ES笔记02ElasticSearch数据库之查询操作(matchmustmust_notshould_sourcefilterrangeexistsidstermterms)
Posted 朱友斌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ES笔记02ElasticSearch数据库之查询操作(matchmustmust_notshould_sourcefilterrangeexistsidstermterms)相关的知识,希望对你有一定的参考价值。
这篇文章,主要介绍ElasticSearch数据库之查询操作(match、must、must_not、should、_source、filter、range、exists、ids、term、terms)。
目录
一、布尔查询
1.1、主键查询
# 主键查询
GET /索引名称/_doc/doc文档的id
# 测试案例
GET /idx_20221124/_doc/2022001这种查询方式,每一次只能够查询一条doc文档,如果要查询很多doc文档,那么就需要通过【_search】命令。
1.2、两种查询方式
(1)路径参数查询
将查询条件放在请求路径后面,查询条件使用【q=字段名称:字段值】这种格式,如下所示:
# 单个查询条件
# 查询age字段等于20的doc文档
GET /idx_20221124/_search?q=age:20(2)请求体参数查询
当查询条件有很多个的时候,如果将所有的查询条件都放在请求路径上面,显然不合适,所以ES可以将查询条件放到请求体里面,请求体里面的查询条件需要按照指定的格式,不然ES会解析报错。
#
# 查询
GET /idx_20221124/_search
"query":
"指定查询类型":
"查询字段": "查询值"
# 查询
GET /idx_20221124/_search
"query":
"match":
"age": 20
1.3、match查询
match关键字,相当于mysql数据库中的like查询,match查询的字段如果是text类型,那么text会被分词,match就会匹配分词,查询所有包含分词的doc文档,如果不是text类型的,那就是精确查询。
match有多种形式,如下所示:
- match:查询指定条件的数据,match会将查询的条件进行分词操作,然后只有doc文档中包含分词,就都会查询出来。
- match_all:查询所有数据。
- match_phrase:匹配短语,match是会查询所有包含分词的doc文档,而match_phrase则是匹配整个短语,才会返回对应的doc文档。
- match_phrase_prefix:匹配短语的前缀部分,这个只能使用在text类型字段。
(1)match
# 查询所有数据
# 查询age等于20的doc文档
GET /idx_20221124/_search
"query":
"match":
"age": 20
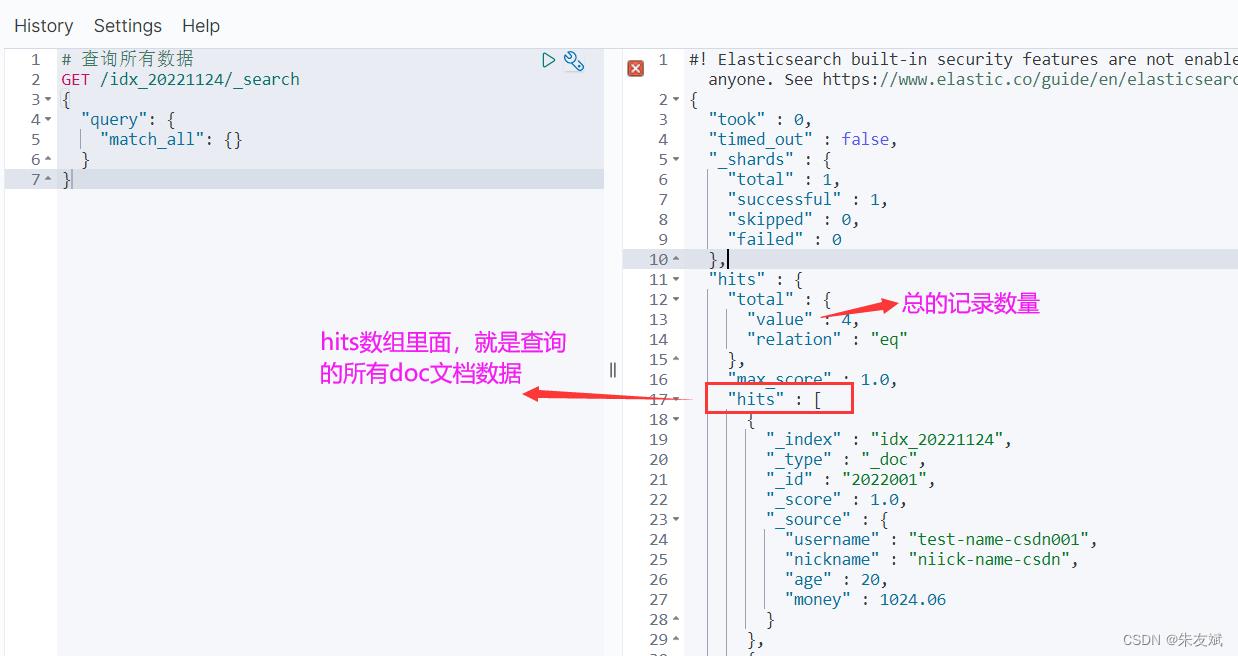
(2)match_all
match_all表示查询所有的数据,默认是10条,因为ES默认分页是10条数据,这个关键字不能写查询条件。
# 查询所有数据
GET /idx_20221124/_search
"query":
"match_all":
执行结果:
1.4、过滤字段
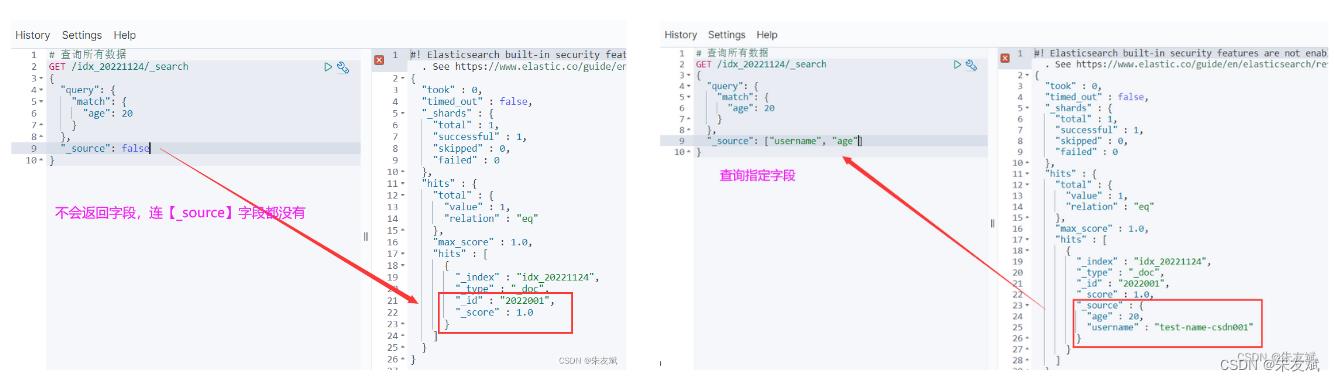
ES查询时候,默认情况下,会将doc文档中的所有字段都返回,如果查询时候不想查询某个字段,那么可以使用【_source】属性设置查询哪些字段。【_source】就相当于mysql数据库中的【select 字段1,字段2】形式。
【_source】过滤字段:
- 第一种:_source=false,表示所有字段都不返回。
- 第二种:_source: ["username", "age"],只返回指定的字段。
案例代码:
# 查询数据,不返回字段
GET /idx_20221124/_search
"query":
"match":
"age": 20
,
"_source": false
# 查询数据,返回指定字段
GET /idx_20221124/_search
"query":
"match":
"age": 20
,
"_source": ["username", "age"]
执行结果:
1.5、布尔查询(must)
条件查询,和mysql数据库中的条件查询是类似的,只不过ES中使用JSON的方式来组织查询条件,条件查询基本格式如下所示:
# 条件查询数据
GET /索引名称/_search
"query":
"bool":
"条件类型": [
条件1,
条件2
]
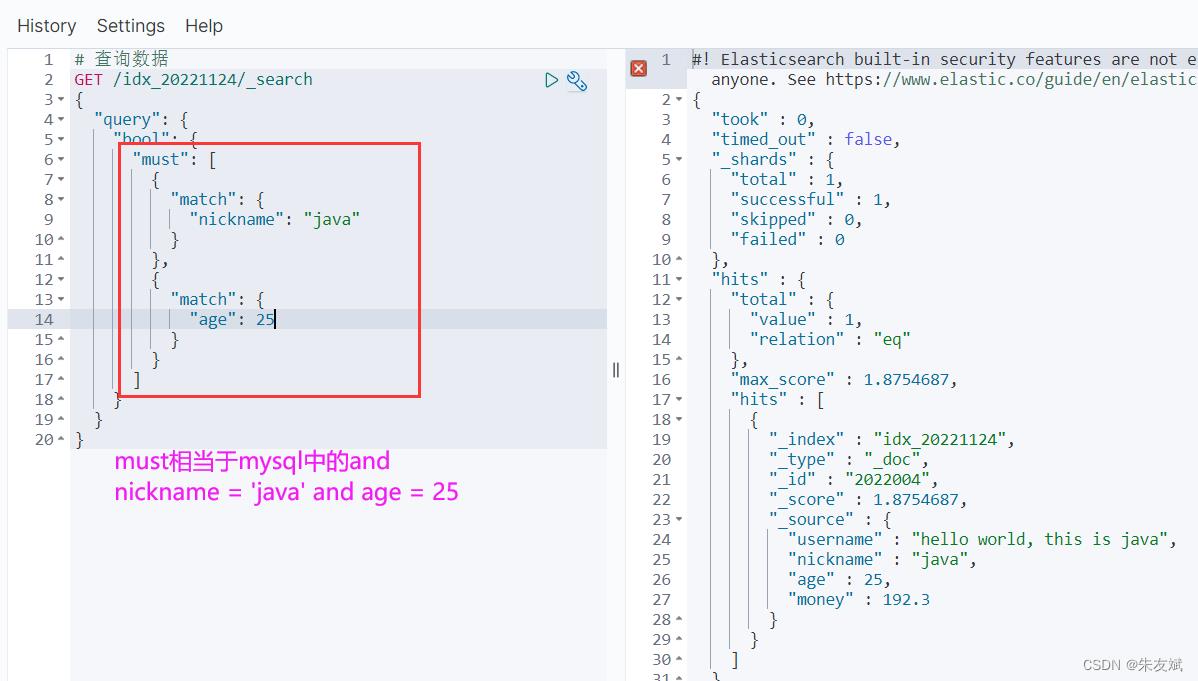
条件查询中的【must】和mysql数据库中的【and】是相同作用,【must】接收一个数组,数组中的所有条件都成立,这个时候才会查询对应数据。
# 查询数据
GET /idx_20221124/_search
"query":
"bool":
"must": [
"match":
"nickname": "java"
,
"match":
"age": 25
]
执行结果:
1.6、布尔查询(should)
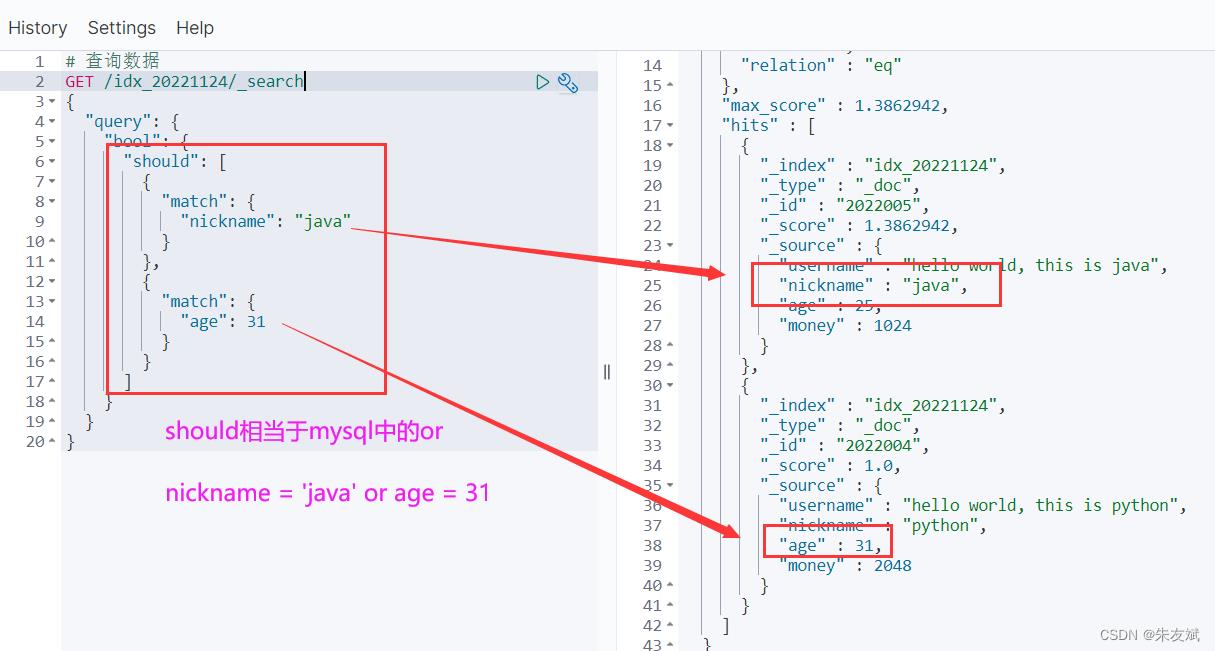
既然有and运算,那当然少不了or运算,ES中使用【should】表示或运算,相当于mysql数据库中的【or】连接符。
# 查询数据
GET /idx_20221124/_search
"query":
"bool":
"should": [
"match":
"nickname": "java"
,
"match":
"age": 31
]
执行结果:
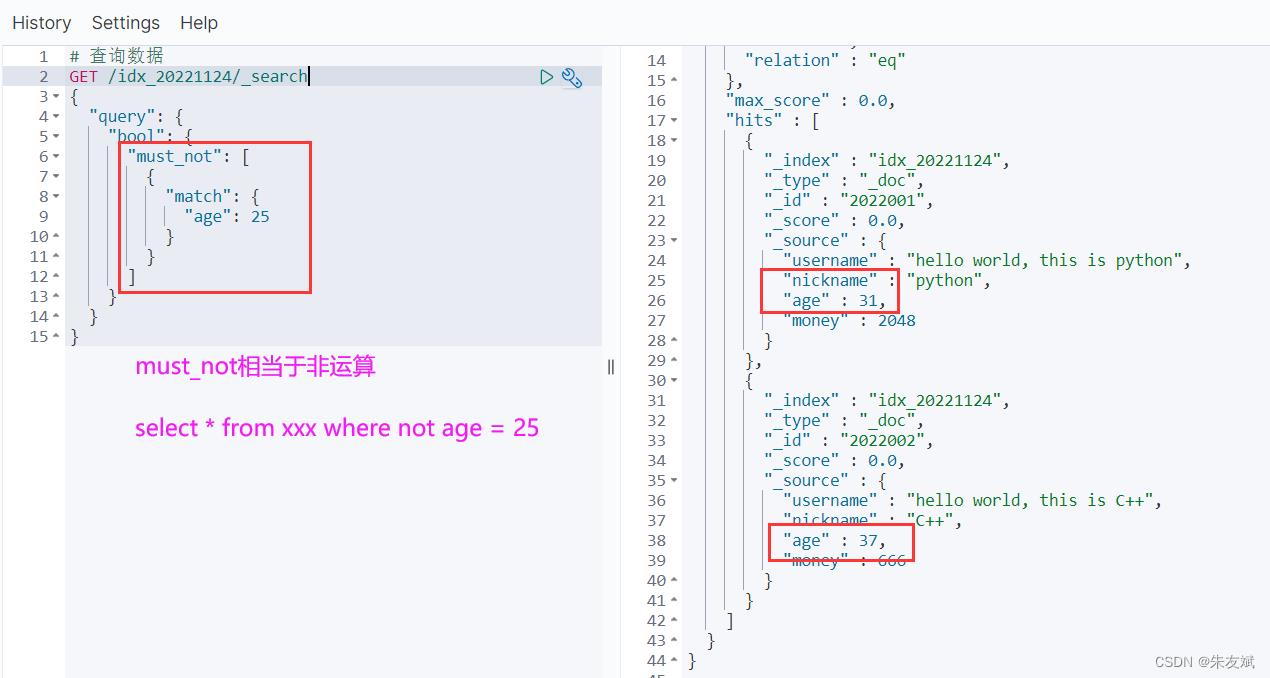
1.7、布尔查询(must_not)
must_not是非运算,相当于mysql数据库中的【!】非运算,即:【not】。
# 查询数据
# 查询年龄不是25的所有doc文档
GET /idx_20221124/_search
"query":
"bool":
"must_not": [
"match":
"age": 25
]
执行结果:
二、filter过滤查询
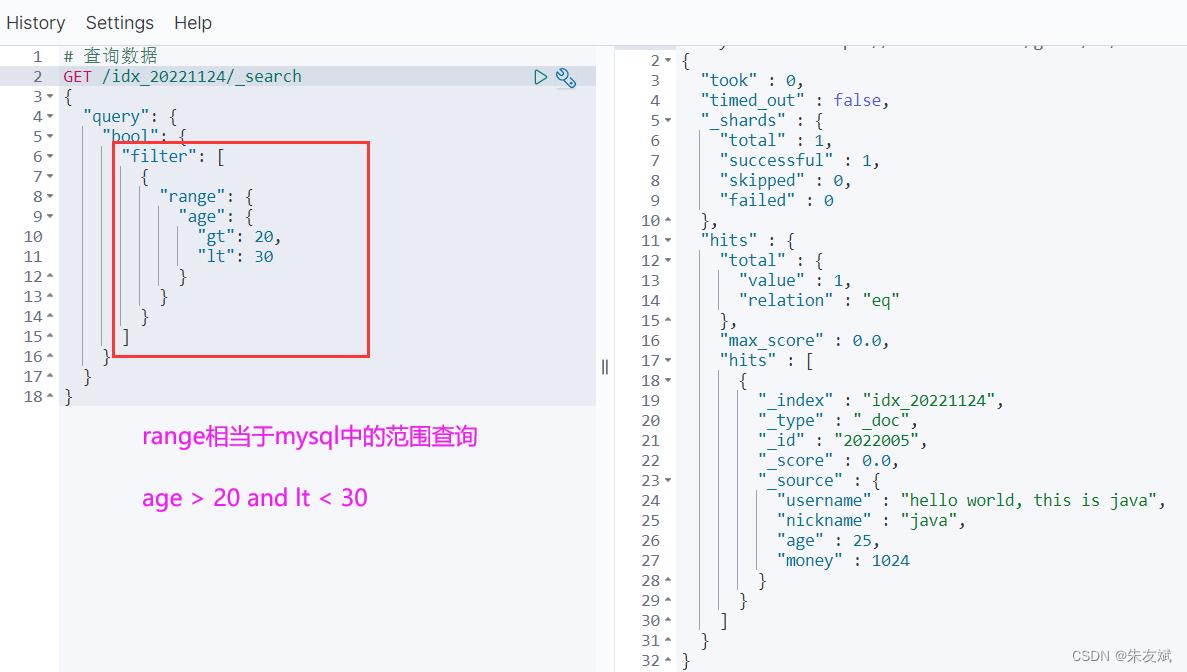
2.1、range范围查询
filter是用于过滤查询的关键字,在filter里面可以使用多种查询条件,例如:range、term、terms、exists、ids几种常见的查询,这里先介绍range范围查询,范围查询首先需要指定范围,下面是几个常见的范围关键字。
range范围关键字:
- gt:大于。
- lt:小于。
- gte:大于等于。
- lte:小于等于。
- eq:等于。
- ne:不等于。
range范围查询的语句格式:
# 查询数据
GET /索引名称/_search
"query":
"bool":
"filter": [
"range":
"指定字段":
"条件": 范围值,
"条件": 范围值
]
具体案例代码:
# 查询数据
GET /idx_20221124/_search
"query":
"bool":
"filter": [
"range":
"age":
"gt": 20,
"lt": 30
]
执行结果:
2.2、exists是否存在
exists关键字,是表示指定的字段的值是否存在,类似于mysql数据库中的【is null】,但是ES中exists用在filter里面时候,表示过滤掉不存在指定字段的doc文档。
# 查询数据
# 过滤nickname不存在的doc文档数据
GET /idx_20221124/_search
"query":
"bool":
"filter": [
"exists":
"field": "nickname"
]
运行上面语句之后,会返回所有doc文档中,nickname字段不存在的doc文档结果。
注意:exists会返回指定字段存在的doc文档,只有当字段等于null,即:不存在时候才会匹配成功,如果字段等于空字符串不会匹配成功。
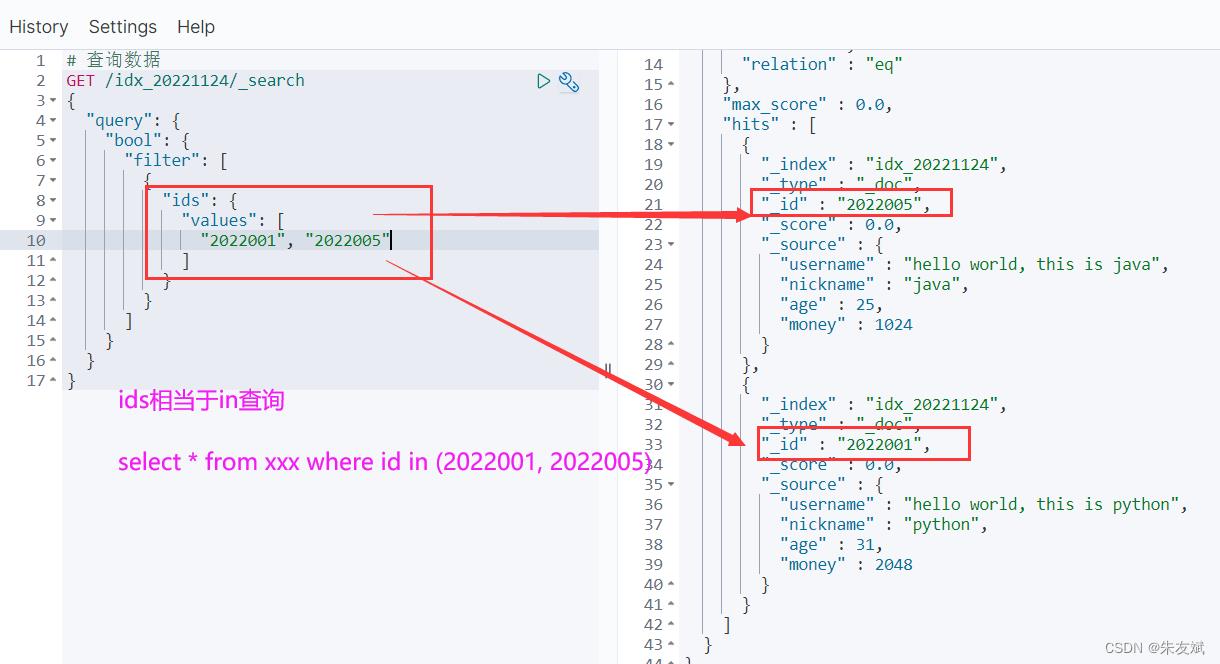
2.3、ids过滤查询
ids查询,这就相当于mysql数据库中的【in】条件查询,多个条件值查询,但是这里的只能够对doc文档的id进行多个值查询。
# 查询数据
# 查询doc文档id等于:2022001、2022005的数据
GET /idx_20221124/_search
"query":
"bool":
"filter": [
"ids":
"values": [
"2022001", "2022005"
]
]
执行结果:
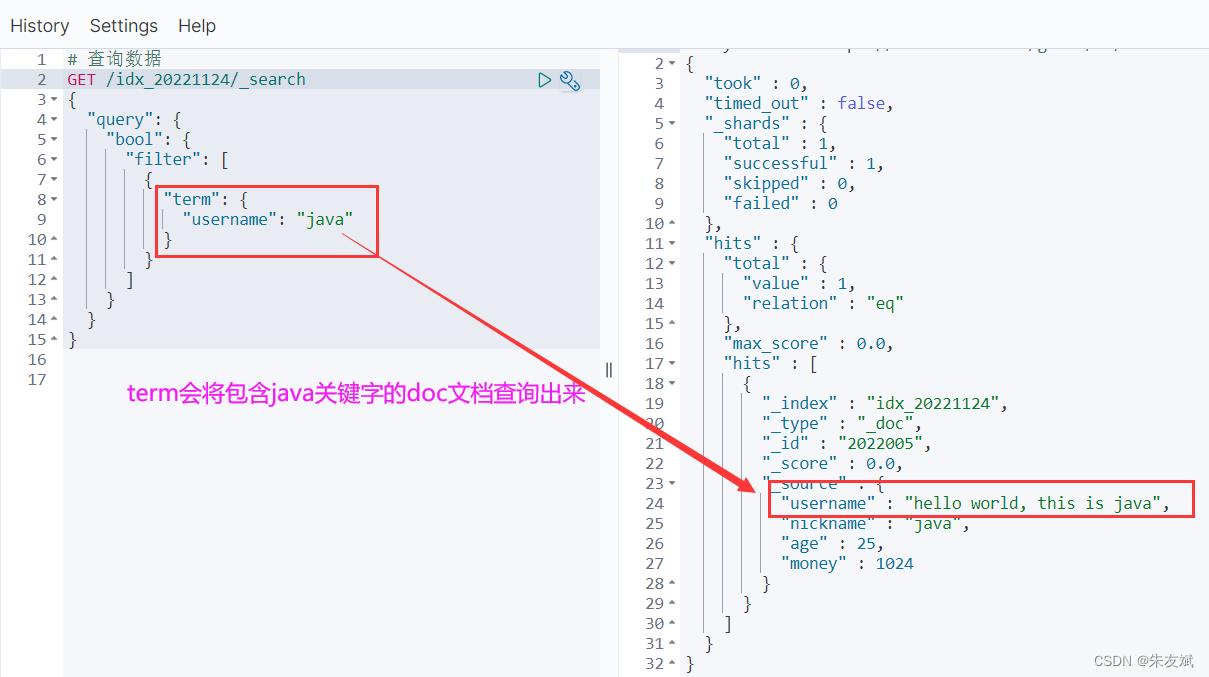
2.4、term关键词查询
term表示关键字查询,即:判断doc文档里面是否包含给定的term关键字,如果包含,则满足条件,否则不满足。
# 查询数据
GET /索引名称/_search
"query":
"bool":
"filter": [
"term":
"字段名称": "字段值"
]
# 测试案例
GET /idx_20221124/_search
"query":
"bool":
"filter": [
"term":
"username": "java"
]
执行结果:
2.5、terms多关键词查询
term每次只能够匹配一个关键字,而terms则允许多个关键字匹配。
# 查询数据
GET /idx_20221124/_search
"query":
"bool":
"filter": [
"terms":
"字段名称": [
"字段值1",
"字段值2",
"字段值n"
]
]
# 测试案例
GET /idx_20221124/_search
"query":
"bool":
"filter": [
"terms":
"username": [
"java",
"python"
]
]
执行结果:

到此,ES中的一些基本查询操作就介绍完啦。
综上,这篇文章结束了,主要介绍ElasticSearch数据库之查询操作(match、must、must_not、should、_source、filter、range、exists、ids、term、terms)。
elasticsearch基本查询笔记(三)-- es查询总结
参考技术Aterm 查询是简单查询,接受一个字段名和参数,进行精准查询,类似sql中:
ES中对应的DSL如下:
在ES5.x及以上版本,字符串类型需设置为keyword或text类型,根据类型来进行精确值匹配。
当进行精确值查询,可以使用过滤器,因为过滤器的执行非常快,不会计算相关度(ES会计算查询评分),且过滤器查询结果容易被缓存。
bool过滤器组成部分:
当我们需要多个过滤器时,只须将它们置入 bool 过滤器的不同部分即可。
terms是包含的意思,如下:
name包含["奥尼尔","麦迪"]
返回结果:
range查询可同时提供包含(inclusive)和不包含(exclusive)这两种范围表达式,可供组合的选项如下:
类似sql中的范围查询:
ES中对应的DSL如下:
如下sql,age不为null:
ES中对应的DSL如下:
如下sql,age为null:
ES中对应的DSL如下:
注:missing查询在5.x版本已经不存在。
匹配包含 not analyzed(未分词分析)的前缀字符:
匹配具有匹配通配符表达式( (not analyzed )的字段的文档。 支持的通配符:
1) * 它匹配任何字符序列(包括空字符序列);
2) ? 它匹配任何单个字符。
请注意,此查询可能很慢,因为它需要遍历多个术语。
为了防止非常慢的通配符查询,通配符不能以任何一个通配符*****或 ? 开头。
正则表达式查询允许您使用正则表达式术语查询。
举例如下:
注意: * 的匹配会非常慢,你需要使用一个长的前缀,
通常类似.*?+通配符查询的正则检索性能会非常低。
模糊查询查找在模糊度中指定的最大编辑距离内的所有可能的匹配项,然后检查术语字典,以找出在索引中实际存在待检索的关键词。
举例:
检索索引test_index中,type为user的全部信息。不过在 es6.x 版本,一个index仅有一个type,未来 es7.x 版本,将取消type,所以这个查询没啥意义。
返回指定id的全部信息。
全文检索查询,是通过分析器,对查询条件进行分析,然后在全文本字段进行全文查询。
全文搜索取决于mapping中设定的analyzer(分析器),这里使用的是ik分词器。
所以在进行查询开发时候,需要先了解index的mapping,从而选择查询方式。
匹配查询接受文本/数字/日期类型,分析它们,并构造查询。
对查询传入参数进行分词,搜索词语相同文档。
match_phrase查询分析文本,并从分析文本中创建短语查询。
用户已经渐渐习惯在输完查询内容之前,就能为他们展现搜索结果,这就是所谓的即时搜索(instant search) 或输入即搜索(search-as-you-type) 。
不仅用户能在更短的时间内得到搜索结果,我们也能引导用户搜索索引中真实存在的结果。
例如,如果用户输入 johnnie walker bl ,我们希望在它们完成输入搜索条件前就能得到: Johnnie Walker Black Label 和 Johnnie Walker Blue Label 。
match_phrase_prefix与match_phrase相同,除了它允许文本中最后一个术语的前缀匹配。
以上是关于ES笔记02ElasticSearch数据库之查询操作(matchmustmust_notshould_sourcefilterrangeexistsidstermterms)的主要内容,如果未能解决你的问题,请参考以下文章