「Python 机器学习」Pandas 数据分析
Posted Aurelius-Shu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「Python 机器学习」Pandas 数据分析相关的知识,希望对你有一定的参考价值。
Pandas 是一个开源的 Python 库,专为数据处理和分析任务而设计;它提供了高性能、易用的数据结构和数据分析工具,使得在 Python 中进行数据科学变得简单高效;Pandas 基于 NumPy,因此可以与许多其他基于 NumPy 的库(如 SciPy 和 scikit-learn)无缝集成;
Pandas 中的两个主要数据结构
-
Series,一个一维带标签的数组,可存储整数、浮点数、字符串等不同类型的数据;Series 具有索引(index),这使得它类似于 Python 字典,但具有更多的特性和功能; -
DataFrame,一个二维带标签的数据结构,类似于表格或电子表格;它由一系列具有相同索引的列组成,每列可以具有不同的数据类型;DataFrame 提供了各种功能,如筛选、排序、分组、合并和聚合,以便在大型数据集上进行高效操作;
支持的数据处理和分析任务
- 数据导入和导出
- 数据清洗和预处理
- 数据过滤和选择
- 数据排序、排名和聚合
- 缺失值处理
- 分组操作
- 数据透视表
- 时间序列分析
- 合并和连接多个数据集
Pandas 提供了丰富的功能,使得它成为 Python 数据科学生态系统中最受欢迎和广泛使用的库之一;
import pandas as pd
import numpy as np
文章目录
1. Series
1. 构造与初始化
- Series 是一个一维数据结构,Pandas 会默认用 0 到 n 来作为 Series 的 index;
>>> s = pd.Series([1, 3, 'Beijing', 3.14, -123, 'Year!'])
>>> s
0 1
1 3
2 Beijing
3 3.14
4 -123
5 Year!
dtype: object
- 自行指定 index;
>>> s = pd.Series([1, 3, 'Beijing', 3.14, -123, 'Year!'], index=['A', 'B', 'C', 'D', 'E','G'])
>>> s
A 1
B 3
C Beijing
D 3.14
E -123
G Year!
dtype: object
- 直接使用 dictionary 构造 Series, 因为 Series 本身就是 keyvalue pairs;
>>> cities = 'Beijing': 55000, 'Shanghai': 60000, 'Shenzhen': 50000,
>>> 'Hangzhou': 20000, 'Guangzhou': 25000, 'Suzhou': None
>>> apts = pd.Series(cities)
>>> apts
Beijing 55000.0
Shanghai 60000.0
Shenzhen 50000.0
Hangzhou 20000.0
Guangzhou 25000.0
Suzhou NaN
dtype: float64
2. 选择数据
- 通过 index 选择数据
>>> apts['Hangzhou']
20000.0
>>> apts[['Hangzhou', 'Beijing', 'Shenzhen']]
Hangzhou 20000.0
Beijing 55000.0
Shenzhen 50000.0
dtype: float64
>>> # boolean indexing
>>> apts[apts < 50000]
Hangzhou 20000.0
Guangzhou 25000.0
dtype: float64
>>> # boolean indexing 的工作方式
>>> less_than_50000 = apts < 50000
>>> less_than_50000
Beijing False
Shanghai False
Shenzhen False
Hangzhou True
Guangzhou True
Suzhou False
dtype: bool
>>> apts[less_than_50000]
Hangzhou 20000.0
Guangzhou 25000.0
dtype: float64
3. 元素赋值
>>> print("Old value: ", apts['Shenzhen'])
Old value: 50000.0
>>> apts['Shenzhen'] = 55000
>>> print("New value: ", apts['Shenzhen'])
New value: 55000.0
>>> print(apts[apts < 50000])
Hangzhou 20000.0
Guangzhou 25000.0
dtype: float64
>>> apts[apts <= 50000] = 40000
>>> print(apts[apts < 50000])
angzhou 40000.0
Guangzhou 40000.0
dtype: float64
4. 数学运算
>>> apts / 2
Beijing 27500.0
Shanghai 30000.0
Shenzhen 27500.0
Hangzhou 20000.0
Guangzhou 20000.0
Suzhou NaN
dtype: float64
>>> np.square(apts)
Beijing 3.025000e+09
Shanghai 3.600000e+09
Shenzhen 3.025000e+09
Hangzhou 1.600000e+09
Guangzhou 1.600000e+09
Suzhou NaN
dtype: float64
>>> cars = pd.Series('Beijing': 300000, 'Shanghai': 400000, 'Shenzhen': 300000,
>>> 'Tianjin': 200000, 'Guangzhou': 200000, 'Chongqing': 150000)
>>> cars
Beijing 300000
Shanghai 400000
Shenzhen 300000
Tianjin 200000
Guangzhou 200000
Chongqing 150000
dtype: int64
>>> # 按 index 运算
>>> cars + apts * 100
Beijing 5800000.0
Chongqing NaN
Guangzhou 4200000.0
Hangzhou NaN
Shanghai 6400000.0
Shenzhen 5800000.0
Suzhou NaN
Tianjin NaN
dtype: float64
5. 数据缺失
>>> print('Hangzhou' in apts)
True
>>> print('Hangzhou' in cars)
False
>>> apts.notnull()
Beijing True
Shanghai True
Shenzhen True
Hangzhou True
Guangzhou True
Suzhou False
dtype: bool
>>> print(apts.isnull())
Beijing False
Shanghai False
Shenzhen False
Hangzhou False
Guangzhou False
Suzhou True
dtype: bool
>>> print(apts[apts.isnull()])
Suzhou NaN
dtype: float64
2. DataFrame
一个 DataFrame 就是一张表格,Series 表示的是一维数组,DataFrame 则是一个二维数组,可以类比成一张 excel 的表格;也可以把 DataFrame 当做一个一组 Series 的集合;
1. 构造和选择数据
- 由一个 dictionary 构造;
>>> data = 'city': ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen', 'Hangzhou', 'Chongqing'],
>>> 'year': [2016, 2017, 2016, 2017, 2016, 2016],
>>> 'population': [2100, 2300, 1000, 700, 500, 500]
>>> d1 = pd.DataFrame(data)
>>> print(d1)
city year population
0 Beijing 2016 2100
1 Shanghai 2017 2300
2 Guangzhou 2016 1000
3 Shenzhen 2017 700
4 Hangzhou 2016 500
5 Chongqing 2016 500
- 全列遍历
>>> for row in d1.values:
>>> print(row)
['Beijing' 2016 2100]
['Shanghai' 2017 2300]
['Guangzhou' 2016 1000]
['Shenzhen' 2017 700]
['Hangzhou' 2016 500]
['Chongqing' 2016 500]
- 选择列并合并遍历
>>> for row in zip(d1['city'], d1['year'], d1['population']):
>>> print(row)
('Beijing', 2016, 2100)
('Shanghai', 2017, 2300)
('Guangzhou', 2016, 1000)
('Shenzhen', 2017, 700)
('Hangzhou', 2016, 500)
('Chongqing', 2016, 500)
>>> print(d1.columns)
Index(['city', 'year', 'population'], dtype='object')
- 列序重组
>>> print(pd.DataFrame(data, columns=['year', 'city', 'population']))
year city population
0 2016 Beijing 2100
1 2017 Shanghai 2300
2 2016 Guangzhou 1000
3 2017 Shenzhen 700
4 2016 Hangzhou 500
5 2016 Chongqing 500
- 行与列索引
>>> frame2 = pd.DataFrame(data,
>>> columns=['year', 'city', 'population', 'debt'],
>>> index=['one', 'two', 'three', 'four', 'five', 'six'])
>>> print(frame2)
year city population debt
one 2016 Beijing 2100 NaN
two 2017 Shanghai 2300 NaN
three 2016 Guangzhou 1000 NaN
four 2017 Shenzhen 700 NaN
five 2016 Hangzhou 500 NaN
six 2016 Chongqing 500 NaN
>>> print(frame2['city'])
one Beijing
two Shanghai
three Guangzhou
four Shenzhen
five Hangzhou
six Chongqing
Name: city, dtype: object
>>> print(frame2.year)
one 2016
two 2017
three 2016
four 2017
five 2016
six 2016
Name: year, dtype: int64
>>> # loc 取 label based indexing or iloc 取 positional indexing
>>> print(frame2.loc['three'])
year 2016
city Guangzhou
population 1000
debt NaN
Name: three, dtype: object
>>> print(frame2.iloc[2].copy())
year 2016
city Guangzhou
population 1000
debt NaN
Name: three, dtype: object
2. 元素赋值
- 整列赋值(单值);
>>> frame2['debt'] = 100
>>> print(frame2)
year city population debt
one 2016 Beijing 2100 100
two 2017 Shanghai 2300 100
three 2016 Guangzhou 1000 100
four 2017 Shenzhen 700 100
five 2016 Hangzhou 500 100
six 2016 Chongqing 500 100
- 整列赋值(列表值);
>>> frame2.debt = np.arange(6)
>>> print(frame2)
year city population debt
one 2016 Beijing 2100 0
two 2017 Shanghai 2300 1
three 2016 Guangzhou 1000 2
four 2017 Shenzhen 700 3
five 2016 Hangzhou 500 4
six 2016 Chongqing 500 5
- 用 Series 来指定需要修改的 index 以及相对应的 value,没有指定的默认用 NaN;
>>> val = pd.Series([100, 200, 300], index=['two', 'three', 'five'])
>>> frame2['debt'] = val
>>> print(frame2)
year city population debt
one 2016 Beijing 2100 NaN
two 2017 Shanghai 2300 100.0
three 2016 Guangzhou 1000 200.0
four 2017 Shenzhen 700 NaN
five 2016 Hangzhou 500 300.0
six 2016 Chongqing 500 NaN
- 用存在的列赋值(创建新列);
>>> frame2['western'] = (frame2.city == 'Chongqing')
>>> print(frame2)
year city population debt western
one 2016 Beijing 2100 NaN False
two 2017 Shanghai 2300 100.0 False
three 2016 Guangzhou 1000 200.0 False
four 2017 Shenzhen 700 NaN False
five 2016 Hangzhou 500 300.0 False
six 2016 Chongqing 500 NaN True
- DataFrame 的转置;
>>> pop = 'Beijing': 2016: 2100, 2017: 2200,
>>> 'Shanghai': 2015: 2400, 2016: 2500, 2017: 2600
>>> frame3 = pd.DataFrame(pop)
>>> print(frame3)
Beijing Shanghai
2016 2100.0 2500
2017 2200.0 2600
2015 NaN 2400
>>> print(frame3.T)
2016 2017 2015
Beijing 2100.0 2200.0 NaN
Shanghai 2500.0 2600.0 2400.0
- 行序重组;
>>> pd.DataFrame(pop, index=[2015, 2016, 2017])
Beijing Shanghai
2015 NaN 2400
2016 2100.0 2500
2017 2200.0 2600
- 使用切片初始化数据;
>>> pdata = 'Beijing': frame3['Beijing'][:-1],
>>> 'Shanghai': frame3['Shanghai'][:-1]
>>> pd.DataFrame(pdata)
Beijing Shanghai
2016 2100.0 2500
2017 2200.0 2600
- 指定 index 的名字和列的名字;
>>> frame3.index.name = 'year'
>>> frame3.columns.name = 'city'
>>> print(frame3)
city Beijing Shanghai
year
2016 2100.0 2500
2017 2200.0 2600
2015 NaN 2400
>>> print(frame2.values)
[[2016 'Beijing' 2100 nan False]
[2017 'Shanghai' 2300 100.0 False]
[2016 'Guangzhou' 1000 200.0 False]
[2017 'Shenzhen' 700 nan False]
[2016 'Hangzhou' 500 300.0 False]
[2016 'Chongqing' 500 nan True]]
>>> print(frame2)
year city population debt western
one 2016 Beijing 2100 NaN False
two 2017 Shanghai 2300 100.0 False
three 2016 Guangzhou 1000 200.0 False
four 2017 Shenzhen 700 NaN False
five 2016 Hangzhou 500 300.0 False
six 2016 Chongqing 500 NaN True
>>> print(type(frame2.values))
<class 'numpy.ndarray'>
3. Index
1. Index 对象
>>> obj = pd.Series(range(3), index=['a', 'b', 'c'])
>>> index = obj.index
>>> index
Index(['a', 'b', 'c'], dtype='object')
>>> index[1:]
Index(['b', 'c'], dtype='object')
>>> # index 不能被动态改动
>>> # index[1]='d'
>>> index = pd.Index(np.arange(3))
>>> obj2 = pd.Series([2, 5, 7], index=index)
>>> print(obj2)
0 2
1 5
2 7
dtype: int64
>>> print(obj2.index is index)
True
>>> 2 in obj2.index
True
>>> pop = 'Beijing': 2016: 2100, 2017: 2200,
>>> 'Shanghai': 2015: 2400, 2016: 2500, 2017: 2600
>>> frame3 = pd.DataFrame(pop)
>>> print('Shanghai' in frame3.columns)
True
>>> print('2015' in frame3.index)
False
>>python机器学习数据建模与分析——pandas中常用函数总结
本文主要对数据建模与分析中常使用到的pandas内置函数进行总结分析,以此来熟悉数据建模与分析的流程。
文章目录
一、Pandas数据结构
Pandas有两个最主要也是最重要的数据结构Series 和DataFrame
类型 描述 Series 一维的数据结构DataFrame 二维的表格型的数据结构
提示:以下是本篇文章正文内容,下面案例可供参考
1.1 数据结构—Series
Series是一个类似一维数组的对象,它能够保存任何类型的数据,主要由一组数据和与之相关的索引两部分构成,函数如下:
pandas.Series(data, index, dtype, name, copy)
参数说明:
data:一组数据(ndarray 类型)index:数据索引标签,如果不指定,默认从 0 开始dtype:数据类型,默认会自己判断name:设置名称 copy:拷贝数据,默认为 False
注意:
Series的索引位于左边,数据位于右边
index element 0 a 1 b 2 c 3 d
1.1.1 Series的创建方式
Pandas的Series类对象的原型如下(仅作了解):
class pandas.Series(data = None,index = None,dtype = None,
name = None,copy = False,fastpath = False)
data:表示传入的数据。index:表示索引,唯一且与数据长度相等,默认会自动创建一个从0~N的整数索引。
创建series对象举例:
1、通过传入一个列表来创建一个Series类对象:
# 给pandas起个别名pd
import pandas as pd
# 创建Series类对象
ser_obj = pd.Series([1, 2, 3, 4, 5])
print(ser_obj)
# 输出结果如下:
0 1
1 2
2 3
3 4
4 5
dtype: int64
创建Series类对象,并指定索引
# 给pandas起个别名pd
import pandas as pd
# 创建Series类对象
ser_obj = pd.Series([1, 2, 3, 4, 5])
ser_obj.index = ['a', 'b', 'c', 'd', 'e']
print(ser_obj)
# 输出结果如下:
a 1
b 2
c 3
d 4
e 5
dtype: int64
2、通过传入一个字典创建一个Series类对象,其中字典的key就是Series的index,例如:
import pandas as pd
year_data = 2001: 17.8, 2002: 20.1, 2003: 16.5
ser_obj2 = pd.Series(year_data)
print(ser_obj2)
# 输出结果如下:
2001 17.8
2002 20.1
2003 16.5
dtype: float64
1.1.2 使用索引和获取数据
为了能方便地操作Series对象中的索引和数据,所以该对象提供了两个属性index和values分别进行获取。
# 获取ser_obj的索引
ser_obj.index
# 获取ser_obj的数据
ser_obj.values
举例:
# 给pandas起个别名pd
import pandas as pd
# 创建Series类对象
ser_obj = pd.Series([1, 2, 3, 4, 5])
ser_obj.index = ['a', 'b', 'c', 'd', 'e']
print(ser_obj.index)
print('-'*50)
print(ser_obj.values)
# 输出结果如下:
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
--------------------------------------------------
[1 2 3 4 5]
当然,我们也可以直接使用索引来获取数据
# 获取位置索引'c'对应的数据
print(ser_obj['c'])
# 输出结果如下:
3
当某个索引对应的数据进行运算以后,其运算的结果会替换原数据,仍然与这个索引保持着对应的关系。
例如:
# 给pandas起个别名pd
import pandas as pd
# 创建Series类对象
ser_obj = pd.Series([1, 2, 3, 4, 5])
ser_obj.index = ['a', 'b', 'c', 'd', 'e']
ser_obj2 = ser_obj * 2
print(ser_obj)
print('-' * 50)
print(ser_obj)
print(ser_obj2)
结果如下:
a 1
b 2
c 3
d 4
e 5
dtype: int64
--------------------------------------------------
a 1
b 2
c 3
d 4
e 5
dtype: int64
--------------------------------------------------
a 2
b 4
c 6
d 8
e 10
dtype: int64
1.2 数据结构—DataFrame
DataFrame是一个类似于二维数组或表格(如excel)的对象,它每列的数据都可以是不同的数据类型。
注意:
DataFrame的索引不仅有行索引,还有列索引,数据可以有多列
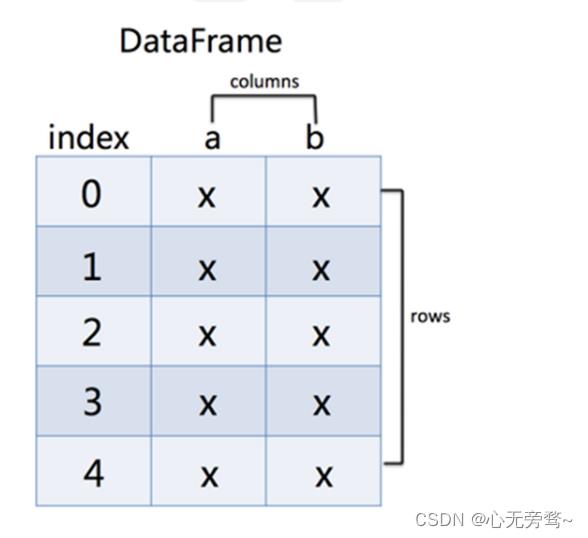
1.2.1 DataFrame的创建方式
Pandas的DataFrame类对象的原型如下(仅作了解):
pandas.DataFrame(data = None,index = None,columns = None,dtype = None,copy = False )
index:表示行标签。若不设置该参数,则默认会自动创建一个从0~N的整数索引。columns:列标签
1、通过传入数组来创建DataFrame类对象:
import numpy as np
import pandas as pd
# 创建数组
demo_arr = np.array([['a', 'b', 'c'],
['d', 'e', 'f']])
# 基于数组创建DataFrame对象
df_obj = pd.DataFrame(demo_arr)
print(df_obj)
# 输出结果如下:
0 1 2
0 a b c
1 d e f
在创建DataFrame类对象时,如果为其指定了列索引,则DataFrame的列会按照指定索引的顺序进行排列,比如指定列索引No1,No2, No3的顺序:
df_obj = pd.DataFrame(demo_arr, columns=['No1', 'No2', 'No3'])
index No1 No2 No3 0 a b c 1 d e f
1.2.2 使用列索引或访问属性获取数据
我们可以使用dataframe的列索引的方式来获取一列数据,返回的结果是一个Series对象。
import numpy as np
import pandas as pd
# 创建数组
demo_arr = np.array([['a', 'b', 'c'],
['d', 'e', 'f']])
# 基于数组创建DataFrame对象,并指定列索引
df_obj = pd.DataFrame(demo_arr, columns=['No1', 'No2', 'No3'])
print(df_obj)
# 通过列索引的方式获取一列数据
element = df_obj['No2']
# 查看一列数据
print('查看一列数据:\\n', element)
# 查看返回结果的类型
print(type(element)) # pandas.core.series.Series
输出结果如下:
No1 No2 No3
0 a b c
1 d e f
查看一列数据:
0 b
1 e
Name: No2, dtype: object
<class 'pandas.core.series.Series'>
我们还可以使用访问属性的方式来获取一列数据,返回的结果是一个Series对象。
# 通过属性获取列数据
element = df_obj.No2
# 查看返回结果的类型
print(type(element))
# 输出类型如下:
<class 'pandas.core.series.Series'>
注意:
在获取DataFrame的一列数据时,推荐使用列索引的方式完成,主要是因为在实际使用中,列索引的名称中很有可能带有一些特殊字符(如空格),这时使用“点字符”进行访问就显得不太合适了。
1.2.3 增加列
要想为DataFrame增加一列数据,则可以通过给列索引或者列名称赋值的方式实现。
import numpy as np
import pandas as pd
# 创建数组
demo_arr = np.array([['a', 'b', 'c'],
['d', 'e', 'f']])
# 基于数组创建DataFrame对象,并指定列索引
df_obj = pd.DataFrame(demo_arr, columns=['No1', 'No2', 'No3'])
print('原始数据:\\n', df_obj)
# 增加No4一列数据
df_obj['No4'] = ['g', 'h']
print('增加一列之后的数据:\\n', df_obj)
输出结果如下:
原始数据:
No1 No2 No3
0 a b c
1 d e f
增加一列之后的数据:
No1 No2 No3 No4
0 a b c g
1 d e f h
1.2.4 删除列
要想删除某一列数据,则可以使用del语句实现。
import numpy as np
import pandas as pd
# 创建数组
demo_arr = np.array([['a', 'b', 'c'],
['d', 'e', 'f']])
# 基于数组创建DataFrame对象,并指定列索引
df_obj = pd.DataFrame(demo_arr, columns=['No1', 'No2', 'No3'])
print('原始数据:\\n', df_obj)
# 删除No3一列数据
del df_obj['No3']
print('删除一列之后的数据:\\n', df_obj)
输出结果如下所示:
原始数据:
No1 No2 No3
0 a b c
1 d e f
删除一列之后的数据:
No1 No2
0 a b
1 d e
1.2.5 读入txt或者csv文件的操作
前面我们提到了DataFrame是一个类似于二维数组或表格(如excel)的对象,既然如此,那么我们便是能够对excel对象类似于csv、xlsx和txt等文件进行如DataFrame一样的操作。
这里展示一下读取txt文件后的输出结果(部分),详细的在下面我们会讲
import pandas as pd
data1 = pd.read_csv('E:\\python机器学习数据建模与分析\\数据\\ReportCard1.txt', sep='\\t')
data2 = pd.read_csv('E:\\python机器学习数据建模与分析\\数据\\ReportCard2.txt', sep='\\t')
# 将两个数据文件按照学号合并为一个数据文件
lastdata = pd.merge(data1, data2, on='xh', how='inner')
print(lastdata)
输出结果如下所示:
xh sex poli chi math fore phy che geo his
0 92103 2.0 NaN NaN NaN 66.0 98.0 79.0 89.0 81.0
1 92239 2.0 40.0 63.0 44.0 21.0 54.0 26.0 26.0 55.0
2 92142 2.0 NaN 70.0 59.0 22.0 68.0 26.0 26.0 63.0
3 92223 1.0 56.0 91.0 65.5 68.0 77.0 39.0 54.5 63.0
4 92144 1.0 59.0 79.0 34.0 34.0 57.0 37.0 37.0 76.0
5 92217 2.0 60.0 82.5 76.5 35.0 81.0 60.0 70.5 74.0
通过输出结果我们可以看出,输出的格式和DataFrame的是一模一样。
二、groupby函数
对数据集进行分组,并对各组应用一个聚合函数或转换函数,通常是数据分析的重要组成部分。在数据载入、合并,完成数据准备之后,通常需要计算分组统计或生成数据透视表。pandas提供了灵活高效的groupby()方法,方便用户对数据集进行切片、切块和摘要等操作。
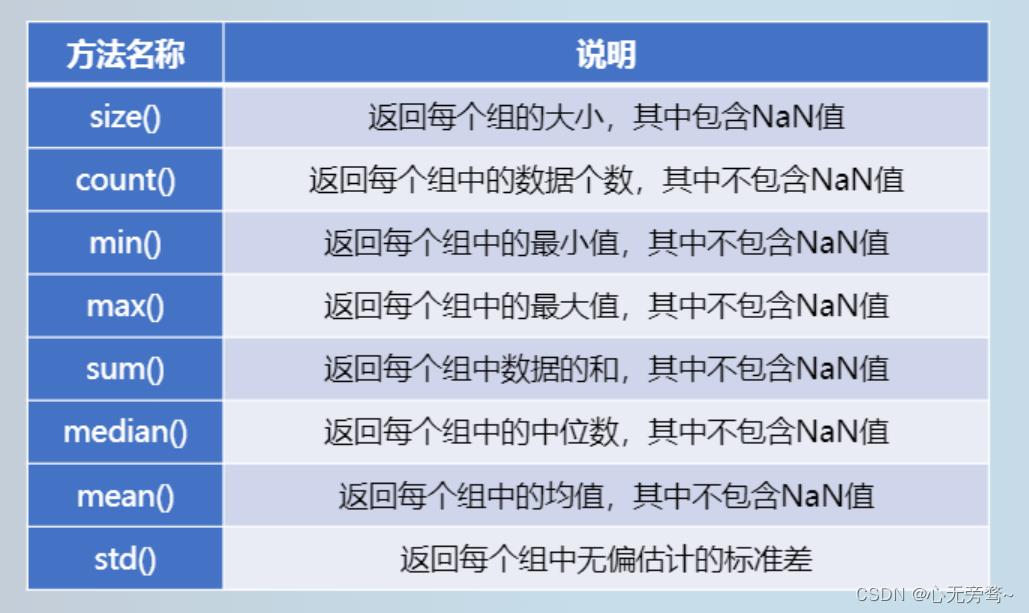
2.1 基本格式
pandas对象支持的groupby()方法语法格式如下:
groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False)
参数by用于指定分组依据,可以是函数、字典、Series对象、DataFrame对象的列名等;参数axis表示分组轴的方向,可以是0或’index’,1或’columns’,默认值为0;参数level表示如果某个轴是一个MultiIndex对象(层级索引),则按照特定级别或多个级别分组;参数as_index=False表示用来分组的列中的数据不作为结果DataFrame对象的index;参数sort指定是否对分组标签进行排序,默认值为True。
使用groupby()方法可以实现两种分组方式,返回的对象结果不同。如果仅对DataFrame对象中的数据进行分组,将返回一个DataFrameGroupBy对象;如果是对DataFrame对象中某一列数据进行分组,将返回一个SeriesGroupBy对象。
举例:
1、按列名对列分组
# 按列名对列分组
obj1 =data['Country'].groupby(data['Region'])
print(type(obj1))
# 输出结果如下:
<class'pandas.core.groupby.generic.SeriesGroupBy’>
2、按列名对数据分组
obj2 = data.groupby(data['Region'])
print(type(obj2))
# 输出结果如下:
<class'pandas.core.groupby.generic.DataFrameGroupBy'>
2.2 groupby的返回形式和正确使用方法
可以使用groupby('label')方法按照单列分组,也可以使用groupby('label1','label2')方法按照多列分组,返回一个GroupBy对象。
举例:
data.groupby('Region')# 按单列分组
# 输出结果如下:
<pandas.core.groupby.generic.DataFrameGroupByobject at 0x7f0aee73e850>
data.groupby(['Region', 'Country'])# 按多列分组
# 输出结果如下:
<pandas.core.groupby.generic.DataFrameGroupByobject at 0x7f0aedeb99d0>
通过以上输出结果我们可以看出,使用数据分组的groupby()方法返回一个GroupBy对象,此时并未真正进行计算,只是保存了数据分组的中间结果。
下面我们就举个例子来简单介绍下如何使用groupby输出自己想要的结果。
原数据data:
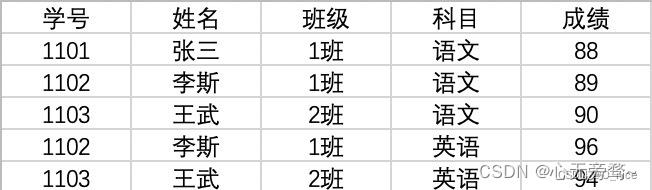
2.2.1 单类分组举例
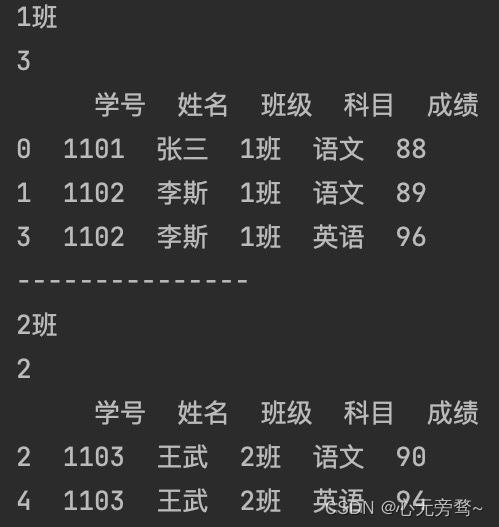
根据“班级”进行分组:
import pandas as pd
data = pd.read_excel('/Users/ABC/Documents/工作簿1.xlsx')
for name, group in data.groupby(['班级']):
num_g = group['班级'].count() # 获取组内记录数目
print(name) # name为班级名称
print(num_g)
print(group) # group为每个分组中的记录情况
print('---------------')
“班级”分组结果:
2.2.2 多类分组举例
根据“班级”和“科目”分组:
import pandas as pd
data = pd.read_excel('/Users/ABC/Documents/工作簿1.xlsx')
for name, group in data.groupby(['班级','科目']):
num_g = group['学号'].count() # 获取组内记录数目
print(name) # name为班级名称
print(num_g)
print(group) # group为每个分组中的记录情况
print('---------------')
“班级”和“科目”分组结果:

三、Pandas读取文件操作
3.1 使用read_csv()进行文件读取
import pandas as pd
data=pd.read_csv('path',sep=',',header=0,names=["第一列","第二列","第三列"],encoding='utf-8')
-
path: 要读取的文件的绝对路径
-
sep:指定列和列的间隔符,默认sep=‘,’
若sep=‘’\\t",即列与列之间用制表符\\t分割,相当于tab——四个空格
-
header:列名行,默认为0
-
names:列名命名或重命名
-
encoding:指定用于unicode文本编码格式
注意:read_csv()函数不仅可以读取csv类型的文件,还可以读取txt类型的文本文件。
3.2 pandas读取xlsx、xls文件
import pandas as pd
data=pd.read_excel('path',sheetname='sheet1',header=0,names=['第一列','第二列','第三列'])
-
path:要读取的文件的绝对路径
-
sheetname:指定读取excel中的哪一个工作表,默认sheetname=0,即默认读取excel中的第一个工作表
若sheetname = ‘sheet1’,即读取excel中的sheet1工作表;
-
header:用作列名的行号,默认为header=0
若header=None,则表明数据中没有列名行
若header=0,则表明第一行为列名
-
names:列名命名或重命名
3.3 pandas读取txt文件
read_csv 也可以读取txt文件,读取txt文件的方法同上,也可以用read_table读取txt文件
import pandas as pd
data = pd.read_table('path', sep = '\\t', header = None, names = ['第一列','第二列','第三列'])
四、数据合并concat
扩展库pandas支持使用concat()函数按照指定的轴方向对多个pandas对象进行数据合并,常用于多个DataFrame对象的数据合并。语法格式及常用参数如下:
pd.concat((objs, axis=0, join='outer', join_axes=None, keys=None, levels=None, names=None, ignore_index=False, verify_integrity=False, copy=True)
参数objs表示需要连接的多个pandas对象,可以是Series对象,DataFrame或Panel对象构成的列表或字典;参数axis指定需要连接的轴向,默认axis=0表示按行进行纵向合并和扩展,axis=1表示按列进行横向合并和扩展。参数join指定连接方式,默认值为outer,表示按照外连接(并集)方式合并数据;如果join=‘inner’,表示按照内连接(交集)方式合并数据。
举例:
创建DataFrame数据框:
df1 = pd.DataFrame('A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0',