.1.开启binlog
打开mysql容器挂载的日志文件,我的在/tmp/mysql/conf目录:

修改文件:
vi /tmp/mysql/conf/my.cnf
添加内容:
log-bin=/var/lib/mysql/mysql-bin
binlog-do-db=heima
配置解读:
log-bin=/var/lib/mysql/mysql-bin:设置binary log文件的存放地址和文件名,叫做mysql-binbinlog-do-db=heima:指定对哪个database记录binary log events,这里记录heima这个库
最终效果:
[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/var/lib/mysql
server-id=1000
log-bin=/var/lib/mysql/mysql-bin
binlog-do-db=heima
1.2.设置用户权限
接下来添加一个仅用于数据同步的账户,出于安全考虑,这里仅提供对heima这个库的操作权限。
create user canal@'%' IDENTIFIED by 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%' identified by 'canal';
FLUSH PRIVILEGES;
重启mysql容器即可
docker restart mysql
测试设置是否成功:在mysql控制台,或者Navicat中,输入命令:
show master status;

2.安装Canal
2.1.创建网络
我们需要创建一个网络,将MySQL、Canal、MQ放到同一个Docker网络中:
docker network create heima
让mysql加入这个网络:
docker network connect heima mysql
2.3.安装Canal
课前资料中提供了canal的镜像压缩包:

大家可以上传到虚拟机,然后通过命令导入:
docker load -i canal.tar
然后运行命令创建Canal容器:
docker run -p 11111:11111 --name canal \\
-e canal.destinations=heima \\
-e canal.instance.master.address=mysql:3306 \\
-e canal.instance.dbUsername=canal \\
-e canal.instance.dbPassword=canal \\
-e canal.instance.connectionCharset=UTF-8 \\
-e canal.instance.tsdb.enable=true \\
-e canal.instance.gtidon=false \\
-e canal.instance.filter.regex=heima\\\\..* \\
--network heima \\
-d canal/canal-server:v1.1.5
说明:
-p 11111:11111:这是canal的默认监听端口-e canal.instance.master.address=mysql:3306:数据库地址和端口,如果不知道mysql容器地址,可以通过docker inspect 容器id来查看-e canal.instance.dbUsername=canal:数据库用户名-e canal.instance.dbPassword=canal:数据库密码-e canal.instance.filter.regex=:要监听的表名称
表名称监听支持的语法:
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\\\)
常见例子:
1. 所有表:.* or .*\\\\..*
2. canal schema下所有表: canal\\\\..*
3. canal下的以canal打头的表:canal\\\\.canal.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用然后以逗号隔开:canal\\\\..*,mysql.test1,mysql.test2
二、八阶段-第五章-RabbitMQ部署指南
1.单机部署 【之前已经做过了】
我们在Centos7虚拟机中使用Docker来安装。
1.1.下载镜像
方式一:在线拉取
docker pull rabbitmq:3.8-management
方式二:从本地加载
在课前资料已经提供了镜像包:

上传到虚拟机中后,使用命令加载镜像即可:
docker load -i mq.tar
1.2.安装MQ
执行下面的命令来运行MQ容器:
注意:下面第四行要挂载,如果没有挂载要重新安装一下MQ;
docker run \\
-e RABBITMQ_DEFAULT_USER=itcast \\
-e RABBITMQ_DEFAULT_PASS=123321 \\
-v mq-plugins:/plugins \\
--name mq \\
--hostname mq1 \\
-p 15672:15672 \\
-p 5672:5672 \\
-d \\
rabbitmq:3.8-management
2.安装DelayExchange插件
官方的安装指南地址为:https://blog.rabbitmq.com/posts/2015/04/scheduling-messages-with-rabbitmq
上述文档是基于linux原生安装RabbitMQ,然后安装插件。
因为我们之前是基于Docker安装RabbitMQ,所以下面我们会讲解基于Docker来安装RabbitMQ插件。
2.1.下载插件
RabbitMQ有一个官方的插件社区,地址为:https://www.rabbitmq.com/community-plugins.html
其中包含各种各样的插件,包括我们要使用的DelayExchange插件:

大家可以去对应的GitHub页面下载3.8.9版本的插件,地址为https://github.com/rabbitmq/rabbitmq-delayed-message-exchange/releases/tag/3.8.9这个对应RabbitMQ的3.8.5以上版本。
课前资料也提供了下载好的插件:

2.2.上传插件
因为我们是基于Docker安装,所以需要先查看RabbitMQ的插件目录对应的数据卷。如果不是基于Docker的同学,请参考第一章部分,重新创建Docker容器。
我们之前设定的RabbitMQ的数据卷名称为mq-plugins,所以我们使用下面命令查看数据卷:
docker volume inspect mq-plugins
可以得到下面结果:

接下来,将插件上传到这个目录即可:
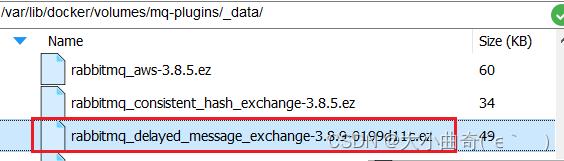
2.3.安装插件
最后就是安装了,需要进入MQ容器内部来执行安装。我的容器名为mq,所以执行下面命令:
docker exec -it mq bash #进入容器内部
执行时,请将其中的 -it 后面的mq替换为你自己的容器名.
进入容器内部后,执行下面命令开启插件:
rabbitmq-plugins enable rabbitmq_delayed_message_exchange
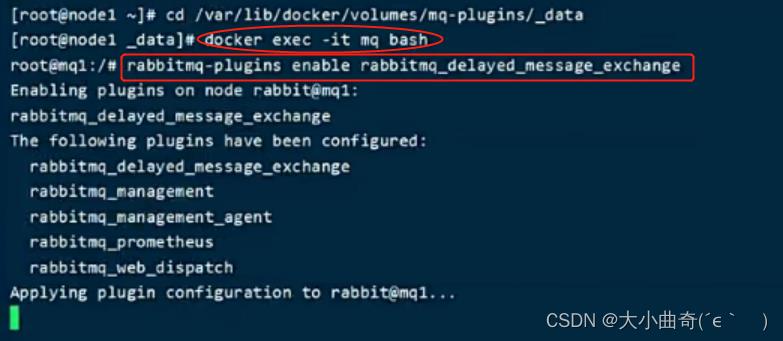
结果如下:

已经被启动了,此时MQ已经具备延迟的功能了;
2.4.使用插件


总结:
使用步骤:①创建一个交换机,把他的类型指定成x-delayed-message类型,把路由方式指定成想用的方式;②给交换机发消息,发送时要加一个头x-delay,并可以设置延迟时间;
3.集群部署
接下来,我们看看如何安装RabbitMQ的集群。
3.1.集群分类
在RabbitMQ的官方文档中,讲述了两种集群的配置方式:
- 普通模式:普通模式集群不进行数据同步,每个MQ都有自己的队列、数据信息(其它元数据信息如交换机等会同步)。例如我们有2个MQ:mq1,和mq2,如果你的消息在mq1,而你连接到了mq2,那么mq2会去mq1拉取消息,然后返回给你。如果mq1宕机,消息就会丢失。
- 镜像模式:与普通模式不同,队列会在各个mq的镜像节点之间同步,因此你连接到任何一个镜像节点,均可获取到消息。而且如果一个节点宕机,并不会导致数据丢失。不过,这种方式增加了数据同步的带宽消耗。
我们先来看普通模式集群,我们的计划部署3节点的mq集群(目前我们只有一台机器):
| 主机名 | 控制台端口 | amqp通信端口 |
|---|---|---|
| mq1 | 8081 —> 15672 | 8071 —> 5672 |
| mq2 | 8082 —> 15672 | 8072 —> 5672 |
| mq3 | 8083 —> 15672 | 8073 —> 5672 |
集群中的节点标示默认都是:rabbit@[hostname],因此以上三个节点的名称分别为:
- rabbit@mq1
- rabbit@mq2
- rabbit@mq3
3.2.获取cookie
RabbitMQ底层依赖于Erlang,而Erlang虚拟机就是一个面向分布式的语言,默认就支持集群模式。集群模式中的每个RabbitMQ 节点使用 cookie 来确定它们是否被允许相互通信。
要使两个节点能够通信,它们必须具有相同的共享秘密,称为Erlang cookie。cookie 只是一串最多 255 个字符的字母数字字符。
每个集群节点必须具有相同的 cookie。实例之间也需要它来相互通信。
我们先在之前启动的mq容器中获取一个cookie值,作为集群的cookie。执行下面的命令:
docker exec -it mq cat /var/lib/rabbitmq/.erlang.cookie
可以看到cookie值如下:
FXZMCVGLBIXZCDEMMVZQ
接下来,停止并删除当前的mq容器,我们重新搭建集群。
docker rm -f mq
清理数据卷(把mq清理干净):
docker volume prune

3.3.准备集群配置
在/tmp目录新建一个配置文件 rabbitmq.conf:
cd /tmp
# 创建文件
touch rabbitmq.conf
文件内容如下:
loopback_users.guest = false #禁用guest 用户
listeners.tcp.default = 5672
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config
cluster_formation.classic_config.nodes.1 = rabbit@mq1
cluster_formation.classic_config.nodes.2 = rabbit@mq2
cluster_formation.classic_config.nodes.3 = rabbit@mq3
再创建一个文件,记录cookie
cd /tmp
# 创建cookie文件
touch .erlang.cookie
# 写入cookie
echo "FXZMCVGLBIXZCDEMMVZQ" > .erlang.cookie
# 修改cookie文件的权限(只有root用户有读写权限)
chmod 600 .erlang.cookie
准备三个目录,mq1、mq2、mq3:
cd /tmp
# 创建目录
mkdir mq1 mq2 mq3
然后拷贝rabbitmq.conf、cookie文件到mq1、mq2、mq3:
# 进入/tmp
cd /tmp
# 拷贝
cp rabbitmq.conf mq1
cp rabbitmq.conf mq2
cp rabbitmq.conf mq3
cp .erlang.cookie mq1
cp .erlang.cookie mq2
cp .erlang.cookie mq3
3.4.启动集群
创建一个网络:
docker network create mq-net
docker volume create
运行命令
docker run -d --net mq-net \\
-v $PWD/mq1/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \\
-v $PWD/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \\
-e RABBITMQ_DEFAULT_USER=itcast \\
-e RABBITMQ_DEFAULT_PASS=123321 \\
--name mq1 \\ #容器名
--hostname mq1 \\ #主机名
-p 8071:5672 \\
-p 8081:15672 \\
rabbitmq:3.8-management
docker run -d --net mq-net \\
-v $PWD/mq2/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \\
-v $PWD/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \\
-e RABBITMQ_DEFAULT_USER=itcast \\
-e RABBITMQ_DEFAULT_PASS=123321 \\
--name mq2 \\
--hostname mq2 \\
-p 8072:5672 \\
-p 8082:15672 \\
rabbitmq:3.8-management
docker run -d --net mq-net \\
-v $PWD/mq3/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \\
-v $PWD/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \\
-e RABBITMQ_DEFAULT_USER=itcast \\
-e RABBITMQ_DEFAULT_PASS=123321 \\
--name mq3 \\
--hostname mq3 \\
-p 8073:5672 \\
-p 8083:15672 \\
rabbitmq:3.8-management
3.5.测试
在mq1这个节点上添加一个队列:
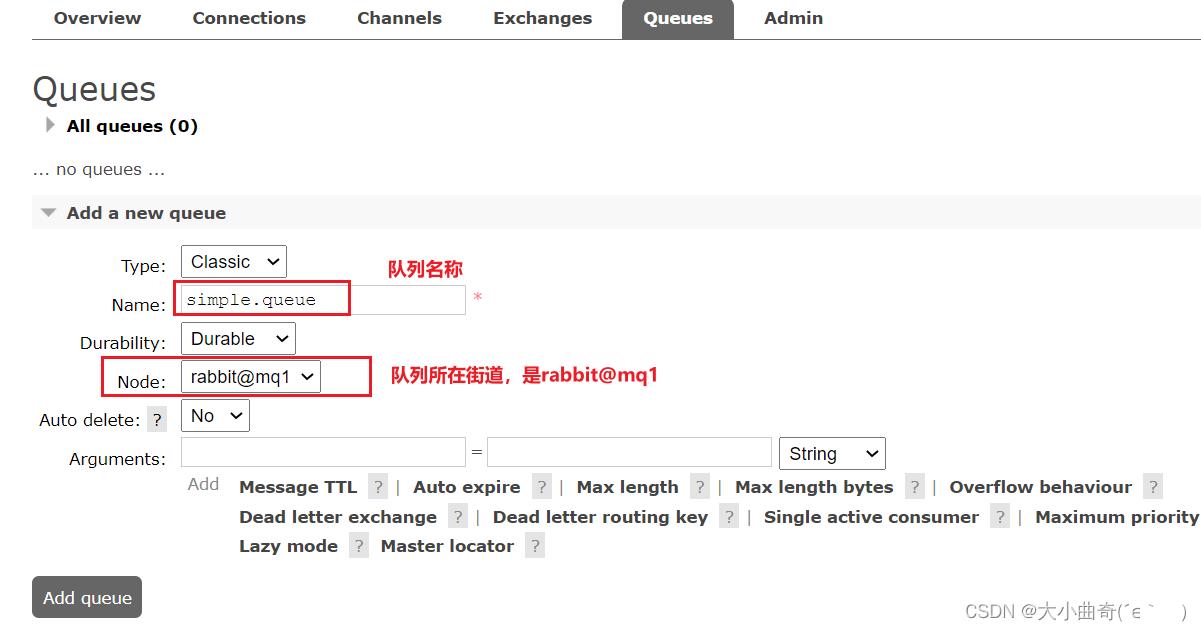
如图,在mq2和mq3两个控制台也都能看到:

3.5.1.数据共享测试
点击这个队列,进入管理页面:

然后利用控制台发送一条消息到这个队列:
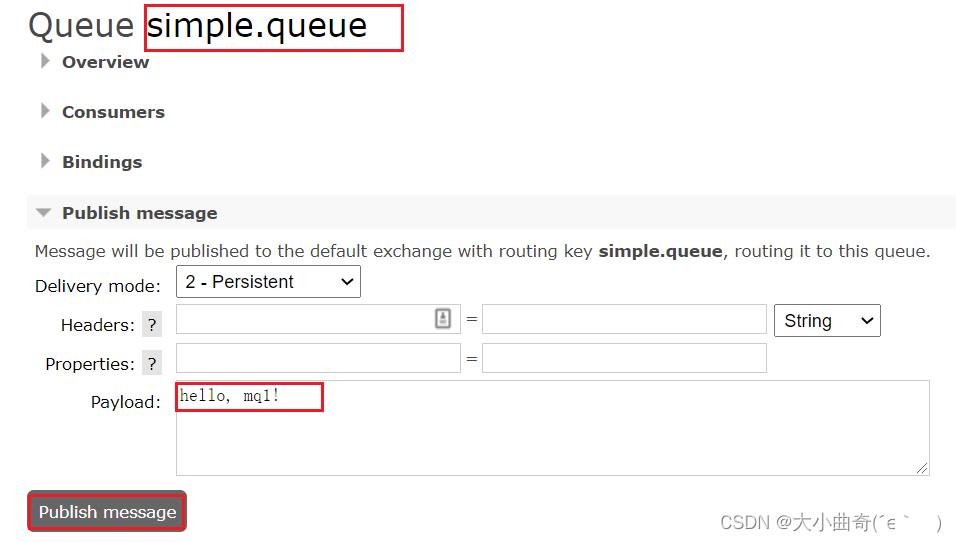
结果在mq2、mq3上都能看到这条消息:
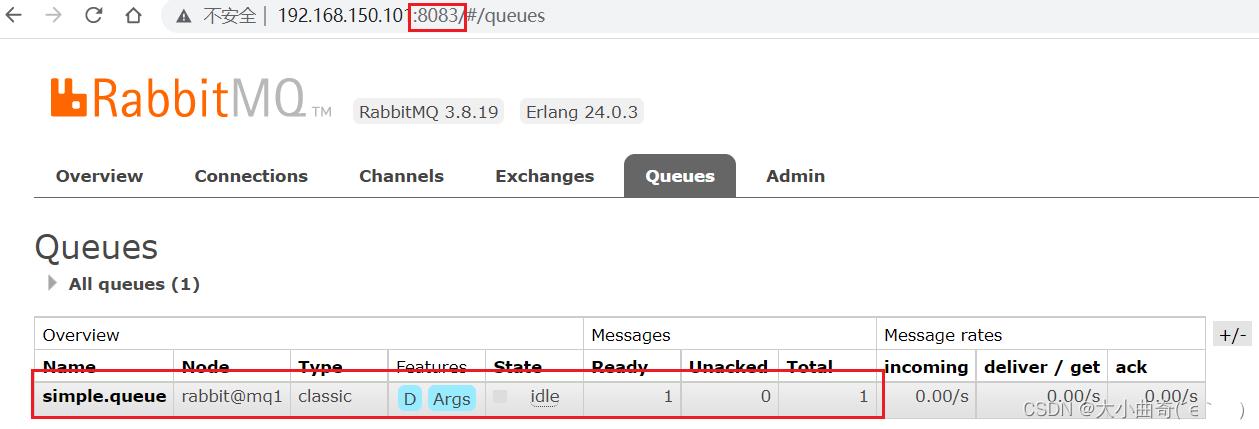
3.5.2.可用性测试
我们让其中一台节点mq1宕机:
docker stop mq1
然后登录mq2或mq3的控制台,发现simple.queue也不可用了:

说明数据并没有拷贝到mq2和mq3。
要想恢复:docker start mq1重新启动mq1
4.镜像模式
在刚刚的案例中,一旦创建队列的主机宕机,队列就会不可用。不具备高可用能力。如果要解决这个问题,必须使用官方提供的镜像集群方案。
官方文档地址:https://www.rabbitmq.com/ha.html
4.1.镜像模式的特征
默认情况下,队列只保存在创建该队列的节点上。而镜像模式下,创建队列的节点被称为该队列的主节点,队列还会拷贝到集群中的其它节点,也叫做该队列的镜像节点。
但是,不同队列可以在集群中的任意节点上创建,因此不同队列的主节点可以不同。甚至,一个队列的主节点可能是另一个队列的镜像节点。
用户发送给队列的一切请求,例如发送消息、消息回执默认都会在主节点完成,如果是从节点接收到请求,也会路由到主节点去完成。镜像节点仅仅起到备份数据作用。
当主节点接收到消费者的ACK时,所有镜像都会删除节点中的数据。
总结如下:
- 镜像队列结构是一主多从(从就是镜像)
- 所有操作都是主节点完成,然后同步给镜像节点
- 主宕机后,镜像节点会替代成新的主(如果在主从同步完成前,主就已经宕机,可能出现数据丢失)
- 不具备负载均衡功能,因为所有操作都会有主节点完成(但是不同队列,其主节点可以不同,可以利用这个提高吞吐量)
4.2.镜像模式的配置
镜像模式的配置有3种模式:
| ha-mode | ha-params | 效果 |
|---|---|---|
| 准确模式exactly | 队列的副本量count | 集群中队列副本(主服务器和镜像服务器之和)的数量。count如果为1意味着单个副本:即队列主节点。count值为2表示2个副本:1个队列主和1个队列镜像。换句话说:count = 镜像数量 + 1。如果群集中的节点数少于count,则该队列将镜像到所有节点。如果有集群总数大于count+1,并且包含镜像的节点出现故障,则将在另一个节点上创建一个新的镜像。 |
| all (不推荐) | (none) | 队列在群集中的所有节点之间进行镜像。队列将镜像到任何新加入的节点。镜像到所有节点将对所有群集节点施加额外的压力,包括网络I / O,磁盘I / O和磁盘空间使用情况。推荐使用exactly,设置副本数为(N / 2 +1)。 |
| nodes | node names | 指定队列创建到哪些节点,如果指定的节点全部不存在,则会出现异常。如果指定的节点在集群中存在,但是暂时不可用,会创建节点到当前客户端连接到的节点。 |
这里我们以rabbitmqctl命令作为案例来讲解配置语法。
语法示例:
4.2.1.exactly模式
rabbitmqctl set_policy ha-two "^two\\." '"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"'
rabbitmqctl set_policy:固定写法ha-two:策略名称,自定义"^two\\.":匹配队列的正则表达式,符合命名规则的队列才生效,这里是任何以two.开头的队列名称'"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"': 策略内容"ha-mode":"exactly":策略模式,此处是exactly模式,指定副本数量"ha-params":2:策略参数,这里是2,就是副本数量为2,1主1镜像"ha-sync-mode":"automatic":同步策略,默认是manual,即新加入的镜像节点不会同步旧的消息。如果设置为automatic,则新加入的镜像节点会把主节点中所有消息都同步,会带来额外的网络开销
4.2.2.all模式
rabbitmqctl set_policy ha-all "^all\\." '"ha-mode":"all"'
ha-all:策略名称,自定义"^all\\.":匹配所有以all.开头的队列名'"ha-mode":"all"':策略内容"ha-mode":"all":策略模式,此处是all模式,即所有节点都会称为镜像节点
4.2.3.nodes模式
rabbitmqctl set_policy ha-nodes "^nodes\\." '"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]'
rabbitmqctl set_policy:固定写法ha-nodes:策略名称,自定义"^nodes\\.":匹配队列的正则表达式,符合命名规则的队列才生效,这里是任何以nodes.开头的队列名称'"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]': 策略内容"ha-mode":"nodes":策略模式,此处是nodes模式"ha-params":["rabbit@mq1", "rabbit@mq2"]:策略参数,这里指定副本所在节点名称
4.3.测试 [准确模式exactly]
我们使用exactly模式的镜像,因为集群节点数量为3,因此镜像数量就设置为2.
进入控制台:
docker exec -it mq1 bash
运行下面的命令:
docker exec -it mq1 rabbitmqctl set_policy ha-two "^two\\." '"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"'
下面,我们创建一个新的队列:

在任意一个mq控制台查看队列:

4.3.1.测试数据共享
给two.queue发送一条消息:

然后在mq1、mq2、mq3的任意控制台查看消息:
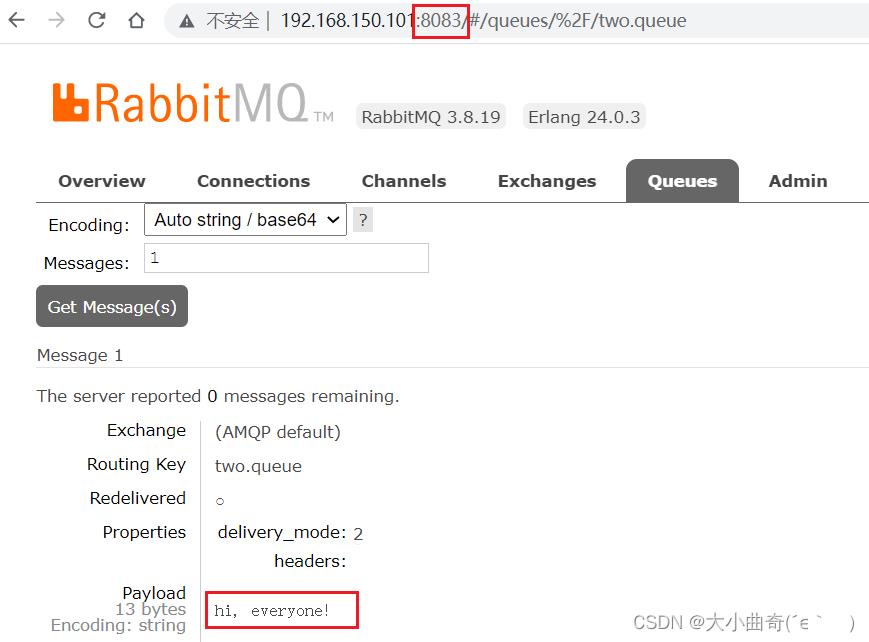
4.3.2.测试高可用
现在,我们让two.queue的主节点mq1宕机:
docker stop mq1
查看集群状态:

查看队列状态:
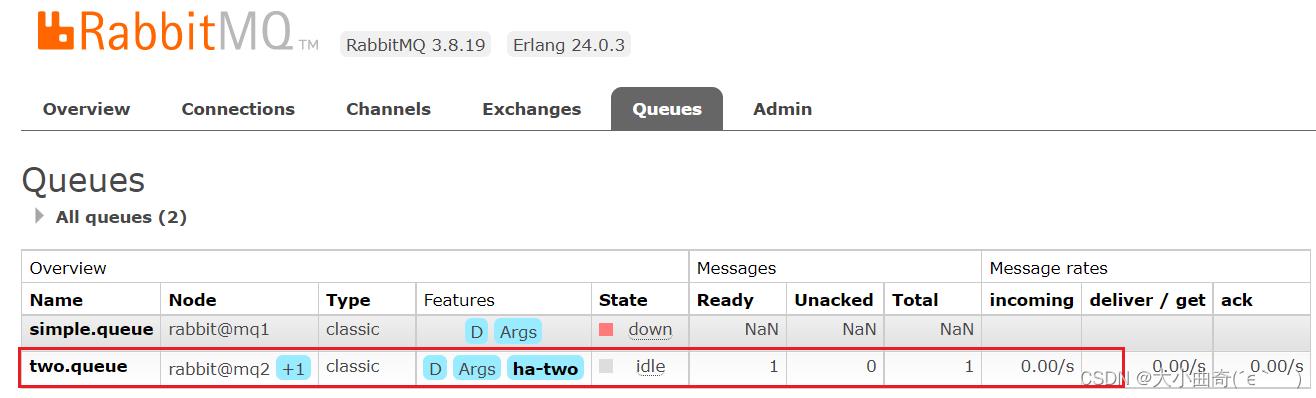
发现依然是健康的!并且其主节点切换到了rabbit@mq2上,集群的健壮性很好;
5.仲裁队列
从RabbitMQ 3.8版本开始,引入了新的仲裁队列,他具备与镜像队里类似的功能,但使用更加方便。
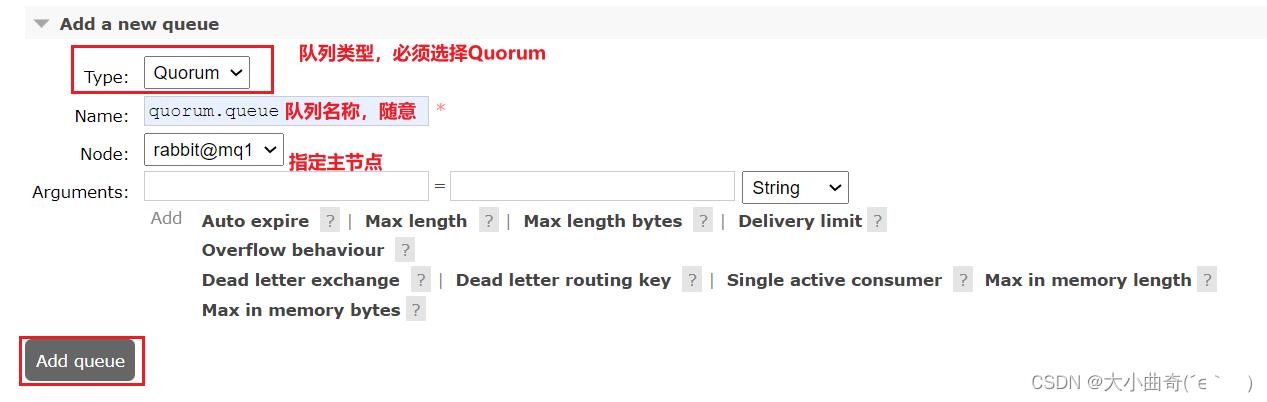
5.1.添加仲裁队列
在任意控制台添加一个队列,一定要选择队列类型为Quorum类型。
在任意控制台查看队列:

可以看到,仲裁队列的 + 2字样。代表这个队列有2个镜像节点。
因为仲裁队列默认的镜像数为5。如果你的集群有7个节点,那么镜像数肯定是5;而我们集群只有3个节点,因此镜像数量就是3.
5.2.测试
可以参考对镜像集群的测试,效果是一样的。
5.3.集群扩容
5.3.1.加入集群
1)启动一个新的MQ容器:
docker run -d --net mq-net \\
-v $PWD/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \\
-e RABBITMQ_DEFAULT_USER=itcast \\
-e RABBITMQ_DEFAULT_PASS=123321 \\
--name mq4 \\
--hostname mq5 \\
-p 8074:15672 \\
-p 8084:15672 \\
rabbitmq:3.8-management
2)进入容器控制台:
docker exec -it mq4 bash
3)停止mq进程
rabbitmqctl stop_app
4)重置RabbitMQ中的数据:
rabbitmqctl reset
5)加入mq1:
rabbitmqctl join_cluster rabbit@mq1
6)再次启动mq进程
rabbitmqctl start_app

5.3.2.增加仲裁队列副本
我们先查看下quorum.queue这个队列目前的副本情况,进入mq1容器:
docker exec -it mq1 bash
执行命令:
rabbitmq-queues quorum_status "quorum.queue"
结果:

现在,我们让mq4也加入进来:
rabbitmq-queues add_member "quorum.queue" "rabbit@mq4"
结果:

再次查看:
rabbitmq-queues quorum_status "quorum.queue"

查看控制台,发现quorum.queue的镜像数量也从原来的 +2 变成了 +3:

关于 Appium 各种版本的安装,都在这里

大家在初次接触 Appium 时会看到网上各种帖子讲解如何安装 Appium,各种 Appium 版本的安装教程满天飞,而很多帖子中提供的安装教程是已经过时了的,容易误导初学者。
这篇文章带着你一起全面了解 Appium 各种版本如何选择如何安装。
一句话概述:
Appium 安装提供两种方式:桌面版和命令行版。其中桌面版又分为 Appium GUI 和 Appium Desktop。
01.Appium GUI
Appium 最先发布的桌面版本,将 Appium 的核心 Server 进行封装提供了图形界面,对初学者比较友好。
下载地址:
[https://bitbucket.org/appium/appium.app/downloads/]
它长这样:

需要注意的是:
目前该项目已经很久没有维护了,针对 Windows 平台最新的版本是 AppiumForWindows_1_4_16_1,里面封装的 Appium server 为 1.4.16,针对 Mac 平台最新的版本是 appium-1.5.3,里面封装的 Appium server 为 1.5.3。
如果要使用较新的 Appium server 显然该项目不满足,所以此版本不推荐。

02.Appium Desktop
Appium GUI 的替代项目,它封装了运行 Appium 服务端的所有依赖,目前该项目持续在维护中。一般 Appium server 更新之后 Appium desktop 也会有对应新版本发布出来。所以强烈建议初学者选择 Appium-desktop,并且安装也非常的容易。
Appium-desktop 是 GitHub 上面的开源项目,源码地址是:
[https://github.com/appium/appium-desktop]
对应安装包下载地址:
[https://github.com/appium/appium-desktop/releases]
建议不要使用最新的,可能会存在一些 BUG,可以选择较新的版本进行安装。这里以 V1.17.1 为例:展开 Assets 选项,选择 windows 平台的安装包。


03.Appium Server 命令行版本
Appium 的核心就是 Appium Server,使用 node.js 语言实现,所以在安装 Appium Server 命令行版本之前我们需要先安装配置 node.js。Appium 命令行版本安装相较于 Appium 图形化版本要复杂很多,建议初学者先安装桌面版本练习,后续再使用命令行版本。
1:下载 node.js
https://nodejs.org/en/download/

2:选择安装路径,笔者这边选择安装到 D 盘
3:打开 cmd 窗口,输入 node -v 以及 npm -v 检测(npm 是 node.js 自带的包管理器)
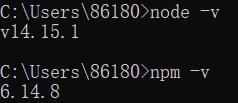
4:指定 npm 安装的全局模块和缓存的路径,如果不指定默认会安装到 C 盘中“C:\\Users\\用户名\\AppData\\Roaming\\npm”。
(1) 在 nodejs 目录下新建“node_cache”和“node_global”目录
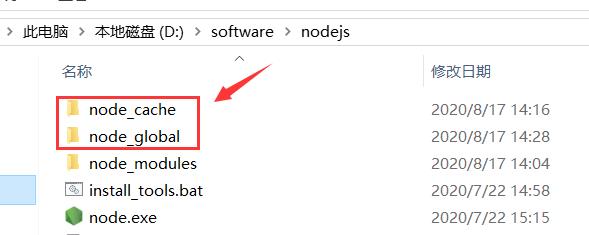
(2) 在 cmd 窗口中输入如下命令:
【】
5:配置 node.js 环境变量
(1) 在系统变量中新建“NODE_PATH”变量名,变量值为 “D:\\software\\nodejs\\node_global\\node_modules”
(2) 在系统变量“Path”中追加“%NODE_PATH%”
(3) 将用户变量“Path”中原来的“C:\\Users\\用户名\\AppData\\Roaming\\npm”修改为“D:\\software\\nodejs\\node_global”
6: 安装 Appium Server
(1) 设置 npm 淘宝镜像地址,执行如下命令:
npm config set registry https://registry.npm.taobao.org
如果安装指定版本(比如 1.17.1),使用如下方式:
npm install appium@1.17.1 -g
(2) npm 通过全局方式安装 Appium Server(默认下载安装最新版本 Appium)
npm install appium-doctor -g
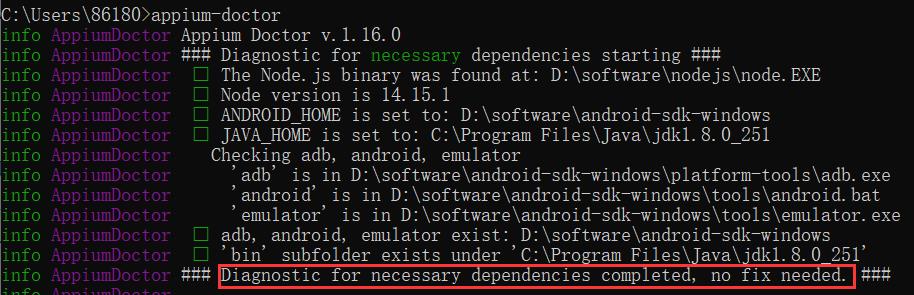
执行 appium-doctor,出现如下提示表示 Appium 环境 OK。
(3) 安装 appium-doctor(用来检测 appium 所需环境依赖,包括 node.js、Android SDK、JDK)。
7: 启动 Appium Server
直接在 cmd 窗口输入“appium”即可启动 Appium Server:


最后: 可以关注公众号:伤心的辣条 ! 进去有许多资料共享!资料都是面试时面试官必问的知识点,也包括了很多测试行业常见知识,其中包括了有基础知识、Linux必备、Shell、互联网程序原理、Mysql数据库、抓包工具专题、接口测试工具、测试进阶-Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架、性能测试、安全测试等。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “评论” “收藏” 一键三连哦!喜欢我们自动化的小伙伴们,可以加入我们的技术交流扣扣群:914172719(里面有超多学习资料免费分享哟)
好文推荐
转行面试,跳槽面试,软件测试人员都必须知道的这几种面试技巧!
以上是关于各种安装2的主要内容,如果未能解决你的问题,请参考以下文章