神经网络--基于fashion mnist数据库获得最高的识别准确率
Posted 是Dream呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络--基于fashion mnist数据库获得最高的识别准确率相关的知识,希望对你有一定的参考价值。

前言:Hello大家好,我是Dream。 今天来学习一下如何基于fashion mnist数据库获得最高的识别准确率,本文是从零开始的,如有需要可自行跳至所需内容~
本文目录:
说明:在此试验下,我们使用的是使用tf2.x版本,在jupyter环境下完成
在本文中,我们将主要完成以下任务:
- 基于fashion mnist数据库设计网络模型
- 使用evaluate方法对测试集进行测试,获取尽可能高的准确率
1.调用库函数
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import Model
2.调用数据集
(train_X, train_y),(test_X, test_y) = tf.keras.datasets.fashion_mnist.load_data()
train_X, test_X = train_X / 255.0, test_X / 255.0
train_X = train_X.reshape(-1, 28, 28, 1)
train_y = tf.keras.utils.to_categorical(train_y)
test_X = test_X.reshape(-1, 28, 28, 1)
test_y = tf.keras.utils.to_categorical(test_y)
X_train, X_test, y_train, y_test = train_test_split(train_X, train_y, test_size=0.1, random_state=0)
3.数据增强
在这里我们使用数据增强方法,更好的提高准确率
# 数据增强
datagen = ImageDataGenerator(
rotation_range=15,
zoom_range = 0.01,
width_shift_range=0.1,
height_shift_range=0.1)
train_gen = datagen.flow(X_train, y_train, batch_size=128)
test_gen = datagen.flow(X_test, y_test, batch_size=128)
4.选择模型,构建网络
首先我们批量输入的样本个数:
# 批量输入的样本个数
batch_size = 128
train_steps = X_train.shape[0] // batch_size
valid_steps = X_test.shape[0] // batch_size
在此处,我们使用ResNet残差网络,ResNet-34残差网络中首先是卷积层,然后是池化层,有连接线的结构就是一个残差结构再这个34层的ResNet是由一系列的残差结构组成的。最后通过一个平均池化层以及一个全脸基层也就是输出层组成的。这个网络的结构十分简单,基本就是堆叠残差结构组成的。
ResNet结构中具有以下的优点,可以极大程度的提高我们的模型准确率。
- 超深的网络结构(突破了1000层)
- 提出residual模块
- 使用BN加速训练
# 使用ResNet残差网络
class ResnetBlock(Model):
def __init__(self, filters, strides=1, residual_path=False):
super(ResnetBlock, self).__init__()
self.filters = filters
self.strides = strides
self.residual_path = residual_path
# 第1个部分
self.c1 = Conv2D(filters, (3, 3), strides=strides, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
# 第2个部分
self.c2 = Conv2D(filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b2 = BatchNormalization()
# residual_path为True时,对输入进行下采样,即用1x1的卷积核做卷积操作,保证x能和F(x)维度相同,顺利相加
if residual_path:
self.down_c1 = Conv2D(filters, (1, 1), strides=strides, padding='same', use_bias=False)
self.down_b1 = BatchNormalization()
self.a2 = Activation('relu')
def call(self, inputs):
residual = inputs # residual等于输入值本身,即residual=x
# 将输入通过卷积、BN层、激活层,计算F(x)
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.c2(x)
y = self.b2(x)
if self.residual_path:
residual = self.down_c1(inputs)
residual = self.down_b1(residual)
out = self.a2(y + residual) # 最后输出的是两部分的和,即F(x)+x或F(x)+Wx,再过激活函数
return out
class ResNet18(Model):
def __init__(self, block_list, initial_filters=64): # block_list表示每个block有几个卷积层
super(ResNet18, self).__init__()
self.num_blocks = len(block_list) # 共有几个block
self.block_list = block_list
self.out_filters = initial_filters
# 结构定义
self.c1 = Conv2D(self.out_filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.blocks = tf.keras.models.Sequential()
# 构建ResNet网络结构
for block_id in range(len(block_list)): # 第几个resnet block
for layer_id in range(block_list[block_id]): # 第几个卷积层
if block_id != 0 and layer_id == 0: # 对除第一个block以外的每个block的输入进行下采样
block = ResnetBlock(self.out_filters, strides=2, residual_path=True)
else:
block = ResnetBlock(self.out_filters, residual_path=False)
self.blocks.add(block) # 将构建好的block加入resnet
self.out_filters *= 2 # 下一个block的卷积核数是上一个block的2倍
self.p1 = tf.keras.layers.GlobalAveragePooling2D()
self.f1 = tf.keras.layers.Dense(10, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
def call(self, inputs):
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
# 4个元素,block执行4次,每次有2个
model = ResNet18([2, 2, 2, 2])
5.训练
经过我们测试分析,此模型训练到70轮之前变化趋于静止,我们可以只进行70个epochs
optimizer = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
# 经过我们测试分析,此模型训练到70轮之前变化趋于静止,我们可以只进行70个epochs
es = tf.keras.callbacks.EarlyStopping(
monitor="val_accuracy",
patience=15,
verbose=1,
mode="max",
restore_best_weights=True
)
rp = tf.keras.callbacks.ReduceLROnPlateau(
monitor="val_accuracy",
factor=0.2,
patience=10,
verbose=1,
mode="max",
min_lr=0.0001
)
model.compile(optimizer=optimizer, loss=tf.keras.losses.categorical_crossentropy, metrics=['accuracy'])
# 训练(训练70个epoch)
history = model.fit(train_gen,
batch_size=128,
epochs=70,
verbose=1,
validation_data=test_gen,
validation_steps=valid_steps,
steps_per_epoch=train_steps,
callbacks=[es, rp]
)
🌟🌟🌟 这里是输出的结果:✨✨✨

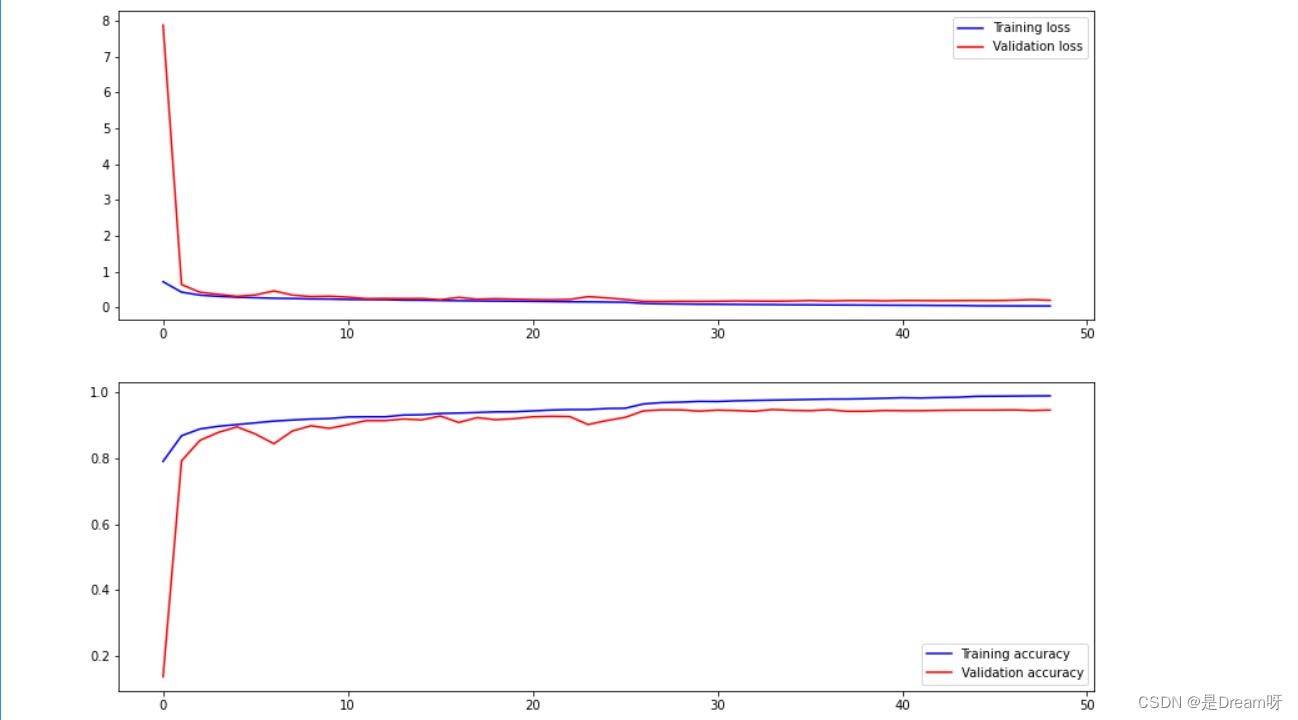
6.画出图像
使用plt模块进行数据可视化处理
# 显示训练集和验证集的acc和loss曲线
fig, ax = plt.subplots(2,1, figsize=(14, 10))
ax[0].plot(history.history['loss'], color='b', label="Training loss")
ax[0].plot(history.history['val_loss'], color='r', label="Validation loss",axes =ax[0])
ax[0].legend(loc='best', shadow=False)
ax[1].plot(history.history['accuracy'], color='b', label="Training accuracy")
ax[1].plot(history.history['val_accuracy'], color='r',label="Validation accuracy")
ax[1].legend(loc='best')
🌟🌟🌟 这里是输出的结果:✨✨✨
7.输出
最后在测试集上进行模型评估,输出测试集上的预测准确率
score = model.evaluate(X_test, y_test) # 在测试集上进行模型评估
print('测试集预测准确率:', score[1]) # 打印测试集上的预测准确率
🌟🌟🌟 这里是输出的结果:✨✨✨
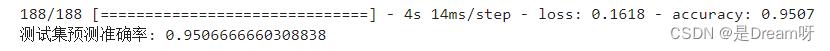
8.结果
print("The accuracy of the model is %f" %score[1])
🌟🌟🌟 这里是输出的结果:✨✨✨
The accuracy of the model is 0.950667
源码获取
关注此公众号:人生苦短我用Pythons,回复 神经网络实验获取源码,快点击我吧
🌲🌲🌲 好啦,这就是今天要分享给大家的全部内容了,我们下期再见!
❤️❤️❤️如果你喜欢的话,就不要吝惜你的一键三连了~


最后,有任何问题,欢迎关注下面的公众号,获取第一时间消息、作者联系方式及每周抽奖等多重好礼! ↓↓↓
深度学习基于tensorflow的服装图像分类训练(数据集:Fashion-MNIST)
活动地址:CSDN21天学习挑战赛
目录
前言
关于环境这里不再赘述,与【深度学习】从LeNet-5识别手写数字入门深度学习一文的环境一致。
了解Fashion-MNIST数据集
Fashion-MNIST数据集与MNIST手写数字数据集不一样。但他们都有共同点就是都是灰度图片。
Fashion-MNIST数据集是各类的服装图片总共10类。下面列出了中英文对应表,方便接下来的学习。
| 中文 | 英文 |
|---|---|
| t-shirt | T恤 |
| trouser | 牛仔裤 |
| pullover | 套衫 |
| dress | 裙子 |
| coat | 外套 |
| sandal | 凉鞋 |
| shirt | 衬衫 |
| sneaker | 运动鞋 |
| bag | 包 |
| ankle boot | 短靴 |
下载数据集
使用tensorflow下载(推荐)
默认下载在C:\\Users\\用户\\.keras\\datasets路径下。
from tensorflow.keras import datasets
# 下载数据集
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
数据集分类
这里对从网上下载的数据集进行一个说明。
| 文件名 | 数据说明 |
|---|---|
| train-images-idx3-ubyte | 训练数据图片集 |
| train-labels-idx1-ubyte | 训练数据标签集 |
| t10k-images-idx3-ubyte | 测试数据图片集 |
| t10k-labels-idx1-ubyte | 测试数据标签集 |
数据集格式
训练数据集共60k张图片,各个服装类型的数据量一致也就是说每种6k。
测试数据集共10k张图片,各个服装类型的数据量一致也就是说每种100。
数据集均采用28281的灰度照片。
采用CPU训练还是GPU训练
一般来说有好的显卡(GPU)就使用GPU训练因为快,那么对应的你就要下载tensorflow-gpu包。如果你的显卡较差或者没有足够资金入手一款好的显卡就可以使用CUP训练。
区别
(1)CPU主要用于串行运算;而GPU则是大规模并行运算。由于深度学习中样本量巨大,参数量也很大,所以GPU的作用就是加速网络运算。
(2)CPU计算神经网络也是可以的,算出来的神经网络放到实际应用中效果也很好,只不过速度会很慢罢了。而目前GPU运算主要集中在矩阵乘法和卷积上,其他的逻辑运算速度并没有CPU快。
使用CPU训练
# 使用cpu训练
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
使用CPU训练时不会显示CPU型号。

使用GPU训练
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0], "GPU")
使用GPU训练时会显示对应的GPU型号。

预处理
最值归一化(normalization)
关于归一化相关的介绍在前文中有相关介绍。 最值归一化与均值方差归一化
# 将像素的值标准化至0到1的区间内。
train_images, test_images = train_images / 255.0, test_images / 255.0
return train_images, test_images
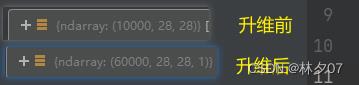
升级图片维度
因为数据集是灰度照片,所以我们需要将[28,28]的数据格式转换为[28,28,1]
# 调整数据到我们需要的格式
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
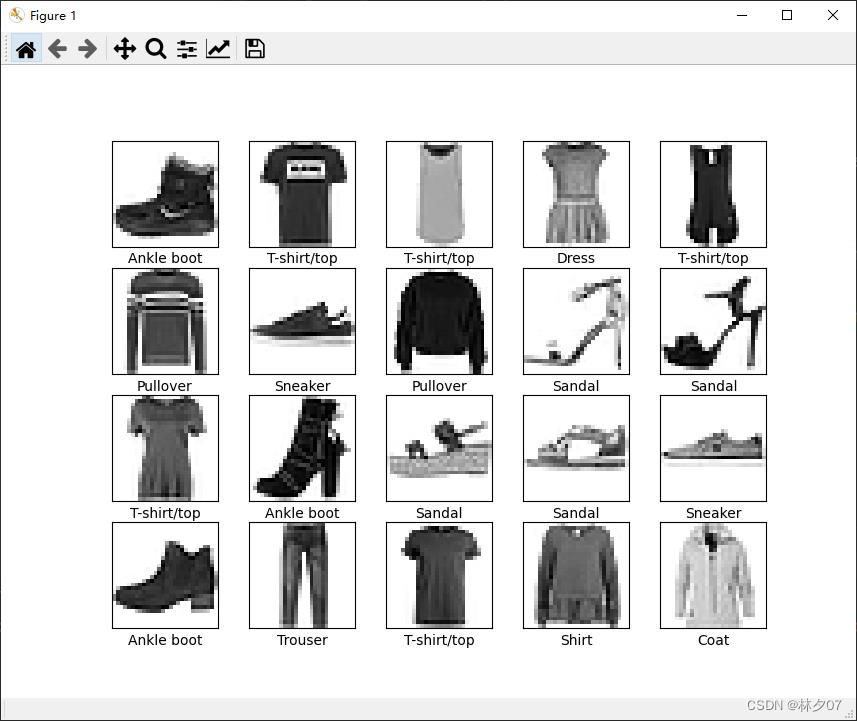
显示部分图片
首先需要建立一个标签数组,然后绘制前20张,每行5个共四行
注意:如果你执行下面这段代码报这个错误:TypeError: Invalid shape (28, 28, 1) for image data。那么你就使用我下面注释掉的那句话。
from matplotlib import pyplot as plt
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
plt.figure(figsize=(20, 10))
for i in range(20):
plt.subplot(4, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
#plt.imshow(train_images[i].squeeze(), cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()
绘制结果:
建立CNN模型
from tensorflow_core.python.keras import Input, Sequential
from tensorflow_core.python.keras.layers import Conv2D, Activation, MaxPooling2D, Flatten, Dense
def simple_CNN(input_shape=(32, 32, 3), num_classes=10):
# 构建一个空的网络模型,它是一个线性堆叠模型,各神经网络层会被顺序添加,专业名称为序贯模型或线性堆叠模型
model = Sequential()
# 卷积层1
model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
# 最大池化层1
model.add(MaxPooling2D((2, 2), strides=(2, 2), padding='same'))
# 卷积层2
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
# 最大池化层2
model.add(MaxPooling2D((2, 2), strides=(2, 2), padding='same'))
# 卷积层3
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
# flatten层常用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。
model.add(Flatten())
# 全连接层 对特征进行提取
model.add(Dense(units=64, activation='relu'))
# 输出层
model.add(Dense(10))
return model
网络结构
包含输入层的话总共9层。其中有三个卷积层,俩个最大池化层,一个flatten层,俩个全连接层。
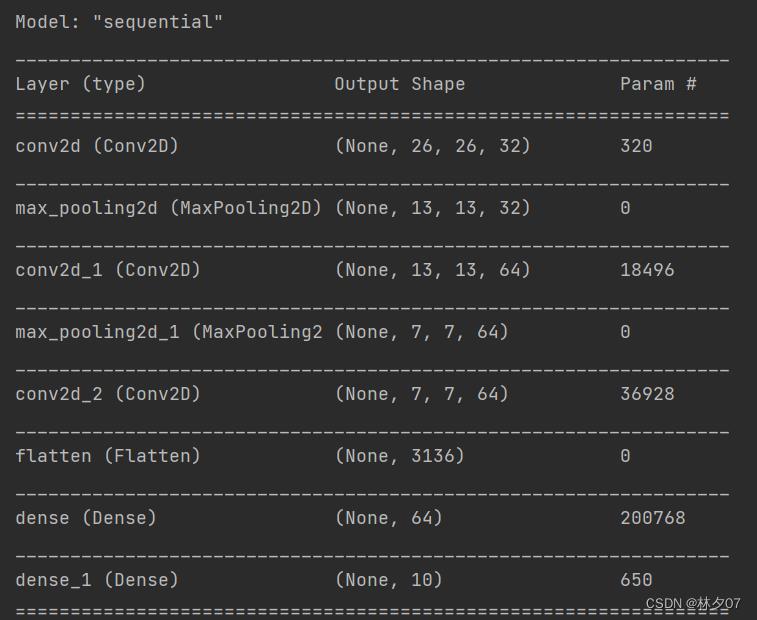
参数量
总共参数为319k,训练时间比LeNet-5较长。建议采用GPU训练。
Total params: 257,162
Trainable params: 257,162
Non-trainable params: 0
训练模型
训练模型,进行10轮,将模型保存到1.h5文件中。后期可以直接加载模型继续训练。
from tensorflow_core.python.keras.models import load_model
from Cnn import simple_CNN
import tensorflow as tf
model = simple_CNN(train_images, train_labels)
model.summary() # 打印网络结构
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.save("1.h5")
history = model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))
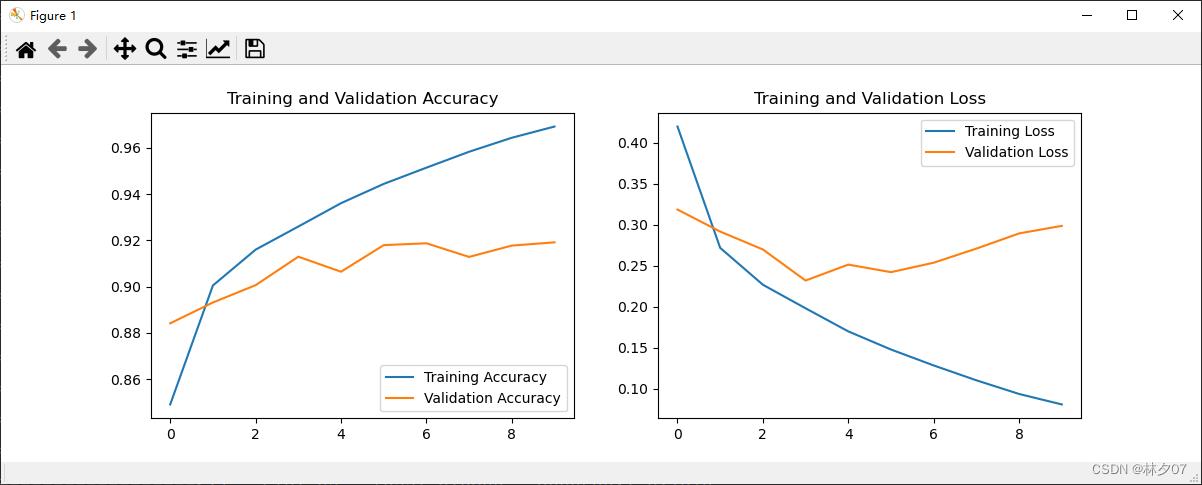
训练结果:测试集acc为91.64%。从效果来说该模型还是不错的。

模型评估
对训练完模型的数据制作成曲线表,方便之后对模型的优化,看是过拟合还是欠拟合还是需要扩充数据等等。
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(10)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
运行结果:
以上是关于神经网络--基于fashion mnist数据库获得最高的识别准确率的主要内容,如果未能解决你的问题,请参考以下文章