63 ALTERNATIVE I/O MODELS
Posted 你回到了你的家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了63 ALTERNATIVE I/O MODELS相关的知识,希望对你有一定的参考价值。
1 Overview
补充
1.1 Level-Triggered and Edge-Triggered Notification
Before discussing the various alternative I/O mechanisms in detail, we need to distinguish two models of readiness notification for a file descriptor:
- Level-triggered notification: A file descriptor is considered to be ready if it is possible to perform an I/O system call without blocking.
- Edge-triggered notification: Notification is provided if there is I/O activity (e.g., new input) on a file descriptor since it was last monitored.
Table 63-1 summarizes the notification models employed by I/O multiplexing, signal-driven I/O, and epoll. The epoll API differs from the other two I/O models in that it can employ both level-triggered notification (the default) and edge-triggered
notification.

Details of the differences between these two notification models will become clearer during the course of the chapter. For now, we describe how the choice of notification model affects the way we design a program.
When we employ level-triggered notification, we can check the readiness of a file descriptor at any time. This means that when we determine that a file descriptor is ready (e.g., it has input available), we can perform some I/O on the descriptor, and then repeat the monitoring operation to check if the descriptor is still ready (e.g., it still has more input available), in which case we can perform more I/O, and so on. In other words, because the level-triggered model allows us to repeat the I/O monitoring operation at any time, it is not necessary to perform as much I/O as possible (e.g., read as many bytes as possible) on the file descriptor (or even perform any I/O at all) each time we are notified that a file descriptor is ready.
By contrast, when we employ edge-triggered notification, we receive notification only when an I/O event occurs. We don’t receive any further notification until another I/O event occurs. Furthermore, when an I/O event is notified for a file descriptor, we usually don’t know how much I/O is possible (e.g., how many bytes
are available for reading). Therefore, programs that employ edge-triggered notification are usually designed according to the following rules:
- After notification of an I/O event, the program should—at some point—perform as much I/O as possible (e.g., read as many bytes as possible) on the corresponding file descriptor. If the program fails to do this, then it might miss the opportunity to perform some I/O, because it would not be aware of the need to operate on the file descriptor until another I/O event occurred. This could lead to spurious data loss or blockages in a program. We said “at some point,” because sometimes it may not be desirable to perform all of the I/O immediately after we determine that the file descriptor is ready. The problem is that we may starve other file descriptors of attention if we perform a large amount of I/O on one file descriptor. We consider this point in more detail when we describe the edge-triggered notification model for epoll in Section 63.4.6.
- If the program employs a loop to perform as much I/O as possible on the file
descriptor, and the descriptor is marked as blocking, then eventually an I/O sys-
tem call will block when no more I/O is possible. For this reason, each monitored
file descriptor is normally placed in nonblocking mode, and after notification
of an I/O event, I/O operations are performed repeatedly until the relevant
system call (e.g., read() or write()) fails with the error EAGAIN or EWOULDBLOCK.
1.2 Employing Nonblocking I/O with Alternative I/O Models
Nonblocking I/O (the O_NONBLOCK flag) is often used in conjunction with the I/O models described in this chapter. Some examples of why this can be useful are the following:
- As explained in the previous section, nonblocking I/O is usually employed in conjunction with I/O models that provide edge-triggered notification of I/O events.
- If multiple processes (or threads) are performing I/O on the same open file descriptions, then, from a particular process’s point of view, a descriptor’s readiness may change between the time the descriptor was notified as being ready and the time of the subsequent I/O call. Consequently, a blocking I/O call could block, thus preventing the process from monitoring other file descriptors. (This can occur for all of the I/O models that we describe in this chapter, regardless of whether they employ level-triggered or edge-triggered notification.)
- Even after a level-triggered API such as select() or poll() informs us that a file descriptor for a stream socket is ready for writing, if we write a large enough block of data in a single write() or send(), then the call will nevertheless block.
- In rare cases, level-triggered APIs such as select() and poll() can return spurious
readiness notifications—they can falsely inform us that a file descriptor is ready.
This could be caused by a kernel bug or be expected behavior in an uncom-
mon scenario.
Section 16.6 of [Stevens et al., 2004] describes one example of spurious readi-
ness notifications on BSD systems for a listening socket. If a client connects to
a server’s listening socket and then resets the connection, a select() performed
by the server between these two events will indicate the listening socket as
being readable, but a subsequent accept() that is performed after the client’s
reset will block.
2 I/O Multiplexing
I/O multiplexing allows us to simultaneously monitor multiple file descriptors to
see if I/O is possible on any of them. We can perform I/O multiplexing using
either of two system calls with essentially the same functionality. The first of these,
select(), appeared along with the sockets API in BSD. This was historically the more
widespread of the two system calls. The other system call, poll(), appeared in System V.
Both select() and poll() are nowadays required by SUSv3.
We can use select() and poll() to monitor file descriptors for regular files, termi-
nals, pseudoterminals, pipes, FIFOs, sockets, and some types of character devices.
Both system calls allow a process either to block indefinitely waiting for file descrip-
tors to become ready or to specify a timeout on the call.
2.1 The select() System Call
The select() system call blocks until one or more of a set of file descriptors becomes ready.
#include <sys/time.h>
#include <sys/select.h>
/* For portability */
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds,
struct timeval *timeout);
//Returns number of ready file descriptors, 0 on timeout, or –1 on error
The nfds, readfds, writefds, and exceptfds arguments specify the file descriptors that
select() is to monitor. The timeout argument can be used to set an upper limit on the
time for which select() will block. We describe each of these arguments in detail below.
In the prototype for select() shown above, we include <sys/time.h> because that
was the header specified in SUSv2, and some UNIX implementations require
this header. (The <sys/time.h> header is present on Linux, and including it
does no harm.)
File descriptor sets
补充
The timeout argument
补充
Return value from select()
补充
Example program
补充
2.2 The poll() System Call
The poll() system call performs a similar task to select(). The major difference
between the two system calls lies in how we specify the file descriptors to be moni-
tored. With select(), we provide three sets, each marked to indicate the file descriptors
of interest. With poll(), we provide a list of file descriptors, each marked with the set of
events of interest.
补充
2.3 When Is a File Descriptor Ready?
Correctly using select() and poll() requires an understanding of the conditions under which a file descriptor indicates as being ready. SUSv3 says that a file descriptor (with O_NONBLOCK clear) is considered to be ready if a call to an I/O function would not block, regardless of whether the function would actually transfer data. The key point is italicized: select() and poll() tell us whether an I/O operation would not block, rather than whether it would successfully transfer data. In this light, let us consider how these system calls operate for different types of file descriptors. We show this information in tables containing two columns:
- The select() column indicates whether a file descriptor is marked as readable ( r ), writable ( w ), or having an exceptional condition ( x ).
- The poll() column indicates the bit(s) returned in the revents field. In these tables, we omit mention of POLLRDNORM, POLLWRNORM, POLLRDBAND, and POLLWRBAND. Although some of these flags may be returned in revents in various circumstances (if they are specified in events), they convey no useful information
beyond that provided by POLLIN, POLLOUT, POLLHUP, and POLLERR.
Regular files
File descriptors that refer to regular files are always marked as readable and writable by select(), and returned with POLLIN and POLLOUT set in revents for poll(), for the following reasons:
补充
2.5 Problems with select() and poll()
The select() and poll() system calls are the portable, long-standing, and widely used
methods of monitoring multiple file descriptors for readiness. However, these
APIs suffer some problems when monitoring a large number of file descriptors:
3 Signal-Driven I/O
With I/O multiplexing, a process makes a system call (select() or poll()) in order to check whether I/O is possible on a file descriptor. With signal-driven I/O, a process requests that the kernel send it a signal when I/O is possible on a file descriptor. The process can then perform any other activity until I/O is possible, at which time the signal is delivered to the process. To use signal-driven I/O, a program performs the following steps:
- Establish a handler for the signal delivered by the signal-driven I/O mechanism. By default, this notification signal is SIGIO.
- Set the owner of the file descriptor—that is, the process or process group that is to receive signals when I/O is possible on the file descriptor. Typically, we make the calling process the owner. The owner is set using an fcntl() F_SETOWN operation of the following form:
fcntl(fd, F_SETOWN, pid); - Enable nonblocking I/O by setting the O_NONBLOCK open file status flag.
4 The epoll API
Like the I/O multiplexing system calls and signal-driven I/O, the Linux epoll (event poll) API is used to monitor multiple file descriptors to see if they are ready for I/O.
The primary advantages of the epoll API are the following:
- The performance of epoll scales much better than select() and poll() when moni-toring large numbers of file descriptors.
- The epoll API permits either level-triggered or edge-triggered notification. By contrast, select() and poll() provide only level-triggered notification, and signal-driven I/O provides only edge-triggered notification.
The performance of epoll and signal-driven I/O is similar. However, epoll has some advantages over signal-driven I/O:
- We avoid the complexities of signal handling (e.g., signal-queue overflow).
- We have greater flexibility in specifying what kind of monitoring we want to perform (e.g., checking to see if a file descriptor for a socket is ready for reading, writing, or both).
补充
五种I/O模型
文档地址:https://www.cse.huji.ac.il/course/2004/com1/Exercises/Ex4/I.O.models.pdf
五种I/O模型:
1. blocking I/O 阻塞I/O
2. nonblocking I/O 非阻塞I/O
3. I/O multiplexing (select and poll) I/O多路复用
4. signal driven I/O (SIGIO) 信号驱动I/O
5. asynchronous I/O (the POSIX aio_functions) 异步I/O
对于input操作,有两个不同的阶段:
1. 等待数据准备完毕(用户空间 通过 内核空间 调用系统资源,数据准备完毕是在内核里的)
2. 从kernel拷贝数据到相应的进程 (即从 内核空间 复制到 用户空间 的某个进程,内核空间是系统内核运行的地方,用户空间是用户程序运行的地方,两者是独立分割的,用户空间没有什么权限,只能通过内核空间调用系统资源)
对于socket的input,两个阶段通常是:
1. 等待网络的数据到达,并将数据拷贝到内核空间的buffer里。
2. 从kernel的buffer里拷贝数据到应用程序的buffer
1. 阻塞I/O
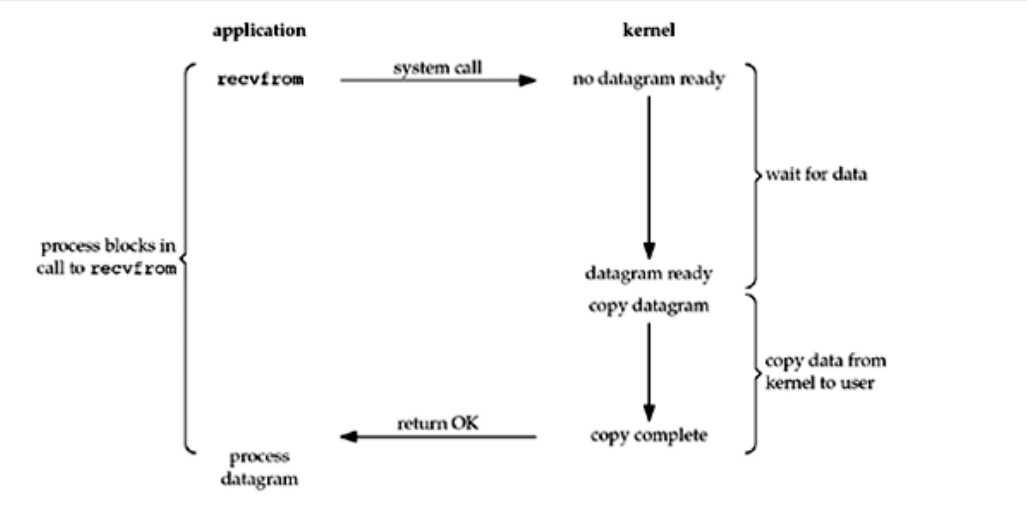
上图使用的是UDP协议,在这个过程中,进程调用recvfrom,在这个过程中,程序一直是阻塞的,直到网络数据报到达本地,并且数据从内核空间拷贝到了用户空间,此时才会return,当recvfrom成功return后,应用程序才获取到这个数据报。
从图看出,此模型全程阻塞。
2. 非阻塞I/O
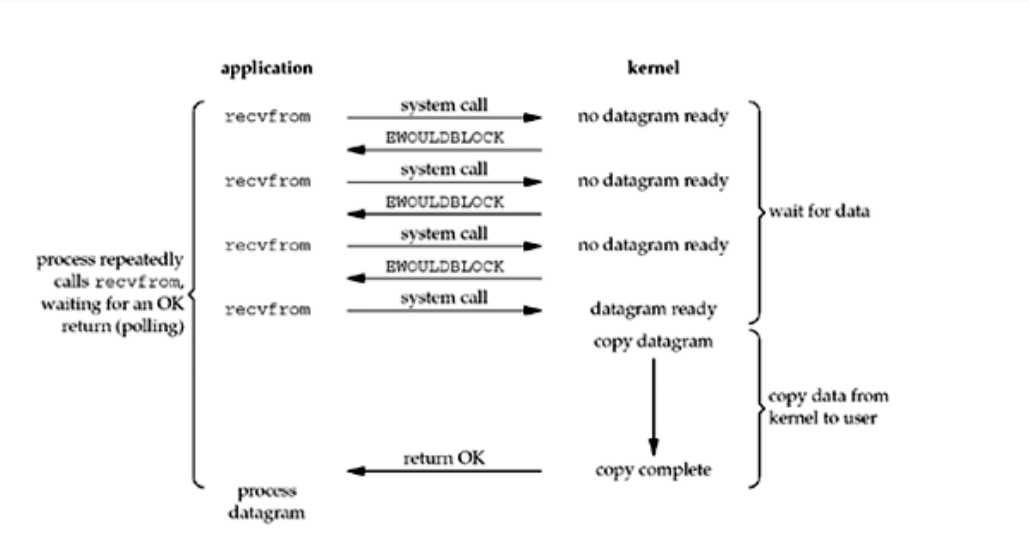
首先,进程每隔一阵子调用一次 recvfrom,图中前三次调用recvfrom,但是数据报没有准备好,所以每一次内核都返回EWOULDBLOCK错误,第四次调用recvfrom,数据报此时已经准备完毕,拷贝到用户空间中后,recvfrom成功返回,此时进程就获取到了值。
当系统用这种不停的循环的方法对一个非阻塞的描述符调用recvfrom,这种被称为polling
此模型并不阻塞,但是需要循环查询,浪费CPU的时间,低效。
3. 多路复用I/O
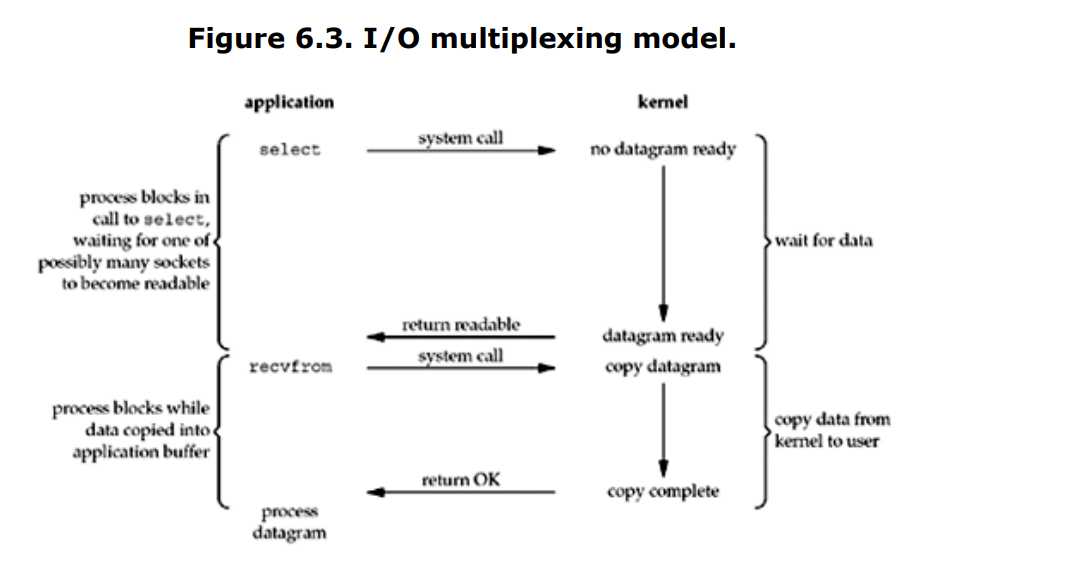
给一个select阻塞住,直到数据报readable(也就是准备好了,readable是select返回的值),当select返回readable时,说明数据报准备好了,此时就recvfrom,让数据报从内核空间拷贝到用户空间,拷贝完成后,recvfrom返回成功,数据报也就成功的被用户程序所拥有了。
其实select并没有什么优势,反而略微有点劣势,因为它使用了两次系统调用,而不是一次。但是它的优势是它能够等待多个描述符准备好。
此模型也会阻塞,但是它可以等待多个描述符准备,因此还是有优势的。
4. 信号驱动的I/O
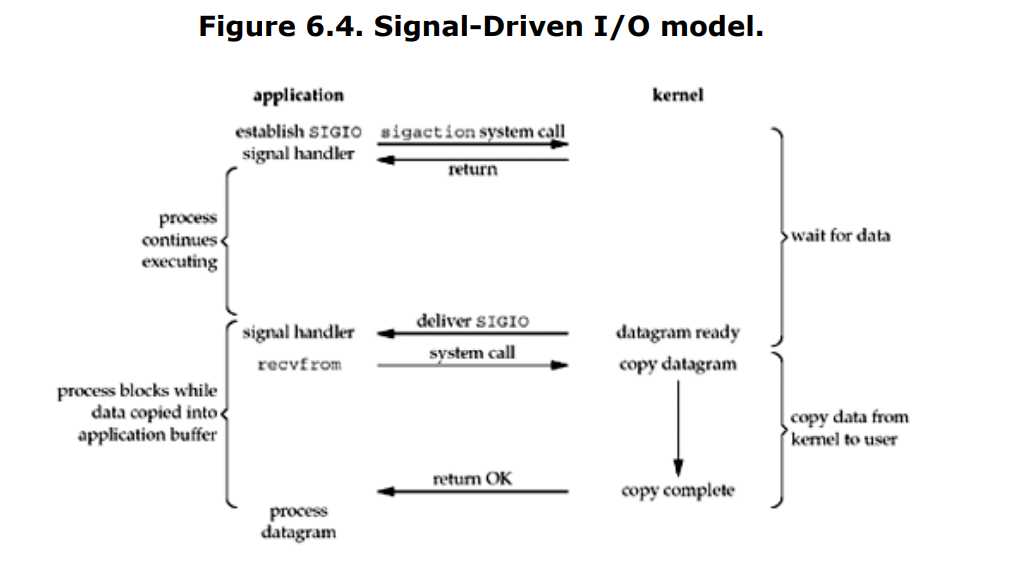
除了上面的方法,我们也可以使用信号,告诉内核当数据报准备好时,你就用信号通知我。
首先启动信号驱动I/O的socket,然后安装一个使用sigaction系统调用的signal handler,这个系统调用是立即返回的,并且返回后还继续执行,它是非阻塞的,当数据报准备好时,就会生成SIGIO信号,我们可以调用recvfrom从signal handler读取数据,并且告诉主循环数据已经准备好被获取了;或者我们可以通知主循环,让它自己读取数据。
此模型第一个阶段是非阻塞的,主循环可以做别的事情,但是从内核拷贝数据到用户的过程,是阻塞的。
5. 异步I/O
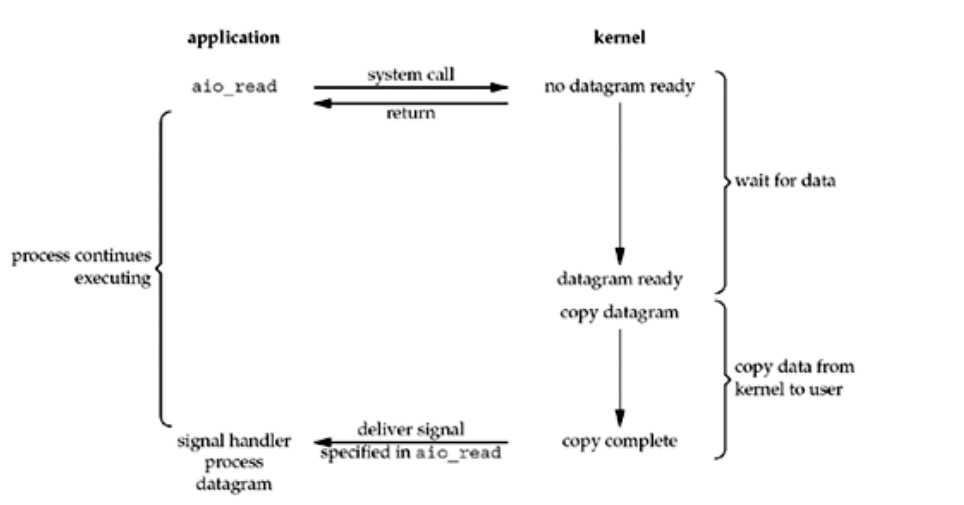
异步I/O是完全不阻塞的模型,它调用aio_read,会立刻返回,在等待I/O的过程中,进程是完全不阻塞的,我们猜测它可能在I/O完成时(这里的完成 包括从内核拷贝数据到用户)生成一个signal,这是它和信号I/O不同的地方(信号I/O不会拷贝数据到用户)
五种模型的比较:
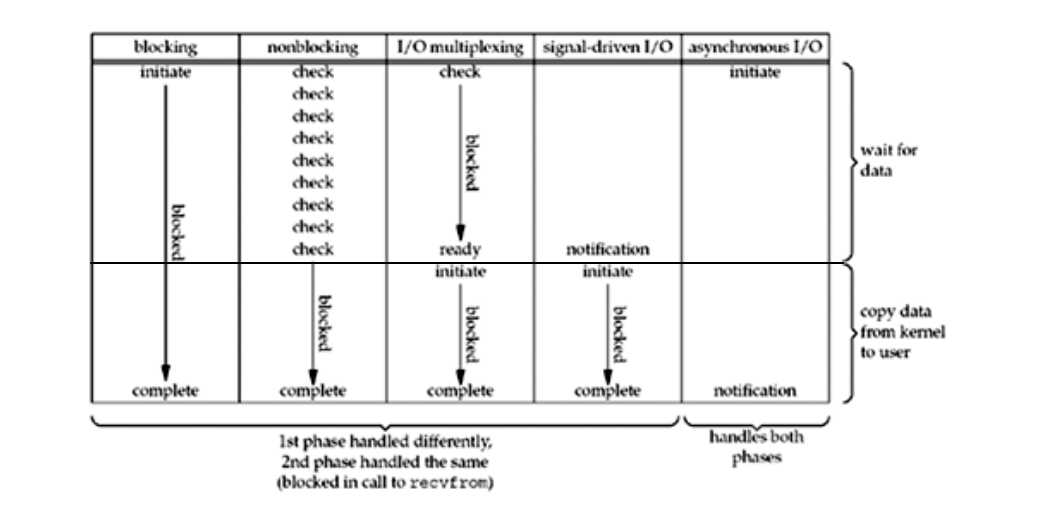
简单来讲,如果把等待数据准备过程比作钓鱼时等待鱼上钩,把从内核拷贝数据到用户空间比作拉线收鱼,那么:
1. 阻塞I/O:守着一个鱼竿一直等待鱼上钩,期间不干别的事情,就等着,鱼上钩了就拉线取走鱼。
2. 非阻塞I/O: 弄个鱼竿搁在那儿,可以干别的事情去,每隔一段时间回来看一次有没有鱼上钩,直到有鱼上钩了,就拉线取走鱼。
3. I/O 多路复用: 一次性弄好多鱼竿钓鱼(select就是可以同时等待多个描述符),这些鱼竿如果有任何一个有鱼上钩,就拉线取走鱼,没有的话就干等着鱼上钩,不干别的事情。
4. 信号I/O: 给一个鱼竿弄个铃铛,然后自己干别的事情去,一旦铃铛响了,说明鱼上钩了,就过来取走鱼。
5. 异步I/O:放个鱼竿钓鱼,然后自己干别的事情去,一旦鱼上钩了,鱼竿比较高级,自动把鱼拉上来放到桶里。
以上是关于63 ALTERNATIVE I/O MODELS的主要内容,如果未能解决你的问题,请参考以下文章