Oracle数据库执行慢问题排查
Posted kida_yuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle数据库执行慢问题排查相关的知识,希望对你有一定的参考价值。
文中使用的Oracle版本为10g。
这是之前在工作中遇到的慢查询排查记录,为了防杠先做个声明。
“All Roads Lead to Rome”
以下方法是本人处理思路以及在排除掉其他外部因素后,只针对数据库层面的排查内容。当然了肯定有更好的排查方式,这里只是提供一个方案而已。
1. 若出现插入速度慢或者无法插入数据的情况下,先检查表空间
SELECT UPPER(F.TABLESPACE_NAME) "表空间名",
D.TOT_GROOTTE_MB "表空间大小(M)",
D.TOT_GROOTTE_MB - F.TOTAL_BYTES "已使用空间(M)",
TO_CHAR(ROUND((D.TOT_GROOTTE_MB - F.TOTAL_BYTES) / D.TOT_GROOTTE_MB * 100, 2), '990.99') || '%' "使用比",
F.TOTAL_BYTES "空闲空间(M)",
F.MAX_BYTES "最大块(M)"
FROM (SELECT TABLESPACE_NAME,
ROUND(SUM(BYTES) / (1024 * 1024), 2) TOTAL_BYTES,
ROUND(MAX(BYTES) / (1024 * 1024), 2) MAX_BYTES
FROM SYS.DBA_FREE_SPACE
GROUP BY TABLESPACE_NAME) F,
(SELECT DD.TABLESPACE_NAME,
ROUND(SUM(DD.BYTES) / (1024 * 1024), 2) TOT_GROOTTE_MB
FROM SYS.DBA_DATA_FILES DD
GROUP BY DD.TABLESPACE_NAME) D
WHERE D.TABLESPACE_NAME = F.TABLESPACE_NAME
--and F.TABLESPACE_NAME = '<tablespace>'
ORDER BY 1;
上面的脚本已经将列名都用中文标识清楚了,若用户表空间使用率达到峰值,则基本只能查询,其他的操作都不能做了。除此之外,本脚本还可以看到系统的表空间情况,其中值得注意的是UNDOTBS1这个表空间,如下图:

这个是回滚表空间,越大越能够储存回滚段。在做提交操作或者复杂运算的时候这里的使用率会飞涨。这个表空间是系统自动回收的,当系统判断资源不需要被使用之后表空间将会被回收。但若这个表空间长时间不回收就需要留意是否存在大批量的提交操作甚至锁表情况出现。
2. 表空间正常但发现只能查询不能修改或者插入时,可以初步判定存在锁表的可能性
通过以下语句查询是否存在表级锁
SELECT SESS.SID,
SESS.SERIAL#,
LO.ORACLE_USERNAME,
LO.OS_USER_NAME,
AO.OBJECT_NAME,
LO.LOCKED_MODE
FROM V$LOCKED_OBJECT LO, DBA_OBJECTS AO, V$SESSION SESS
WHERE AO.OBJECT_ID = LO.OBJECT_ID
AND LO.SESSION_ID = SESS.SID;
一般情况下会在做DML操作时系统会自动分配一个行级排它锁。同时这个事务就会获得一个表锁以防止其他的DDL操作影响DML操作。以上说的都是系统自动操作的,但是需要用到上面语句来进行查询的时候应该大多数情况都是产生了死锁,即多个DML操作产生了冲突引起的锁。这个时候就只能查询出来锁的SID和SERIAL#来将其KILL掉。
除此之外还有其他找锁表的语句,譬如:
SELECT (SELECT USERNAME FROM V$SESSION WHERE SID = A.SID) BLOCKER,
A.SID,
'IS BLOCKING',
(SELECT USERNAME FROM V$SESSION WHERE SID = B.SID) BLOCKEE,
B.SID
FROM V$LOCK A, V$LOCK B
WHERE A.BLOCK = 1
AND B.REQUEST > 0
AND A.ID1 = B.ID1
AND A.ID2 = B.ID2;
找到SID和SERIAL#字段信息并KILL掉当前死锁执行脚本如下:
ALTER SYSTEM KILL SESSION 'SID,SERIAL#';
还有很多情况也会产生出锁表的现象,不过本人经历过最多的锁表原因都在于:
- 应用程序的编写不当引起,包括JDBC连接没有正常关闭,通过循环提交负责级联更新操作等
- 数据库 存储过程/触发器 编写逻辑混乱引起的同表资源抢占(一个操作没有完成就又要提交另一个操作)
- 数据库利用定时器模仿多线程进行同表数据DML操作
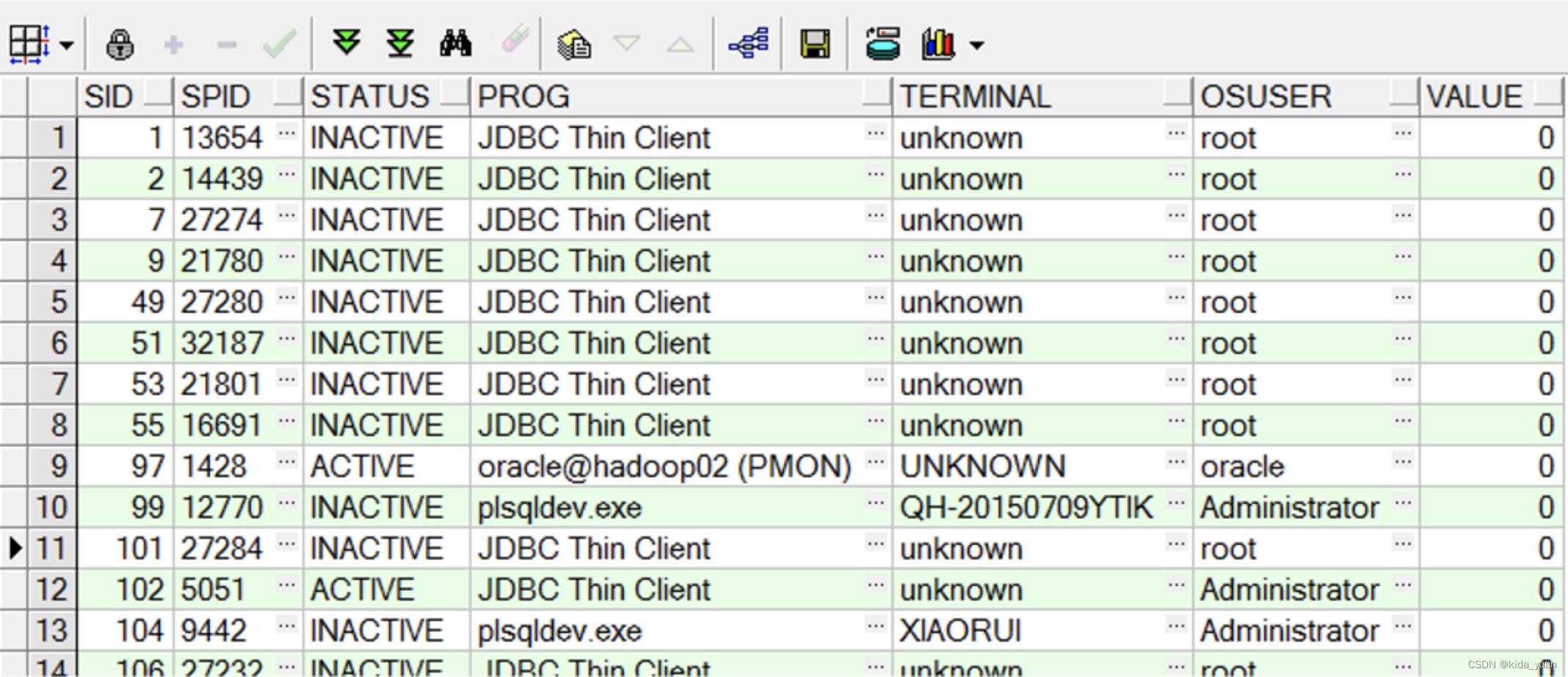
3. 服务器端出现多个Oracle进程并CPU占用率高
要想知道是那个数据库用户在占用CPU可以使用以下语句找到:
SELECT A.SID,
SPID,
STATUS,
SUBSTR(A.PROGRAM, 1, 40) PROG,
A.TERMINAL,
OSUSER,
VALUE / 60 / 100 VALUE
FROM V$SESSION A, V$PROCESS B, V$SESSTAT C
WHERE C.STATISTIC# = 12
AND C.SID = A.SID
AND A.PADDR = B.ADDR
-- AND STATUS = 'ACTIVE'
ORDER BY VALUE DESC;
执行后如下图所示,可以通过图中的字段知道哪个用户是通过哪种方式连接到数据库的,是否在线状态,数据库中执行id是什么,操作系统中是那个用户,CPU耗时多长时间,以此来定为那个用户。
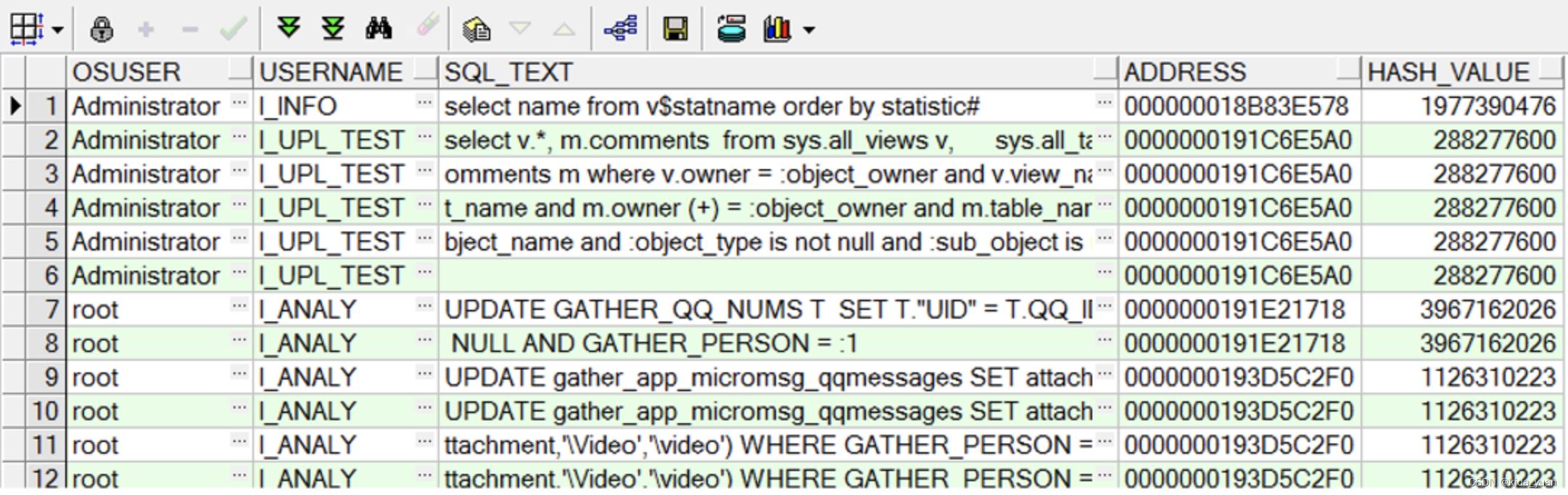
4. 进一步深挖究竟执行什么导致CPU使用率高
SELECT OSUSER, USERNAME, SQL_TEXT, ADDRESS, HASH_VALUE
FROM V$SESSION A, V$SQLTEXT B
WHERE A.SQL_ADDRESS = B.ADDRESS
--AND USERNAME = 'I_INFO'
ORDER BY ADDRESS, PIECE;
执行之后如下图所示,查询出来后可以根据USERNAME来进行筛选,再来拿到语句的ADDRESS(SGA内存地址)和HASH_VALUE(Oracle Hash值)进行后续查询。
下面脚本将根据ADDRESS和HASH_VALUE来找到对应SQL执行性能消耗情况:
SELECT HASH_VALUE,
BUFFER_GETS,
DISK_READS,
EXECUTIONS,
PARSE_CALLS,
CPU_TIME
FROM V$SQLAREA
WHERE HASH_VALUE = 1977390476
AND ADDRESS = HEXTORAW('000000018B83E578');
执行之后可以看到BUFFER_GETS(所有子游标运行这条语句导致的读内存次数),DISK_READS(所有子游标运行这条语句导致的读磁盘次数),EXECUTIONS(所有子游标的执行这条语句次数),PARSE_CALLS (语句的解析调用(软、硬)次数),CPU_TIME (语句被解析和执行的CPU时间),如下图:

一般来说EXECUTIONS,BUFFER_GETS越高表示读内存多,磁盘少是比较理想的状态,因此越高越好。
之后若发现语句资源消耗异常可以从SQL_TEXT找到对应的语句,放到执行计划里面进行分析看看具体是那个地方造成性能问题。
5. 还有另一种解法获取等待时间长的用户和执行语句
SELECT S.SID, S.USERNAME, SUM(A.WAIT_TIME + A.TIME_WAITED) TOTAL_WAIT_TIME
FROM V$ACTIVE_SESSION_HISTORY A, V$SESSION S
WHERE A.SAMPLE_TIME BETWEEN SYSDATE - 30 / 2880 AND SYSDATE
GROUP BY S.SID, S.USERNAME
ORDER BY TOTAL_WAIT_TIME DESC;
SELECT A.PROGRAM,
A.SESSION_ID,
A.USER_ID,
D.USERNAME,
S.SQL_TEXT,
SUM(A.WAIT_TIME + A.TIME_WAITED) TOTAL_WAIT_TIME
FROM V$ACTIVE_SESSION_HISTORY A, V$SQLAREA S, DBA_USERS D
WHERE A.SAMPLE_TIME BETWEEN SYSDATE - 30 / 2880 AND SYSDATE
AND A.SQL_ID = S.SQL_ID
AND A.USER_ID = D.USER_ID
GROUP BY A.PROGRAM, A.SESSION_ID, A.USER_ID, S.SQL_TEXT, D.USERNAME;
两个脚本里面都有TOTAL_WAIT_TIME字段,这个字段就是这些用户和SQL从产生开始到目前为止等待的最长时间,可以根据这个定位用户和SQL。
若问题仍然存在,就需要注意内存使用情况和Oracle的SGA和PGA分配情况(这个网上有太多方法了就不再叙述)。
后日谈
在另一次慢查询分析时在执行到了第四步“进一步深挖究竟执行什么导致CPU使用率高”后找到了执行慢的语句,进一步执行分析计划后看到语句本应该是主键的ID字段没有走到索引,本以为Oracle会自动基于成本规则选择了别的执行方式。但并没有…后来将这个结果与所在项目组沟通才知道他们在做数据迁移时执行脚本用CTAS方式建表忘记额外生成主键了。
其实我想说的是,只要不是过于复杂的业务过程或者大规模运算的情况下哪有那么多性能问题,往往性能问题都是因为一些“粗心大意”下引起的,听我说多用checklist准没错的。
Mysql通过show processlist排查数据库执行慢
RDS for MySQL使用的是InnoDB引擎。不同于MyISAM引擎只提供表锁,InnoDB提供不同级别的锁。但是在我们日常的操作过程中经常由于对数据库不当的SQL操作导致出现长时间的锁,造成其他的SQL语句长期等待执行。这种现象对于数据库的正常使用带来的极大的阻碍。接下来我们就来介绍如何排查当前实例是否出现该状态。
首先,用户可以登录RDS(通过客户端、DMS等工具都可),在数据库中执行命令:
show processlist
执行结果如图所示:

我们首先来讲述下各字段的含义:
id,该进程的标识;
user,显示当前用户;
host,显示来源IP和端口;
db,显示当前连接的数据库;
command,显示当前连接的执行的命令,一般就是休眠(sleep),查询(query),连接(connect);
time,此这个状态持续的时间,单位是秒;
state列,显示使用当前连接的sql语句的状态,很重要的列;
info,显示这个sql语句,因为长度有限,所以长的sql语句就显示不全,但是一个判断问题语句的重要依据。
当如果用户某个SQL正在query导致别的SQL等待锁的时候,别的SQL的state状态会出现”Waiting for table metadata lock“,如果出现这种情况就会导致大量SQL堆积,实例状态出现异常,因此这个时候就需要用户去根据前面的id,去kill掉导致其他SQL等待锁的正在query的语句,然后其他语句即会正常执行。
以上是关于Oracle数据库执行慢问题排查的主要内容,如果未能解决你的问题,请参考以下文章