业务数据LEFT JOIN 多表查询慢--优化操作
Posted 神族依恋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了业务数据LEFT JOIN 多表查询慢--优化操作相关的知识,希望对你有一定的参考价值。
首先你会想到,给表加索引,那么mysql会给主键自动建立索引吗?
会的,当然会。
在我们查询的业务表操作的时候,表业务数据庞大起来的时候,以及left join多的时候,甚至多表关联到几十张表的时候,查询是慢到不行。
这时候,只需要给表join查询的字段,及表结构,进行索引优化,即可解决这个慢的问题。
一,首先利用explain 关键字对查询的SQL进行分析。

type=ALL,全表扫描,MySQL遍历全表来找到匹配行
type=index,索引全扫描,MySQL遍历整个索引来查询匹配行,并不会扫描表
type=range,索引范围扫描,常用于<、<=、>、>=、between等操作
type=ref,使用非唯一索引或唯一索引的前缀扫描,返回匹配某个单独值的记录行
type=eq_ref,类似ref,区别在于使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配
type=const/system,单表中最多有一条匹配行,查询起来非常迅速,所以这个匹配行的其他列的值可以被优化器在当前查询中当作常量来处理
type=NULL,MySQL不用访问表或者索引,直接就能够得到结果
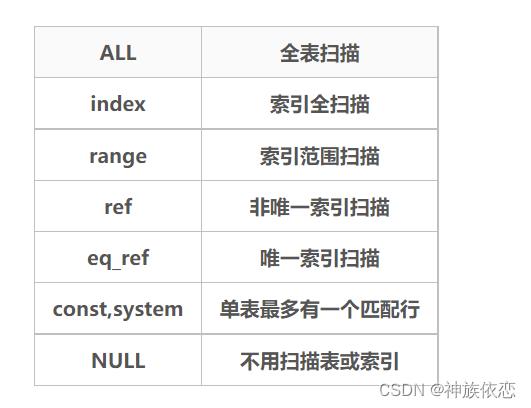
all < index < range < index_subquery < unique_subquery < index_merge < ref_or_null < ref < eq_ref < const < system
*** 重点来了,为表添加索引,如果发现分析出来的表type 为all ,我们首先想到这个表没加索引,我们给他加上 ***
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引
mysql引擎放弃使用索引而进行全表扫描的几种情况:
应尽量避免在 where 子句中对字段进行 null 值判断,可以设置默认值0
应尽量避免在 where 子句中使用!=或<>操作符
应尽量避免在 where 子句中使用or 来连接条件,in 和 not in 也要慎用
模糊查询select id from t where name like ‘%李%’也会全表扫描,若要提高效率,可以考虑全文检索
------------------添加完后--大功告成----------------------
MySQL目前主要有以下几种索引类型:
1.普通索引2.唯一索引3.主键索引4.组合索引5.全文索引
mysql Hash索引和BTree索引区别
一、BTree
BTree索引是最常用的mysql数据库索引算法,因为它不仅可以被用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操作符,只要它的查询条件是一个不以通配符开头的常量,例如:
select * from user where name like ‘jack%’;
select * from user where name like ‘jac%k%’;
如果一通配符开头,或者没有使用常量,则不会使用索引,例如:
select * from user where name like ‘%jack’;
select * from user where name like simply_name;
一、Hash
- hash索引查找数据基本上能一次定位数据,当然有大量碰撞的话性能也会下降。而btree索引就得在节点上挨着查找了,很明显在数据精确查找方面hash索引的效率是要高于btree的;
- 那么不精确查找呢,也很明显,因为hash算法是基于等值计算的,所以对于“like”等范围查找hash索引无效,不支持;
- 对于btree支持的联合索引的最优前缀,hash也是无法支持的,联合索引中的字段要么全用要么全不用。提起最优前缀居然都泛起迷糊了,看来有时候放空得太厉害;
- hash不支持索引排序,索引值和计算出来的hash值大小并不一定一致。
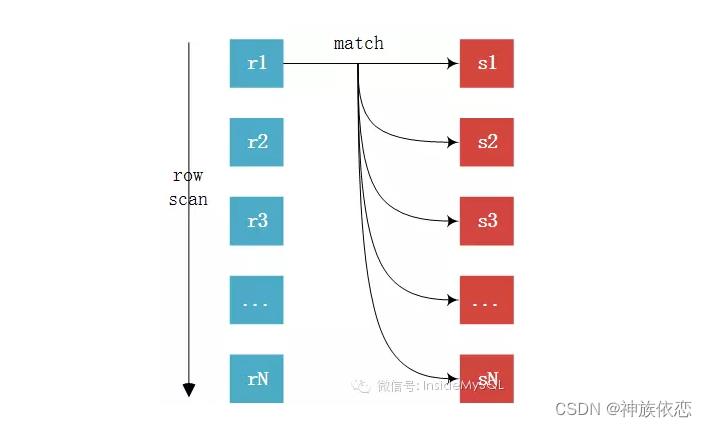
MySQL是只支持一种JOIN算法Nested-Loop Join(嵌套循环链接) —
没有索引时会走,Block Nested-Loop Join比Simple Nested-Loop Join多了一个中间join buffer缓冲处理的过程
没有索引时:
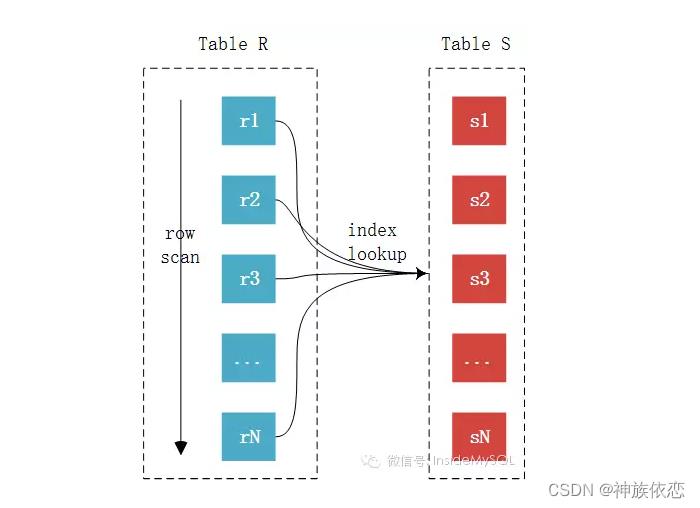
当关联字段有索引时,走的是Index Nested-Loop Join(索引嵌套链接) —
有索引时;
Mysql left join with nested select慢,如何优化
【中文标题】Mysql left join with nested select慢,如何优化【英文标题】:Mysql left join with nested select slow, how to optimize 【发布时间】:2021-08-01 00:47:50 【问题描述】:我有一个执行速度很慢的 LEFT JOIN mysql 查询,我正在寻找改进。 我有一个表“VM”列出了“VmId”(+ 一些其他数据)和另一个表“VM_Status”列出了 VM 的状态(上/下),每一行都有一个“inputDate”。
表 VM 为 7.000 行,表 VM_Status 为 76.000 行
我需要选择 7.000 VM 的最新状态
我的查询如下,执行需要 25 秒:
SELECT
VM.*,
`VM_Status`.`Status` AS `Status`
FROM VM
left join (
select
*
from
`VM_Status` `s1`
where
(
`s1`.`InputDate` = (
select
max(`s2`.`InputDate`)
from
`VM_Status` `s2`
where
(`s1`.`VmId` = `s2`.`VmId`)
)
)
) `VM_Status` on(
(
`VM_Status`.`VmId` = `WORKLOAD`.`VmId`
)
)
我怎样才能更快地做到这一点?
【问题讨论】:
查看添加的标签。 【参考方案1】:您可以使用窗口函数。Window Functions in MySQL
MySQL 支持窗口函数,对于查询中的每一行,使用与该行相关的行执行计算。
在您的情况下,您可以使用带有 order by 子句的 RANK() 或 DENSE_RANK() 函数,并在窗口内获取该 MAX(避免慢速连接)。 见:RANK
类似的东西:
select
*
from (
SELECT
VM.*,
`VM_Status`.`Status` AS `Status`,
RANK() OVER(PARTITION BY `VM_Status`.`VmId` ORDER BY `VM_Status`.`InputDate` DESC) rank
FROM VM left join `VM_Status`
ON `VM_Status`.`VmId` = `VM`.`VmId`
) `last_status`
WHERE
rank = 1
【讨论】:
谢谢,我不知道 RANK()。但是我在 5.7 版上,我的东西 RANK() 仅在 8 上可用。我尝试了一个替代方案,但它从 1 级到 78.000 级返回了 78.000 行......我错过了什么? select * from ( SELECT VM.VmId, VM_Status.Status AS Status, @curRank := @curRank + 1 AS Rank FROM (SELECT @curRank := 0) r, VM 离开加入 VM_Status ON VM_Status.VmId = VM .VmId ORDER BY VM_Status.InputDate DESC ) last_status ORDER BY Rank以上是关于业务数据LEFT JOIN 多表查询慢--优化操作的主要内容,如果未能解决你的问题,请参考以下文章