论文解读|2018Prerequisite-Driven Deep Knowledge Tracing
Posted 林若漫空
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读|2018Prerequisite-Driven Deep Knowledge Tracing相关的知识,希望对你有一定的参考价值。

先决条件驱动的知识追踪
文章目录
摘要
知识追踪是计算机支持教育环境(如智能辅导系统)中对学生知识状态进行建模的关键技术。虽然已经开发了贝叶斯知识追踪和深度知识追踪模型,但学生运动数据的稀疏性仍然限制了知识追踪的性能和应用。为了解决这一问题,我们提倡并提出将知识结构信息,特别是教学概念之间的前提关系,纳入知识追踪模型。具体而言,通过考虑学生如何掌握教学概念及其先决条件,我们将先决条件概念对建模为有序对。通过适当的数学公式,可以将这一性质作为知识追踪模型设计的约束条件。结果表明,该模型对学生的概念掌握有较好的预测效果。为了对该模型进行评价,我们在5个不同的真实世界数据集上进行了测试,实验结果表明,通过与三种知识追踪模型的比较,所提出的模型取得了显著的性能提高。
1 引言
知识追踪的目的是通过定量诊断学生对每个概念[9]的掌握程度,对学生个体的知识状态进行建模。传统上,知识追溯是实现个性化学习和教学的关键组成部分和技术之一,学生可以选择他们需要更多的练习,教师可以决定哪些概念更多地教授给学生[2],[3],[30]。快速发展的计算机辅助教育环境和在线教育平台为知识追溯提供了丰富的学生练习数据。然而,这也带来了一个主要的挑战,那就是学生行为的稀疏性。具体而言,学生使用系统的时间基础不规律,用于练习的时间较少,对自己的概念掌握情况进行综合评估。因此,对于每个学生来说,每门学科很可能只有一小部分概念被实践(通过解决测试问题)或学习(通过浏览教程视频或与老师互动)。大量概念的掌握水平未知,使得知识追踪存在准确性问题,限制了知识追溯的进一步应用(如学生成绩预测[15]、问题难度预测[14]、课程优化[22])。
我们解决稀疏性问题的思路在于充分挖掘知识结构中概念之间的相互依赖关系,特别是教学概念之间的先决条件。概念通常不是单独存在的:一些概念作为其他概念的先决条件,因此,如果我们知道一个学生掌握了一个目标概念,那么我们就可以确定她也掌握了这个目标概念的先决条件。知识追踪的建模先决条件还有待深入研究。大多数现有的研究先决条件的工作主要是对先决条件进行挖掘,而不是对它们进行建模,以辅助知识跟踪[16]、[17]、[20]、[29]。其他一些工作尝试使用先决条件进行概念图提取[27],但仍然没有考虑如何使用先决条件进行知识跟踪。对学生建模[5]、[7]使用先决条件的尝试是有限的,但他们没有专门将深度学习用于知识跟踪目的。
在本文中,我们提出了一种新的方法来建模知识追踪的先决条件。简而言之,我们的直觉是,先决条件实际上代表了概念学习的依赖,这自然是对学生概念掌握预测的约束。让我们考虑一个例子。假设有两个概念k1和k2, k1是k2的前提条件。一般来说,这意味着如果一个学生掌握了k2,那么她很可能也掌握了k1;此外,如果学生没有掌握k1,那么她不可能掌握k2[4]。利用这一特性,我们提出了一个以先决条件为约束条件的知识追踪模型,它实际上在问题之间建立了联系。因此,练习数据稀疏性问题可以得到缓解,我们现在可以在估计每个学生对概念的掌握程度方面获得更好的表现。
然而,尽管将先决条件建模为知识跟踪模型的约束条件,对于数据稀疏性问题很有前景,但如何将先决条件建模为约束条件仍然是一个主要的挑战。有许多不同的方法来建模约束,但是如何将先决条件表达和表述成适当的数学形式并不简单。例如,可以将约束建模为逻辑[1]、[23]或正则化中的布尔函数[6]、[11],或目标函数中最大化的条件概率[32]。我们将在后面详细的数学形式中看到,每一种约束建模的方法对于在深入的知识追踪设置中制定教学概念之间的先决条件关系都不是微不足道的。
为了应对这一挑战,通过分析先决条件的特征,我们提出将每个先决条件建模为学生对两个概念的掌握水平之间的排序对。也就是说,假设概念k1是概念k2的前提;然后,我们强制学生掌握k1的概率总是大于她在以后任何时候掌握k2的概率。正如我们将在后面的推导细节中看到的,这样的排序对有一个很好的数学公式,它很容易解释,在计算上也很容易处理。最后,我们提出了一个包含前提约束的顺序对正则化深度知识跟踪框架,该框架对学生的知识状态估计有较好的效果。
主要贡献:
- 我们研究了一个重要的问题,即如何将辅助深度知识追踪的先决条件纳入其中,这本质上是将学科概念及其结构信息引入知识追踪领域;
- 我们探索了一种通过新的知识追踪模型将先决条件建模为约束的新方法;
- 我们在真实数据集上评估了我们的模型,结果表明我们的模型改进了最先进的基线。
本文的其余部分组织如下:第二部分回顾了现有的工作以及我们的模型与其他工作的不同之处。第三节对问题定义进行了清晰的描述,第四节说明了如何对练习序列数据进行建模。拟议模式的细节载于第五节。第六节给出了在五个真实世界数据集上的实验结果,并在第七节对全文进行了总结。
2 相关工作
研究人员探索了进行知识追踪的不同方法。早期的工作集中在贝叶斯知识追踪模型,它将每个学生的知识状态定义为一个二元变量,并利用像隐马尔可夫模型这样的概率模型来估计学生的概念掌握[9]。随后,研究人员考虑了滑移和猜测[2]等认知因素,对模型进行了改进。对个别学生的先验知识[30]和问题[21]的难度水平也进行了探索,以改进贝叶斯知识追踪模型。为了处理主观问题的部分正确反应,提出了模糊认知诊断框架[28]。近年来,随着深度学习的发展,深度知识追踪模型被提出来建模学生的练习序列[22],基于动态键值记忆网络的模型也被提出来更好地表示问题语义[31]。此外,结合推荐系统的发展,提出了基于矩阵分解的学生运动数据建模方法[26]。与这些知识追踪模型相比,我们在使用深度学习(特别是前提条件驱动的循环神经网络)进行知识追踪的同时,也在深度知识追踪的背景下探索了前提条件。
利用先决信息来解决知识追踪问题在以往的工作中仍有局限性。通过将知识跟踪问题建模为贝叶斯网络,[5]尝试将先决条件作为贝叶斯网络中的一个新层引入。此外,最近的一项工作试图扩展先决条件贝叶斯网络建模的思想,共同发现先决条件图,并估计学生的概念掌握[7]。与这两种方法相比,我们考虑了深度学习背景下的知识追踪,并系统地探讨了前提条件。
另一个与此密切相关的研究是约束学习,这是一种将领域知识整合到预测中的流行方法。例如,马尔科夫逻辑网络(MLN)[23]以一阶逻辑的形式对约束进行建模。相比之下,我们以排序对的形式对学生概念掌握进行建模,比用逻辑来制定先决条件更加灵活。也有非逻辑形式的建模约束,如约束驱动学习[6]、广义期望[18]、后验正则化[11]和鲁棒RegBayes[19],但所有这些方法都没有考虑如何在深度学习模型中使用约束。此外,最近的一些尝试尝试在知识图嵌入[12]、深度神经网络[13]和文本嵌入中使用逻辑规则进行关系提取[24]。然而,它们被设计用于不同的应用程序,而不是深度知识跟踪,并且它们必须以逻辑形式建模约束。
5 结论
为了更好地估计学生的知识状态,本文开发了一种新的知识追踪模型PDKT-C。直观的方法是利用概念之间的前提关系来规范知识追踪模型。更具体地说,通过考虑前提关系如何影响学生对概念的掌握,我们定义了概念掌握概率的排序对。该排序对通过适当的数学公式,在知识追踪模型中形成数学约束,从而更好地预测学生的知识状态。最后,在五个真实世界的数据集上进行了大量的实验,结果表明,与其他基线模型相比,所提出的PDKT-C模型产生了显著的性能改进。
在未来的工作中,我们希望探索其他更好地表达这些概念相互依赖的方法,例如图嵌入。此外,我们还希望联合优化前提关系提取过程和知识追踪过程,更好地识别前提关系,估计学生的知识状态。
《ALBERT 论文解读》
ALBERT 论文解读
NLP论文专栏里怎么可能没有关于BERT的论文呢,今天给大家介绍的就是google最近发的一个又一个秒杀各个数据集的模型ALBERT。
论文地址:
https://openreview.net/pdf?id=H1eA7AEtvSgithub地址(中文预训练模型):
brightmart/albert_zh?github.com
一、概述
最近各种大体量的预训练模型层出不穷,经常是一个出来刷榜没几天,另外一个又出现了。BERT、RoBERTa、XLNET等等都是代表人物。这些“BERT”们虽然一个比一个效果好,但是他们的体量都是非常大的,懂不懂就几千万几个亿的参数量,而且训练也非常困难。新出的ALBERT就是为了解决模型参数量大以及训练时间过长的问题。ALBERT最小的参数只有十几M, 效果要比BERT低1-2个点,最大的xxlarge也就200多M。可以看到在模型参数量上减少的还是非常明显的,但是在速度上似乎没有那么明显。最大的问题就是这种方式其实并没有减少计算量,也就是受推理时间并没有减少,训练时间的减少也有待商榷。
二、模型详解
整个模型的结构还是依照了BERT的骨架,采用了Transformer以及GELU激活函数。具体的创新部分应该有三个:一个是将embedding的参数进行了因式分解,然后就是跨层的参数共享,最后是抛弃了原来的NSP任务,现在使用SOP任务。这几个更新的细节后面会仔细再说。这三个更新前两个的主要任务就是来进行参数减少的,第三个更新这已经算不上什么更新了,之前已经有很多工作发现原来BERT中的下一句话预测这个任务并没有什么积极地影响。根据文章的实验结果来看似乎参数共享对参数降低的影响比较大,同时也会影响模型的整体效果。后面就来详细的说一下这三个改动。
- Factorized embedding parameterization
原始的BERT模型以及各种依据transformer来搞的预训练语言模型在输入的地方我们会发现它的E是等于H的,其中E就是embedding size,H就是hidden size,也就是transformer的输入输出维度。这就会导致一个问题,当我们的hidden size提升的时候,embedding size也需要提升,这就会导致我们的embedding matrix维度的提升。所以这里作者将E和H进行了解绑,具体的操作其实就是在embedding后面加入一个矩阵进行维度变换。E是永远不变的,后面H提高了后,我们在E的后面进行一个升维操作,让E达到H的维度。这使得embedding参数的维度从O(V×H)到了O(V×E + E×H), 当E远远小于H的时候更加明显。
- Cross-layer parameter sharing
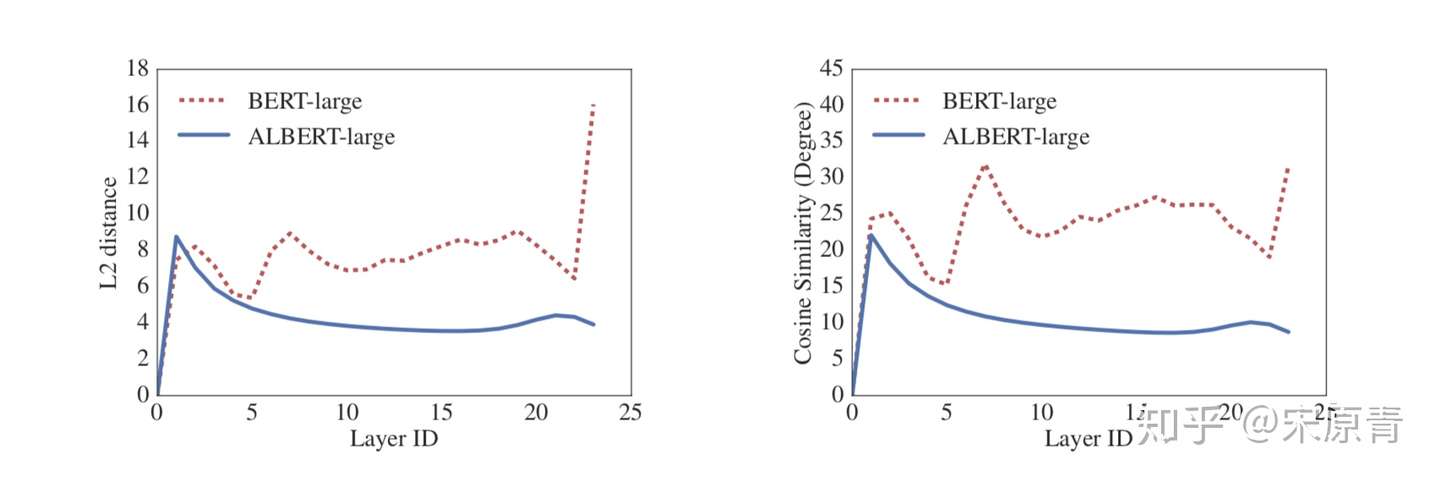
之前transformer的每一层参数都是独立的,包括self-attention 和全连接,这样的话当层数增加的时候,参数就会很明显的上升。之前有工作试过单独的将self-attention或者全连接进行共享,都取得了一些效果。这里作者尝试将所有的参数进行共享,这其实就导致多层的attention其实就是一层attention的叠加。同时作者通过实验还发现了,使用参数共享可以有效地提升模型的稳定程度。实验结果如下图:
- Inter-sentence coherence loss
这里作者使用了一个新的loss,其实就是更改了原来BERT的一个子任务NSP, 原来NSP就是来预测下一个句子的,也就是一个句子是不是另一个句子的下一个句子。这个任务的问题出在训练数据上面,正例就是用的一个文档里面连续的两句话,但是负例使用的是不同文档里面的两句话。这就导致这个任务包含了主题预测在里面,而主题预测又要比两句话连续性的预测简单太多。新的方法使用了sentence-order prediction(SOP), 正例的构建和NSP是一样的,不过负例则是将两句话反过来。实验的结果也证明这种方式要比之前好很多。但是这个这里应该不是首创了,百度的ERNIE貌似也采用了一个这种的。
三、实验
作者进行了大量的对比试验对前面三个改进进行了证明,首先是模型的参数配置:
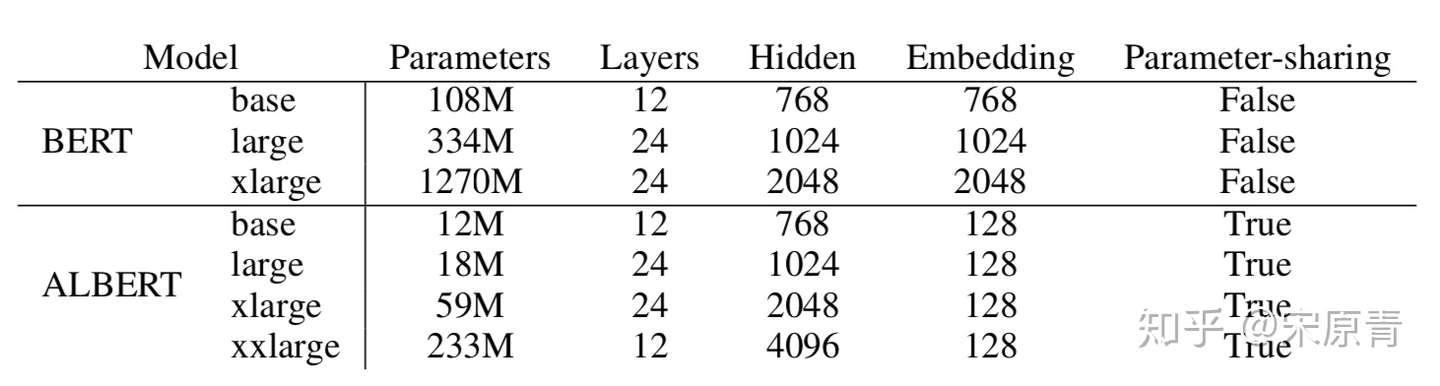
这里可以看到ALBERT的与参数的减少还是非常的显著的,同时我们也可以看出来,似乎参数共享对参数量减少的作用更大一点。
- 整体与BERT的对比
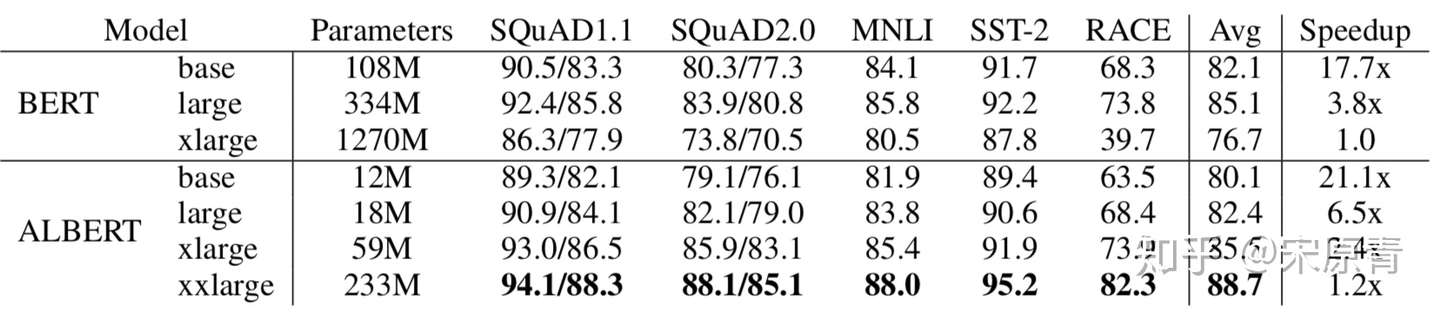
这里的比较就很有意思了,首先常规的提升我们都能看到,参数量巨大的减少以及效果的提升。但是我们可以看到ALBERT xxlarge只有233M的参数,而BERT xlarge足足有1270M的参数,但是在训练速度上之快了0.2。这个模型其实在计算效率上并没有很大的提升。
- 因式分解embedding的影响
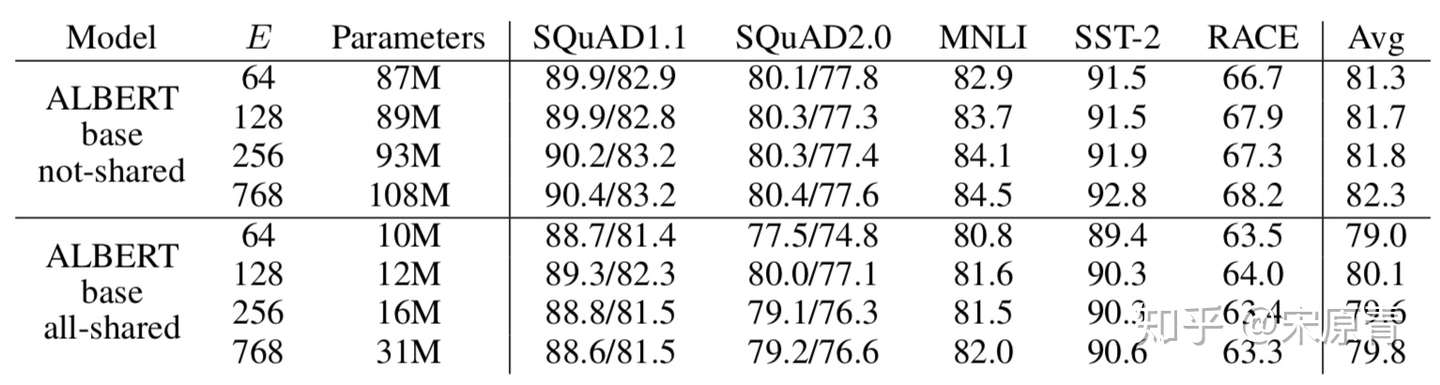
这里我们可以看到,对于参数不共享的版本,随着E的增加,效果是不断提升的。但是在参数共享的版本似乎不是这样的,效果最好的版本并不是E最大的版本。同时我们也可以发现参数共享对于效果可能带来1-2个点的下降
- 多层参数共享的影响
 添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
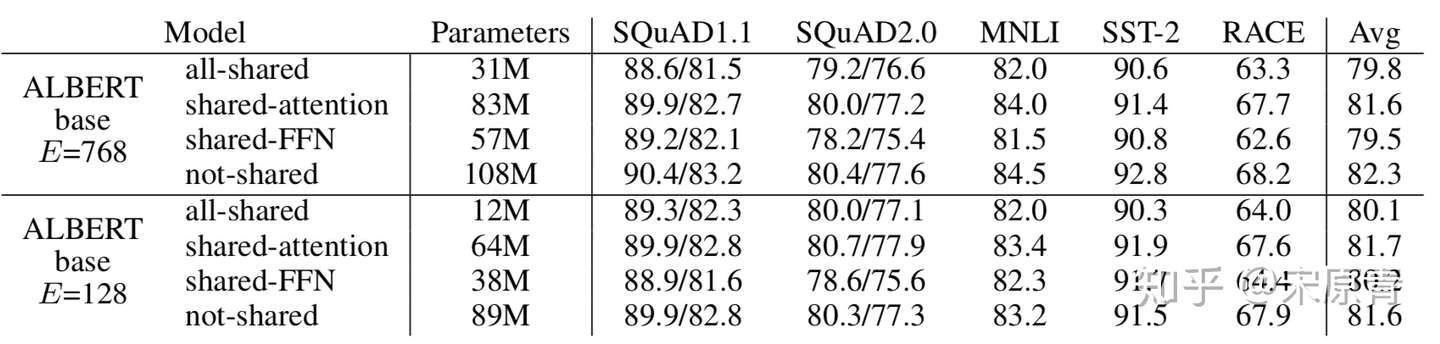
这里我们可以看到对于E=768的版本,参数不共享的效果是最好的,但是对于E=128的版本,只共享attention确实最好的。这里作者只是指出了这个情况,但是没有分析具体的原因是为啥。
- SOP任务的影响

这里可以看到SOP任务对于各个数据集效果提升还是很明显的。
- 网络深度和宽度的影响

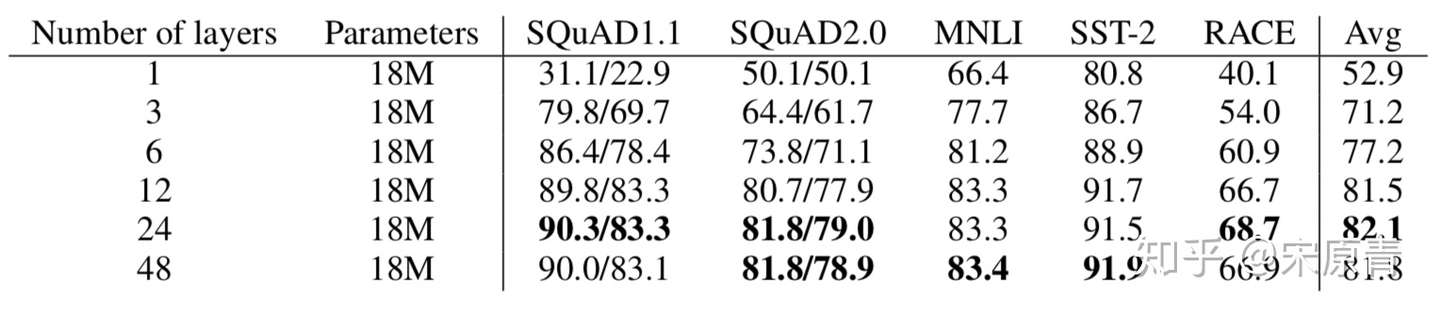
上面两个图我们可以看出来,随着网络的加深和加宽,模型效果是越来越好的。
四、结论
总体来看这个模型并没有那么的让人惊喜,虽然在各个数据及上有更好的效果而且参数量下降了。但是XXlarge版本的计算量还是非常大的,这就意味着其在训练和推理上要花更多的时间,作者也说了未来的工作就是提升模型的推理速度。
以上是关于论文解读|2018Prerequisite-Driven Deep Knowledge Tracing的主要内容,如果未能解决你的问题,请参考以下文章