Redis什么是缓存与数据库双写不一致?怎么解决?
Posted 没对象的指针
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis什么是缓存与数据库双写不一致?怎么解决?相关的知识,希望对你有一定的参考价值。
什么是缓存与数据库双写不一致?怎么解决?
1. 热点缓存重建
我们以热点缓存 key 重建来一步步引出什么是缓存与数据库双写不一致,及其解决办法。
1.1 什么是热点缓存重建
在实际开发中,开发人员使用 “缓存 + 过期时间” 的策略来实现加速数据读写和内存使用率,这种策略能满足大多数业务场景。但还是会有一些问题:
-
当前 key 是一个热点 key(某时间管理大师登顶微博热搜第一),并发量非常大;
-
在缓存失效瞬间,重建缓存不能在短时间完成(可能是一个负责业务场景,需要经过复杂的计算、多次IO、多次服务之间调用等等),有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用崩溃。
下面一起看一下热点缓存重建场景下的解决方案
1.2 基于 DCL(double check lock) 双重检测锁解决热点缓存并发重建问题
synchronized(this)
productStr = redisUtil.get(productCacheKey);
if (!StringUtils.isEmpty(productStr))
if (EMPTY_CACHE.equals(productStr))
redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);
return new Product();
product = JSON.parseObject(productStr, Product.class);
// 读延期
redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS);
return product;
product = productDao.get(productId);
if (product != null)
redisUtil.set(productCacheKey, JSON.toJSONString(product),
genProductCacheTimeout(), TimeUnit.SECONDS);
productMap.put(productCacheKey, product);
else
redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS);
DCL 存在的问题:
- synchronized 只在单节点内部有效,多节点会在每个web服务上缓存重建一次
- this 是单例的,比如同时有 101、102 两个商品需要热点重建,101 先请求,synchronized(this) 会把 102 阻塞,可以 synchronized(每个商品)
解决办法:分布式锁解决热点缓存并发重建问题
1.3 分布式锁解决热点缓存并发重建问题
RLock hotCacheLock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_PREFIX + productId);
hotCacheLock.lock();
try
productStr = redisUtil.get(productCacheKey);
if (!StringUtils.isEmpty(productStr))
if (EMPTY_CACHE.equals(productStr))
redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);
return new Product();
product = JSON.parseObject(productStr, Product.class);
// 读延期
redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS);
return product;
product = productDao.get(productId);
if (product != null)
redisUtil.set(productCacheKey, JSON.toJSONString(product),
genProductCacheTimeout(), TimeUnit.SECONDS);
productMap.put(productCacheKey, product);
else
redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS);
finally
hotCacheLock.unlock();
问题:缓存与数据库双写不一致
2. 缓存与数据库双写不一致
2.1 Cache Aside Pattern
Cache Aside Pattern 是最经典的 “缓存 + 数据库” 读写的模式。包括 Facebook 的论文《Scaling Memcache at Facebook》也使用了这个策略。
-
失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
-
命中:应用程序从cache中取数据,取到后返回。
-
更新:先把数据存到数据库中,成功后,再让缓存失效。

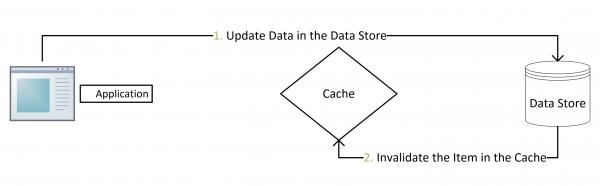
为什么不是写完数据库后更新缓存?而是删除缓存?
可以看一下Quora上的这个问答《Why does Facebook use delete to remove the key-value pair in Memcached instead of updating the Memcached during write request to the backend?》,主要是怕两个并发的写操作导致脏数据。
是不是 Cache Aside 这个就不会有并发问题了?
不是的,比如,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
这个问题理论上会出现,不过,实际上出现的概率可能非常低。
因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
所以,这也就是Quora上的那个答案里说的,要么通过2PC或是Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率,而Facebook使用了这个降低概率的玩法,因为2PC太慢,而Paxos太复杂。当然,最好还是为缓存设置上过期时间。
2.2 缓存与数据库双写不一致
2.2.1 数据不一样场景
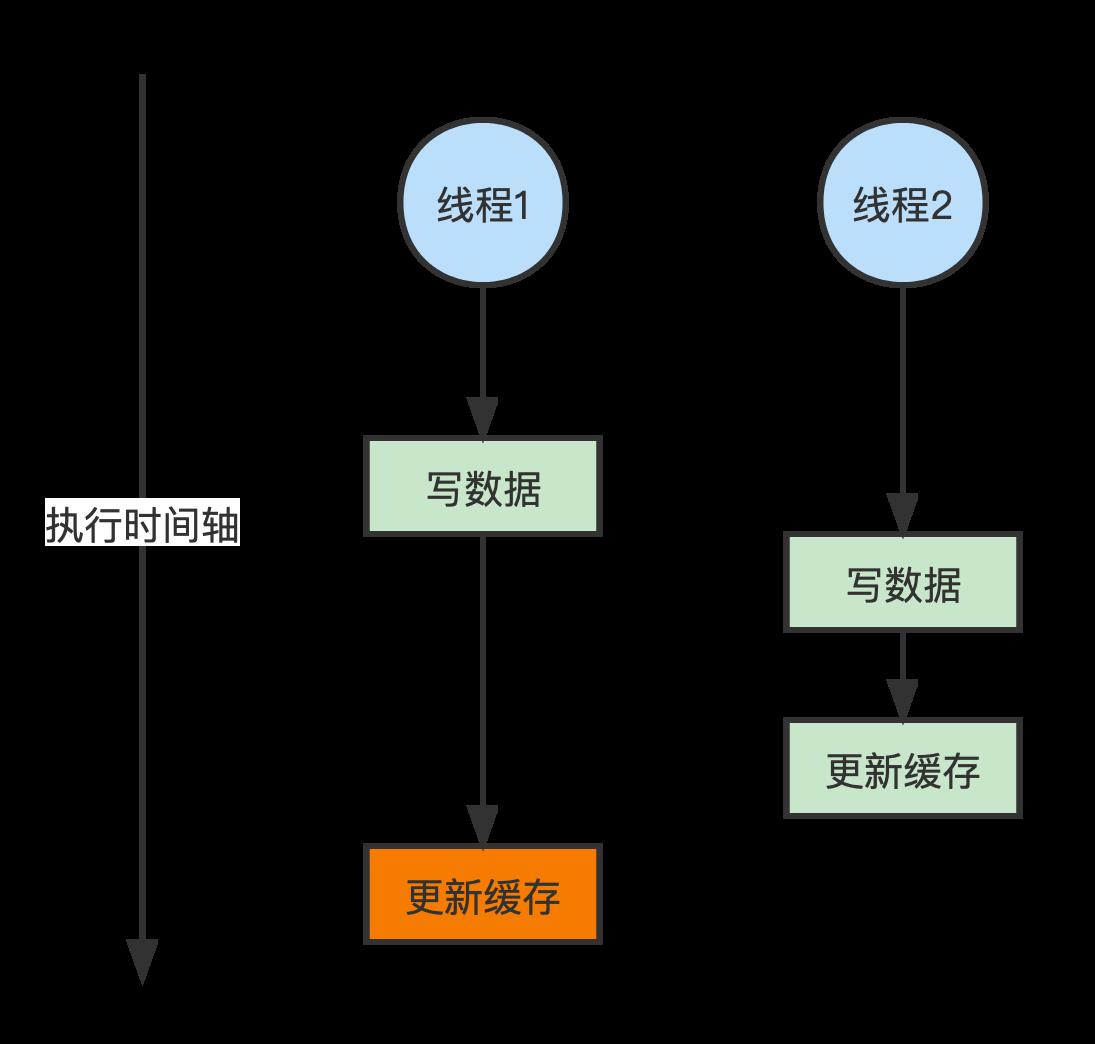
(1)双写不一致情况
线程1 在写数据库与更新缓存之间卡顿了一下,然后 线程2 在 线程1 卡顿的这个空隙去写了数据库并刷新了缓存,然后 线程2 都已经执行完了,线程1 又把脏数据更新到了缓存,造成了数据库与缓存不一致。
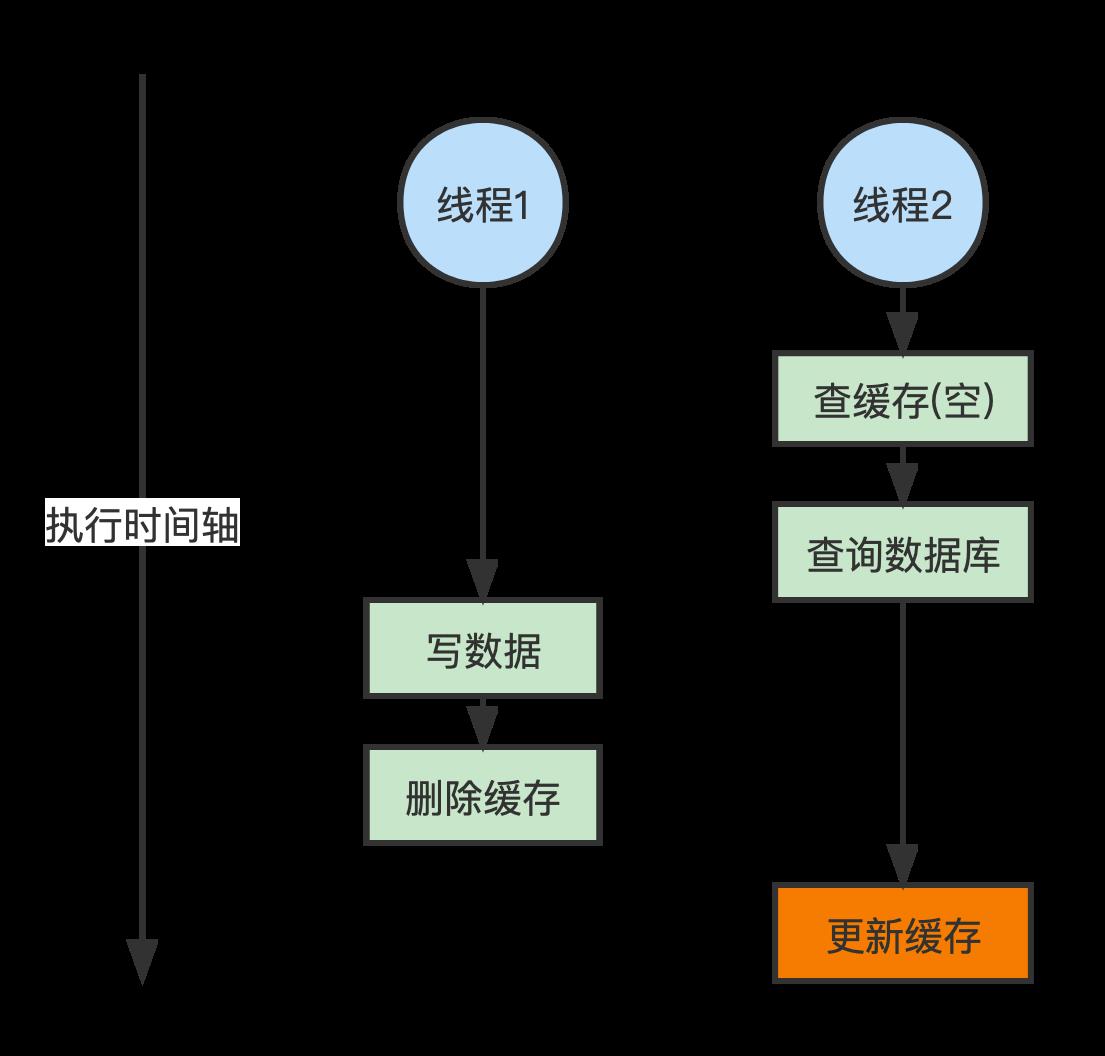
(2)读写并发不一致
线程1 执行读操作,且没有命中缓存,然后就到数据库中取数据;此时来了一个 线程2 执行写操作,写完数据库后,让缓存失效,然后,之前的 线程1 再把老的数据放进去,会造成脏数据。
2.2.2 解决方案
(1)缓存数据加上过期时间
-
对于并发几率很小的数据(如个人维度的订单数据、用户数据等),这种几乎不用考虑这个问题,很少会发生缓存不一致,可以给
缓存数据加上过期时间,每隔一段时间触发读的主动更新即可。 -
就算并发很高,如果业务上能容忍短时间的缓存数据不一致(如商品名称,商品分类菜单等),
缓存加上过期时间依然可以解决大部分业务对于缓存的要求。
(2)消息队列串行化
(1)主要思路:在后台进程中我们可以创建多个队列,然后根据hash算法将写请求路由到不同的队列中,当来读请求的时候,就加入队列中,当写请求处理完毕后,再去处理读请求。
(2)分析:如果对于同一份数据有多个写请求同时在队列中,那么来一个读请求中加入队列中之后,一般写请求耗时比较久,那么读请求会需要很久才能返回,这样会特别影响性能,但能保证一致性(一般情况下建议不要用)。
(3)加分布式锁
通过加分布式读写锁保证并发读写或写写的时候按顺序排好队,读读的时候相当于无锁。
RLock hotCacheLock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_PREFIX + productId);
hotCacheLock.lock();
try
productStr = redisUtil.get(productCacheKey);
if (!StringUtils.isEmpty(productStr))
if (EMPTY_CACHE.equals(productStr))
redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);
return new Product();
product = JSON.parseObject(productStr, Product.class);
// 读延期
redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS);
return product;
RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
RLock readLock = readWriteLock.readLock();
readLock.lock();
try
product = productDao.get(productId);
if (product != null)
redisUtil.set(productCacheKey, JSON.toJSONString(product),
genProductCacheTimeout(), TimeUnit.SECONDS);
productMap.put(productCacheKey, product);
else
redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS);
finally
readLock.unlock();
finally
hotCacheLock.unlock();
@Transactional
public Product update(Product product)
Product productResult = null;
RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + product.getId());
RLock writeLock = readWriteLock.writeLock();
writeLock.lock();
try
productResult = productDao.update(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult),
genProductCacheTimeout(), TimeUnit.SECONDS);
productMap.put(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), product);
finally
writeLock.unlock();
return productResult;
(4)canal 监听 binlog日志
可以用阿里开源的 canal 通过监听数据库的 binlog日志 及时的去修改缓存,但是引入了新的中间件,增加了系统的复杂度。
https://coolshell.cn/articles/17416.html
redis缓存+数据库双写不一致问题分析与解决方案
在高并发场景下,肯定会发生这个问题,这里简单谈谈解决思路
1.常规简单的解决方案
先删除缓存,在更新数据库,如果删除缓存成功,修改数据库失败了,那么数据库中依然是旧数据,如果去读取数据的时候,发现缓存没有,则去读数据库,数据库会把旧数据加载到缓存里,这样缓存和数据库则保持了一致。
2.如果在高并发的情况下会发生了如下更复杂的操作
比如有数据发生了变更,先删除了缓存,然后准备要去修改数据库,此时还没修改,这时候一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中 ,之后数据变更的程序完成了数据库的修改。完了,数据库和缓存中的数据不一样了。。。
3.内存队列
更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个jvm内部的队列中,读取数据的时候,如果发现数据不在缓存中,那么将重新读取数据+更新缓存的操作,根据唯一标识路由之后,也发送同一个jvm内部的队列中
一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行。这样的话,一个数据变更的操作,先执行删除缓存,然后再去更新数据库,但是还没完成更新。此时如果一个读请求过来,读到了空的缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤,如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可,待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中。如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回; 如果请求等待的时间
超过一定时长,那么这一次直接从数据库中读取当前的旧值。
以上是关于Redis什么是缓存与数据库双写不一致?怎么解决?的主要内容,如果未能解决你的问题,请参考以下文章