论文阅读笔记Beyond Natural Motion: Exploring Discontinuity for Video Frame Interpolation——超越自然运动: 探索视频帧
Posted 站在天涯望断鸿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读笔记Beyond Natural Motion: Exploring Discontinuity for Video Frame Interpolation——超越自然运动: 探索视频帧相关的知识,希望对你有一定的参考价值。
论文:Beyond Natural Motion: Exploring Discontinuity for Video Frame Interpolation
会议:2022CVPR February
摘要
视频插值是在给定两个连续的帧时,合成中间帧的任务。以往的研究大多集中在适当的帧翘曲操作和对翘曲帧的改进模块上。这些研究都是对只有连续运动的自然视频进行的。然而,许多实用的视频包含了许多不连续的动作,如聊天窗口、水印、GUI元素或字幕。我们提出了三种技术来扩展两个连续帧之间的转换的概念来解决这些问题。首先是一种新的架构,它可以分离连续和不连续的运动区域。我们还提出了一种新的数据增强策略,称为图-文本混合(FTM),以使我们的模型学习更一般的场景。最后,我们提出了损失函数来提供具有数据增强的不连续运动区域的监督。我们收集了一个特殊的数据集,包括一些手机游戏和聊天视频。我们表明,我们的方法显著提高了视频在特殊数据集上的插值质量。此外,我们的模型对于只包含连续运动的自然视频数据集的性能优于最先进的方法,如davis和UCF101。
一、介绍
视频插值是一种低级的视觉任务,通过生成额外的帧来提高视频质量。当每个连续输入帧的时间间隔固定时,我们可以得到更平滑的视频,当帧率固定时,我们可以得到慢动作视频。这也可以通过控制帧速率[2,31]、视图合成[8,14,36]或其他实际应用程序[22,26,34]来应用于视频压缩。之前的大部分作品都集中在视频中物体的运动上。他们利用估计的流图[12,16]、内核[6,15,17,20,21]或预先训练过的光流模型[18,19,26],将每个对象放置在相邻帧上的其位置的中间。然而,许多实际的视频包含特殊的对象,如GUI元素和字幕,它们不连续移动。此外,即使是没有这些元素的典型视频也会包含一些特殊的场景,如亮度变化和雾霾。因此,连续帧之间的过渡概念应进一步超出运动范围。
在本文中,我们提出了三种技术来处理同时包含连续运动和不连续运动的视频。首先,我们提出了一种新的数据增强方法,称为图-文本混合(FTM),它由图形混合(FM)和文本混合™组成。FM是添加固定随机数字的增强,TM是添加不连续移动随机文本的增强。该网络可以使用FTM学习连续和不连续的运动,而无需任何额外的数据集。其次,我们提出了一种基于AdaCoF[15]的体系结构,它可以分离每一帧中连续和不连续运动的区域。我们的框架估计了一个被称为不连续映射的映射,它决定了每个像素的运动是连续的还是不连续的。由于只看到两帧很难确定物体是否不连续移动,所以我们给了四帧作为网络的输入。最后,如果我们同时利用FTM和不连续映射,就可以通过给出不连续映射的基本真实情况来监督模型。因此,我们提出了一个额外的损失函数来指导我们的模型来估计更尖锐的不连续映射。
我们构造了一个特殊的数据集,称为游戏图形数据集,来评估我们的方法和竞争工作如何处理不连续运动。与其他方法相比,我们的方法有了明显的改进结果。此外,我们的方法在仅包含连续运动的典型测试数据集上优于这些方法,如davis[24]和[27]数据集[27]。我们的主要贡献可以总结如下:
1.数据增强 我们提出了一种新的数据增强策略,称为FTM,它可以简单地应用于现有的视频数据集,使模型学习连续和不连续的运动。
2.新架构 我们提出了一种可以分离连续运动和不连续运动的新框架。
3.表现我们提出的网络不仅在包含不连续运动的数据集上,而且在所有其他自然测试视频上,实现了一般视频帧插值的最先进的性能。
二、相关工作
现有的视频帧插值算法大多由运动估计和运动补偿两部分组成。运动估计模块估计连续两帧之间的像素级对应关系,以得到运动信息。然后,运动补偿部分根据估计的运动来扭曲帧。近年来的视频帧插值研究利用深度神经网络(DNN)从两个方面获得了高质量的结果。
一个是端到端学习方法。一些工作训练他们的神经网络,同时执行运动估计和补偿。Niklaus等人[20]提出了估计输入帧像素的大核权值的网络。然后将输入帧与估计的内核进行自适应卷积,得到输出帧。由于核尺寸大,需要过多的权值,Niklaus等人[21]通过使用可分离核来解决了这个问题。另一方面,Liu等人[16]和Jiang等人[12]提出了估计由向量直接指向参考像素组成的密集流图的神经网络。但是,上述方法都有一些局限性,即基于核的方法不能处理核以外的运动,而基于流的方法只表示每个输出像素的一个像素。为了解决这个问题,Lee等人[20]使用可变形卷积[5]结合了这两种方法。一些方法提出了在没有运动补偿的直接估计中间帧的神经网络。Long等人[17]训练了一个简单的U-Net[25]来估计中间帧,但结果往往很模糊。因此,Choi等人[4]提出了一种新的基于渠道关注的架构,以获得更清晰的结果。
另一种是基于光流的方法。最近,许多估计高质量光流图的方法被引入了[11,28,29]。因此,一些工作利用光流图作为运动信息,并训练额外的网络进行运动补偿或输出帧细化。Niklaus等人[18]利用从ResNet-18[10]中提取的上下文信息以及光流,并使用他们自己的基于GridNet[9]的神经网络改进扭曲帧。使用预先训练过的光流有一个问题,即流图由从输入帧开始的向量组成。然而,从输出帧开始的向量是必要的,以清楚地扭曲帧。为了解决这个问题,Bao等人的[1]使用了从基于沙漏架构的单核深度估计网络[3]中获得的深度图来清晰地反转光流图。Niklaus等人[19]提出使用SoftMax函数将所有投影到相同位置的像素值合并。
有一些研究需要扩大视频的内插插值领域。Liu等人[32]提出了二次视频插值方法,该方法利用四帧不仅覆盖线性运动,还覆盖二次运动。然而,它们仍然不能处理不连续的运动。最后,Siyao等人[26]提出了可以插值卡通视频的网络。然而,他们关注的是卡通图像的特征,而不是视频的运动。在本文中,我们扩展了视频插值任务,不仅包括自然运动,而且还包括帧之间的不连续过渡
三、建议的方法
给定连续的视频帧I0、I1、I2和I3,我们的研究重点是通过适当设计帧插值网络f来找到I1和I2之间的中间帧Iout。产生Iout所需的所有信息都可以从I1和I2中获得。由于估计了不连续的运动面积,我们的模型获得了四帧作为输入,而模型实际使用产生的帧是i1和i2。然后,我们引入了基于AdaCoF[15]的所提网络。
3.1.重新访问以前的模型
在AdaCoF[15]中,他们将这种关系看作是从I1和I2到Iout的扭曲操作T(流的自适应协作)。我们可以得到Iout作为T(I1;Θf)和T(I2;Θb)的组合,作为前向和向后向翘曲Θf和Θb的权值和偏移向量。输入和输出图像大小为M×N,遮挡图为V∈[0,1]M×N;总体方程如下:
论文阅读 Learning Transferable Visual Models From Natural Language Supervisio
Learning Transferable Visual Models From Natural Language Supervision
Computer Vision and Pattern Recognition 2021
task
利用网上大规模的图片信息来进行训练从而做计算机视觉的任务
阅读记录



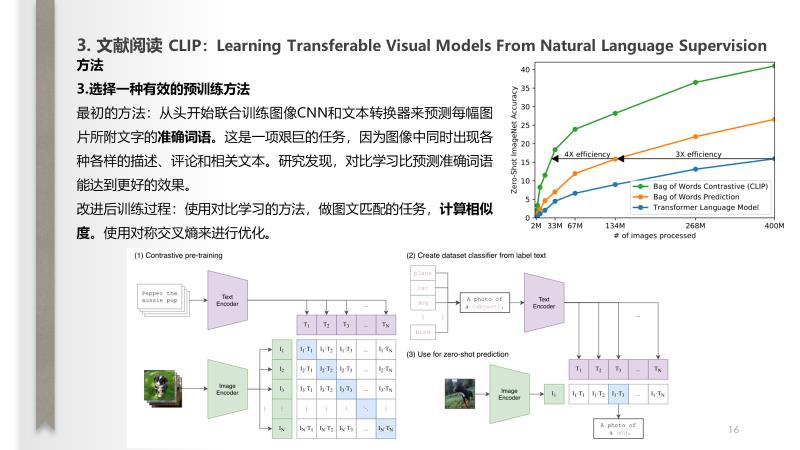

说明
以上内容均为作者本人平时阅读并且汇报使用,内容整理全凭个人理解,如有侵权,请联系我;内容如有错误,欢迎留言交流。转载请注明出处,并附有原文链接,谢谢!
此外,我还喜欢用ipad对论文写写画画(个人英文阅读的水平有限),做一些断句、重点勾画等,有兴趣大家可以按需下载:链接

更多论文分享,请参考: 深度学习相关阅读论文汇总(持续更新)
以上是关于论文阅读笔记Beyond Natural Motion: Exploring Discontinuity for Video Frame Interpolation——超越自然运动: 探索视频帧的主要内容,如果未能解决你的问题,请参考以下文章