jupyterhub配置安装教程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了jupyterhub配置安装教程相关的知识,希望对你有一定的参考价值。
参考技术A首先你需要一个VMware workstation15和ubuntu 18.04 server
自取:链接:https://pan.baidu.com/s/1JtEF5OdZB2PqJJCd2KaEMQ
提取码:qz2b
VMware15 大家自己查找教程安装应该不难,激活取:链接:https://pan.baidu.com/s/1_TMrFQxjCt52Q-pnVAzOvw
提取码:25bb
复制这段内容后打开百度网盘手机App,操作更方便哦--来自百度网盘超级会员V5的分享
接下来先安装ubuntu18.04参照下面链接:
https://blog.csdn.net/tjsxin/article/details/93199595
好了,到了这里vm15和ubuntu18都可以了,接下来我们来安装nodejs和npm
sudo apt remove --purge nodejs npm # 这一步里有一个[Y/n] 的 一定要Y,不然又老的node.js不会被删除
sudo apt clean
sudo apt autoclean
sudo apt install -f
sudo apt autoremove
sudo apt install curl
curl -sL https://deb.nodesource.com/setup_10.x | sudo -E bash -
sudo apt-get install -y nodejs
curl -sL https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add -
sudo apt-get update && sudo apt-get install yarn
最后两部yarn没成功也不影响我们安装jupyterhub
出现:
npm -version
6.1.0
nodejs -v
v10.7.0
成功!
然后就是安装jupyterhub的git指示安装了:https://github.com/jupyterhub/jupyterhub
我是用pip方式安装的
python3 -m pip install jupyterhub 执行这句的时候可能会出现问题,参考以下链接:
apt-get install python3-pip # no module named pip
https://www.cnblogs.com/Do-n/p/13893611.html # can not import name 'sysconfig'
但是里面要换相应的国内源
sudo apt-get install python3-setuptools # No module named 'setuptools'
# 如果本地运行notebook
If you plan to run notebook servers locally, you will need to install the Jupyter notebook package:
python3 -m pip install --upgrade notebook
# 接下来就大功告成了
To start the Hub server, run the command:
jupyterhub
Visit https://本机ip:8000 in your browser, and sign in with your unix PAM credentials.
当AI遇上K8S:使用Rancher安装机器学习必备工具JupyterHub
Jupyter Notebook是用于科学数据分析的利器,JupyterHub可以在服务器环境下为多个用户托管Jupyter运行环境。本文将详细介绍如何使用Rancher安装JupyterHub来为数据科学和机器学习开发创建可扩展的工作区。
本文来自 Rancher Labs
人工智能(AI)和机器学习(ML)正在成为技术领域的关键差异化因素。从本质上讲,人工智能和机器学习都是计算量巨大的工作负载,它们需要一流的分布式计算环境才能够蓬勃发展。因此,AI和ML为Kubernetes提供了一个完美的用例,他们能够最大化展现Kubernetes可以运行大量工作负载的特点。
什么是JupyterHub?
Jupyter Notebook是用于科学数据分析的利器,JupyterHub可以在服务器环境下为多个用户托管Jupyter运行环境。JupyterHub是一个多用户数据探索工具,通常是数据科学和机器学习研究与开发的关键工具。它为工程师、科学家、研究人员和学生提供了云或数据中心的计算能力,同时仍然像本地开发环境一样易于使用。本质上,JupyterHub使用户可以访问计算环境和资源,而不会给他们增加安装和维护任务的负担。用户可以在工作区中使用共享资源,系统管理员会对其进行有效管理。
在AI/ML工作负载中使用Kubernetes
Kubernetes非常擅长让我们利用大型分布式计算环境。因为其声明式设计和基于发现的服务器寻址方法,所以将计算资源应用于工作负载很容易。通常在AI/ML工作负载中,工程师或研究人员需要分配更多的资源。而Kubernetes让在物理基础架构之间迁移工作负载更加可行。在本文中,我们将展示如何使用Rancher安装JupyterHub。
使用Rancher安装JupyterHub
首先,假设我们在Rancher环境中拥有现代化的Kubernetes部署。在本文发布时,Kubernetes的稳定版本是1.16。对于JupyterHub来说,其中一个前期准备是持久化存储,所以你将需要思考如何在这个集群中提供它。出于演示的目的,我们可以使用Rancher Catalog中包含的实验性NFS提供程序来提供持久化存储。点开App Catalog并选择【启动】。然后搜索NFS提供程序。保留默认设置,然后单击屏幕底部的【启动】。如果你已经有持久化存储的解决方案,也可以直接使用它。

导航到Rancher App Catalog
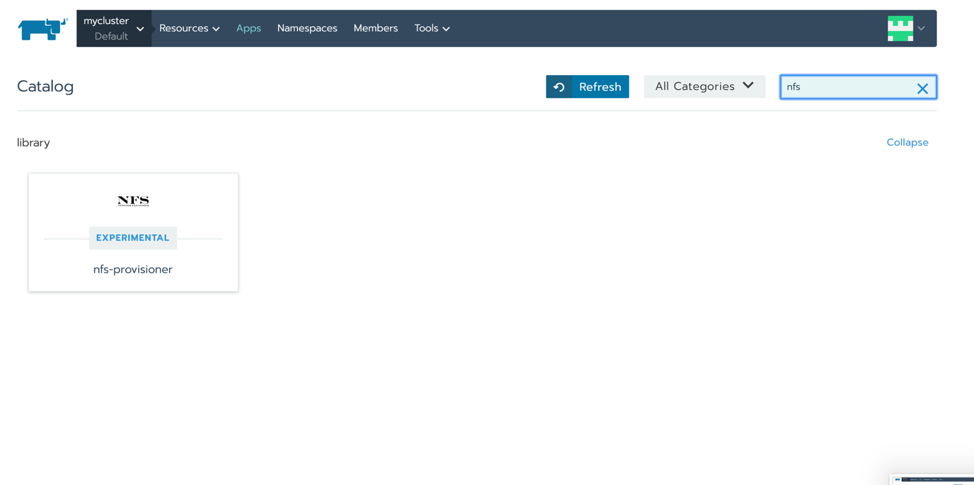
搜索NFS提供程序
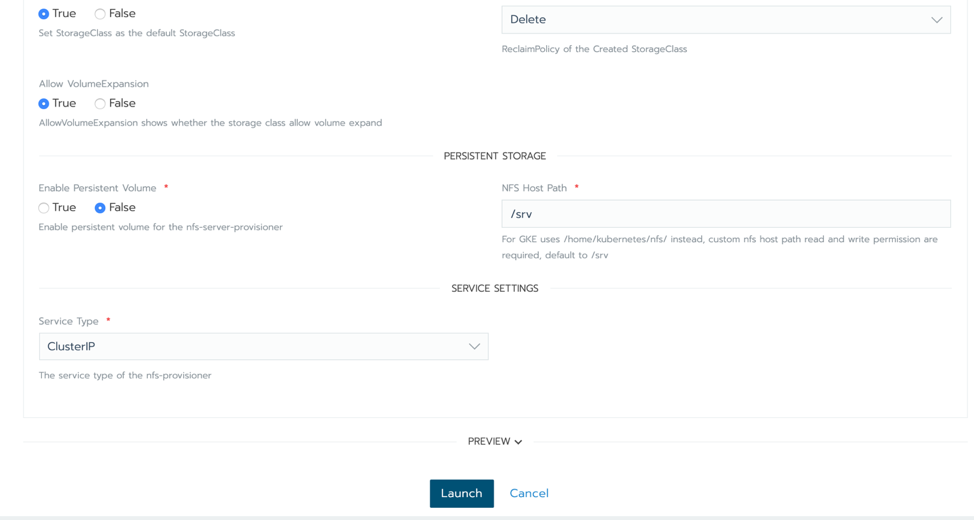
启动NFS提供程序
现在我们已经有了存储提供程序并且定义了默认存储类,我们可以继续部署应用程序组件。我们将使用Helm3来完成这一操作。查看helm官方文档(https://helm.sh/docs/intro/install/ ),在你的电脑上安装helm3客户端。另外,你也可以使用Rancher Catalog来部署helm chart,而无需任何其他工具。需要确保将repo添加到Rancher catalog中。
在我们使用helm之前,我们需要为应用程序创建一个命名空间。在Rancher UI中,进入集群并选择顶端菜单栏的【项目/命名空间】。你可以为JupyterHub创建一个新的命名空间。例如,我们将命名空间称为“jhub“。请注意此名称,因为我们将之后会使用。
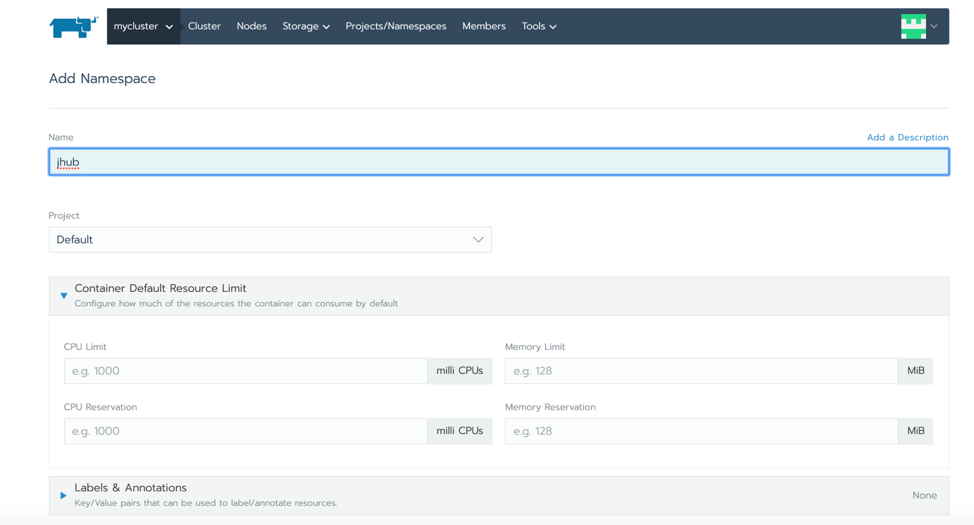
创建一个命名空间
接下来,我们可以为将要使用的JupyterHub Chart添加Helm repo。如果使用的是Rancher catalog,你需要在UI上完成此操作而不是Helm CLI:
helm repo add jupyterhub https://jupyterhub.github.io/helm-chart/
helm repo update
然后,让我们创建一个config文件,其中包含了我们要与此chart一起使用的设置。我们将该文件命名为config.yaml:
proxy:
secretToken: "<secret token>"
ingress:
enabled: true
hosts:
- <host name>
让我们替换几个项目,使它们是唯一的。用以下输出替换secretToken:
openssl rand -hex 32
并替换为你打算用来访问JyupiterHub UI的可解析DNS名称。
有了配置文件之后,就可以安装chart了。我们将引用该配置文件,因此请确保该文件存在你当前的工作目录中:
RELEASE=jhub
NAMESPACE=jhub
helm upgrade --install $RELEASE jupyterhub/jupyterhub --namespace $NAMESPACE --version=0.8.2 --values config.yaml
Helm现在应该部署所需的组件。这将需要一些时间,但是最终你应该能够通过之前设置的主机名访问UI。你也可以通过转到Rancher UI中的“工作负载“选项卡来检查状态。当我们尝试在浏览器中设置的主机名时,它将显示以下登录界面:
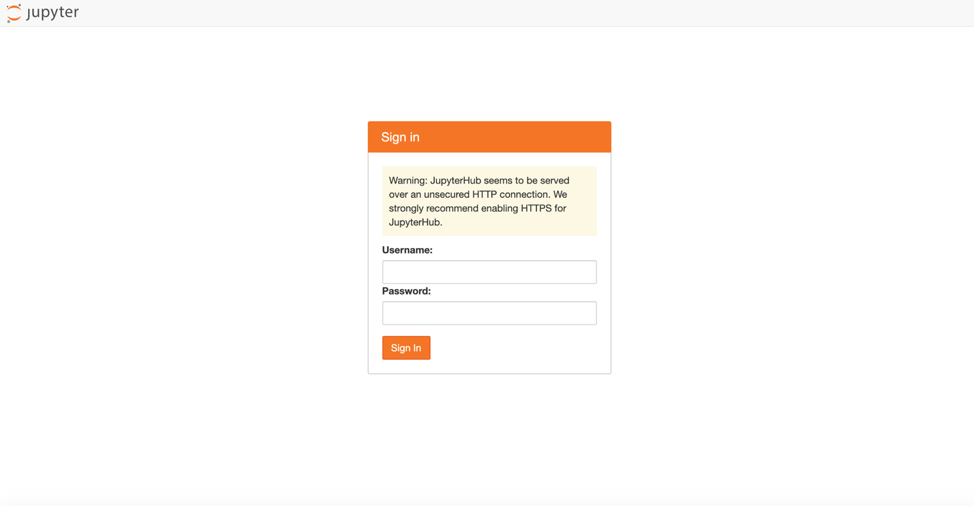
主机名登录界面
在撰写本文时,有一个issue是Kubernetes 1.16中的更改导致Jyupiter Hub的代码在尝试与Kuberentes API交互时中断。如果要立即修复,我们可以运行以下patch命令:
kubectl patch deploy -n $NAMESPACE hub --type json --patch ‘[{"op": "replace", "path": "/spec/template/spec/containers/0/command", "value": ["bash", "-c", "
mkdir -p ~/hotfix
cp -r /usr/local/lib/python3.6/dist-packages/kubespawner ~/hotfix
ls -R ~/hotfix
patch ~/hotfix/kubespawner/spawner.py << EOT
72c72
< key=lambda x: x.last_timestamp,
---
> key=lambda x: x.last_timestamp and x.last_timestamp.timestamp() or 0.,
EOT
PYTHONPATH=$HOME/hotfix jupyterhub --config /srv/jupyterhub_config.py --upgrade-db
"]}]‘
你现在已经在Rancher上部署了可以正常工作的JupyterHub环境。默认情况下,JupyterHub使用PAM身份验证。因此,可以使用系统上的任何有效Linux用户登录。登录后,我们应该能够创建新的notebook:
Jupyter登录界面
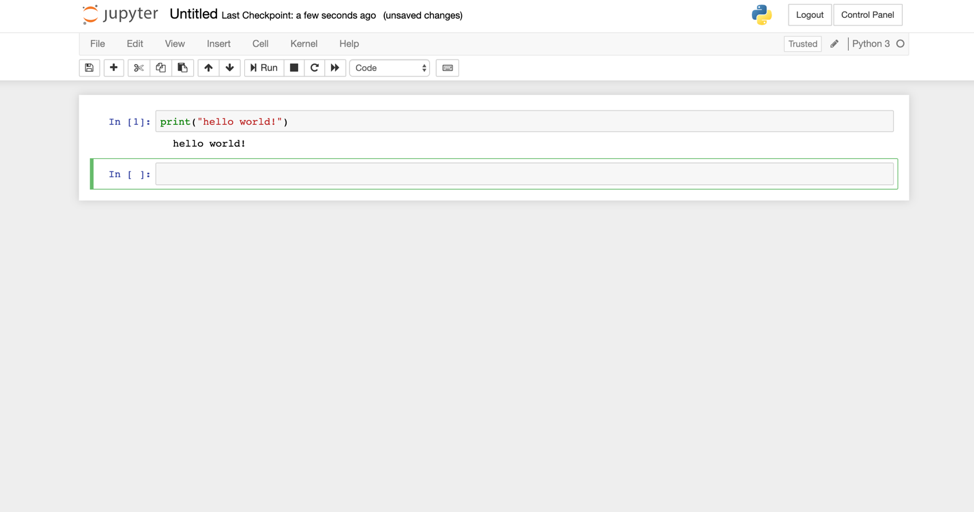
创建新的notebook
另外,你可以查看其他你可能想配置的身份验证选项。例如,你可以使用Github身份验证来允许用户登录并且创建基于他们Github ID的notebook。你选择好一个身份验证的工具之后,需要按照说明更新我们之前创建的config.yml文件,然后重新运行helm upgrade命令。
总 结
在本文中,我们展示了如何使用Rancher安装JupyterHub来为数据科学和机器学习开发创建可扩展的工作区。如果你想要安装功能齐全的JupyterHub安装,你可能还需要考虑其他因素。本文只是向你展示了如何快速搭建一个基础功能的JupyterHub,希望能帮助你快速开启AI旅程!
以上是关于jupyterhub配置安装教程的主要内容,如果未能解决你的问题,请参考以下文章