基于跳表实现的轻量级KV存储引擎 项目总结
Posted Ray Song
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于跳表实现的轻量级KV存储引擎 项目总结相关的知识,希望对你有一定的参考价值。
项目介绍
KV存储引擎
众所周知,非关系型数据库redis,以及levedb,rockdb其核心存储引擎的数据结构就是跳表。
本项目就是基于跳表实现的轻量级键值型存储引擎,使用C++实现。插入数据、删除数据、查询数据、数据展示、数据落盘、文件加载数据,以及数据库大小显示。
在随机写读情况下,该项目每秒可处理啊请求数(QPS): 24.39w,每秒可处理读请求数(QPS): 18.41w
项目存储文件
- main.cpp 包含skiplist.h使用跳表进行数据操作
- skiplist.h 跳表核心实现
- README.md 中文介绍
- README-en.md 英文介绍
- bin 生成可执行文件目录
- makefile 编译脚本
- store 数据落盘的文件存放在这个文件夹
- stress_test_start.sh 压力测试脚本
- LICENSE 使用协议
提供接口
- insertElement(插入数据)
- deleteElement(删除数据)
- searchElement(查询数据)
- displayList(展示已存数据)
- dumpFile(数据落盘)
- loadFile(加载数据)
- size(返回数据规模)
存储引擎数据表现
- 插入操作
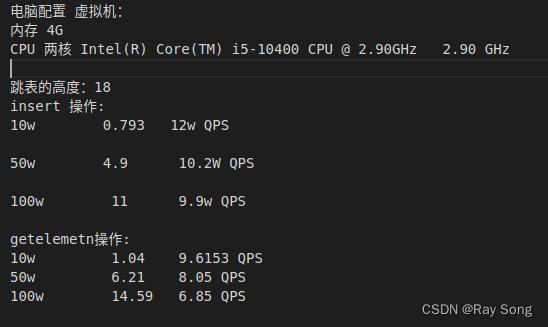
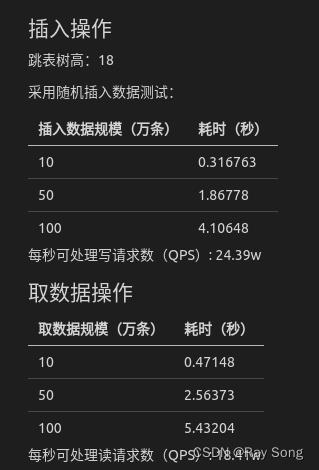
跳表树高:18
采用随机插入数据测试:
| 插入数据规模(万条) | 耗时(秒) |
|---|---|
| 10 | 0.316763 |
| 50 | 1.86778 |
| 100 | 4.10648 |
每秒可处理写请求数(QPS): 24.39w
- 取数据操作
| 取数据规模(万条) | 耗时(秒) |
|---|---|
| 10 | 0.47148 |
| 50 | 2.56373 |
| 100 | 5.43204 |
每秒可处理读请求数(QPS): 18.41w
- 项目运行方式
make // complie demo main.cpp
./bin/main // run
如果想自己写程序使用这个kv存储引擎,只需要在你的CPP文件中include skiplist.h 就可以了。
可以运行如下脚本测试kv存储引擎的性能(当然你可以根据自己的需求进行修改)
sh stress_test_start.sh
待优化
- delete的时候没有释放内存
- 压力测试并不是全自动的
- 跳表的key用int型,如果使用其他类型需要自定义比较函数,当然把这块抽象出来更好
- 如果再加上一致性协议,例如raft就构成了分布式存储,再启动一个http server就可以对外提供分布式存储服务了
部分代码解析
项目涉及知识
- 函数模板、类模板
- 跳表结构的增、删、查 以及 mutex的使用
- 压力测试、线程(pthread 和 chrono)
代码阅读
从main函数开始阅读,然后跳到头文件,最后压力测试
SkipList<int, std::string> skipList(6); 定义了一个6层高度的跳表
头文件全局变量

node节点类
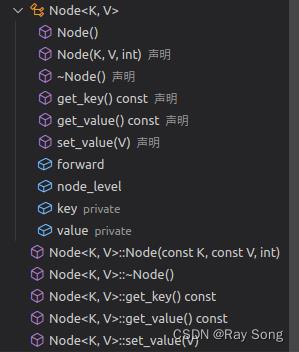
跳表类
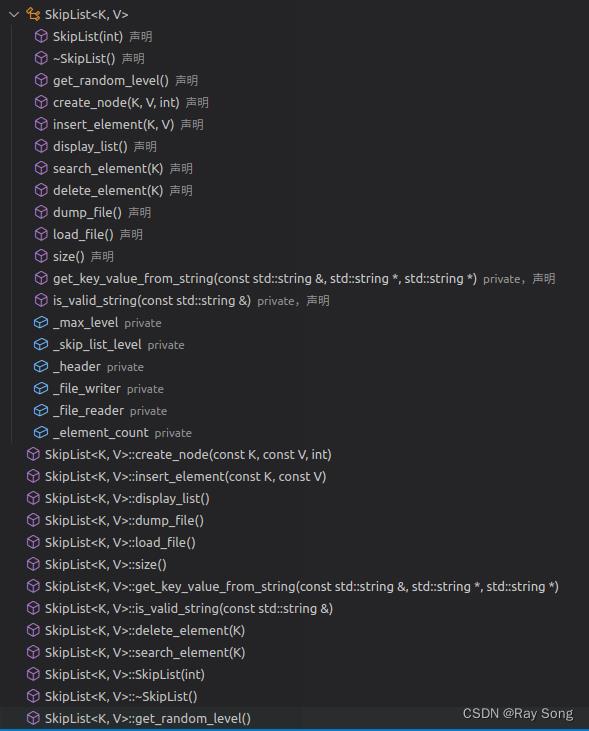
该项目的跳表对Redis的跳表结构进行了一定的简化
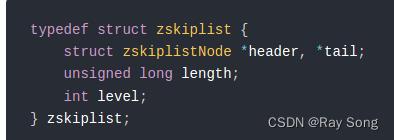
Redis跳表
跳表数据结构:
 代码实现:
代码实现:
 本项目的跳表
本项目的跳表
- 节点
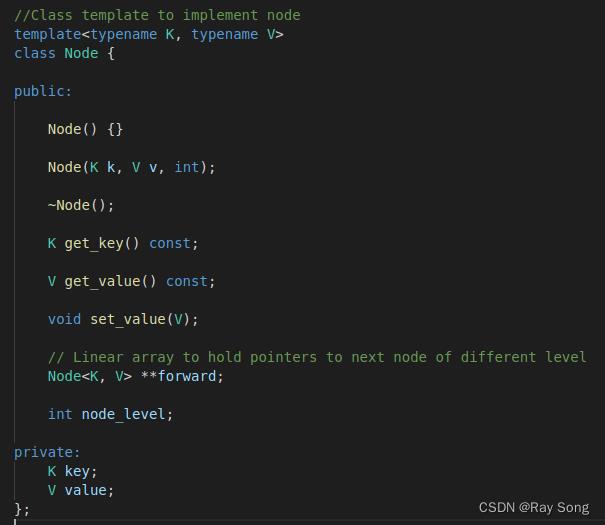
- 跳表
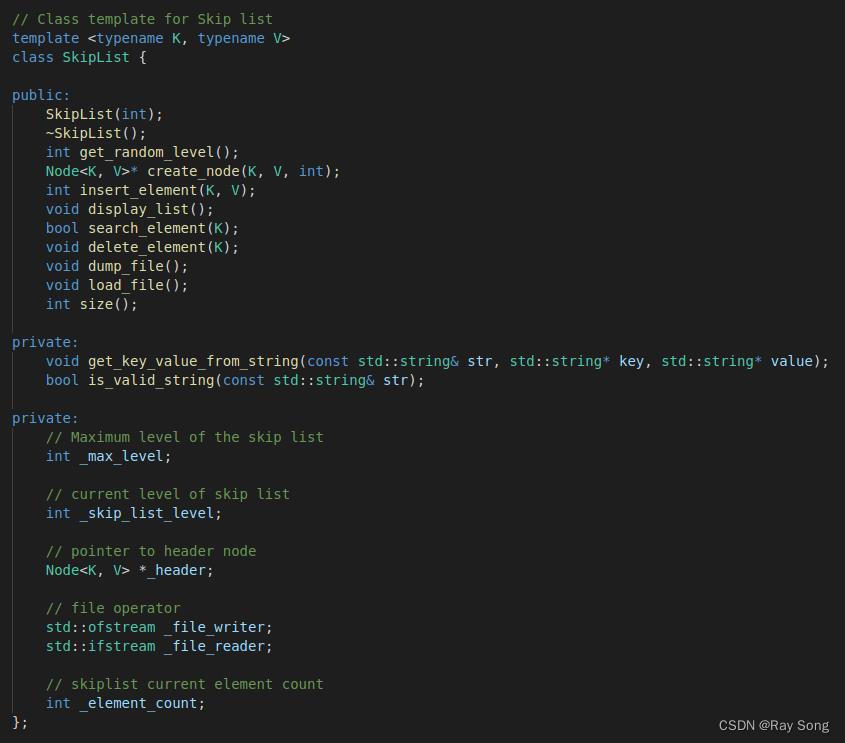
插入节点
template<typename K, typename V>
int SkipList<K, V>::insert_element(const K key, const V value)
mtx.lock();
Node<K, V> *current = this->_header;
// update 是个节点数组,用于后续插入位置的前向链接 和 后向链接
Node<K, V> *update[_max_level+1];
memset(update, 0, sizeof(Node<K, V>*)*(_max_level+1));
// 寻找插入位置,并保存插入位置前面的节点
// for进行高度遍历,while 行方向遍历
for(int i = _skip_list_level; i >= 0; i--)
while(current->forward[i] != NULL && current->forward[i]->get_key() < key)
current = current->forward[i];
update[i] = current;
// 定位到 == key 或者 > key 的 节点
current = current->forward[0];
// 如果current节点存在且和key相等,提示,并解锁
if (current != NULL && current->get_key() == key)
std::cout << "key: " << key << ", exists" << std::endl;
mtx.unlock();
return 1;
//否则,需要在update[0]和current node节点之间插入 [节点]
if (current == NULL || current->get_key() != key )
// 随机生成节点的高度
int random_level = get_random_level();
// 如果随机高度比当前的跳表的高度大,update数组在多余高出来的部分保存头节点指针
if (random_level > _skip_list_level)
for (int i = _skip_list_level+1; i < random_level+1; i++)
update[i] = _header;
_skip_list_level = random_level;
// 用随机生成的高度 创建 insert node
Node<K, V>* inserted_node = create_node(key, value, random_level);
// node节点 forword 指向 所在位置后面的节点指针
// node节点 所在位置前面的节点 指向node
for (int i = 0; i <= random_level; i++)
inserted_node->forward[i] = update[i]->forward[i];
update[i]->forward[i] = inserted_node;
std::cout << "Successfully inserted key:" << key << ", value:" << value << std::endl;
_element_count ++;
mtx.unlock();
return 0;
删除节点
template<typename K, typename V>
void SkipList<K, V>::delete_element(K key)
mtx.lock();
Node<K, V> *current = this->_header;
// update数组 用于保存 删除节点前面的节点 ,用于删除节点后的指向链接,步骤和插入节点类似
Node<K, V> *update[_max_level+1];
memset(update, 0, sizeof(Node<K, V>*)*(_max_level+1));
// 寻找要删除的节点,并将该节点前面的节点保存到update数组中
for (int i = _skip_list_level; i >= 0; i--)
while (current->forward[i] !=NULL && current->forward[i]->get_key() < key)
current = current->forward[i];
update[i] = current;
// ==key 或者 > key 的元素节点
current = current->forward[0];
// 如果相等进行下面的操作,不相等直接解锁 return
if (current != NULL && current->get_key() == key)
// 从低级别开始删除每层的节点,
for (int i = 0; i <= _skip_list_level; i++)
// 如果在第i曾,其下一个节点不是所要删除的节点直接break
if (update[i]->forward[i] != current)
break;
// 如果是要删除的节点 重新设置指针的指向,将其指向下一个节点的位置
update[i]->forward[i] = current->forward[i];
// 减少没有元素的层,更新跳表的level
while (_skip_list_level > 0 && _header->forward[_skip_list_level] == 0)
_skip_list_level --;
std::cout << "Successfully deleted key "<< key << std::endl;
_element_count --;
mtx.unlock();
return;
搜索节点
// Search for element in skip list
/*
+------------+
| select 60 |
+------------+
level 4 +-->1+ 100
|
|
level 3 1+-------->10+------------------>50+ 70 100
|
|
level 2 1 10 30 50| 70 100
|
|
level 1 1 4 10 30 50| 70 100
|
|
level 0 1 4 9 10 30 40 50+-->60 70 100
*/
template<typename K, typename V>
bool SkipList<K, V>::search_element(K key)
std::cout << "search_element-----------------" << std::endl;
Node<K, V> *current = _header;
// for循环高度遍历,while循环水平遍历每一层。
for (int i = _skip_list_level; i >= 0; i--)
while (current->forward[i] && current->forward[i]->get_key() < key)
current = current->forward[i];
// 找到 > 或者 = key的 节点
current = current->forward[0];
// 如果存在且相等,成功找到
if (current and current->get_key() == key)
std::cout << "Found key: " << key << ", value: " << current->get_value() << std::endl;
return true;
// 否则 没有找到 进行提示
std::cout << "Not Found Key:" << key << std::endl;
return false;
进一步优化
- 原始代码使用key进行排序,不具备通用型,增加score变量,通过score权重进行排序;
- 增加反向back指针
- 删除节点的时候没有释放内存,增加智能指针
github网址:
性能测试
-
参数设置
#define NUM_THREADS 1
#define TEST_COUNT 100000
SkipList<int, std::string> skipList(18); -
测试的代码
pthread_t threads[NUM_THREADS];
pthread_create(&threads[i], NULL, insertElement, (void *)i);
void *insertElement(void* threadid)
long tid;
tid = (long)threadid;
std::cout << tid << std::endl;
int tmp = TEST_COUNT/NUM_THREADS;
for (int i=tid*tmp, count=0; count<tmp; i++)
count++;
skipList.insert_element(rand() % TEST_COUNT, "a");
pthread_exit(NULL);
- 计时
auto finish = std::chrono::high_resolution_clock::now();
std::chrono::duration elapsed = finish - start;
std::cout << “insert elapsed:” << elapsed.count() << std::endl;
虚拟机测试:
项目官方测试:
知识补充:
4. c语言中__attribute__的意义 取消内存对齐
5. C++多线程之使用Mutex和Critical_Section
mutex和临界区的区别
异步日志系统
异步日志系统主要涉及了两个模块,一个是日志模块,一个是阻塞队列模块,其中加入阻塞队列模块主要是解决异步写入日志做准备.
- 自定义阻塞队列
- 单例模式创建日志
- 异步日志
0. 生产者消费者模型
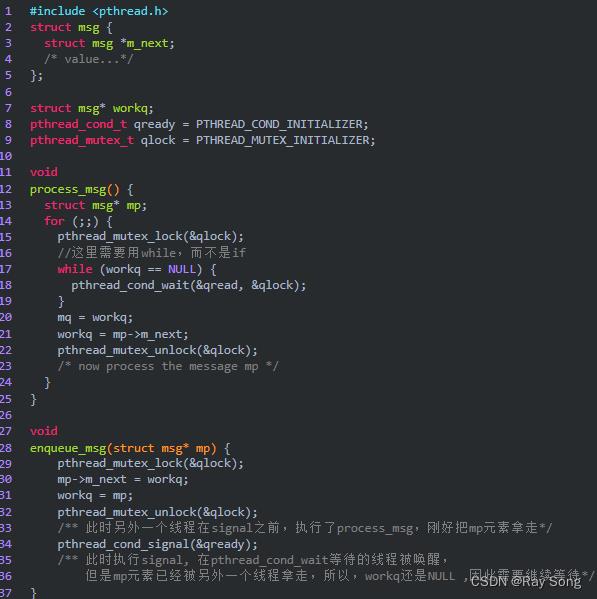
1. 阻塞队列
/*************************************************************
*循环数组实现的阻塞队列,m_back = (m_back + 1) % m_max_size;
*线程安全,每个操作前都要先加互斥锁,操作完后,再解锁
**************************************************************/
private:
locker m_mutex; // 循环数组加锁
cond m_cond; // 条件变量通知
T *m_array; // 循环数组
int m_size; // 已经有的size
int m_max_size; // 最大的size
int m_front; // 头部元素
int m_back; // 尾部元素
- 构造函数
block_queue(int max_size = 1000)
if (max_size <= 0)
exit(-1);
m_max_size = max_size;
m_array = new T[max_size];
m_size = 0;
m_front = -1;
m_back = -1;
- 析构函数
~block_queue()
m_mutex.lock();
if (m_array != NULL)
delete [] m_array;
m_mutex.unlock();
- 队列中添加元素push():
- 0. 先加锁
- 1. 判断阻塞队列是否满了,满了的话就条件变量广播让pop来取,解锁,同时返回false
- 2. 如果阻塞队列没有满的话,就队列尾部添加string, size++,条件变量广播让pop来取,解锁
bool push(const T &item)
m_mutex.lock();
if (m_size >= m_max_size)
m_cond.broadcast();
m_mutex.unlock();
return false;
m_back = (m_back + 1) % m_max_size;
m_array[m_back] = item;
m_size++;
m_cond.broadcast();
m_mutex.unlock();
return true;
- pop消费操作
- 1. 先对阻塞队列加锁
- 2. 如果阻塞队列为空,条件变量阻塞在
-
//pop时,如果当前队列没有元素,将会等待条件变量
bool pop(T &item)
m_mutex.lock();
//多个消费者的时候,这里要是用while而不是if
while (m_size <= 0)
//当重新抢到互斥锁
if (!m_cond.wait(m_mutex.get()))
m_mutex.unlock();
return false;
m_front = (m_front + 1) % m_max_size;
item = m_array[m_front];
m_size--;
m_mutex.unlock();
return true;
- 清空
void clear()
m_mutex.lock();
m_size = 0;
m_front = -1;
m_back = -1;
m_mutex.unlock();
- 判断队列满还是空 返回队首元素 队尾元素
bool full()
bool empty()
bool front(T &value)
bool back(T &value)
- 在size() 和max_size()操作的时候需要对size和max_size变量加锁
2. Log类头文件
单例模式
- 成员变量
private:
char dir_name[128]; //路径名
char log_name[128]; //log文件名
int m_log_buf_size; //日志缓冲区大小
FILE *m_fp; //打开log的文件指针
char *m_buf;
block_queue<string> *m_log_queue; //阻塞队列
locker m_mutex;
- 成员函数
private:
Log();
virtual ~Log();
- public成员函数
//C++11以后,使用局部变量懒汉不用加锁
static Log *get_instance()
static Log instance;
return &instance;
static void *flush_log_thread(void *args)
string single_log;
//从阻塞队列中取出一个日志string,写入文件
while (m_log_queue->pop(single_log))
m_mutex.lock();
fputs(single_log.c_str(), m_fp);
m_mutex.unlock();
//可选择的参数有日志文件、日志缓冲区大小、最长日志条队列
bool init(const char *file_name, int log_buf_size = 8192, int max_queue_size = 1000);
void write_log(int level, const char *format, ...);
void flush(void);
3. Log实现文件
- init函数: 初始化
m_log_queue = new block_queue<string>(max_queue_size);
pthread_t tid;
//flush_log_thread为回调函数,这里表示创建线程异步写日志
pthread_create(&tid, NULL, flush_log_thread, NULL);
m_fp = fopen(log_full_name, "a");
- write_log函数 : 如果阻塞队列满了,就直接将内容追加到日志文件中
if (!m_log_queue->full())
m_log_queue->push(log_str);
else
m_mutex.lock();
fputs(log_str.c_str(), m_fp);
m_mutex.unlock();
- flush强制刷新缓冲区
void Log::flush(void)
m_mutex.lock();
//强制刷新写入流缓冲区
fflush(m_fp);
m_mutex.unlock();
编写你的第一个 Java 版 Raft 分布式 KV 存储
前言
本文旨在讲述如何使用 Java 语言实现基于 Raft 算法的,分布式的,KV 结构的存储项目。该项目的背景是为了深入理解 Raft 算法,从而深刻理解分布式环境下数据强一致性该如何实现;该项目的目标是:在复杂的分布式环境中,多个存储节点能够保证数据强一致性。
项目地址:https://github.com/stateIs0/lu-raft-kv
欢迎 star :)
什么是 Java 版 Raft 分布式 KV 存储
Raft 算法大部分人都已经了解,也有很多实现,从 GitHub 上来看,似乎 Golang 语言实现的较多,比较有名的,例如 etcd。而 Java 版本的,在生产环境大规模使用的实现则较少;
同时,他们的设计目标大部分都是命名服务,即服务注册发现,也就是说,他们通常都是基于 AP 实现,就像 DNS,DNS 是一个命名服务,同时也不是一个强一致性的服务。
比较不同的是 Zookeeper,ZK 常被大家用来做命名服务,但他更多的是一个分布式服务协调者。
而上面的这些都不是存储服务,虽然也都可以做一些存储工作。甚至像 kafka,可以利用 ZK 实现分布式存储。
回到我们这边。
此次我们语言部分使用 Java,RPC 网络通信框架使用的是蚂蚁金服 SOFA-Bolt,底层 KV 存储使用的是 RocksDB,其中核心的 Raft 则由我们自己实现(如果不自己实现,那这个项目没有意义)。 注意,该项目将舍弃一部分性能和可用性,以追求尽可能的强一致性。
为什么要费尽心力重复造轮子
小时候,我们阅读关于高可用的文章时,最后都会提到一个问题:服务挂了怎么办?
通常有 2 种回答:
- 如果是无状态服务,那么毫不影响使用。
- 如果是有状态服务,可以将状态保存到一个别的地方,例如 Redis。如果 Redis 挂了怎么办?那就放到 ZK。
很多中间件,都会使用 ZK 来保证状态一致,例如 codis,kafka。因为使用 ZK 能够帮我们节省大量的时间。但有的时候,中间件的用户觉得引入第三方中间件很麻烦,那么中间件开发者会尝试自己实现一致性,例如 Redis Cluster, TiDB 等。
而通常自己实现,都会使用 Raft 算法,那有人问,为什么不使用"更牛逼的" paxos 算法?对不起,这个有点难,至少目前开源的、生产环境大规模使用的 paxos 算法实现还没有出现,只听过 Google 或者 alibaba 在其内部实现过,具体是什么样子的,这里我们就不讨论了。
回到我们的话题,为什么重复造轮子?从 3 个方面来回答:
- 有的时候 ZK 和 etcd 并不能解决我们的问题,或者像上面说的,引入其他的中间件部署起来太麻烦也太重。
- 完全处于好奇,好奇为什么 Raft 可以保证一致性(这通常可以通过汗牛充栋的文章来得到解答)?但是到底该怎么实现?
- 分布式开发的要求,作为开发分布式系统的程序员,如果能够更深刻的理解分布式系统的核心算法,那么对如何合理设计一个分布式系统将大有益处。
好,有了以上 3 个原因,我们就有足够的动力来造轮子了,接下来就是如何造的问题了。
编写前的 Raft 理论基础
任何实践都是理论先行。如果你对 Raft 理论已经非常熟悉,那么可以跳过此节,直接看实现的步骤。
Raft 为了算法的可理解性,将算法分成了 4 个部分。
- leader 选举
- 日志复制
- 成员变更
- 日志压缩
同 zk 一样,leader 都是必须的,所有的写操作都是由 leader 发起,从而保证数据流向足够简单。而 leader 的选举则通过比较每个节点的逻辑时间(term)大小,以及日志下标(index)的大小。
刚刚说 leader 选举涉及日志下标,那么就要讲日志复制。日志复制可以说是 Raft 核心的核心,说简单点,Raft 就是为了保证多节点之间日志的一致。当日志一致,我们可以认为整个系统的状态是一致的。这个日志你可以理解成 mysql 的 binlog。
Raft 通过各种补丁,保证了日志复制的正确性。
Raft leader 节点会将客户端的请求都封装成日志,发送到各个 follower 中,如果集群中超过一半的 follower 回复成功,那么这个日志就可以被提交(commit),这个 commit 可以理解为 ACID 的 D ,即持久化。当日志被持久化到磁盘,后面的事情就好办了。
而第三点则是为了节点的扩展性。第四点是为了性能。相比较 leader 选举和 日志复制,不是那么的重要,可以说,如果没有成员变更和日志压缩,也可以搞出一个可用的 Raft 分布式系统,但没有 leader 选举和日志复制,是万万不能的。
因此,本文和本项目将重点放在 leader 选举和日志复制。
以上,就简单说明了 Raft 的算法,关于 Raft 算法更多的文章,请参考本人博客中的其他文章(包含官方各个版本论文和 PPT & 动画 & 其他博客文章),博客地址:thinkinjava.cn
实现的步骤
实现目标:基于 Raft 论文实现 Raft 核心功能,即 Leader 选举 & 日志复制。
Raft 核心组件包括:一致性模块,RPC 通信,日志模块,状态机。
技术选型:
- 一致性模块,是 Raft 算法的核心实现,通过一致性模块,保证 Raft 集群节点数据的一致性。这里我们需要自己根据论文描述去实现。
- RPC 通信,可以使用 HTTP 短连接,也可以直接使用 TCP 长连接,考虑到集群各个节点频繁通信,同时节点通常都在一个局域网内,因此我们选用 TCP 长连接。而 Java 社区长连接框架首选 Netty,这里我们选用蚂蚁金服网络通信框架 SOFA-Bolt(基于 Netty),便于快速开发。
- 日志模块,Raft 算法中,日志实现是基础,考虑到时间因素,我们选用 RocksDB 作为日志存储。
- 状态机,可以是任何实现,其实质就是将日志中的内容进行处理。可以理解为 Mysql binlog 中的具体数据。由于我们是要实现一个 KV 存储,那么可以直接使用日志模块的 RocksDB 组件。
以上。我们可以看到,得益于开源世界,我们开发一个 Raft 存储,只需要编写一个“一致性模块”就行了,其他模块都有现成的轮子可以使用,真是美滋滋。
接口设计:
上面我们说了 Raft 的几个核心功能,事实上,就可以理解为接口。所以我们定义以下几个接口:
- Consensus, 一致性模块接口
- LogModule,日志模块接口
- StateMachine, 状态机接口
- RpcServer & RpcClient, RPC 接口
- Node,同时,为了聚合上面的几个接口,我们需要定义一个 Node 接口,即节点,Raft 抽象的机器节点。
- LifeCycle, 最后,我们需要管理以上组件的生命周期,因此需要一个 LifeCycle 接口。
接下来,我们需要详细定义核心接口 Consensus。我们根据论文定义了 2 个核心接口:
/**
* 请求投票 RPC
*
* 接收者实现:
*
* 如果term < currentTerm返回 false (5.2 节)
* 如果 votedFor 为空或者就是 candidateId,并且候选人的日志至少和自己一样新,那么就投票给他(5.2 节,5.4 节)
*/
RvoteResult requestVote(RvoteParam param);
/**
* 附加日志(多个日志,为了提高效率) RPC
*
* 接收者实现:
*
* 如果 term < currentTerm 就返回 false (5.1 节)
* 如果日志在 prevLogIndex 位置处的日志条目的任期号和 prevLogTerm 不匹配,则返回 false (5.3 节)
* 如果已经存在的日志条目和新的产生冲突(索引值相同但是任期号不同),删除这一条和之后所有的 (5.3 节)
* 附加任何在已有的日志中不存在的条目
* 如果 leaderCommit > commitIndex,令 commitIndex 等于 leaderCommit 和 新日志条目索引值中较小的一个
*/
AentryResult appendEntries(AentryParam param);请求投票 & 附加日志。也就是我们的 Raft 节点的核心功能,leader 选举和 日志复制。实现这两个接口是 Raft 的关键所在。
然后再看 LogModule 接口,这个自由发挥,考虑日志的特点,我定义了以下几个接口:
void write(LogEntry logEntry);
LogEntry read(Long index);
void removeOnStartIndex(Long startIndex);
LogEntry getLast();
Long getLastIndex();
分别是写,读,删,最后是两个关于 Last 的接口,在 Raft 中,Last 是一个非常关键的东西,因此我这里单独定义了 2个方法,虽然看起来不是很好看 :)
状态机接口,在 Raft 论文中,将数据保存到状态机,作者称之为应用,那么我们也这么命名,说白了,就是将已成功提交的日志应用到状态机中:
/**
* 将数据应用到状态机.
*
* 原则上,只需这一个方法(apply). 其他的方法是为了更方便的使用状态机.
* @param logEntry 日志中的数据.
*/
void apply(LogEntry logEntry);
LogEntry get(String key);
String getString(String key);
void setString(String key, String value);
void delString(String... key);
第一个 apply 方法,就是 Raft 论文常常提及的方法,即将日志应用到状态机中,后面的几个方法,都是我为了方便获取数据设计的,可以不用在意,甚至于,这几个方法不存在也不影响 Raft 的实现,但影响 KV 存储的实现,试想:一个系统只有保存功能,没有获取功能,要你何用?。
RpcClient 和 RPCServer 没什么好讲的,其实就是 send 和 receive。
然后是 Node 接口,Node 接口也是 Raft 没有定义的,我们依靠自己的理解定义了几个接口:
/**
* 设置配置文件.
*
* @param config
*/
void setConfig(NodeConfig config);
/**
* 处理请求投票 RPC.
*
* @param param
* @return
*/
RvoteResult handlerRequestVote(RvoteParam param);
/**
* 处理附加日志请求.
*
* @param param
* @return
*/
AentryResult handlerAppendEntries(AentryParam param);
/**
* 处理客户端请求.
*
* @param request
* @return
*/
ClientKVAck handlerClientRequest(ClientKVReq request);
/**
* 转发给 leader 节点.
* @param request
* @return
*/
ClientKVAck redirect(ClientKVReq request);首先,一个 Node 肯定需要配置文件,所以有一个 setConfig 接口,
然后,肯定需要处理“请求投票”和“附加日志”,同时,还需要接收用户,也就是客户端的请求(不然数据从哪来?),所以有 handlerClientRequest 接口,最后,考虑到灵活性,我们让每个节点都可以接收客户端的请求,但 follower 节点并不能处理请求,所以需要重定向到 leader 节点,因此,我们需要一个重定向接口。
最后是生命周期接口,这里我们简单定义了 2 个,有需要的话,再另外加上组合接口:
void init() throws Throwable;
void destroy() throws Throwable;好,基本的接口定义完了,后面就是实现了。实现才是关键。
Leader 选举的实现
选举,其实就是一个定时器,根据 Raft 论文描述,如果超时了就需要重新选举,我们使用 Java 的定时任务线程池进行实现,实现之前,需要确定几个点:
- 选举者必须不是 leader。
- 必须超时了才能选举,具体超时时间根据你的设计而定,注意,每个节点的超时时间不能相同,应当使用随机算法错开(Raft 关键实现),避免无谓的死锁。
- 选举者优先选举自己,将自己变成 candidate。
- 选举的第一步就是把自己的 term 加一。
- 然后像其他节点发送请求投票 RPC,请求参数参照论文,包括自身的 term,自身的 lastIndex,以及日志的 lastTerm。同时,请求投票 RPC 应该是并行请求的。
- 等待投票结果应该有超时控制,如果超时了,就不等待了。
- 最后,如果有超过半数的响应为 success,那么就需要立即变成 leader ,并发送心跳阻止其他选举。
- 如果失败了,就需要重新选举。注意,这个期间,如果有其他节点发送心跳,也需要立刻变成 follower,否则,将死循环。
具体代码,可参见 https://github.com/stateIs0/lu-raft-kv/blob/master/lu-raft-kv/src/main/java/cn/think/in/java/impl/DefaultNode.java#L546
上面说的,其实是 Leader 选举中,请求者的实现,那么接收者如何实现呢?接收者在收到“请求投票” RPC 后,需要做以下事情:
- 注意,选举操作应该是串行的,因为涉及到状态修改,并发操作将导致数据错乱。也就是说,如果抢锁失败,应当立即返回错误。
- 首先判断对方的 term 是否小于自己,如果小于自己,直接返回失败。
- 如果当前节点没有投票给任何人,或者投的正好是对方,那么就可以比较日志的大小,反之,返回失败。
- 如果对方日志没有自己大,返回失败。反之,投票给对方,并变成 follower。变成 follower 的同时,异步的选举任务在最后从 condidate 变成 leader 之前,会判断是否是 follower,如果是 follower,就放弃成为 leader。这是一个兜底的措施。
具体代码参见 https://github.com/stateIs0/lu-raft-kv/blob/master/lu-raft-kv/src/main/java/cn/think/in/java/impl/DefaultConsensus.java#L51
到这里,基本就能够实现 Raft Leader 选举的逻辑。
注意,我们上面涉及到的 LastIndex 等参数,还没有实现,但不影响我们编写伪代码,毕竟日志复制比 leader 选举要复杂的多,我们的原则是从易到难。:)
日志复制的实现
日志复制是 Raft 实现一致性的核心。
日志复制有 2 种形式,1种是心跳,一种是真正的日志,心跳的日志内容是空的,其他部分基本相同,也就是说,接收方在收到日志时,如果发现是空的,那么他就是心跳。
心跳
既然是心跳,肯定就是个定时任务,和选举一样。在我们的实现中,我们每 5 秒发送一次心跳。注意点:
- 首先自己必须是 leader 才能发送心跳。
- 必须满足 5 秒的时间间隔。
- 并发的向其他 follower 节点发送心跳。
- 心跳参数包括自身的 ID,自身的 term,以便让对方检查 term,防止网络分区导致的脑裂。
- 如果任意 follower 的返回值的 term 大于自身,说明自己分区了,那么需要变成 follower,并更新自己的 term。然后重新发起选举。
具体代码查看:https://github.com/stateIs0/lu-raft-kv/blob/master/lu-raft-kv/src/main/java/cn/think/in/java/impl/DefaultNode.java#L695
然后是心跳接收者的实现,这个就比较简单了,接收者需要做几件事情:
- 无论成功失败首先设置返回值,也就是将自己的 term 返回给 leader。
- 判断对方的 term 是否大于自身,如果大于自身,变成 follower,防止异步的选举任务误操作。同时更新选举时间和心跳时间。
- 如果对方 term 小于自身,返回失败。不更新选举时间和心跳时间。以便触发选举。
具体代码参见:https://github.com/stateIs0/lu-raft-kv/blob/master/lu-raft-kv/src/main/java/cn/think/in/java/impl/DefaultConsensus.java#L109
说完了心跳,再说说真正的日志附加。
简单来说,当用户向 Leader 发送一个 KV 数据,那么 Leader 需要将 KV数据封装成日志,并行的发送到其他的 follower 节点,只要在指定的超时时间内,有过半几点返回成功,那么久提交(持久化)这条日志,返回客户端成功,否者返回失败。
因此,Leader 节点会有一个 ClientKVAck handlerClientRequest(ClientKVReq request) 接口,用于接收用户的 KV 数据,同时,会并行向其他节点复制数据,具体步骤如下:
- 每个节点都可能会接收到客户端的请求,但只有 leader 能处理,所以如果自身不是 leader,则需要转发给 leader。
- 然后将用户的 KV 数据封装成日志结构,包括 term,index,command,预提交到本地。
- 并行的向其他节点发送数据,也就是日志复制。
- 如果在指定的时间内,过半节点返回成功,那么就提交这条日志。
- 最后,更新自己的 commitIndex,lastApplied 等信息。
注意,复制不仅仅是简单的将这条日志发送到其他节点,这可能比我们想象的复杂,为了保证复杂网络环境下的一致性,Raft 保存了每个节点的成功复制过的日志的 index,即 nextIndex ,因此,如果对方之前一段时间宕机了,那么,从宕机那一刻开始,到当前这段时间的所有日志,都要发送给对方。
甚至于,如果对方觉得你发送的日志还是太大,那么就要递减的减小 nextIndex,复制更多的日志给对方。注意:这里是 Raft 实现分布式一致性的关键所在。
具体代码参见:https://github.com/stateIs0/lu-raft-kv/blob/master/lu-raft-kv/src/main/java/cn/think/in/java/impl/DefaultNode.java#L244
再来看看日志接收者的实现步骤:
- 和心跳一样,要先检查对方 term,如果 term 都不对,那么就没什么好说的了。
- 如果日志不匹配,那么返回 leader,告诉他,减小 nextIndex 重试。
- 如果本地存在的日志和 leader 的日志冲突了,以 leader 的为准,删除自身的。
- 最后,将日志应用到状态机,更新本地的 commitIndex,返回 leader 成功。
具体代码参见:https://github.com/stateIs0/lu-raft-kv/blob/master/lu-raft-kv/src/main/java/cn/think/in/java/impl/DefaultConsensus.java#L109
到这里,日志复制的部分就讲完了。
注意,实现日志复制的前提是,必须有一个正确的日志存储系统,即我们的 RocksDB,我们在 RocksDB 的基础上,使用一种机制,维护了 每个节点 的LastIndex,无论何时何地,都能够得到正确的 LastIndex,这是实现日志复制不可获取的一部分。
验证“Leader 选举”和“日志复制”
写完了程序,如何验证是否正确呢?
当然是写验证程序。
我们首先验证 “Leader 选举”。其实这个比较好测试。
- 在 idea 中配置 5 个 application 启动项,配置 main 类为 RaftNodeBootStrap 类, 加入 -DserverPort=8775 -DserverPort=8776 -DserverPort=8777 -DserverPort=8778 -DserverPort=8779
系统配置, 表示分布式环境下的 5 个机器节点. - 依次启动 5 个 RaftNodeBootStrap 节点, 端口分别是 8775,8776, 8777, 8778, 8779.
- 观察控制台, 约 6 秒后, 会发生选举事件,此时,会产生一个 leader. 而 leader 会立刻发送心跳维持自己的地位.
- 如果leader 的端口是 8775, 使用 idea 关闭 8775 端口,模拟节点挂掉, 大约 15 秒后, 会重新开始选举, 并且会在剩余的 4 个节点中,产生一个新的 leader. 并开始发送心跳日志。
然后验证 日志复制,分为 2 种情况:
正常状态下
- 在 idea 中配置 5 个 application 启动项,配置 main 类为 RaftNodeBootStrap 类, 加入 -DserverPort=8775 -DserverPort=8776 -DserverPort=8777 -DserverPort=8778 -DserverPort=8779
- 依次启动 5 个 RaftNodeBootStrap 节点, 端口分别是 8775,8776, 8777, 8778, 8779.
- 使用客户端写入 kv 数据.
- 杀掉所有节点, 使用 junit test 读取每个 rocksDB 的值, 验证每个节点的数据是否一致.
非正常状态下
- 在 idea 中配置 5 个 application 启动项,配置 main 类为 RaftNodeBootStrap 类, 加入 -DserverPort=8775 -DserverPort=8776 -DserverPort=8777 -DserverPort=8778 -DserverPort=8779
- 依次启动 5 个 RaftNodeBootStrap 节点, 端口分别是 8775,8776, 8777, 8778, 8779.
- 使用客户端写入 kv 数据.
- 杀掉 leader (假设是 8775).
- 再次写入数据.
- 重启 8775.
- 关闭所有节点, 读取 RocksDB 验证数据一致性.
Summary
本文并没有贴很多代码,如果要贴代码的话,阅读体验将不会很好,并且代码也不能说明什么,如果想看具体实现,可以到 github 上看看,顺便给个 star :)
该项目 Java 代码约 2500 行,核心代码估计也就 1000 多行。你甚至可以说,这是个玩具代码,但我相信毕玄大师所说,玩具代码经过优化后,也是可以变成可在商业系统中真正健壮运行的代码(http://hellojava.info/?p=508) :)
回到我们的初衷,我们并不奢望这段代码能够运行在生产环境中,就像我的另一个项目 Lu-RPC 一样。但,经历了一次编写可正确运行的玩具代码的经历,下次再次编写工程化的代码,应该会更加容易些。这点我深有体会。
可以稍微展开讲一下,在写完 Lu-RPC 项目后,我就接到了开发生产环境运行的限流熔断框架任务,此时,开发 Lu-RPC 的经历让我在开发该框架时,更加的从容和自如:)
再回到 Raft 上面来,虽然上面的测试用例跑过了,程序也经过了我反反复复的测试,但不代表这个程序就是 100% 正确的,特别是在复杂的分布式环境下。如果你对 Raft 有兴趣,欢迎一起交流沟通 :)
项目地址:https://github.com/stateIs0/lu-raft-kv
以上是关于基于跳表实现的轻量级KV存储引擎 项目总结的主要内容,如果未能解决你的问题,请参考以下文章