如何搭建mysql的主从关系
Posted 是九九不是酒酒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何搭建mysql的主从关系相关的知识,希望对你有一定的参考价值。
目录
4.5.4.指定主库的ip 账号密码 日志文件 从什么时候推送日志文件
1.什么是mysql主从
mysql主从就是说,使用多台mysql服务器,实现对于数据的读写分离,分担单台mysql服务器的压力,使用一台服务器作为mysql主库,在这台服务器上实现对数据的写的操作,然后使用一台或多台服务器作为mysql从库,来实现对数据的读的操作
2.为什么要使用MySQL主从
我们都知道mysql是一个关系型数据库,用来存储我们的数据,那么就会有对于某一张表的curd,当我们的访问量和操作量 都比较大时,我们就有可能出现读写冲突,或者压力过大等问题。所以我们采用主从的方式来将数据的读写操作分离,一方面防止读写冲突,另一方面也能减轻单台mysql的压力,提高系统的扩展性和可用性。
3.MySQL主从的实现原理
当我们在mysql主库上进行写的操作时,主库会将操作进行备份,存储到二进制日志binlog中,由从库的I/O线程来读取binlog日志的内容,将主库中写的操作读取到从库并转存到从库的中继日志relaylog中,从库通过SQL线程将relaylog中的内容进行读取并写入库中,实现主从数据同步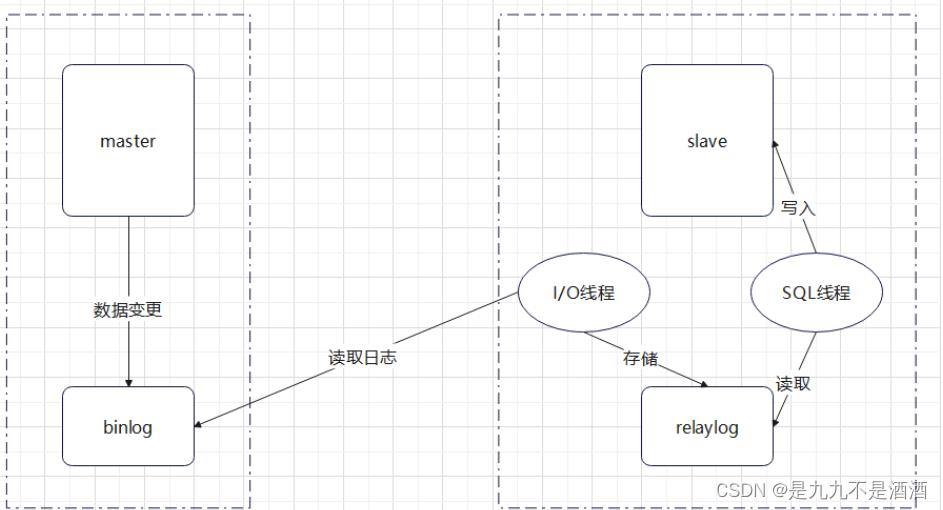
4.如何搭建mysql主从关系
4.1.搭建两台有mysql的虚拟机(可以克隆)
 4.2.保证自己的mysql可以远程访问--以前笔记有
4.2.保证自己的mysql可以远程访问--以前笔记有
设置远程访问
grant replication slave on *.* to 'root'@'192.168.192.131' identified by 'root';
flush privileges;
4.3.修改ip地址(因为我是克隆的)


4.4.主库的搭建
4.4.1.配置mater的配置文件
输入 vi/etc/my.cnf进入编辑模式
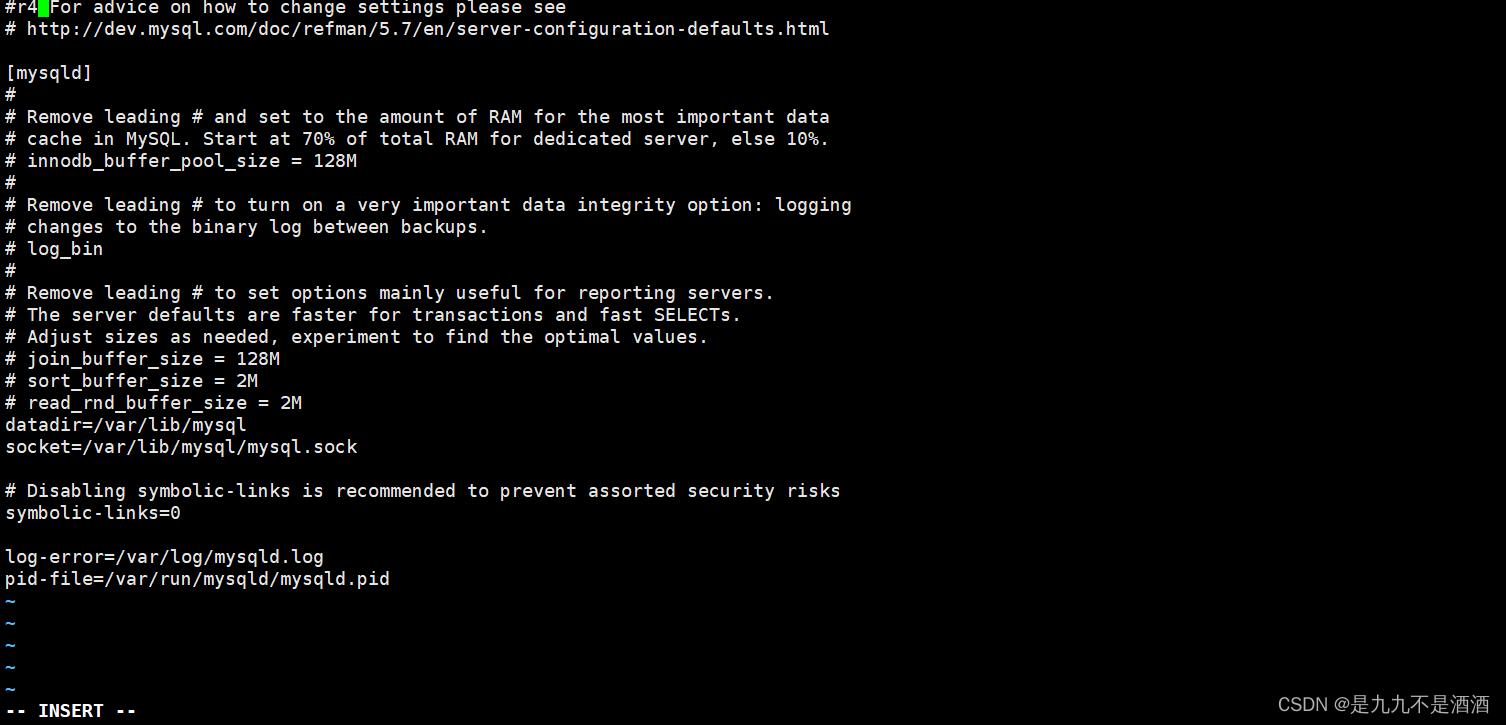
输入配置内容
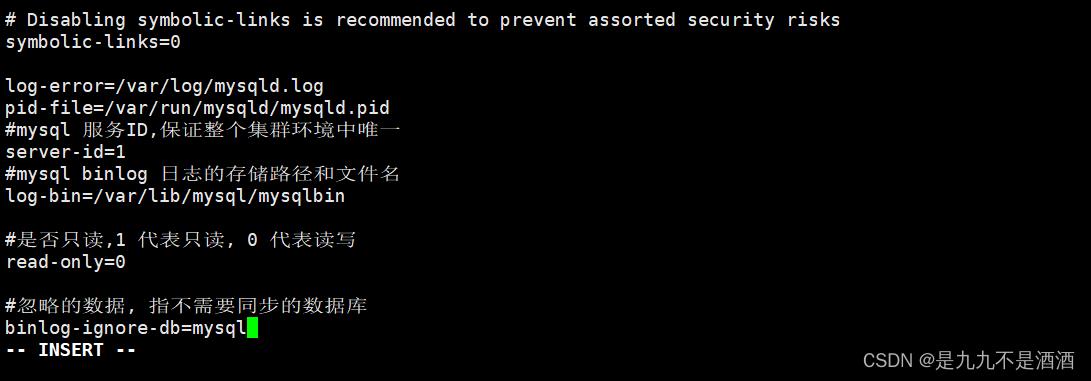
#mysql 服务ID,保证整个集群环境中唯一
server-id=1#mysql binlog 日志的存储路径和文件名
log-bin=/var/lib/mysql/mysqlbin#是否只读,1 代表只读, 0 代表读写
read-only=0#忽略的数据, 指不需要同步的数据库
binlog-ignore-db=mysql
4.4.2.执行完毕之后,需要重启Mysql
systemctl restart mysqld
4.4.3.进入mysql中
mysql -root -p密码
4.4.4. 查看master状态
show master status;

File : 从哪个日志文件开始推送日志文件 给从节点 Position : 从哪个位置开始推送日志 从什么位置开始同步 Binlog_Ignore_DB : 指定不需要同步的数据库
4.5.从库的搭建
4.5.1.配置从配置文件的配置
输入 vi /etc/my.cnf进入编辑模式

#mysql服务端ID,唯一
server-id=2#指定binlog日志
log-bin=/var/lib/mysql/mysqlbin
4.5.2.执行完毕之后,需要重启Mysql
systemctl restart mysqld
4.5.3.进入到数据库
mysql -uroot -p密码
4.5.4.指定主库的ip 账号密码 日志文件 从什么时候推送日志文件
change master to master_host= '192.168.74.152', master_user='root', master_password='1234', master_log_file='mysqlbin.000001', master_log_pos=154;

指定当前从库对应的主库的IP地址,用户名,密码,从哪个日志文件开始的那个位置开始同步推送日志。
4.5.5.开启同步
start slave;

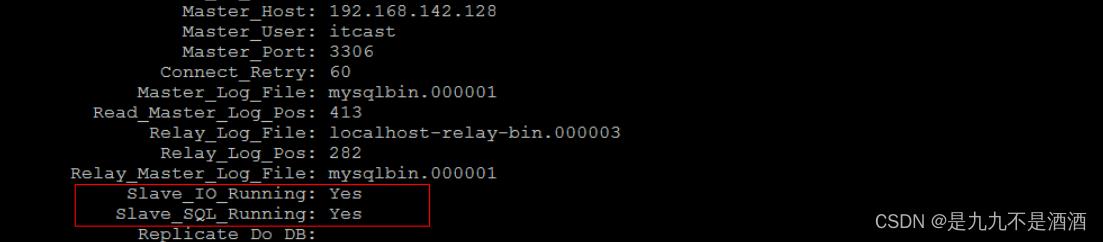
4.5.6.查看同步的状态
show slave status \\G;
出现两个yes 是成功的

4.5.6.如何解决

1.查看主从的server_id变量
show variables like 'server_id';
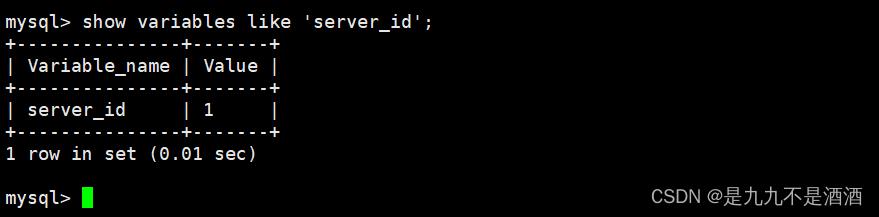
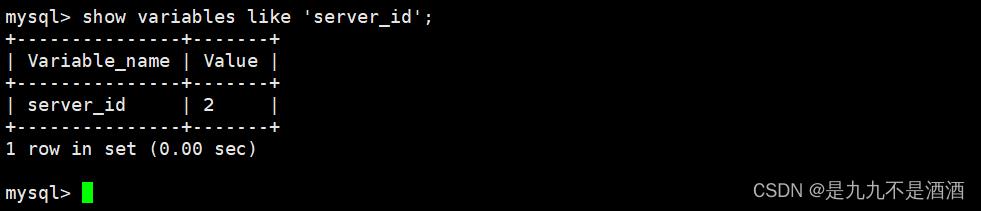 从上面的情形可知,主从mysql已经使用了不同的server_id
从上面的情形可知,主从mysql已经使用了不同的server_id
2.查看auto.cnf文件
找auto.cnf文件文件的位置
find / -name auto.cnf



我们发现两个的UUID相同
3.删除其中一个的auto.cnf文件

4.重启mysql
service mysql restart
5.进入mysql
mysql -uroot -p1234
6.指定当前从库对应的主库的IP地址,用户名,密码,从哪个日志文件开始的那个位置开始同步推送日志。
change master to master_host= '192.168.74.152', master_user='root', master_password='1234', master_log_file='mysqlbin.000001', master_log_pos=154;
7.开启同步
start slave;
9.查看同步的状态
show slave status \\G;
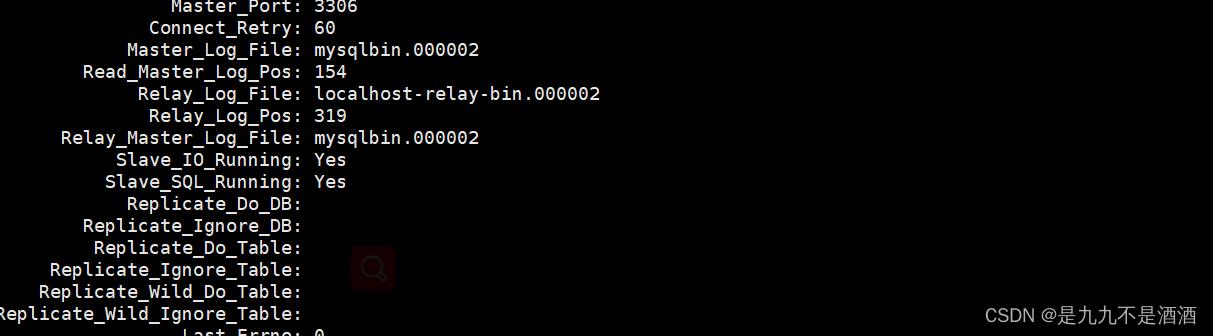 10. 停止同步操作
10. 停止同步操作
stop slave;
第02关 如何体系化掌握数据库?技术选型之数据库选型 基于 docker 搭建 mysql 主从
技术选型之数据库选型
- 2.1 SQL VS NOSQL
- 2.2 关系型数据库的特点和适用场景
- 2.3 非关系型数据库的特点和适用场景
- 2.4 关系型数据库选型步骤
- 2.5 为项目选择适合的数据库
- 2.5.1 Docker 基础操作简介
- 2.5.2 基于binlog搭建MySQL主从服务
2.1 SQL VS NOSQL
这看似并不是一个很难回答的问题,并且在大多数情况下,我们也并不需要来进行选择,因为公司中早就有其他人来帮我们选择好了我们要使用的数据存储系统,但是你有没有想过这种选择是否真的适合我们的系统,又或者如果我们面对的是一个完全崭新的这种项目,那么这时候需要我们来作出选择时,我们要如何来在众多的数据存储系统中来选择出最符合我们需要的系统。
如何选择我们所要使用的数据库系统,那么要选择数据存储系统,我们可以从哪些方面来考虑,我们可以先对数据库中数据的操作方式,这一点上来进行一下筛选。
而从对数据库中数据的操作方式来看,目前来说市场上主要分为 SQL 和 NOSQL 两类,

那么SQL类系统顾名思义就是使用 SQL 语言来对数据库中的数据进行操作的这种数据库系统,通常指的是这种关系性的数据库系统,比如我们常见的 MySQL,Oracle,SQLServer或者是PostGreSQL等等,而 NOSQL 则主要指的是不使用 SQL 语言来操作数据库中数据的系统。
虽然 NOSQL 本身它的意思是 no only sql,也就是不仅仅有 sql 的意思,但是不得不说这类系统大多数都并不是以 sql 语言来操作数据的,并且这类系统通常都是非关系型数据库比如 MongoDB,Redis等等。
近年来 NOSQL 系统大行其道,并且有一种说法, NOSQL 最终会替代 SQL 数据库成为数据存储系统的主力。
不过从目前来说, SQL 和 NOSQL 的系统使用情况来看,SQL 类系统还是处于绝对的霸主地位的,其实也并没有什么系统是能适合所有业务的,SQL 系统 和 NOSQL 系统都有它们所擅长的领域。那么下面我们就分别来看一下这两种数据库存储系统的特点和它们所适用的应用领域。
2.2 关系型数据库的特点和适用场景
首先从数据的存储方式来说,关系型数据库中的数据都是按照一定的结构来进行存储的。
也就是说在存储数据之前,我们要先定义好数据的存储的结构,也就是我们常说的表结构,那么在关系型数据库系统中存储在一个表中的所有数据的行都具有相同的列属性,并且表的定义通常要求是标准的二维表,
那么就像我们现在所看到的用户表,

我们可以看到在这个表中一共有三行数据,每一行数据都具有相同的列属性,比如说姓名、性别、生日和注册时间,这些都是列属性,这个就是一个标准的二维表。
当然了这种情况现在也有了一些变化,目前在很多的关系型数据库中都支持Json类型的列数据类型,【JsonField ORM Python 需要MySQL8.0】那么在 Json 类中我们可以存储非结构化的数据,这就是关系型数据库,也具有了一些非关系型数据库的特点,可以存储非结构化的数据,但是这也仅限于使用 Json 这种类型的列,从整体上来看关系型数据库的结构还是这种结构化的。
那么关系型数据库系统的第二个特点就是支持事务的ACID特性,也就是说是事务的原子性、一致性、隔离性和持久性,可以保证存储在数据库中的数据是完整的,不会出现一个事务中的多条 SQL 只有部分被成功执行的情况,也不会出现丢失了已提交事务的对数据修改的这种情况。
最后关系型数据库都是支持使用 SQL 语言来对数据库中的数据进行操作的,SQL 语言可以灵活的对数据库中的数据进行组合并操作,那么还可以对多个表通过关联关系来进行关联的查询,这一点是很多非关系型数据库很难做到的。
那么了解了关系型数据库的特点,我们就不难看出关系型数据库的一些适应场景了。
首先如果我们的业务数据之间是存在着某种关联关系的,并且需要通过这些关系来操作存储在数据库中的数据,那样就非常适合使用关系型数据库了。
那么什么是数据库之间的关系?这里我们来举一个例子,比如订单和订单商品之间就存在着关系,我们一个订单可以包括多个商品,而某一个订单中的商品它只能属于一个订单,再比如我们在 CSDN 上来发一篇博客,那么这个博客就只能属于一个人,而一个人就可以发行多篇博客,那么这个东西就叫做关系。
所以我们可以发现大多数情况下,我们都可以使用关系型数据库来解决我们数据的存储问题。
再有如果我们的业务场景是需要严格的保证所存储数据的完整性的话,就需要这个数据存储系统对事务进行完全的支持,这时也就只能使用关系型数据库系统了。
比如在一些金融类的电商类的应用中,毕竟我们谁也不会希望自己的账户中的钱莫名其妙的就会减少,而只有关系型数据库是可以保证做到事务的完整性。
最后如果我们需要对数据进行灵活的统计分析,需要利用 SQL 语言来处理存储的数据的话,那么也建议使用关系型数据库系统,毕竟我们把数据保存在数据库中是为了使用的,而只有关系型数据库系统可以完美的支持SQL 语言。
虽然也有非关系型数据库,现在开始来支持 SQL 语言了,但是其对 SQL 语言特性的支持还是很有限的。
2.3 非关系型数据库的特点和适用场景
首先非关系型数据库的存储结构是非常灵活的,那么以 MongoDB 为例,它就是以 Json 格式来进行数据存储的,可以没有固定的结构,也就是说每一行的数据可以具有不同的列。
比如我们还是以存储用户注册数据这个例子来说,

那么以 Json 格式存储的话,我们可以看到张三李四和王二这三个人可以具有不同的属性,相比于关系型数据库系统来说要灵活的多,不用一开始就把这个数据结构固定下来,但是也有一些问题,这就是每一行数据都要包括列数据之外,还要包括我们的列名,如果不考虑压缩的情况下,从存储空间的占用上来说,通常来说存储相同的数据,非关系型数据库要比关系型数据库占用更多的存储空间。
那么同时由于非关系型数据库大都是不会完全支持事务的所有特性的,所以在查询和写入数据时,也不用对数据的完整性来进行检查,所以读写效率上通常要比关系型数据库要高,非常适合使用在日志处理的业务场景中。
最后非关系型数据库大都是不是用 SQL 语言来进行操作的,比如 MongoDB,ta使用的就是 JavaScript 来操作数据的,那么除了上面说过的日志类处理的场景之外,非关系型数据库还适合使用在哪些场景下呢?
首先就是我们无法固定数据结构的场景,比如我们要存储产品的属性数据,由于每类产品的储量的数量都是不完全相同的,有的产品可能是具有产地,重量,长宽这些属性,而有的产品则可能会具有诸如这种颜色,味道这些属性,所以就比较适合于使用 MongoDB 这样的数据库来进行存储。
还有对事务的完整性要求并不是十分严格的应用场景,如果这种应用场景下读写的并发又非常大,那就更加适合于使用非关系型数据库了。
比如前面提到过的这种日志监控类的应用,以及用户行为分析类的应用,那么这类应用的共同特点就是对数据的这种完整性要求不高,比如我们偶尔丢失一些数据,也并不会对用户的整个行为带来什么太大的影响。
同时在用户的操作行为比较频繁的情况下,数据量和并发量都会比较大,这就不适合使用关系型数据库来进行存储了。
那么最后由于非关系型数据库大多都是不支持 SQL 语言的,所以无法做到对数据的灵活处理,所以也比较适合工作在对数据处理需求比较简单的场景下,那么比如只是要求简单的数据汇总等等,在这种场景下也是可以使用非关系型数据库。
那么以上就是关系型数据库和非关系型数据库的特点和它们各自比较适合的场景。
那么在实际工作中,大家都可以根据自己的业务特点,分析并选择自己所要使用的数据的存储系统。
2.4 关系型数据库选型步骤
那么在众多的关系型数据库中,我们要如何来选择?
接下来我们来看一下关系型数据库的一些选型的原则。
首先我们要选择一个系统,第一点就是要来看它是否已经被广泛的使用了,因为只有已经被广泛使用的系统,当出现问题的时候,我们才能更容易的来找到足够的资料来进行处理。【软件生态很重要】
其实这就和我们买车一样,只有一款车有足够的市场占有率,当我们修车的时候才能容易的来找到修车的地方。
而另一方面,一款数据库系统被使用的足够多时,也说明系统的稳定性和性能已经被大家所认可了。那么在选择关系型数据库时候,数据库的可扩展性也是一个必须要被考虑的因素。
数据库在系统中是一个非常关键的组成部分,数据库的性能也决定了整个系统的性能,所以一款数据库是否足够的稳定,是否有足够的扩展性,就显得尤为重要了。
第三点,数据库的安全性和稳定性,数据是我们企业的重要的资产,我们把数据保存在数据库中,总不希望我们的数据可以随意的被人获取,所以是否能够有效的来保证存储在系统的数据的安全,也就成为了我们选择一个数据存储系统的重要的条件。
接下来选择一个关系型数据库系统的第四点依据,这个系统是否能够支持我们所使用的操作系统的版本,因为毕竟一些操作系统有的是收费的,有的是免费的,如果我们并不想支付这种大量的软件费用的话,那么我们可能只能选择那些可以运行在这种免费的像Linux系统下的这种数据库系统。
那么最后除了操作系统的软件费用之外,数据库系统是否可以免费使用,是否可以很容易的找到关系型数据库,是否可以找到足够熟悉的运维和开发人员,也就是我们在选择一款软件系统时所必须考虑的一个因素。
那么如果一个系统虽然说它是系统本身是免费的,在市场上却很难找到熟悉的运维和开发人员,那么它的使用成本也会相当的高。
2.5 为项目选择适合的数据库
MySQL开源免费。
所以如果大家在项目中不考虑软件成本的话,或者项目并没有太多的软件预算,我们可以选择MySQL。
那么我们再来看一下 MySQL 的扩展性是不是能够满足我们的需要。MySQL 本身是支持基于二进制日志的逻辑复制的,并且其配置也非常简单和灵活,可以对一个实体下的所有数据库,或者是某一实例下的某一个数据库,甚至是某一个表来进行复制,并且存在着很多的第三方数据库中间层,支持读写分离和分库分表。
通过这些数据库中间层,我们可以很容易的来实现对数据库的读写分离和分库分表,因此可以说 MySQL 其本身是具有很好的扩展性。
接下来我们再来看一看 MySQL 的安全性和稳定性是不是符合我们的要求,同样得益于主从复制的功能,在部署了主从复制的MySQL 集群,本身是可以提供99%的可用性的。
如果我们同时配合像 MYISAM 这样的主从复制高可用架构的话,这种可能性可以提升到99.99%的范围。
那么另外对于数据安全性上来说,MySQL 支持对数据进行加密存储,同时还支持多级别的这种用户授权。我们可以对实例与数据库,对表或者是对表中的某一列来进行控制,以保证数据的安全性。
另外从所支持的操作系统来看, MySQL 同时会支持Linux系统和 Windows系统,所以从这一点来看,我们选择 MySQL 作为数据存储系统也是没有什么问题的。
最后我们再来看一看 MySQL 的使用成本,社区版本和企业版本的区别就在于一些附加的功能,主要的功能并无太大的区别,并且经过这几年的发展,MySQL 的运维和开发人员也逐渐多了起来,可以很容易的找到需要的运维和开发人员,更可以方便的获取这种社区的支持。
那么基于以上几点我们可以看出来,使用 MySQL 来作为我们的项目的数据库,来用于数据存储的是完全符合我们的需求的。那么既然我们已经做出了选择,那么下面我们就来看一下如何部署一个项目体系中所需要的一种实战环境。
2.5.1 Docker 基础操作简介
容器的话,我们使用一个工具叫做Docker,在我们开发中 Docker 在我们一台机器上面可以起多个容器,每个容器相当于我们独立的一个服务器,在实际开发中我们每个 Docker 的容器,那就可以当一个独立的服务器来使用。
我们的思路是用 Docker 新建两个 MySQL 的容器,
然后我们一台容器当做主,另一台当做从,
下载 Docker 滴话,访问如下链接:
https://www.docker.com/products/docker-desktop/
根据自己的操作系统选择性的下载:



安装好之后我们来打开 Docker ,这个主要是帮我们启动了一个 Docker 的引擎,我们看它到这儿是正在启动这个状态,当它启动起来以后,我们打开一个命令行窗口,等他现在已经启动起来了。

好,我们先来认识一下 Docker,先在命令行里面输入命令 Docker ,

看这就是 Docker 的命令行,Docker 它的操作方式主要是靠命令行的方式。在我们认识 Docker 命令之前,我们先要明白两个 Docker 的基本概念,第一个基本概念叫做 image,什么是 image?我们简单的来理解它就是一个镜像。
第二个就是 container,container 就相当于是我们镜像起的一个实例。
打一个比方,镜像就相当于是我们 Windows 系统的安装光盘,我们 container 就相当于是我们拿镜像盘我们安装了 Windows 的系统,可以在系统里面做一些事情,我们 Docker 上面这些镜像它是怎么的一个管理方式呢?
我们打开一个网站叫 https://hub.docker.com/,这是 Docker 的镜像网站,在这个网站上面,它管理了好多的我们常用的镜像,比如说我们常用的 MySQL 镜像,在这里我们输入 MySQL,这里面搜出来第一个这是我们需要的 MySQL 镜像 ,

新页面打开它 https://hub.docker.com/_/mysql 就是 MySQL 镜像的介绍,下面包括 MySQL 镜像的一些使用。

https://hub.docker.com/search?q=mysql&type=image

大家看 MySQL 其实我们这么理解的,它并不是说镜像里面只有一个 MySQL,它是整个包含我们底层需要用到的Linux系统,在这个系统上面ta在装了一个 MySQL,相当于我们把镜像安装到我们 container 里面去,我们这上面就相当于是一个整个的 MySQL 运行环境,我们可以简单的把一个运行起来的MySQL container ,当做是 MySQL 的一个服务器。
首先我们看怎样把我们MySQL 镜像给拉取到我们本地。


这里面它有一个 docker pull mysql,一般 docker pull mysql 拉取的是 MySQL 镜像的最新版本,我们有时候也需要它的历史版本,

然后如图所示点开,看它的历史版本,

这个历史版本有各种,latest八点几,还有5.7等等这些,我们需要一个历史版本的时候,

我们执行:
docker pull mysql:5.7
发现M1 arm的兼容问题:

问题:docker: no matching manifest for linux/arm64/v8 in the manifest list entries.
原因:

参考链接:
https://docs.docker.com/desktop/mac/apple-silicon/
总结:
遇到问题,我们第一步是理解问题,这是个什么问题?
可以借助搜索来帮助我们理解问题,见参考链接,
我们知道了这是docker app m1 兼容性的坑,怎么做?
如下:
docker pull --platform linux/x86_64/v8 mysql:5.7
这样的话就把镜像拉取到我们本地了,相当于我们把一个 Windows 的光盘下载下来,那么把这个光盘下载下来之后,我们怎么来启动它?
完整命令:
docker run --name=mysql-test -e MYSQL_ROOT_PASSWORD=ZXCzxc123 -d --platform linux/x86_64 mysql:5.7
运行没问题如图:

你可以参考学习,也可直接忽略此步骤:
网址是:https://hub.docker.com/_/mysql?tab=description

我们来看这里,下面有ta的一个命令介绍,需要加一些参数,比如
–name
-e
-d
啥的,
我们在命令行输入 docker run --help 来看一下。

首先我们看看-d。

这是在后台启动了一个我们的镜像,
然后第二个 --name,

这是给我们的 container【容器】 起一个别名,
别名是什么意思?

我们看 container,首先它有container ID,我们在container的start stop操作的时候,我们可以用它的 ID来操作,但是这个ID毕竟不是太方便,所以ta还起了一个别名叫NAMES,

我们在操作的时候,比如说docker start一个 container,我们就可以start myjenkins或者micro-mysql,我们可以这么来操作,这样会让我们操作更方便一些。【同样的道理,域名是不是比ip地址好记一点?】
-e的话,我们看一下它的一个定义是什么?

这是environment value,相当于在我们 container 启动之后,container 的内部设置了一些环境变量,这样的话我们可以把外面的一些设置给到我们的 container 里面去。
在这里docker run --name some-mysql -e MYSQL_ROOT_PASSWORD=my-secret-pw -d mysql:tag我们就相当于在mysql container里面,我们设置了一个 MYSQL_ROOT_PASSWORD 环境变量,在它 这个 container 启动的时候会读一下我们这个环境变量,读取之后就把它设置成 mysql 的一个root密码。
通过这样的方式,我们指定了镜像里面 mysql 的一个root password,后面这个mysql:tag就是我们的image的镜像。
那么下面我们run 一个 mysql的镜像,
然后我们加一个环境变量,我们给它设置一个简单的 password,在测试环境里面我们可以设置一个简单的password,大家如果在线上用的时候 password 还是要复杂一点,
然后-d后面启动一个mysql5.7的镜像。

大家看这样的话就 run 起来了,run 起来之后我们执行docker ps -a,这样镜像就有了,

容器 ID 是 f32287b0de02
镜像 ID 是 mysql:5.7,
我们看这里我们后面给它起的名字 NAMES 叫 mysql-test,
这样的话就相当于是我们已经跑起来了这个镜像,在我们的机器上面相当于是有一台 mysql 的服务器了。
我们的 container 跑起来之后 怎么样 来登录到这个 container 上面去。
我们用到一个命令叫 docker exec --help,

我们看一下它的格式,这里面我们需要用到两个参数,杠i和杠t。
杠t的话就相当于帮我们打开一个模拟的命令行窗口,
杠i的话就是保持标准输入的连接,
这两个加起来相当于是保持和我们的 container 相互交互的命令行。
我们来打开 container 。
docker exec -it mysql-test /bin/bashdocker exec 加上 -it 这两个参数,
然后我们的 container 名字是 mysql-test,mysql-test 后面我们需要加一个参数 就是/bin/bash,表示 container 它的一个脚本命令行窗口。

这样的话大家看前面的提示变了,就相当于我们直接登录了 mysql 服务器的root账号下。

我们来 ls 一下,显示的是我们 mysql container 里面的机器的一些文件,在这上面就可以直接操作 container 里面的东西了。
像刚才说我们直接执行mysql -uroot -pZXCzxc123,

这样的话就是我们 mysql 内部的这些环境,
执行show databases;

就是查看数据库,这里可以看到一些默认的库,
exit直接退出,

这样就回到我们自己的容器命令行里面了,回到我们本机了。
我们的 container 怎么来管理?
比如说我们有时候在配置完一些环境的时候,我们需要重启一下 container,怎么做?
我们先查看一下 container 名字,
docker ps
docker ps 命令会把我们所有运行起来【Up】的 container 给展示出来。
如果我们电脑重启了以后,我们这些 container 其实就没有自动跑起来了,怎么样找到我们之前的这些 container,输入命令叫docker ps -a就把我们所有的 container 都给显示出来,【Up 和 Exited 】

大家看这里面有我们之前跑起来的容器以及它的一个状态,
Exited 是已经退出了,相当于我们的机器已经关了。
Up 正常状态。
我们想把 container 重启一下怎么办?
docker restart container_id/names我们重启完之后再执行docker ps,

如果我们重启完之后,相当于我们只启动了2秒了,
重启起来之后我们怎么来关闭它?
docker stop container_id/names我们关闭完之后再执行docker ps,

我们再来启动 mysql-test,

以上是 docker 基础的使用命令,当然 docker 其实还有其他更多复杂的命令,包括ta的镜像管理镜像生成等等这些,大家有兴趣的话,就看一下ta的官方文档,
https://docs.docker.com/
试着来操作一下。
2.5.2 基于binlog搭建MySQL主从服务
创建master镜像。
命令:
docker run -p 3339:3306 --name mysql-master -e MYSQL_ROOT_PASSWORD=ZXCzxc123 -d --platform linux/x86_64 mysql:5.7

接下来我们再创建一个 slave 镜像,
命令:
docker run -p 3340:3306 --name mysql-slave -e MYSQL_ROOT_PASSWORD=ZXCzxc123 -d --platform linux/x86_64 mysql:5.7

那么执行完上面两个命令以后,我们就创建了两个 docker 的container,我们再打开一个命令行,我们先到 master 的容器里面去,操作命令如下:
docker exec -it mysql-master /bin/bash
大家看我们前面的提示已经到了我们的容器里面来了,提示组成是root@Container ID,相当于我们已经登录到容器里面了,这个机器是一个Linux的环境,我们登录 mysql 默认的 root 账号:
mysql -uroot -pZXCzxc123

那么接下来我们就要给外部来加一些账号,
为指定的数据库配置 指定的账户。
我们创建一个账号,操作指令如下:
create user "user_keagen"@"%" IDENTIFIED BY "ZXCzxc123";

我们新建用户 user_keagen,可以给他指向我们所有的机器,配置了任意ip都可以连入数据库的账户。
创建完账号以后,继续操作:
我们设置权限账号密码,操作指令如下:
https://tableplus.com/blog/2019/09/access-denied-for-user-root-localhost-mysql.html
# 设置权限账号密码
# 授权账号命令:grant 权限(create, update) on 库.表 to 账号@host identified by 密码
#1. 配置任意ip都可以连入数据库的账户
GRANT ALL PRIVILEGES ON *.* TO "user_keagen"@"%" IDENTIFIED BY "ZXCzxc123";
#2. 由于数据库版本的问题,可能本地还连接不上,就给本地用户单独配置
grant all privileges on *.* to user_keagen@localhost identified by ZXCzxc123;
# 可以使用以下语句访以上是关于如何搭建mysql的主从关系的主要内容,如果未能解决你的问题,请参考以下文章