Linux 网络编程4网络层--UDP/TCP协议,3次握手4次挥手粘包问题等
Posted 一个普通的小白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux 网络编程4网络层--UDP/TCP协议,3次握手4次挥手粘包问题等相关的知识,希望对你有一定的参考价值。
netstat命令
-n.拒绝显示别名,能显示数字的全部转化成数字(IP+PORT)
-l 仅列出有在 Listen (监听) 的服务的状态
-p 显示建立相关链接的程序名(pid)
-t 仅显示tcp相关选项
-u 仅显示udp相关选项

2.UDP协议
2.1.全双工和半双工的区别
全双工:可以双方同时传输数据,UDP协议和TCP都是全双工
半双工:一次只能一方传输数据;
2.2.UDP的特点
1.无连接:知道对端的IP和端口号就直接进行传输, 不需要建立连接 ;
2.不可靠:没有应答机制和重传机制;
3.面向数据报:不能够灵活的控制读写数据的次数和数量 ;
1.必须接受一个完整的报文,不能分两次接受半个报文在拼接;
2.UDP一次只能发送2^16个字节大小的数据,如果超过只能在应用层拆分,再在对端的应用 层合并;
2.3.UDP协议格式
16位源端口号:发送端端口号
16位目的端口号:接受端端口号
16位UDP长度:UDP首部(UDP报头)+UDP数据(UDP有效载荷);整个数据报的总长度
16位UDP检验和:如果校验和出错, 就会直接丢弃;

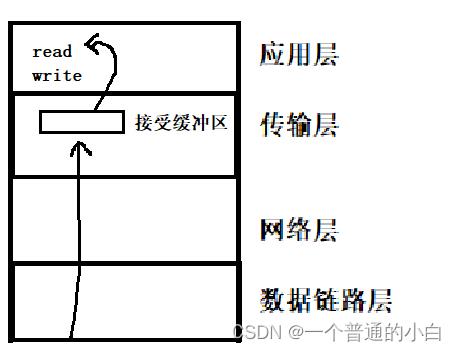
2.4.UDP的缓冲区
过程:调用系统接口read把缓冲区的数据拷贝到应用层,write直接向内核交付数据
UDP协议只有接受缓冲区:因为没有重传机制和应答机制;
3.TCP协议
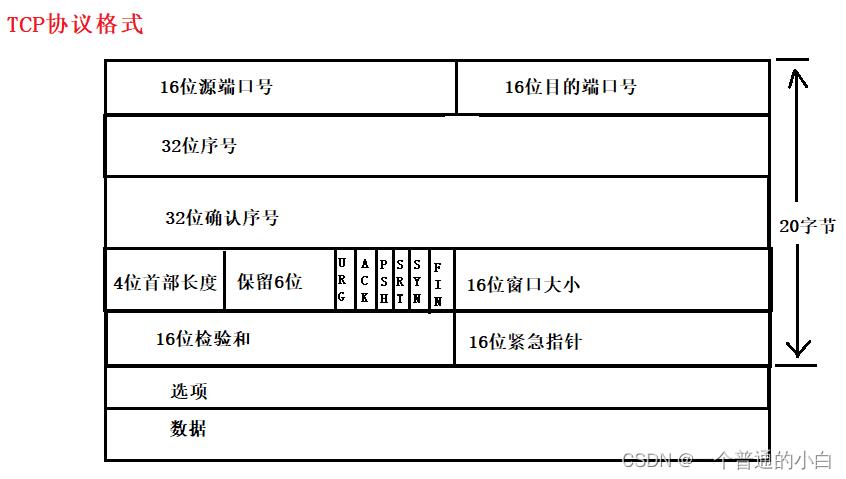
3.1.tcp协议格式
16位源端口号:发送端端口号
16位目的端口号:接受端端口号
3.2.首部长度和序号
TCP的报头标长是20字节;
4位首部长度:4个比特位可以表示0-15;报头长度=首部长度*4;所以最大的报头为4*最大首 部长度(15)=60;报头长度在20-60可以被4整除的数;
序号:每个报文都会被设置一个序号;一个报文在发送缓冲区最大那一个下标,下面这个报文的序号是1000;

确定序号:表示确定序号之前的序号对应的报文被对端接受了;例:确定序号101,表示101序号以前的序号对应的报文都被接受了,下次使用101序号传输;
3.3.确认应答机制
收到确定报文表示确认序号以前的序号已经被接收;并且确定报文中16位窗口大小被设置表示接收端的接受缓冲区还有多少空间,
如果没收到确定报文,发送端默认对端没有收到将重传;

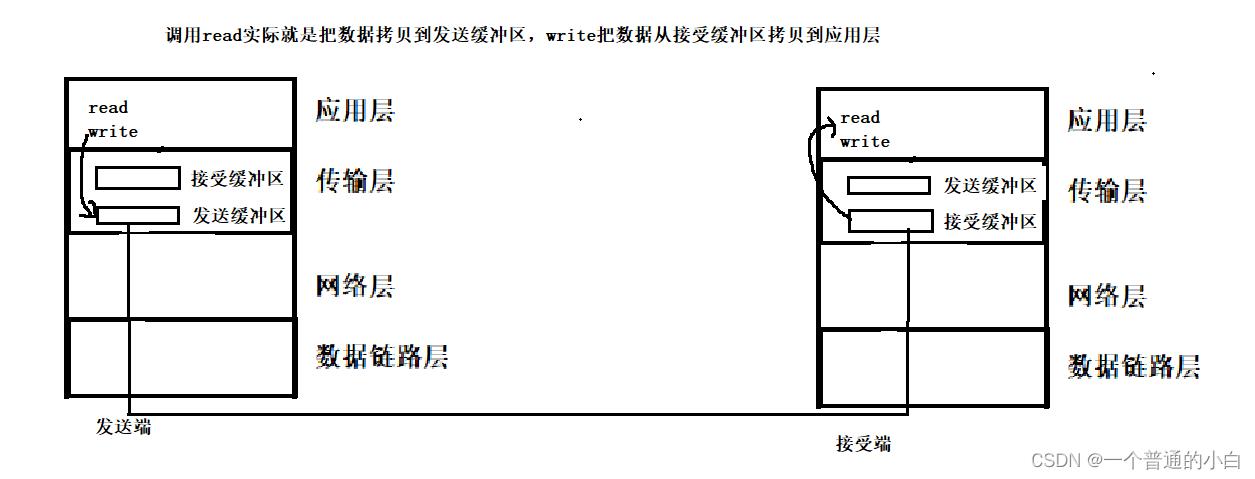
3.4.TCP协议的缓冲区
TCP协议有两个缓冲区:发送缓冲区和接受缓冲区
过程:调用read实际就是把数据拷贝到发送缓冲区,write把数据从接受缓冲区拷贝到应用层
特点:
1. 效率提高 ,因为应用层把数据拷贝到发送缓冲区就结束了就返回;
2. 应用层和传输层的解耦 ,因为应用层把数据拷贝到发送缓冲区,数据就不用应用层管理
3.5.六位标志位
标志位的概念:用于区分不同的报文,确定报文、连接报文等等;
一个标志是3个英文字母总共3字节,有6位的标志位有6字节,所以一次最多设置2个标志,也可以一个都不设置;

6个标志:
前4个标志在3次握手4次挥手讲
ACK: 设置与否表示确认序号是否有效
SYN: 请求建立连接; 我们把携带SYN标识的称为 同步报文段 FIN: 通知对方, 本端要关闭了, 我们称携带FIN标识的为 结束报文段 RST: 对方要求重新建立连接; 我们把携带RST标识的称为 复位报文段
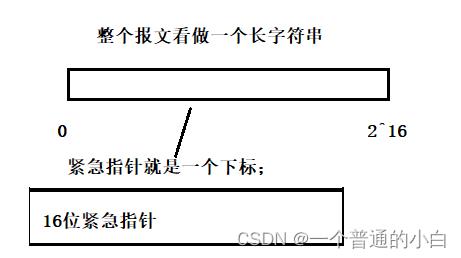
URG: 紧急指针是否有效 PSH: 接收端的接收缓冲区快满了发送端没法传输数据了,提示接收端应用程序立刻从TCP缓冲区把数据读走;
URG(不是很重要):优先先读URG报文不用按序到达,只会读被紧急指针下标的那个字节
3.6.超时重传机制
TCP协议会统计正常通信的时间;来设置一个超时重传的时间
3.7.TCP3次握手,为什么是3次
3次握手过程
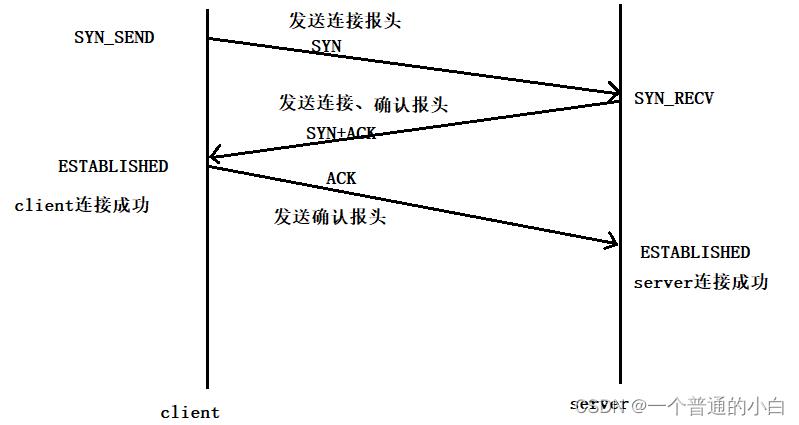
3.7.1.第一个原因:3次握手是最小次数,可证明全双工的双端的网络通信信道是正常
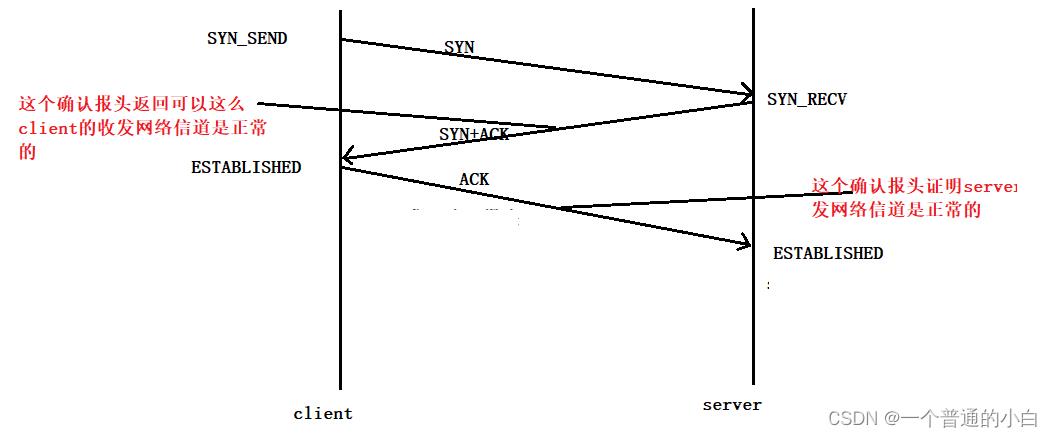
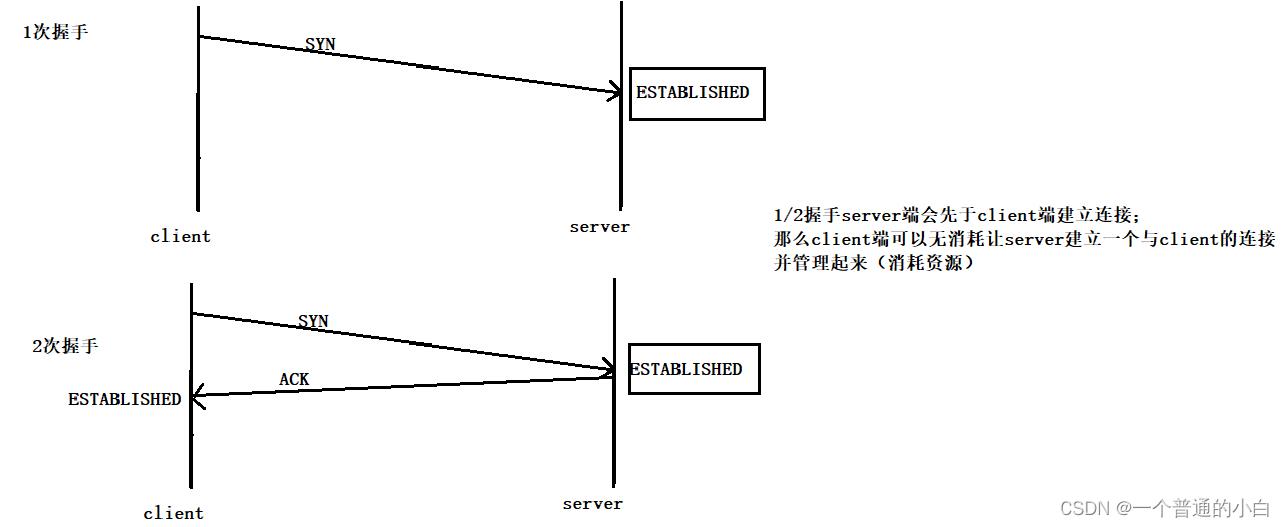
3.7.1第二个原因:防止SYN洪水;
1/2握手server端会先于client端建立连接;
那么client端可以无消耗让server建立一个与client的连接并管理起来(消耗server资源);
3.8.TCP的4次挥手及TIME_WAIT的解释

3.8.1.TIME_WAIT为什么要有这个状态
不能直接CLOSED因为还有给对端发送ACK;
3.8.2.TIME_WAIT需要等多久呢?为什么?
等待时间:需要等2倍MSL时间;
MSL(maximum segment lifetime)时间:MSL在RFC1122中规定为两分钟,但是各操作系统的实现不同, 在Centos7上默认配置的值是60s,并且TCP协议也有自己的一套方法,统计多个正常一次通信的时间,取最大的一个做MSL;
为什么是2MSL
一个来回是2MSL,ACK没被接受就会重发FIN,刚好一个来回的时间2MSL;
2MSL保证历史发的数据在网络中消散:如果server不等待2MSL直接断开,对面没有收到ACK,将会重发FIN,server立马重连收到重发的FIN又会断开不符合我的要求;

3.8.3.CLOSE_WAIT
如果服务器端,在客户端请求关闭连接,服务器端accept的文件描述符不关闭,会在保持CLOSE_WAIT状态(文件描述符泄漏)
服务器端:只能accept的文件描述符但是不处理
int main()
int listen_sock=socket(AF_INET,SOCK_STREAM,0);
//bind服务器
struct sockaddr_in local;
local.sin_family=AF_INET;
local.sin_port=htons(PORT);
local.sin_addr.s_addr=INADDR_ANY;
bind(listen_sock,(struct sockaddr*)&local,sizeof(local))
listen(listen_sock,5);
struct sockaddr_in tmp;
socklen_t tlen=sizeof(tmp);
//建立连接
int fd=accept(listen_sock,(struct sockaddr*)&tmp,&tlen);

3.9.滑动窗口
滑动窗口的作用:发送报文不用立即ACK可以继续发送一些报文
滑动窗口的大小:
跟接收端的窗口大小(接收缓冲区)有关;
在3次握手就设置好了滑动窗口的大小;
滑动窗口大小不是一直不变的;window_start+=ACK(不一定是一个报文可能是多个),window_end+=接收端的16位窗口大小;
三部分依次:1.以确认的报文;2.已发送/可以发送但是没有收到ACK的报文;3.还不能发送的报文
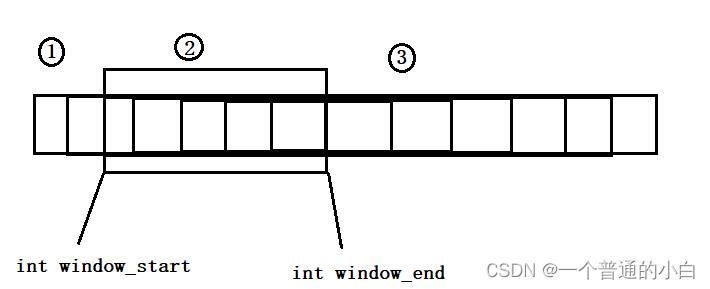
3.9.1.流量控制
因此TCP支持根据接收端的处理能力(窗口大小), 来决定发送端的发送速度. 这个机制就叫做流量控制(Flow Control);
在3次握手就设置好了滑动窗口的大小就是依靠流量控制;
如果接收端的窗口满了就会返回的窗口大小为0;发送端定期发送一个窗口探测报文(标志位设为PSH并且不携带数据);
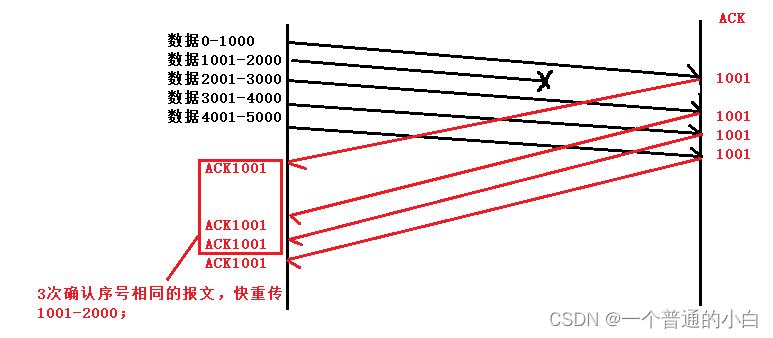
3.9.2.快重传
连续收到3个及以上的确认序号的ACK,那么会重发下一个,这种机制被称为 "高速重发控制"(也叫 "快重传");
3.10.拥塞控制
再开始通信时,并不知道网络情况怎么样,是否拥塞;所有不能通信一开始就发送大量的数据,免得已经拥塞的网络,更加拥塞;
过程(慢启动:前面慢后面快):拥塞窗口初始化时为1;先按指数增长,碰见网络拥塞时,把拥塞窗口的一半做为阈值;
再把阻塞窗口置为1,先按指数增长达到阈值,再按线性增长,再次碰见网络阻塞;(循环这一步)
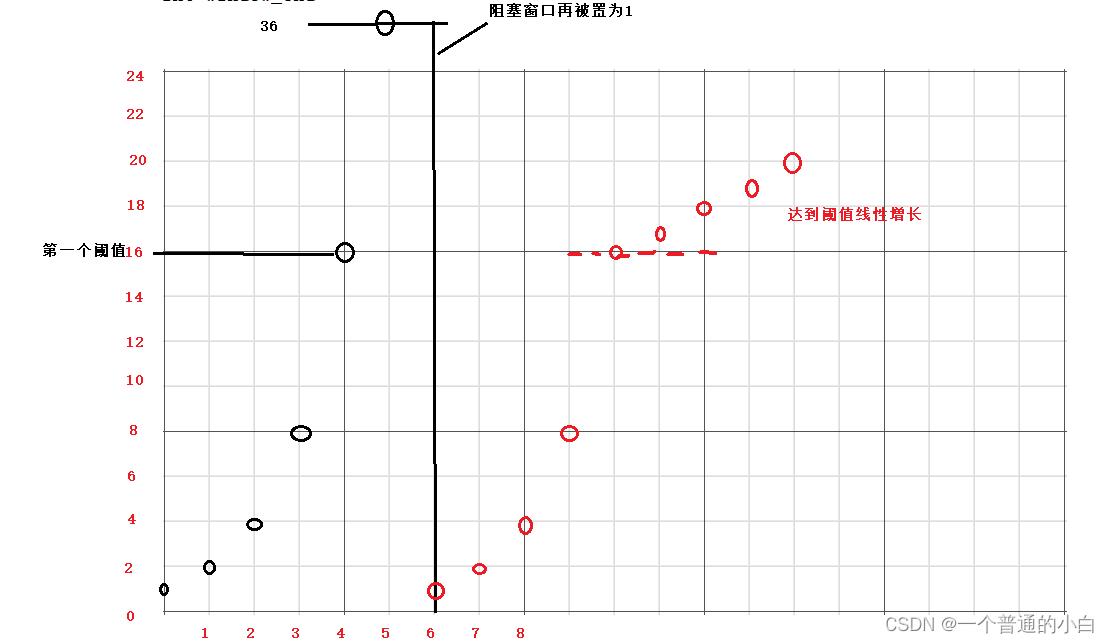
滑动窗口大小=min(阻塞窗口,接受端的窗口大小);
3.11.延迟应答和捎带应答
3.11.1延迟应答
原因:如果接收数据的主机立刻返回ACK应答, 这时候返回的窗口可能比较小(接受端的应用层也在read数据);
窗口越大, 网络吞吐量就越大, 传输效率就越高. 保证网络不拥塞的情况下尽量提高传输 效率;
也是有限制的,一般数量(多少个报文就返回一个ACK)限制:2,时间限制:最大延迟时间:200ms;不同的操作系统可能不同;
3.11.2.捎带应答
携带数据的报文并设置ACK标志位,大多数的报文都是这样的;
3.12.粘包问题
tcp的接受缓冲区是一串连续的字节数据,没有区分的边界,如何把一个个数据包分离出来:

从应用层来解决:
特殊字符
自描述字段
固定长度
http就是使用特殊字符+自描述字段来处理粘包问题的;
空行分离报文和有效载荷
如果存在Content-length自描述字段,那么就有有效载荷并且Content-longth的数值表示有效载荷的字节数;

3.12.1.UDP有粘包问题吗?
A:没有;
表示报头中包含一个16位UDP长度表示UDP报文有多少字节数,并且UDP报头是固长8字节的,UDP长度- 8=一个数据包;UDP的接受缓冲区一次只会交付给应用层一个数据包;

Linux之socket套接字编程20160704
介绍套接字之前,我们先看一下传输层的协议TCP与UDP:
TCP协议与UDP协议的区别
首先咱们弄清楚,TCP协议和UCP协议与TCP/IP协议的联系,很多人犯糊涂了,一直都是说TCP/IP协议与UDP协议的
区别,我觉得这是没有从本质上弄清楚网络通信!
TCP/IP协议是一个协议簇。里面包括很多协议的。UDP只是其中的一个。之所以命名为TCP/IP协议,因为TCP,IP协议是
两个很重要的协议,就用他两命名了。
TCP/IP协议集包括应用层,传输层,网络层,网络访问层。
其中应用层包括:
超文本传输协议(HTTP):万维网的基本协议.
文件传输(TFTP简单文件传输协议):
远程登录(Telnet),提供远程访问其它主机功能,它允许用户登录
internet主机,并在这台主机上执行命令.
网络管理(SNMP简单网络管理协议),该协议提供了监控网络设备的方法,以及配置管理,统计信息收集,性能管理及安全管
理等.
域名系统(DNS),该系统用于在internet中将域名及其公共广播的网络节点转换成IP地址.
其次网络层包括:
Internet协议(IP)
Internet控制信息协议(ICMP)
地址解析协议(ARP)
反向地址解析协议(RARP)
最后说网络访问层:网络访问层又称作主机到网络层(host-to-network).网络访问层的功能包括IP地址与物理地址硬件
的映射,以及将IP封装成帧.基于不同硬件类型的网络接口,网络访问层定义了和物理介质的连接.
当然我这里说得不够完善,TCP/IP协议本来就是一门学问,每一个分支都是一个很复杂的流程,但我相信每位学习软件
开发的同学都有必要去仔细了解一番。
下面我着重讲解一下TCP协议和UDP协议的区别。
TCP(Transmission Control Protocol,传输控制协议)是面向连接的协议,也就是说,在收发数据前,必须和对方建
立可靠的连接。一个TCP连接必须要经过三次“对话”才能建立起来,其中的过程非常复杂,只简单的描述下这三次对
话的简单过程:主机A向主机B发出连接请求数据包:“我想给你发数据,可以吗?”,这是第一次对话;主机B向主机A
发送同意连接和要求同步(同步就是两台主机一个在发送,一个在接收,协调工作)的数据包:“可以,你什么时候发
?”,这是第二次对话;主机A再发出一个数据包确认主机B的要求同步:“我现在就发,你接着吧!”,这是第三次对
话。三次“对话”的目的是使数据包的发送和接收同步,经过三次“对话”之后,主机A才向主机B正式发送数据。
详细点说就是:(文章部分转载http://zhangjiangxing-gmail-com.iteye.com,主要是这个人讲解得很到位,的确很
容易使人理解!)
TCP三次握手过程
1 主机A通过向主机B 发送一个含有同步序列号的标志位的数据段给主机B ,向主机B 请求建立连接,通过这个数据段,
主机A告诉主机B 两件事:我想要和你通信;你可以用哪个序列号作为起始数据段来回应我.
2 主机B 收到主机A的请求后,用一个带有确认应答(ACK)和同步序列号(SYN)标志位的数据段响应主机A,也告诉主机A两
件事:
我已经收到你的请求了,你可以传输数据了;你要用哪佧序列号作为起始数据段来回应我
3 主机A收到这个数据段后,再发送一个确认应答,确认已收到主机B 的数据段:"我已收到回复,我现在要开始传输实际数
据了
这样3次握手就完成了,主机A和主机B 就可以传输数据了.
3次握手的特点
没有应用层的数据
SYN这个标志位只有在TCP建产连接时才会被置1
握手完成后SYN标志位被置0
TCP建立连接要进行3次握手,而断开连接要进行4次
1 当主机A完成数据传输后,将控制位FIN置1,提出停止TCP连接的请求
2 主机B收到FIN后对其作出响应,确认这一方向上的TCP连接将关闭,将ACK置1
3 由B 端再提出反方向的关闭请求,将FIN置1
4 主机A对主机B的请求进行确认,将ACK置1,双方向的关闭结束.
由TCP的三次握手和四次断开可以看出,TCP使用面向连接的通信方式,大大提高了数据通信的可靠性,使发送数据端
和接收端在数据正式传输前就有了交互,为数据正式传输打下了可靠的基础
名词解释
ACK TCP报头的控制位之一,对数据进行确认.确认由目的端发出,用它来告诉发送端这个序列号之前的数据段
都收到了.比如,确认号为X,则表示前X-1个数据段都收到了,只有当ACK=1时,确认号才有效,当ACK=0时,确认号无效,这时
会要求重传数据,保证数据的完整性.
SYN 同步序列号,TCP建立连接时将这个位置1
FIN 发送端完成发送任务位,当TCP完成数据传输需要断开时,提出断开连接的一方将这位置1
TCP的包头结构:
源端口 16位
目标端口 16位
序列号 32位
回应序号 32位
TCP头长度 4位
reserved 6位
控制代码 6位
窗口大小 16位
偏移量 16位
校验和 16位
选项 32位(可选)
这样我们得出了TCP包头的最小长度,为20字节。
UDP(User Data Protocol,用户数据报协议)
(1) UDP是一个非连接的协议,传输数据之前源端和终端不建立连接,当它想传送时就简单地去抓取来自应用程序的
数据,并尽可能快地把它扔到网络上。在发送端,UDP传送数据的速度仅仅是受应用程序生成数据的速度、计算机的能
力和传输带宽的限制;在接收端,UDP把每个消息段放在队列中,应用程序每次从队列中读一个消息段。
(2) 由于传输数据不建立连接,因此也就不需要维护连接状态,包括收发状态等,因此一台服务机可同时向多个客户
机传输相同的消息。
(3) UDP信息包的标题很短,只有8个字节,相对于TCP的20个字节信息包的额外开销很小。
(4) 吞吐量不受拥挤控制算法的调节,只受应用软件生成数据的速率、传输带宽、源端和终端主机性能的限制。
(5)UDP使用尽最大努力交付,即不保证可靠交付,因此主机不需要维持复杂的链接状态表(这里面有许多参数)。
(6)UDP是面向报文的。发送方的UDP对应用程序交下来的报文,在添加首部后就向下交付给IP层。既不拆分,也不合
并,而是保留这些报文的边界,因此,应用程序需要选择合适的报文大小。
我们经常使用“ping”命令来测试两台主机之间TCP/IP通信是否正常,其实“ping”命令的原理就是向对方主机发送
UDP数据包,然后对方主机确认收到数据包,如果数据包是否到达的消息及时反馈回来,那么网络就是通的。
UDP的包头结构:
源端口 16位
目的端口 16位
长度 16位
校验和 16位
小结TCP与UDP的区别:
1.基于连接与无连接;
2.对系统资源的要求(TCP较多,UDP少);
3.UDP程序结构较简单;
4.流模式与数据报模式 ;
5.TCP保证数据正确性,UDP可能丢包,TCP保证数据顺序,UDP不保证。TCP失败就重传,UDP不会
接下来,我们再看看工作在应用层的套接字编程:
套接字是一种使用标准UNIX文件描述符(file descriptor)与其他程序通信的方式。套接字可以看作是处于不同主机之间的两个程序的通信连接端点。一方面程序将要传输的信息写入套接字中,而另一方面则通过读取套接字内的数据来获得传输的信息。
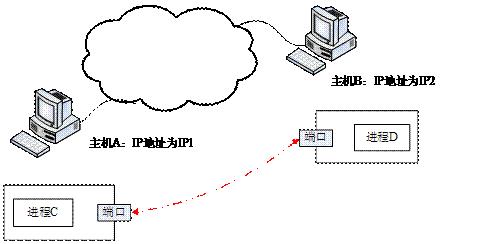
图1 套接字通信示意图
图1所示为使用套接字进行通信的示意图。假设存在两台主机A与B,在主机A中存在进程C,主机B中存在进程D,当进程C需要将数据送到进程D时,首先将数据写到套接字中,而进程D可以通过读取套接字来获得进程C发送的信息。
在网络中,不同计算机是通过IP地址来区分的,也就 是说,要将数据由主机A发送到主机B,只要知道主机B的IP地址就可以确定数据要发送的目的地。但是,在主机A与B中不可能只有进程C和进程D两个进程。 主机B在收到主机A发送来的数据后,如何才能确定该数据是发送给进程D?因此,还需要某种标识信息,用于描述网络通信数据发往的进程。TCP/IP协议提 出了协议端口的概念,用于标识通信的进程。
当进程与某个端口绑定后,操作系统会将收到的给该端 口的数据送往该进程。与文件描述符类似,每个端口都有被称为端口号的整数类型的标识符,该标识符用于区分不同的端口。不同协议可以使用相同的端口号进行数 据传输。例如,TCP使用了344的端口号,UDP同样可以使用344端口号进行数据传输。
端口号为一个16位的无符号整数,其取值范围为0~65535。低于256的端口被作为系统的保留端口号,主要用于系统进程的通信,不在这一范围的端口号被称为自由端口号,可以由进程自由使用。
主要看一下客户端的:
retval = connect(sockfd,(struct sockaddr*)&servaddr,sizeof(servaddr));
//(struct sockaddr*)&servaddr里 是服务器的地址,表示连接到服务器的某一个地址
套接字
ret = getaddrinfo(pSrvName, NULL, &hostInfo, &pAddrInfo);
getaddrinfo函数能够处理名字到地址以及服务到端口这两种转换,返回的是一个sockaddr结构的链表而不是一个地址清单。这些sockaddr结构随后可由套接口函数直接使用
int getaddrinfo( const char *hostname, const char *service, const struct addrinfo *hints, struct addrinfo **result );
参数说明
hostname:一个主机名或者地址串(IPv4的点分十进制串或者IPv6的16进制串)
service:服务名可以是十进制的端口号,也可以是已定义的服务名称,如ftp、http等
hints:可以是一个空指针,也可以是一个指向某个addrinfo结构体的指针,调用者在这个结构中填入关于期望返回的信息类型的暗示。举例来说:指定的服务既可支持TCP也可支持UDP,所以调用者可以把hints结构中的ai_socktype成员设置成SOCK_DGRAM使得返回的仅仅是适用于数据报套接口的信息。
result:本函数通过result指针参数返回一个指向addrinfo结构体链表的指针。
返回值:0——成功,非0——出错
在getaddrinfo函数之前通常需要对以下6个参数进行以下设置:nodename、servname、hints的ai_flags、ai_family、ai_socktype、ai_protocol
通常服务器端在调用getaddrinfo之前,ai_flags设置AI_PASSIVE,用于bind;主机名nodename通常会设置为NULL,返回通配地址[::]。
如果nodename是本机名,servname为NULL,则根据操作系统的不同略有不同,地址列表加以返回
struct sockaddr{
unsigned short sa_family;
char sa_data[14]
};
sa_family:用于指定地址族,如果是TCP/IP通信,该值取PF_INET。sa_data:用于保存套接字的IP地址和端口号信息
struct sockaddr_in {
short int sin_family;
unsigned short int sin_port;
struct in_addr sin_addr;
unsigned char sin_zero[8];
};
l sin_family:用于指定地址族。
l sin_port:套接字通信的端口号。
l sin_addr:通信的IP地址。
l sin_zero[8]:用以填充0,保持与struct sockaddr同样大小。
由于sockaddr数据结构与sockaddr_in数据结构的大小是相同的,指向sockaddr_in的指针可以通过强制转换,转换成指向sockaddr结构的指针。
int socket(int domain, int type, int protocol);
socket函数用于创建通信的套接字,并返回该套接字的文件描述符。参数domain指定了通信域,该参数用于选择通信协议族参数type用于指定套接字的类型。套接字类型除了前面提到的流套接字、数据报套接字及原始套接字外,还有其他的几种类型参数protocol用于指定套接字使用的通信协议。正常情况下,对于给定的协议族,只有单一的协议支持特定的套接字类型。这时,只要将protocol参数设置为0即可
int connect(int sockfd, const struct sockaddr *serv_addr, socklen_t addrlen);
connect函数将使用参数sockfd中的套接字连接到参数serv_addr中指定的服务器。参数addrlen为serv_addr指向的内存空间大小。
如果参数sockfd的类型为SOCK_DGRAM,serv_addr参数为数据报发往的地址,且将只接收该地址的数据报。如果sockfd的类型为SOCK_STREAM或SOCK_SEQPACKET,调用该函数将连接serv_addr中的服务器地址。
ssize_t send(int s, const void *buf, size_t len, int flags);
send函数用于将信息发送到指定的套接字文件描述 符中。该函数只能用于已经建立连接的socket通信中,即只用于面向连接的通信中。参数s为要发送数据的套接字文件描述符。buf参数为指向要发送数据 的指针。len为要发送数据的长度。flag参数可以包含如下的参数
ssize_t recv(int s, void *buf, size_t len, int flags);
recv函数用于从指定套接字中获取发送的消息。与send函数一样,该函数只能用于已经建立连接的socket通信中,即只用于面向连接的通信中。参数s为要读取信息的套接字文件描述符。buf参数为指向要保存数据缓冲区的指针。而len为该缓存的最大长度。
使用套接字除了可以实现网络间不同主机间的通信外,还可以实现同一主机的不同进程间的通信,且建立的通信是双向的通信。这里所指的使用套接字实现进程间通信,是由将通信域指定为PF_UNIX来实现的
AF 表示ADDRESS FAMILY 地址族,PF 表示PROTOCOL FAMILY 协议族,但这两个宏定义是一样的,所以使用哪个都没有关系。Winsock2.h中#define AF_INET 2,#define PF_INET AF_INET,所以在windows中AF_INET与PF_INET完全一样。而在Unix/Linux系统中,在不同的版本中这两者有微小差别。对于BSD,是AF,对于POSIX是PF。UNIX系统支持AF_INET,AF_UNIX,AF_NS等,而DOS,Windows中仅支持AF_INET,它是网际网区域。
AF_INET(又称 PF_INET)是 IPv4 网络协议的套接字类型,AF_INET6 则是 IPv6 的;而 AF_UNIX 则是 Unix 系统本地通信。选择AF_INET 的目的就是使用 IPv4 进行通信。因为 IPv4 使用 32 位地址,相比 IPv6 的 128 位来说,计算更快,便于用于局域网通信。而且 AF_INET 相比 AF_UNIX 更具通用性,因为 Windows 上有 AF_INET 而没有 AF_UNIX。
2.
SOCKET是进程间通信的一种方式,这个时候socket的创建、绑定、连接时的参数是与网络上不同主机间的通信不同的,比如对于socketaddr的使用,进程间通信使用的是sockaddr_un。而主机间的通信使用的是sockadd_in
connect_fd = socket(PF_UNIX, SOCK_STREAM, 0);
if(connect_fd < 0)
{
perror("client create socket failed");
return 1;}
//set server sockaddr_un
srv_addr.sun_family = AF_UNIX;
strcpy(srv_addr.sun_path, UNIX_DOMAIN);
//connect to server
ret = connect(connect_fd, (struct sockaddr*)&srv_addr, sizeof(srv_addr));
至于服务器的,参考下图(流套接字通信示意图):
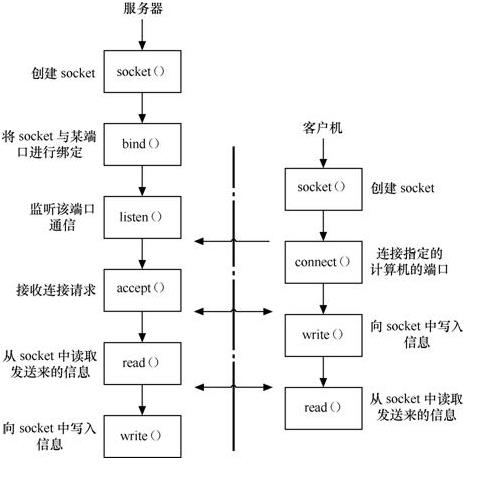
数据报套接字(udp)示意图:
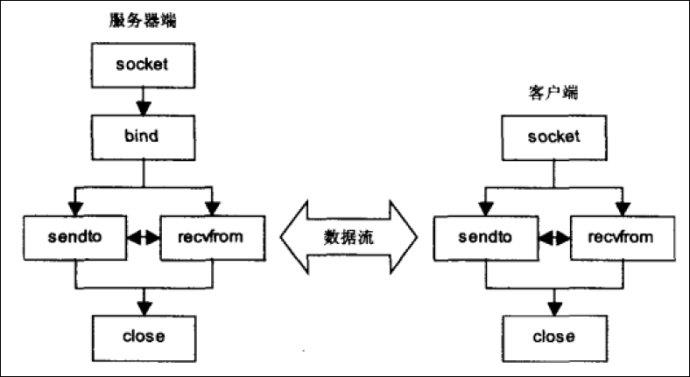
附笔者笔记:
1.网络通信tcp与udp
2.套接字编程



以上是关于Linux 网络编程4网络层--UDP/TCP协议,3次握手4次挥手粘包问题等的主要内容,如果未能解决你的问题,请参考以下文章