MySQL集群:双主模式
Posted 零点冰.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL集群:双主模式相关的知识,希望对你有一定的参考价值。
目录
2.2、在主库master1配置slave访问master1的用户的ip权限
2.4、在主库master2配置slave访问master2的用户的ip权限
2.5、在主库master1配置master2的关联关系
1、双主模式
两台服务器互为主从,任何一台服务器数据变更,都会通过复制应用到另外一方的数据库中。
可解决因主库故障导致的服务不可用情况。
可分为双主单写(推荐)和双主双写模式,双主双写模式会存在如下问题:
- ID冲突
在A主库写入,当A数据未同步到B主库时,对B主库写入,如果采用自动递增容易发生ID主键的冲突。可以采用mysql自身的自动增长步长来解决,例如A的主键为1,3,5,7...,B的主键为2,4,6,8... ,但是对数据库运维、扩展都不友好。
- 更新丢失
同一条记录在两个主库中进行更新,会发生前面覆盖后面的更新丢失。
1.1、高可用架构
一个Master提供线上服务,另一个Master作为备胎供高可用切换,Master下游挂载Slave承担读请求。
通过引入高可用组件(MMM、Keepalived),实现主库故障的自动切换。
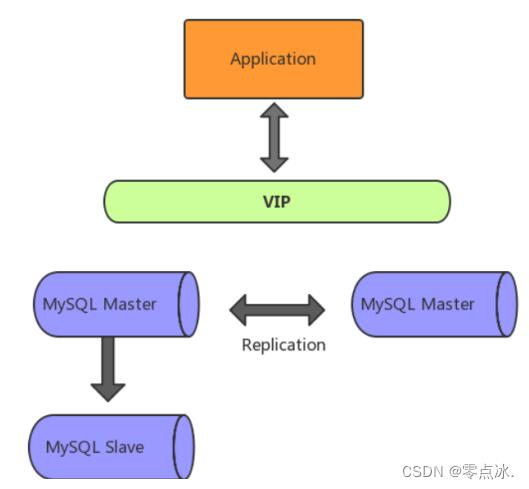
1.2、MMM架构(基于双主模式)
MMM(Master-Master Replication Manager for MySQL)是一套用来管理和监控双主复制,支持双主故障切换的第三方软件。同一时间只允许一个节点进行写入操作。

1.2.1、MMM故障处理机制
MMM 包含writer和reader两类角色,分别对应写节点和读节点。
- 当 writer节点出现故障,程序会自动移除该节点上的VIP(虚拟IP)
- 写操作切换到 Master2,并将Master2设置为writer
- 将所有Slave节点会指向Master2
除了管理双主节点,MMM 也会管理 Slave 节点,在出现宕机、复制延迟或复制错误,MMM 会移除该节点的 VIP,直到节点恢复正常。
1.2.2、MMM监控机制
MMM 包含monitor和agent两类程序,功能如下:
- monitor:监控集群内数据库的状态,在出现异常时发布切换命令,一般和数据库分开部署。
- agent:运行在每个 MySQL 服务器上的代理进程,monitor 命令的执行者,完成监控的探针工作和具体服务设置,例如设置 VIP(虚拟IP)、指向新同步节点
1.3、MHA架构(基于主从模式)
MHA(Master High Availability)是一套比较成熟的 MySQL 高可用方案,也是一款优秀的故障切换和主从提升的高可用软件。
在MySQL故障切换过程中,MHA能做到在30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。MHA还支持在线快速将Master切换到其他主机,通常只需0.5-2秒。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器。
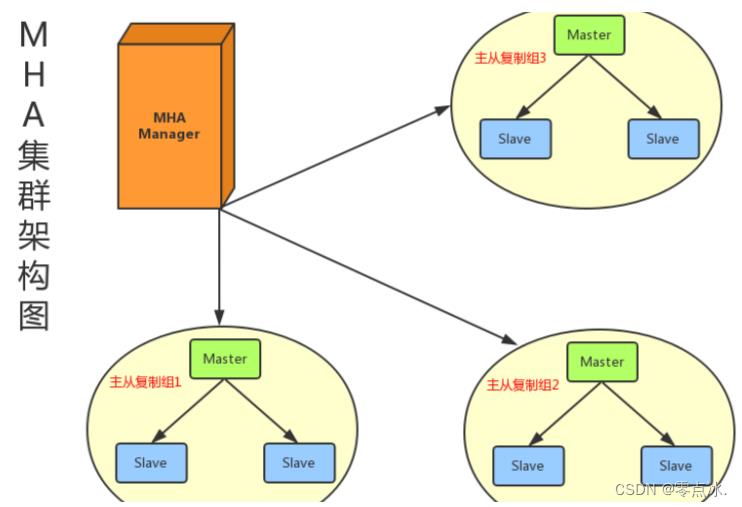
MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。
- MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。负责检测master是否宕机、控制故障转移、检查MySQL复制状况等。
- MHA Node运行在每台MySQL服务器上,不管是Master角色,还是Slave角色,都称为Node,是被监控管理的对象节点,负责保存和复制master的二进制日志、识别差异的中继日志事件并将其差异的事件应用于其他的slave、清除中继日志。
MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master,整个故障转移过程对应用程序完全透明。
1.3.1、MHA故障处理机制
- 把宕机master的binlog保存下来
- 根据binlog位置点找到最新的slave
- 用最新slave的relay log修复其它slave
- 将保存下来的binlog在最新的slave上恢复
- 将最新的slave提升为master
- 将其它slave重新指向新提升的master,并开启主从复制
1.3.2、MHA优点
- 自动故障转移快
- 主库崩溃不存在数据一致性问题
- 性能优秀,支持半同步复制和异步复制
- 一个Manager监控节点可以监控多个集群
1.4、主备切换
将主库变为从库,将从库变为主库。分为可靠性优先和可用性优先,主备切换时存在延迟问题。
1.4.1、主备延迟问题
主备同步流程分为如下三个步骤:
- 主库 A 执行完成一个事务,写入 binlog,我们把这个时刻记为 T1;
- 主库A将binlog传给备库B,我们把备库B接收完 binlog 的时刻记为 T2;
- 备库 B 执行完成这个binlog复制,我们把这个时刻记为 T3。
主备延迟,就是同一个事务,在备库执行完成的时间和主库执行完成的时间之间的差值,也就是 T3-T1。
在备库上执行show slave status命令,它可以返回结果信息,seconds_behind_master表示当前备库延迟了多少秒。
同步延迟主要原因如下:
- 备库机器性能问题
机器性能差,甚至一台机器充当多个主库的备库。
- 分工问题
备库提供了读操作,或者执行一些后台分析处理的操作,消耗大量的CPU资源。
- 大事务操作
大事务耗费的时间比较长,导致主备复制时间长。比如一些大量数据的delete或大表DDL操作都可能会引发大事务
1.4.2、可靠性优先
主备切换过程一般由专门的HA高可用组件完成,但是切换过程中会存在短时间不可用,因为在切换过程中某一时刻主库A和从库B都处于只读状态。

- 判断从库B的Seconds_Behind_Master值,当小于某个值才继续下一步
- 把主库A改为只读状态(readonly=true)
- 等待从库B的Seconds_Behind_Master值降为 0
- 把从库B改为可读写状态(readonly=false)
- 把业务请求切换至从库B
1.4.3、可用性优先
不等主从同步完成, 直接把业务请求切换至从库B ,并且让 从库B可读写 ,这样几乎不存在不可用时间,但可能会数据不一致。
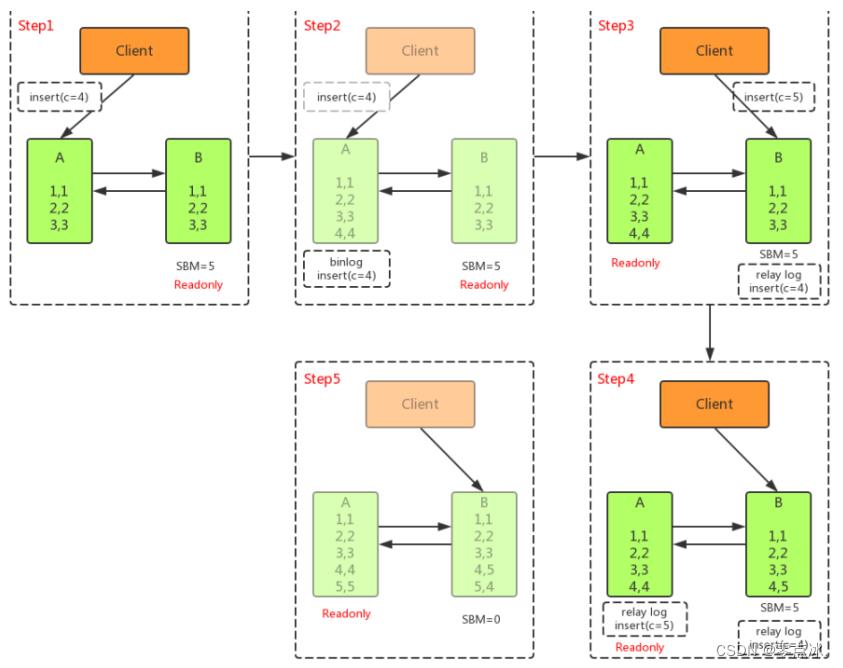
- 主库A执行完 INSERT c=4 ,得到 (4,4) ,然后开始执行 主从切换
- 主从之间有5S的同步延迟,从库B会先执行 INSERT c=5 ,得到 (4,5)
- 从库B执行主库A传过来的binlog日志 INSERT c=4 ,得到 (5,4)
- 主库A执行从库B传过来的binlog日志 INSERT c=5 ,得到 (5,5)
- 此时主库A和从库B会有 两行 不一致的数据
2、双主模式实战
2.1、修改master1的my.ini配置文件
Log_bin=mysql-bin #开启bin log日志功能
Server-id=1 #设置server-id
Sync-binlog=1
Binlog-ignore-db=information_schema #指定需要同步的数据
Binlog-ignore-db=performation_schema
Binlog-ignore-db=sys
Relay_log=mysql-relay-bin #开启relay log配置
Log_slave_updates=1 #在master做了更新操作是否将修改写入binlog
Auto_increment_offset=1 #双主双写时配置,配置主键自增开始值
Auto_increment_increment=2 #双主双写时配置,配置主键自增步长2.2、在主库master1配置slave访问master1的用户的ip权限
grant replication slave on *.* to '用户名'@'%' identified by '密码';
grant all privileges on *.* to '用户名'@'%' identified by '密码';
show master status;
2.3、修改master2的my.ini配置文件
Log_bin=mysql-bin #开启bin log日志功能
Server-id=3 #设置server-id
Sync-binlog=1
Binlog-ignore-db=information_schema #指定需要同步的数据
Binlog-ignore-db=performation_schema
Binlog-ignore-db=sys
Relay_log=mysql-relay-bin #开启relay log配置
Log_slave_updates=1 #在master做了更新操作是否将修改写入binlog
Auto_increment_offset=2 #双主双写时配置,配置主键自增开始值
Auto_increment_increment=2 #双主双写时配置,配置主键自增步长2.4、在主库master2配置slave访问master2的用户的ip权限
grant replication slave on *.* to '用户名'@'%' identified by '密码';
grant all privileges on *.* to '用户名'@'%' identified by '密码';
show master status;
2.5、在主库master1配置master2的关联关系
change master to master_host='master2 IP', master_port=3306, master_user='root', master_password='root', master_log_file='master2 bin log文件名',master_log_pos=1072.6、在主库master2配置master1的关联关系
change master to master_host='master1 IP', master_port=3306, master_user='root', master_password='root', master_log_file='master1 bin log文件名',master_log_pos=107以上内容为个人学习理解,如有问题,欢迎在评论区指出。
部分内容截取自网络,如有侵权,联系作者删除。
通过Keepalived搭建MYSQL双主模式的高可用集群系统
通过Keepalived搭建MYSQL双主模式的高可用集群系统
一.MYSQL replication介绍:
MYSQL replication是MYSQL自身提供的一个主从复制功能,就是一台MYSQL服务器(slave)从另外一台MYSQL服务器(master)上复制日志,然后解析日志应用到自身的过程。MYSQL replication是单向、异步复制。
MYSQL replication支持链式复制,也就是说slave服务器下还可以再链接slave服务器,同时slave服务器也可以充当master的角色。在MYSQL主从复制中,所有表的更新必须在master服务器上运行,slave服务器仅能提供查询操作。
优点:
1,增加了MYSQL应用的健壮性,如果master服务器出现问题,可以随时切换到slave服务器,继续提供服务
2,可以将MYSQL读写分离,写操作只在master服务器完成,读操作可在多个slave服务器上完成,由于master服务器和slave服务器是保持数据同步的,因此不会对前端业务系统产生影响。同时,通过读写分离,可以大大降低MYSQL的运行负荷。
3,在网络环境良好,业务量不大的环境中,slave服务器同步数据很快,基本可以实现实时同步,并且,slave服务器在同步过程中不会干扰master服务器。
MYSQL replication支持多种类型的复制方式,常见的有基于语句的复制,基于行的复制和混合类型的复制。
1,基于语句的复制:
MYSQL默认采用基于语句的复制,效率很高。基本方式是:在master服务器上执行的SQL语句,在slave服务器上再次执行同样的语句。而一旦发现没法精确复制时,会自动选择基于行的复制
2,基于行的复制:
基本方式为:把master服务器上改变的内容复制过去,而不是把SQL语句在从服务器执行一遍
3,混合类型的复制:
是基于以上两种类型发组合,默认采用基于语句的复制,如果发现基于语句的复制无法精确完成,就会采用基于行的复制
二.MYSQL replication实现原理:
MYSQL replication是一个从master复制到一台或多台slave的异步过程,在master与slave之间实现整个复制过程主要由三个线程来完成,其中一个IO线程在master端,另两个线程(sql线程和io线程)在slave端
要实现MYSQL replication,首先在master服务器上打开MYSQL的Binary log(产生二进制日志文件)功能,因为整个复制过程实际上就是slave从master端获取该日志,然后在自身上将二进制文件解析为SQL语句并完全顺序地执行SQL语句所记录的各种操作。
详解:
1,首先slave上的IO线程连接上master,然后请求从指定日志文件的指定位置或者从最开始的日志位置之后的日志内容
2,master在接收到来自slave的IO线程请求后,通过自身的IO线程,根据请求信息读取指定日志位置之后的日志信息,并返回给slave端的IO线程,返回信息中除了日志所包含的信息之外,还包括此次返回的信息在master端对应的binary log文件的名称和binary log中的位置
3,slave的IO线程接收到信息后,将获取到的日志内容一次写入slave端的relay log文件(类似mysql-relay-bin.xxxxx)的最后,并且将读取到的master端的binary log的文件名和位置记录到一个名为master-info的文件中,以便在下一次读取的时候能够迅速定位开始往后读取日志信息的位置
4,slave的SQL线程在检测到relay log文件中新增加了内容后,会马上解析该relay log文件中的内容,将日志内容解析为sql语句,然后在自身执行这些sql,由于是在master和slave端执行了同样的sql操作,所以两端的数据是完全一样的,至此,整个复制过程结束。
本文出自 “高好亮” 博客,转载请与作者联系!
以上是关于MySQL集群:双主模式的主要内容,如果未能解决你的问题,请参考以下文章
Mysql5.7.22+Keepalived双主互备高可用集群