基于SpringBoot的ES整合
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于SpringBoot的ES整合相关的知识,希望对你有一定的参考价值。
参考技术AElasticsearch(ES)的作用可看之前的课件
这儿直接演示使用ES检索学习资料的功能。
步骤一: 引入相关依赖,在文件中smpe-system下的pom.xml中引入下面依赖
步骤二: 添加一个配置类,新建目录层级tiku/config/ElasticSearchClientConfig
[图片上传失败...(image-61aba2-1650806738439)]
步骤三: 项目启动的时候将需要的数据加载进ES中
步骤四: 对接查询操作
IEStudyDataService接口
实现类
返回对象ERepositoryAndPracticeRecordDTO为
[图片上传失败...(image-bbead3-1650806738439)]
[图片上传失败...(image-f674ba-1650806738439)]
定义IERepositoryService中的查询接口
实现方法
其中CacheKey.PRACTICERECORD为
好玩的ES--第三篇之过滤查询,整合SpringBoot
好玩的ES--第三篇之过滤查询,整合SpringBoot
过滤查询
过滤查询
过滤查询,其实准确来说,ES中的查询操作分为2种: 查询(query)和过滤(filter)。查询即是之前提到的query查询,它 (查询)默认会计算每个返回文档的得分,然后根据得分排序。而过滤(filter)只会筛选出符合的文档,并不计算 得分,而且它可以缓存文档 。所以,单从性能考虑,过滤比查询更快。 换句话说过滤适合在大范围筛选数据,而查询则适合精确匹配数据。一般应用时, 应先使用过滤操作过滤数据, 然后使用查询匹配数据。

使用
GET /ems/emp/_search
"query":
"bool":
"must": [
"match_all": //查询条件
],
"filter": .... //过滤条件
注意:- 在执行 filter 和 query 时,先执行 filter 在执行 query
- Elasticsearch会自动缓存经常使用的过滤器,以加快性能。
类型
常见过滤类型有: term 、 terms 、ranage、exists、ids等filter。
term 、 terms Filter
GET /ems/emp/_search # 使用term过滤
"query":
"bool":
"must": [
"term":
"name":
"value": "小黑"
],
"filter":
"term":
"content":"框架"
GET /dangdang/book/_search #使用terms过滤
"query":
"bool":
"must": [
"term":
"name":
"value": "中国"
],
"filter":
"terms":
"content":[
"科技",
"声音"
]
ranage filter
GET /ems/emp/_search
"query":
"bool":
"must": [
"term":
"name":
"value": "中国"
],
"filter":
"range":
"age":
"gte": 7,
"lte": 20
exists filter
过滤存在指定字段,获取字段不为空的索引记录使用
GET /ems/emp/_search
"query":
"bool":
"must": [
"term":
"name":
"value": "中国"
],
"filter":
"exists":
"field":"aaa"
ids filter
过滤含有指定字段的索引记录
GET /ems/emp/_search
"query":
"bool":
"must": [
"term":
"name":
"value": "中国"
],
"filter":
"ids":
"values": ["1","2","3"]
整合应用
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
配置客户端
@Data
@Configuration
public class RestClientConfig extends AbstractElasticsearchConfiguration
@Value("$es.host")
private String ES_HOST;
@Override
@Bean
public RestHighLevelClient elasticsearchClient()
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo(ES_HOST)
.build();
return RestClients.create(clientConfiguration).rest();
es默认开放了两个端口进行访问,一个是9200的rest方式访问,一个是9300的tcp方式访问,这里推荐使用9200rest方式的访问

客户端对象
- ElasticsearchOperations
- RestHighLevelClient 推荐
ElasticsearchOperations
- 特点: 始终使用面向对象方式操作 ES
- 索引: 用来存放相似文档集合
- 映射: 用来决定放入文档的每个字段以什么样方式录入到 ES 中 字段类型 分词器…
- 文档: 可以被索引最小单元 json 数据格式
相关注解
@Data
@Document(indexName = "products", createIndex = true)
public class Product
@Id
private Integer id;
@Field(type = FieldType.Keyword)
private String title;
@Field(type = FieldType.Float)
private Double price;
@Field(type = FieldType.Text)
private String description;
//1. @Document(indexName = "products", createIndex = true) 用在类上 作用:代表一个对象为一个文档
-- indexName属性: 创建索引的名称
-- createIndex属性: 是否创建索引
//2. @Id 用在属性上 作用:将对象id字段与ES中文档的_id对应
//3. @Field(type = FieldType.Keyword) 用在属性上 作用:用来描述属性在ES中存储类型以及分词情况
-- type: 用来指定字段类型
索引文档
@Test
public void testCreate() throws IOException
Product product = new Product();
product.setId(1); //存在id指定id 不存在id自动生成id
product.setTitle("怡宝矿泉水");
product.setPrice(129.11);
product.setDescription("我们喜欢喝矿泉水....");
//文档不存在会创建文档,文档存在会更新文档
elasticsearchOperations.save(product);
删除文档
@Test
public void testDelete()
Product product = new Product();
product.setId(1);
String delete = elasticsearchOperations.delete(product);
System.out.println(delete);
查询文档
@Test
public void testGet()
Product product = elasticsearchOperations.get("1", Product.class);
System.out.println(product);
更新文档
@Test
public void testUpdate()
Product product = new Product();
product.setId(1);
product.setTitle("怡宝矿泉水");
product.setPrice(129.11);
product.setDescription("我们喜欢喝矿泉水,你们喜欢吗....");
elasticsearchOperations.save(product);//不存在添加,存在更新
删除所有
@Test
public void testDeleteAll()
elasticsearchOperations.delete(Query.findAll(), Product.class);
查询所有
@Test
public void testFindAll()
SearchHits<Product> productSearchHits = elasticsearchOperations.search(Query.findAll(), Product.class);
productSearchHits.forEach(productSearchHit ->
System.out.println("id: " + productSearchHit.getId());
System.out.println("score: " + productSearchHit.getScore());
Product product = productSearchHit.getContent();
System.out.println("product: " + product);
);
RestHighLevelClient
创建索引映射
@Test
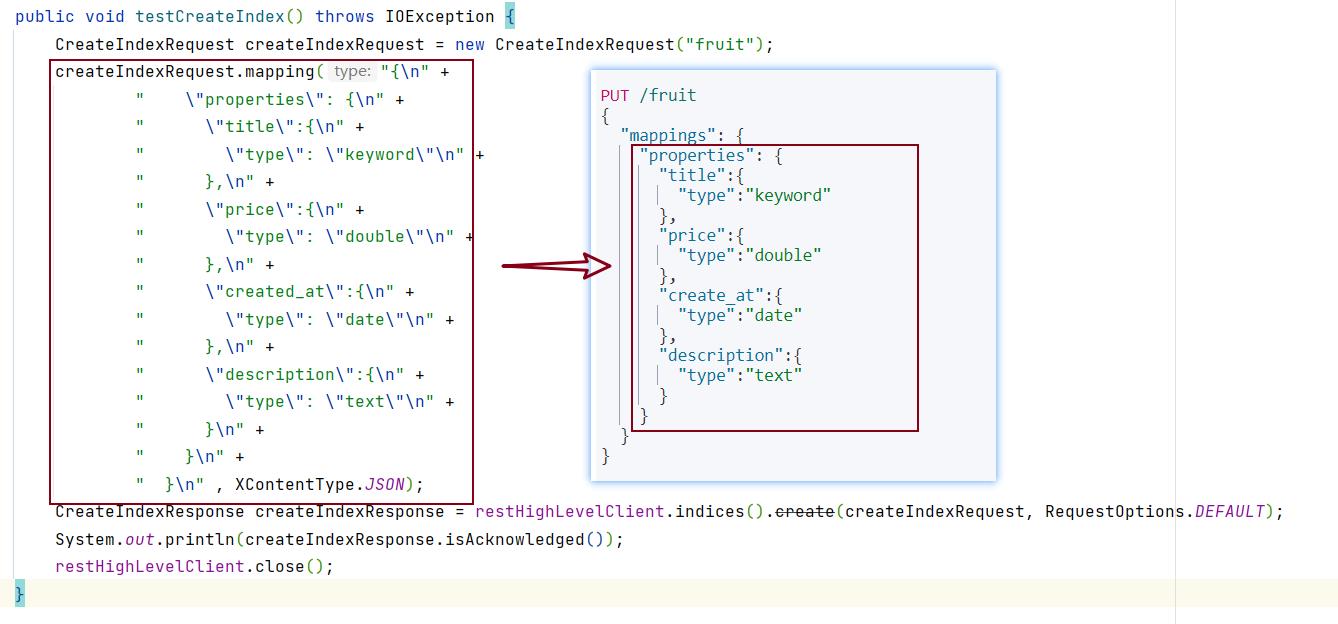
public void testCreateIndex() throws IOException
CreateIndexRequest createIndexRequest = new CreateIndexRequest("fruit");
createIndexRequest.mapping("\\n" +
" \\"properties\\": \\n" +
" \\"title\\":\\n" +
" \\"type\\": \\"keyword\\"\\n" +
" ,\\n" +
" \\"price\\":\\n" +
" \\"type\\": \\"double\\"\\n" +
" ,\\n" +
" \\"created_at\\":\\n" +
" \\"type\\": \\"date\\"\\n" +
" ,\\n" +
" \\"description\\":\\n" +
" \\"type\\": \\"text\\"\\n" +
" \\n" +
" \\n" +
" \\n" , XContentType.JSON);
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
System.out.println(createIndexResponse.isAcknowledged());
restHighLevelClient.close();
索引文档
@Test
public void testIndex() throws IOException
IndexRequest indexRequest = new IndexRequest("fruit");
indexRequest.source("\\n" +
" \\"id\\" : 1,\\n" +
" \\"title\\" : \\"蓝月亮\\",\\n" +
" \\"price\\" : 123.23,\\n" +
" \\"description\\" : \\"这个洗衣液非常不错哦!\\"\\n" +
" ",XContentType.JSON);
IndexResponse index = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
System.out.println(index.status());
更新文档
@Test
public void testUpdate() throws IOException
UpdateRequest updateRequest = new UpdateRequest("fruit","qJ0R9XwBD3J1IW494-Om");
updateRequest.doc("\\"title\\":\\"好月亮\\"",XContentType.JSON);
UpdateResponse update = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(update.status());
删除文档
@Test
public void testDelete() throws IOException
DeleteRequest deleteRequest = new DeleteRequest("fruit","1");
DeleteResponse delete = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(delete.status());
基于 id 查询文档
@Test
public void testGet() throws IOException
GetRequest getRequest = new GetRequest("fruit","aPbmV38BvtuRfHsTIvNo");
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString());
查询所有
public void commonExampleSearch(String indice, QueryBuilder queryBuilder) throws IOException
SearchRequest searchRequest = new SearchRequest(indice);
SearchSourceBuilder sourceBuilder=new SearchSourceBuilder();
sourceBuilder.query(queryBuilder);
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println("总记录数: "+searchResponse.getHits().getTotalHits().value);
System.out.println("最大得分: "+searchResponse.getHits().getMaxScore());
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits)
System.out.println(hit.getSourceAsString());
@Test
public void testSearch() throws IOException
String indice="fruit";
//查询所有
commonExampleSearch(indice,QueryBuilders.matchAllQuery());
//term查询
commonExampleSearch(indice,QueryBuilders.termQuery("description","不错哦!"));
//prefix查询
commonExampleSearch(indice,QueryBuilders.prefixQuery("description","这个"));
//通配符查询
commonExampleSearch(indice,QueryBuilders.wildcardQuery("title","好*"));
//ids查询--多id查询
commonExampleSearch(indice,QueryBuilders.idsQuery().addIds("1","2"));
//多字段查询
commonExampleSearch(indice,QueryBuilders.multiMatchQuery("不错","title","description"));
综合查询
@Test
public void testSearch1() throws IOException
SearchRequest searchRequest = new SearchRequest("fruit");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder
//分页查询
.from(0)//起始位置 start=(page-1)*size
.size(2)//每页显示条数,默认返回10条
//指定排序字段,参数一:根据哪个字段进行排序,参数二:排序方式
.sort("price", SortOrder.DESC)
//返回的结果中排除或者包含哪些字段
//参数1:包含的字段数组
//参数2:排除字段数组
.fetchSource(new String[]"title",new String[])
//高亮设置
.highlighter(new HighlightBuilder()
//高亮显示的字段
.field("description")
//多字段高亮开启
.requireFieldMatch(false)
//自定义高亮html标签
.preTags("<span style='color:red;'>").postTags("</span>"))
//查询
.query(QueryBuilders.termQuery("description","错"));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println("总条数: "+searchResponse.getHits().getTotalHits().value);
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits)
System.out.println(hit.getSourceAsString());
//显示当前查询结果中出现的高亮字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
highlightFields.forEach((k,v)-> System.out.println("key: "+k + " value: "+v.fragments()[0]));
过滤查询
/**
* query: 精确查询,查询计算文档得分,并根据文档得分进行返回
* filter query: 过滤查询,用来在大量数据中筛选出本地查询相关数据,不会计算文档得分,经常使用filter query结果进行缓存
* 注意: 一旦使用query和filterQuery es优先执行filter query 然后再执行 query
*/
@Test
public void testFilterQuery() throws IOException
SearchRequest searchRequest=new SearchRequest("fruit");
SearchSourceBuilder sourceBuilder=new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.termQuery("description","不错"))
//指定过滤条件
.postFilter(QueryBuilders.idsQuery().addIds("1","2","3"));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println("符合条件的总数为: "+searchResponse.getHits().getTotalHits().value);
思路扩展
ElasticsearchOperations面向对象的查询方式,有其优点所在,那么我们能否将其和RestHighLevelClient 进行互补呢 ?
看下面的例子:
@AllArgsConstructor
@NoArgsConstructor
@Builder
@Data
public class Fruit implements Serializable
private String title;
private Double price;
private Date create_at;
private String description;
/**
* @author 大忽悠
* @create 2022/3/5 11:34
*/
public class AllTest extends EsApplicationTests
ObjectMapper objectMapper=new ObjectMapper();
/**
* 添加文档
*/
@Test
public void addIndice() throws IOException
Fruit fruit = Fruit.builder().id(5).title("大忽悠").price(520.521)
.description("大忽悠喜欢小朋友")
.build();
IndexRequest indexRequest=new以上是关于基于SpringBoot的ES整合的主要内容,如果未能解决你的问题,请参考以下文章