如何正确的评测视频画质
Posted 百度Geek说
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何正确的评测视频画质相关的知识,希望对你有一定的参考价值。

导读:本文从影响画质的因素是什么、为什么要不断提升视频画质等问题开始,进而介绍了画质评测的重要性、影响视频画质评测置信度的因素,最后介绍了自研的画质评测系统灵镜及其业务落地情况。
全文5506字,预计阅读时间14分钟。
一、引言
作为视频业务,经常需要:
-
对比不同的视频,从而确定哪个视频的画质更好,以便可以为用户带来更好的体验。
-
对比不同编码参数生成的视频,以便确定在哪些配置下产生的视频能带来最好的体验。
-
对比不同产品的视频画质,以便做到知彼知己,并在对比之中带来较好的用户体验。
总之,需要回答一个问题:究竟哪个是画质最好的视频?本文将从影响画质的因素、为什么要不断提升视频画质、画质评测的重要性、如何正确的评测视频画质、自研的画质评测系统——灵镜来介绍我们如何利用灵镜来客观、置信、高效的评测视频画质,进而提升用户体验。
二、影响画质的因素是什么
当我们提及“视频”时,一般指得均是“数字视频”。视觉信号经过记录、压缩、存储才能产生我们所说的“视频”。同时,由于 HVS(HVS, human visual system,人类视觉系统) 的特点,在视频记录、压缩、存储的过程中,我们可以在视觉质量损失和视频数据压缩之间做出权衡,而不影响视觉质量。
一般而言,影响视频画质的因素主要有以下几点:
-
分辨率:图像中的像素数量,在特定尺寸下,分辨率越高,像素越多,显示的细节则更精细。
-
帧率:一秒内显示的图像数量,电影的帧率一般是 24fps,标准电视的帧率通常是 30fps。
-
亮度:可以显示的图像照明强度的范围,人眼能感知到的亮度范围为 10-3尼特~ 106 尼特。
-
位深:每个像素可以显示的颜色数量,位深度越大,可显示的颜色越多,从而渐变更平滑、更自然。
-
色域:色域是某个特定的色彩的子集,用以表示可以显示的所有颜色的范围。色域一般使用 CIE 1931 色度图上的面积来表示,CIE 1931 曲线的边缘代表可见光光谱颜色的范围。
-
码率:编码每秒视频需要的 bit数量称之为码率(bitrate)。在一定条件下,码率会影响视频质量,码率越低,压缩率越大,画质相对越差。当然,并非码率越高画质越好,在很多情况下,更高的码率带来的往往却只是带宽的浪费。
三、为什么要提升画质
我们经常认为:改善影响视频画质的诸多因素,提升视频的画质,就会提升用户体验,进而会提升产品的相关用户指标。因此,本着以终为始的原则,我们要不断提升视频画质。
然而,事实确实如此吗?我们是否想过如下的问题:
-
用户视频观看时长的增加或降低是视频画质的波动导致的吗?
-
用户在观看视频时,是视频内容的影响力更大还是视频画质的影响力更大?
-
为什么《西游记》的画质比较粗糙,却能循环播放 30 多年,并创造出最高 96%收视率的奇迹?
-
当提升了分辨率、帧率等因素后,画质变好了,但是这同时也意味着需要消耗的带宽、算力、电量等必然会增加。在手机耗电量与画质、播放流畅度与画质之间,用户会选择画质优先吗?
-
提升视频的分辨率和帧率还意味着带宽成本的增加,例如 4K视频比 1080P视频的带宽成本要高 3~4 倍。那么,对于流媒体服务商而言,如果对如上的几个问题还存疑的话,为什么要提升画质呢?
2020年,华纳兄弟与皮克斯等公司的双盲测实验发现,多数消费者其实并无法分辨 8K 与 4K的区别。
看起来,画质提升的必要性并不强烈。既然如此,为什么还要提升视频画质呢?为什么整个视频行业都在为了视频画质的提升而不断努力呢?
1. 显示设备的分辨率不断升级。例如,HUAWEI Mate 40 Pro的屏幕分辨率就达到了2K(2772x1344) 标准。对于电视而言,8K电视目前也成为了趋势。如果视频本身的分辨率依然停留在 480P时代,那么在高分辨率的屏幕上观看时,就会出现比较明显的马赛克效应。
2. 视频采集设备不断升级。例如,iPhone 13 Pro可以支持4K/60fps 的视频拍摄,即便是 android 的千元机档位VIVO Y53S,视频的最低拍摄分辨率也达到了 720P。在这种情况下,如果视频消费端的分辨率还停留在较低分辨率(例如 480P),那就会带来拍摄预览和回放观看体验严重不一致的问题。
3. 视频编解码算法不断升级。有多大的硬件资源,就会产生多复杂的软件产品。不断进化的编解码算法为更高画质的应用提供了底层支撑。当具备了制造飞机的技术时,就不会满足与只制造自行车。
4. 不断丰富的消费级应用和玩法需要更高的画质。根据国家广电总局发布的《5G 高新视频——VR 视频技术白皮书(2020) 》(https://t.hk.uy/baZR),用于 VR视频节目制作与交换中的视频,建议目前最低使用7680x3840 像素数。尤其是在元宇宙之中,要感知到色声香味触法,太差的画质是无法达到要求的。
5. 不断增加的竞对产品。此时,视频画质的基线水平取决于处在该行业中的竞对产品。并且,视频画质已经成为一种对外宣传的有效手段,例如 B 站的 4K/120fps 视频,西瓜的 4K高清修复技术……这无形之中就会形成一种用户对视频画质的预期,当产品的画质如果低于这种预期的时候,用户体验就会降低。当然,更高的画质依赖更高性能的设备和更高的带宽。但是我们需要明白:同样能得 100 分,能力只能到 100 分和卷面只有 100 分之间的差距是非常大的。
四、为什么评测视频画质如此重要
如前所述,众多原因推动视频画质不断提升。然而,没有度量就无法改进,没有度量也就无法评测画质是否有提升、提升的程度如何。另外,在工作中,需要通过评估视频画质来确定流媒体系统的整体要求、对比竞品提供的服务、确定端到端的视频质量等。
视频画质评估如同度量衡一般,构成视频画质提升以及编解码器改进的基石。
4.1 主观评估
评测视频画质的显而易见的方式就是征求用户的意见,这也就是我们所说的:主观评估。但是,主观评估具备如下的问题:
-
主观评估是一个繁琐的、非自动化的过程,不可能利用主观评估来评测每个视频。
-
不同的个体对相同的视频画质感知不同,因此主观评估的结果会随评估者的不同而出现波动。
4.2 客观评估
即便如此,主观评估仍然是一种有价值的方法,并且可以为客观视频画质评估算法提供数据支撑,例如VMAF 就是利用算法指标对主观评估建模的结果。利用算法来评估视频的画质我们称之为:客观评估。
4.3 主、客评估之间的关系
需要注意的是,在视频画质评估领域,虽然算法可以快速、高效、自动的评测视频画质,但是算法也仅仅是对主观评估结果的拟合、预测。也就是说,客观评估算法必须与主观评估之间保持感知上的一致性。
正因为如此,在实际工作中,客观算法一般用以衡量大盘数据,而对于视频编解码器的调整、编解码参数的优化等效果评估,还是会以主观评估为主。MSU Video Codecs Comparisons大赛中,主观打分的结果也是一项重要的指标,例如HEVC/AV1 2019的比赛结果。作为工程师,我们总想着用算法、模型来解决一切问题,然而,我们必须要意识到,并不是所有的问题都可以用算法、模型来解决的。还记得《谁动了我的奶酪》中的“哼哼”吗?
视频画质主、客观评估算法这里不再过多介绍,更详细的信息可以参考《数字视频概念,方法和测量指标》(https://t.hk.uy/baZT)的视频质量指标这一章。
五、影响评测置信度的因素有哪些?
主观评估是画质提升的基石,如何才能保证主观评估结果的客观性、置信度是视频画质评测的核心问题。
为了保证主观评估的置信度,ITU-T 第 9 研究组(SG9, study group 9)提出了若干建议作为主观评估方法,例如ITU-R BT.500。
在工作中,我们发现:不按照标准和规范执行,主观评估的结果肯定是不置信的。但是,有了标准和规范,按照标准和规范来执行主观画质评测,主观评估的结果就置信了吗?
在工作中,我们发现,并非如此。标准提供了建议,但是具体执行却受限于各种因素,这些受限的因素会影响最终的结果置信度。
一个看起来非常简单的事情(不就是找人来打个分吗),实际上却并不简单。
5.1 评测样本的问题
视频样本本身对视频画质主观评估的结果会产生非常大的影响,实际评测过程中,遇到的样本相关的问题主要有如下几种:
1. 评测视频时间较长,场景变化较大。这种情况下,用户可能没有耐心看完整个视频,或者跳跃性的观看视频,导致在评测过程中忽略部分信息而而导致最终结果置信度较差。
2. 评测的视频中存在产品 logo。视频中的 logo 会对用户的主观评测带来额外的信息干扰,进而干扰到最终的评测结果。实际评测过程中,我们也观察到视频中的 logo 确实会影响用户的主观打分。

3. 评测视频的场景覆盖率较低,或者只覆盖了部分产品场景。例如只选取了风景、人物等场景的视频,而缺失了运动类,知识类等场景的视频。
5.2 评测工具的问题
1. 视频缩放带来的误差。为了能够同时对比两个视频,一般而言,评测工具会同时播放待评估的两个视频来让用户主观打分。但是,如下图所示,当视频分辨率比较大时(1080x1920),这种方式就会导致视频显示区域的缩放,进而导致视频中画质较差的地方因为视频显示区域的缩放而隐藏。

2. 视频重叠带来的误差。为了解决上一个问题,评估工具会增加如下图所示的重叠样式来避免缩放带来的误差问题,同时也希望重叠方式能够更直接的对比出视频间的差异。
但是,在实际评估中,我们发现这种看起来比较好的方式因为存在视频画面的阶段,也会导致主观评估结果的不置信。用户在评估过程中,需要不停的拖动画面的分割线,来观察视频不同区域的画质差异。并且对于 ROI编码的视频而言,用一个视频的区域 A和另一个视频的区域 B做对比,本身就非常不合理。

3. 视频运动带来的误差。和图片不同,视频是一个在时间上连续变化的帧序列。而这种视频本身的运动和变化会在一定程度上隐藏视频中某些帧的某些区域的画质问题。这也就是我们常说的 HVS 的运动掩蔽效应。为了避免这种误差,尤其是对于编解码算法的研发人员,往往希望能够对视频进行逐帧对比,以发现潜在的隐藏风险。虽然诸如 QuickTime、VLC等播放器提供了单帧播放能力,但是评测工具却较少提供单帧对比的能力。
4. 忽略播放设备的差异带来的误差。工作中,我们不止一次的发现用 PC 的评估工具来评估移动设备的播放效果的场景。利用标准和规范指导下的工具得到了一个结果,却忽视了不同设备下显示效果的差异,最终导致这个本来应该置信的结果变得非常不置信。尤其是对于 HDR视频而言,设备的差异性会体现的更加明显。
5.3 评测者的认知差异
1. 评测者的惯性认知带来的误差。对于固定顺序出现的对比评估,我们发现评测者总是会根据前面几对样本的结果来对后面的结果进行预测,然后按照预测的结果来打分,而不是完全按照自己个主观感知来打分。这种预测的惯性认知会给评估带来非常大的干扰和误差。
2. 评测者的关注焦点不同带来的误差。不同的评测者对同一画面的关注点不同而带来的评估结果波动较大的问题在实际评估工作中经常出现。例如用户从背景、前景、亮度、美妆等不同角度来评估时,给出的打分也不相同。
六、画质评测利器——灵境
历时 2 年多,经历近 500+ 主观评估,1000+ 评估样本,1000+ 评测人员(专家和普通用户),趟过一个又一个的坑,利用技术解决实际评测中遇到的一个又一个的不置信因素,逐步建成了目前较为置信的视频画质评估系统——灵镜。
灵镜基于 ITU 标准,依托自研的 10+ 项专利技术,借助百度强大的视频基础技术,在不断实践的基础之上而形成的一款支持多端(PC,Android,ios)评测的视频画质评测服务。
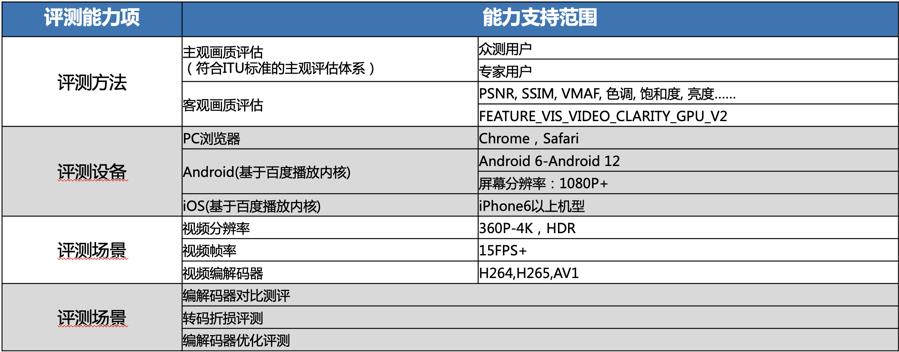
同时灵镜还提供视频画质评估的一站式服务,涵盖了:从视频生产至视频消费的全链路画质评估,画质、成本等全方位的评测以及解析。
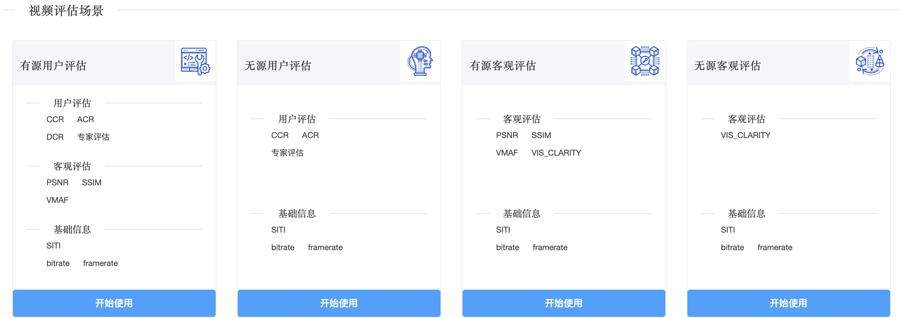
在评测方式上,灵镜支持PC、Android、iOS设备上的横屏/竖屏,专家/普通用户,全屏/非全屏等24种评测模式,其中部分评测模式如下所示:
1. 单屏评测

2. 同屏重叠评测(同时支持 DCR 和 CCR 两种评估模式,并且为了保证置信度,采用视频同区域对比的方式进行同屏重叠对比,可以滑动视频区域来选择不同区域的视频进行对比)
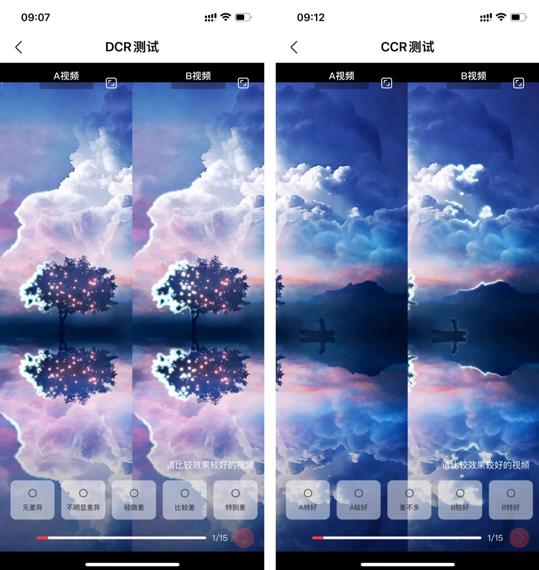
3. 专家评测
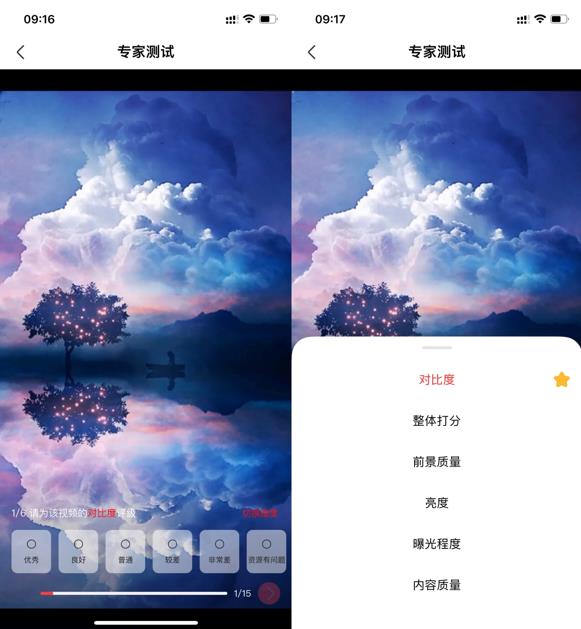
4. 同屏评测

除此之外,灵镜还提供了:
-
摄像头 Mock 能力,实现用指定视频替换摄像头的采集数据
-
画质客观评估能力,例如 VMAF,PSNR,SSIM等,对于 PSNR,灵镜还提供了空间可视化能力,以便进行更客观的评测

-
视频属性计算能力,例如 SITI,色度,饱和度,亮度,码率,帧率,分辨率等
-
视频处理&检测能力,例如静态帧检测,单色帧检测,音画同步检测,异常视频构造等
灵镜通过分层的思想——基础设施层、灵镜工具层、灵镜服务层,上层对下层能力进行封装,在保证使用灵活性的同时使得服务更符合业务需求。

对于业务而言,灵镜提供了如下所示的视频画质评测服务的全流程闭环管理:
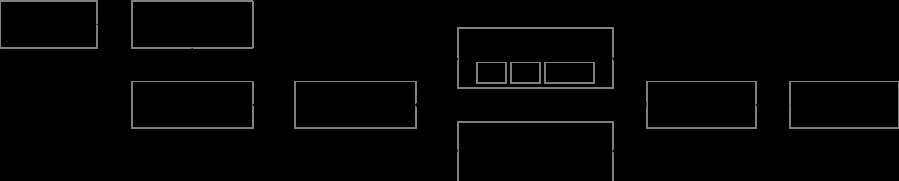
目前,灵镜已经服务于百度 FEED,好看,直播、网盘、小度等的视频画质评测&检测,并发挥着重要作用。同时灵镜也在实践中证明了其置信度。
接下来,我们还将继续完善灵镜的能力:
-
单帧对比评测能力
-
HDR 评测体系
-
8K,120fps的高分辨率、高帧率评测体系
-
美颜、美妆等评测体系
-
……
推荐阅读:
视频质量评测标准——VMAF
阿里云视频云直播转码每天都会处理大量的不同场景、不同编码格式的直播流。为了保证高画质,团队借助VMAF标准来对每路转码的效果做质量评估,然后进行反馈、调优、迭代。这么做的原因在于,像动作片、纪录片、动画片、体育赛事这些场景,影响画质的因素各不相同,基于VMAF的视频质量反馈机制,可以在保证画质的前提下,对不同的场景做针对性优化,达到画质最优、成本最低的效果。本文由阿里云视频云高级开发工程师杨洋撰写,旨在分享VMAF的核心模块与技术实践。
背景
图像质量的衡量是个老问题,对此人们提出过很多简单可行的解决方案。例如均方误差(Mean-squared-error,MSE)、峰值信噪比(Peak-signal-to-noise-ratio,PSNR)以及结构相似性指数(Structural Similarity Index,SSIM),这些指标最初都是被用于衡量图像质量的,随后被扩展到视频领域。这些指标通常会用在编码器(“循环”)内部,可用于对编码决策进行优化并估算最终编码后视频的质量。但是由于这些算法衡量标准单一,缺乏对画面前后序列的总体评估,导致计算的结果很多情况下与主观感受并不相符。
VMAF 介绍
VMAF(Video Multimethod Assessment Fusion)由Netflix开发并开源在Github上,基本想法在于,面对不同特征的源内容、失真类型,以及扭曲程度,每个基本指标各有优劣。通过使用机器学习算法(SVM)将基本指标“融合”为一个最终指标,可以为每个基本指标分配一定的权重,这样最终得到的指标就可以保留每个基本指标的所有优势,借此可得出更精确的最终分数。Netfix使用主观实验中获得的意见分数对这个机器学习模型进行训练和测试。VMAF主要使用了3种指标:visual quality fidelity(VIF)、detail loss measure(DLM)、temporal information(TI)。其中VIF和DLM是空间域的也即一帧画面之内的特征,TI是时间域的也即多帧画面之间相关性的特征。这些特性之间融合计算总分的过程使用了训练好的SVM来预测。工作流程如图:

VMAF 核心模块
VMAF基于SVM的nuSvr算法,在运行的过程中,根据事先训练好的model,赋予每种视频特征以不同的权重。对每一帧画面都生成一个评分,最终以均值算法进行归总(也可以使用其他的归总算法),算出该视频的最终评分。其中主要的几个核心模块如下:

VMAF分别用python和C++实现了两套接口,同时提供了C版本的lib库,最新版本的ffmpeg已经将vmaf作为一个filter集成进去。下面我们分析下各个模块的作用:
? Asset
一个Asset单元,包含了一个正在执行的任务信息。比如目标视频与原始视频的帧范围,低分辨率视频帧上采样信息等(VMAF会在特征提取前通过上采样的方式保证两个视频分辨率相同)。
? Executor
Executor会取走并计算Asset链表中每一个Asset单元,将执行结果返回到一个Results链表中。Executor类是FeatureExtractor与QualityRunner的基类。它提供了一些基函数,包括Results的操作函数、FIFO管道函数、clean函数等。
? Result
Result是以key-value形式,将Executor执行的结果存储起来。key存储的是“FrameNum”或者质量分数的类型(VMAF_feature_vif_scale0_score或VMAF_feature_vif_scale1_score等),value存储的是一系列分值组成的链表。
Result类也提供了一个汇总工具,将每个单元的质量分数汇总成一个值。默认的汇总算法是“均值算法”,但是Result.set_score_aggregate_method()方法允许定制其他的算法。
? ResultStore
ResultStore类提供了Result数据集的存储、加载的能力。
? FeatureExtractor
FeatureExtractor是Extractor子类,专门用于从Asset集合中提取特征,作为基本的特征提取类。任何具体的特征提取接口,都继承自FeatureExtractor,例如VmafFeatureExtractor/PsnrFeatureExtractor/SsimFeatureExtractor等。
? FeatureAssembler
FeatureAssembler是一个聚合类,通过在构造函数传入feature_dict参数,指定具体的特征提取标准,将该标准提取出的特征结果聚合,输出到一个BasicResult对象中。FeatureAssembler被QualityRunner调用,用来将提取后的特征数组传给TrainTestModel使用。
? TrainTestModel
TrainTestModel是任何具体的回归因子接口的基类,回归因子必须提供一个train()方法去训练数据集,predict()方法去预测数据集,以及to_file(),frome_file()方法去保存、加载训练好的模型。
回归方程的超参数必须通过TrainTestModel的构造函数传入。TrainTestModel类提供了一些基础方法,例如归一化、反归一化、评估预测性能。
? CrossValidation
CrossValidation提供了一组静态方法来促进TrainTestModel训练结果的验证。因此,它还提供了搜索TrainTestModel最优超参的方法。
? QualityRunner
QualityRunner是Executor子类,用来评估Asset任务集合的画质分数。任何用于生成最终质量评分的接口都应该继承QualityRunner。例如跑vmaf标准的VmafQualityRunner,跑psnr标准的PsnrQualityRunner都是QualityRunner的子类。
自定义VMAF
最新版本的vmaf提供了1080p、4k、mobilephone三种场景下的model文件。Netflix号称使用了海量的、多分辨率、多码率视频素材(高噪声视频、CG动漫、电视剧)作为数据集,得到的这三组model。在日常使用中,这三组model基本满足需求了。不过,VMAF提供了model训练工具,可以用于训练私有model。
创建新的数据集
首先,按照dataset格式,定义数据集文件,比如定义一个
example_dataset.py:
dataset_name = ‘example_dataset‘
yuv_fmt = ‘yuv420p‘
width = 1920
height = 1080
ref_videos = [
{‘content_id‘: 0,
‘content_name‘: ‘BigBuckBunny‘,
‘path‘: ref_dir + ‘/BigBuckBunny_25fps.yuv‘}
...
]
dis_videos = [{‘asset_id‘: 0,
‘content_id‘: 0,
‘dmos‘: 100.0,
‘path‘: ref_dir + ‘/BigBuckBunny_25fps.yuv‘,
}
...
]
ref_video是比对视频集,dis_video是训练集。每个训练集样本视频都有一个主观评分DMOS,进行主观训练。SVM会根据DMOS做有监督学习,所以DMOS直接关系到训练后model的准确性。
PS: 将所有观察者针对每个样本视频的分数汇总在一起计算出微分平均意见分数(Differential Mean Opinion Score)即DMOS,并换算成0-100的标准分,分数越高表示主观感受越好。
验证数据集
./run_testing quality_type test_dataset_file [--vmaf-model optional_VMAF_model_path] [--cache-result] [--parallelize]
数据集创建后,用现有的VMAF或其他指标(PSNR,SSIM)验证数据集是否正确,验证无误后才能训练。
训练新的模型
验证完数据集没问题后,便可以基于数据集,训练一个新的质量评估模型。
./run_vmaf_training train_dataset_filepath feature_param_file model_param_file output_model_file [--cache-result] [--parallelize]
例如,
./run_vmaf_training example_dataset.py resource/feature_param/vmaf_feature_v2.py resource/model_param/libsvmnusvr_v2.py workspace/model/test_model.pkl --cache-result --parallelize
feature_param_file 定义了使用那些VMAF特征属性。例如,
feature_dict = {‘VMAF_feature‘:‘all‘, } 或 feature_dict = {‘VMAF_feature‘:[‘vif‘, ‘adm‘], }
model_param_file 定义了回归量的类型和使用的参数集。当前版本的VMAF支持nuSVR和随机森林两种机器算法,默认使用的nuSVR。
output_model_file 是新生成的model文件。
交叉验证
vmaf提供了run_vmaf_cross_validation.py工具用于对新生成的model文件做交叉验证。
自定义特征和回归因子
vmaf具有很好的可扩展性,不仅可以训练私有的model,也可以定制化或插入第三方的特征属性、SVM回归因子。
通过feature_param_file类型文件,支持自定义或插入第三方特征,需要注意的是所有的新特征必须要是FeatureExtractor子类。类似的,也可以通过param_model_file类型文件,自定义或插入一个第三方的回归因子。同样需要注意的是,所有创建的新因子,必须是TrainTestModel子类。
由于Netflix没有开放用于训练的数据集,个人觉得,受制于数据集DMOS准确性、数据集样本的量级等因素,通过自建数据集训练出普适的model还是挺不容易滴~
以上是关于如何正确的评测视频画质的主要内容,如果未能解决你的问题,请参考以下文章
端到端QoE优化实践,视频播放体验优化,视频评测体系构建,基于大数据的VMAF质量计算...